

27 мая в главном зале конференции DevOpsConf 2019, проходящей в рамках фестиваля , в рамках секции «Непрерывная поставка», прозвучал доклад «werf — наш инструмент для CI/CD в Kubernetes». В нём рассказывается о тех проблемах и вызовах, с которыми сталкивается каждый при деплое в Kubernetes, а также о нюансах, которые могут быть заметны не сразу. Разбирая возможные пути решения, мы показываем, как это реализовано в Open Source-инструменте .
С момента выступления наша утилита (ранее известная как dapp) преодолела исторический рубеж в 1000 звёзд на GitHub — мы надеемся, что растущее сообщество её пользователей упростит жизнь многим DevOps-инженерам.

Итак, представляем (~47 минут, гораздо информативнее статьи) и основную выжимку из него в текстовом виде. Поехали!
Доставка кода в Kubernetes
Речь в докладе пойдёт больше не про werf, а про CI/CD в Kubernetes, подразумевая, что наш софт упакован в Docker-контейнеры (об этом я рассказывал в ), а K8s будет использоваться для его запуска в production (об этом — в ).
Как выглядит доставка в Kubernetes?
- Есть Git-репозиторий с кодом и инструкциями для его сборки. Приложение собирается в Docker-образ и публикуется в Docker Registry.
- В том же репозитории есть инструкции и о том, как приложение деплоить и запускать. На стадии деплоя эти инструкции отправляются в Kubernetes, который получает нужный образ из registry и запускает его.
- Плюс, обычно есть тесты. Некоторые из них можно выполнять при публикации образа. Также можно (по тем же инструкциям) развернуть копию приложения (в отдельном пространстве имён K8s или отдельном кластере) и запускать тесты там.
- Наконец, нужна CI-система, которая получает события из Git’а (или нажатия кнопок) и вызывает все обозначенные стадии: build, publish, deploy, test.

Здесь есть несколько важных замечаний:
- Поскольку у нас неизменяемая инфраструктура (immutable infrastructure), образ приложения, что используется на всех этапах (staging, production и т.п.), должен быть один. Подробнее об этом и с примерами я рассказывал .
- Поскольку мы следуем подходу инфраструктура как код (IaC), код приложения, инструкции для его сборки и запуска должны лежать именно в одном репозитории. Подробнее об этом — см. в .
- Цепочку доставки (delivery) мы обычно видим так: приложение собрали, протестировали, релизнули (этап release) и всё — доставка произошла. Но в действительности же пользователь получает то, что вы выкатили, не тогда, когда вы это доставили в production, а когда он смог туда зайти и этот production работал. Поэтому я считаю, что цепочка доставки заканчивается только на этапе эксплуатации (run), а если говорить точнее, то даже в тот момент, когда код убрали с production (заменив его на новый).
Вернёмся к обозначенной выше схеме доставки в Kubernetes: её изобрели не только мы, но и буквально каждый, кто занимался данной проблемой. По сути этот паттерн сейчас называют GitOps (подробнее о термине и стоящими за ним идеями можно прочитать ). Посмотрим на этапы схемы.
Стадия сборки (build)
Казалось бы, что можно рассказать в 2019 году про сборку Docker-образов, когда все умеют писать Dockerfile’ы и запускать docker build?.. Вот нюансы, на которые хотелось бы обратить внимание:
- Вес образа имеет значение, поэтому используйте , чтобы оставить в образе только действительно нужное для работы приложения.
- Количество слоёв надо минимизировать, объединяя цепочки из
RUN-команд по смыслу. - Однако это добавляет проблем отладке, поскольку при падении сборки приходится отыскивать ту нужную команду из цепочки, которая вызвала проблему.
- Скорость сборки важна, потому что мы хотим быстро выкатывать изменения и смотреть на результат. Например, не хочется пересобирать зависимости в библиотеках языка при каждой сборке приложения.
- Зачастую из одного Git-репозитория требуются много образов, что можно решить набором из Dockerfile’ов (или именованными стадиями в одном файле) и Bash-скриптом с их последовательной сборкой.
Это была лишь верхушка айсберга, с которой сталкиваются все. Но есть и другие проблемы, а в частности:
- Зачастую на стадии сборки нам нужно что-то примонтировать (например, закэшировать результат команды типа apt’а в стороннюю директорию).
- Мы хотим Ansible вместо того, чтобы писать на shell’е.
- Мы хотим собирать без Docker (зачем нам дополнительная виртуальная машина, в которой надо всё для этого настраивать, когда уже есть кластер Kubernetes, в котором можно запускать контейнеры?).
- Параллельная сборка, которую можно понимать по-разному: разные команды из Dockerfile (если используется multi-stage), несколько коммитов одного репозитория, несколько Dockerfile’ов.
- Распределённая сборка: мы хотим собирать что-то в pod’ах, которые являются «эфемерными», т.к. у них пропадает кэш, а значит — его надо хранить где-то отдельно.
- Наконец, вершину желаний я назвал автомагией: идеально было бы зайти в репозиторий, набрать какую-то команду и получить готовый образ, собранный с пониманием того, как и что правильно сделать. Впрочем, лично я не уверен, что все нюансы так можно предусмотреть.
И вот есть проекты:
- — сборщик от компании Docker Inc (уже интегрированный в актуальные версии Docker), которая пытается решить все эти проблемы;
- — сборщик от Google, позволяющий собирать без Docker;
- — попытка CNCF сделать автомагию и, в частности, интересное решение с rebase для слоёв;
- и ещё куча других утилит, таких как , …
… и посмотрите, сколько у них звёзд на GitHub. То есть, с одной стороны, docker build есть и может что-то сделать, но в действительности-то вопрос до конца не решён — доказательством этому и служит параллельное развитие альтернативных сборщиков, каждый из которых решает какую-то часть проблем.
Сборка в werf
Так мы подобрались к (ранее как dapp) — Open Source-утилите компании «Флант», которую мы делаем уже много лет. Начиналось всё лет 5 назад с Bash-скриптов, оптимизирующих сборку Dockerfile’ов, а последние 3 года ведётся полноценная разработка в рамках одного проекта со своим Git-репозиторием (сначала на Ruby, а потом на Go, а заодно и переименовали). Какие вопросы сборки решены в werf?
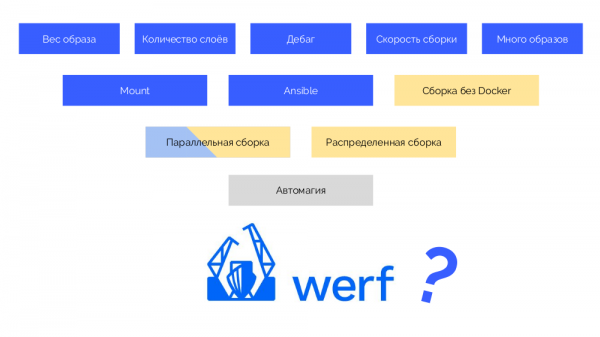
Закрашенные синим проблемы уже реализованы, параллельная сборка сделана в рамках одного хоста, а выделенные жёлтым вопросы планируем доделать к концу лета.
Стадия публикации в registry (publish)
Набрали docker push… — что может быть сложного в том, чтобы загрузить образ в registry? И тут возникает вопрос: «Какой тег поставить образу?» Возникает он по той причине, что у нас есть Gitflow (или другая стратегия Git’а) и Kubernetes, а индустрия стремится к тому, чтобы происходящее в Kubernetes следовало тому, что делается в Git. Ведь Git — наш единственный источник правды.
Что в этом сложного? Гарантировать воспроизводимость: от коммита в Git, который по своей природе неизменный (immutable), до образа Docker, который должен сохраняться таким же.
Нам также важно определять происхождение, потому что мы хотим понимать, из какого коммита было собрано приложение, запущенное в Kubernetes (тогда мы сможем делать diff’ы и подобные вещи).
Стратегии тегирования
Первая — это простой git tag. У нас есть registry с образом, тегированным как 1.0. В Kubernetes есть stage и production, куда этот образ выкачен. В Git мы делаем коммиты и в какой-то момент ставим тег 2.0. Собираем его по инструкциям из репозитория и помещаем в registry с тегом 2.0. Выкатываем на stage и, если всё хорошо, потом на production.
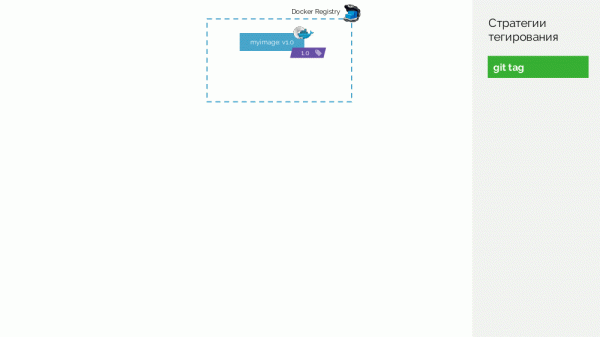
Проблема такого подхода в том, что мы сначала поставили тег, а только потом протестировали и выкатили. Почему? Во-первых, это просто нелогично: мы выдаем версию софту, который еще даже не проверяли (не можем сделать иначе, т.к. для того, чтобы проверить, требуется поставить тег). Во-вторых, такой путь не сочетается с Gitflow.
Второй вариант — git commit + tag. В master-ветке есть тег 1.0; для него в registry — образ, развёрнутый на production. Кроме того, в Kubernetes-кластере есть контуры preview и staging. Дальше мы следуем Gitflow: в основной ветке для разработки (develop) делаем новые фичи, в результате чего появляется коммит с идентификатором #c1. Мы его собираем и публикуем в registry, используя этот идентификатор (#c1). С таким же идентификатором выкатываем на preview. Аналогично делаем с коммитами #c2 и #c3.
Когда поняли, что фич достаточно, начинаем всё стабилизировать. В Git создаём ветку release_1.1 (на базе #c3 из develop). Собирать этот релиз не потребуется, т.к. это было сделано на предыдущем этапе. Поэтому можем просто выкатить его на staging. Исправляем баги в #c4 и аналогично выкатываем на staging. Параллельно в то же время идёт разработка в develop, куда периодически забираются изменения из release_1.1. В какой-то момент получаем собранный и выкаченный на staging коммит, которым мы довольны (#c25).
Тогда мы делаем merge (с fast-forward’ом) релизной ветки (release_1.1) в master. Ставим на этот коммит тег с новой версией (1.1). Но этот образ уже собран в registry, поэтому, чтобы не собирать его ещё раз, мы просто добавляем второй тег на существующий образ (теперь он в registry имеет теги #c25 и 1.1). После этого выкатываем его на production.
Есть недостаток, что на staging выкачен один образ (#c25), а на production — как бы другой (1.1), но мы знаем, что «физически» это один и тот же образ из registry.
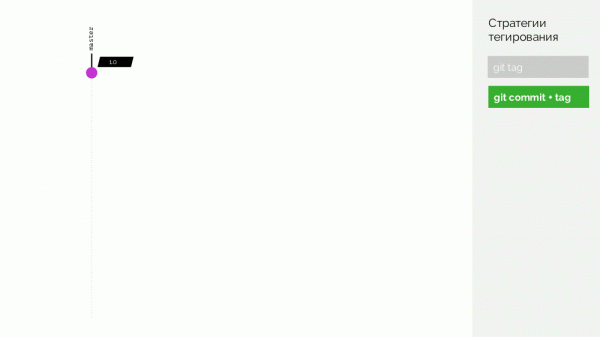
Настоящий же минус в том, что нет поддержки merge commit’ов, надо делать fast-forward.
Можно пойти дальше и сделать трюк… Рассмотрим пример простого Dockerfile:
FROM ruby:2.3 as assets
RUN mkdir -p /app
WORKDIR /app
COPY . ./
RUN gem install bundler && bundle install
RUN bundle exec rake assets:precompile
CMD bundle exec puma -C config/puma.rb
FROM nginx:alpine
COPY --from=assets /app/public /usr/share/nginx/www/publicПостроим из него файл по такому принципу, что возьмём:
- SHA256 от идентификаторов используемых образов (
ruby:2.3иnginx:alpine), которые являются контрольными суммами их содержимого; - все команды (
RUN,CMDи т.п.); - SHA256 от файлов, которые добавлялись.
… и возьмём контрольную сумму (снова SHA256) от такого файла. Это сигнатура всего, что определяет содержимое Docker-образа.

Вернёмся к схеме и вместо коммитов будем использовать такие сигнатуры, т.е. тегировать образы сигнатурами.
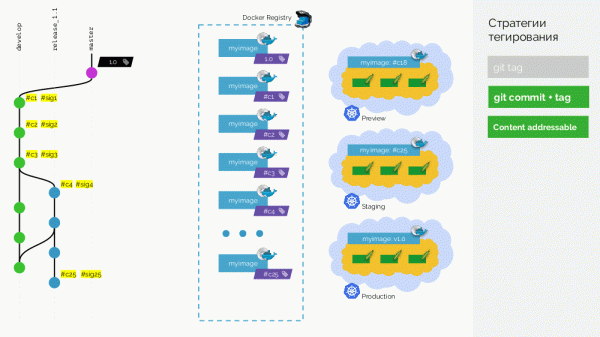
Теперь, когда потребуется, например, с’merge’ить изменения из релиза в master, мы можем делать настоящий merge commit: у него будет другой идентификатор, но та же сигнатура. С таким же идентификатором мы выкатим образ и на production.
Недостаток в том, что теперь не получится определить, что за коммит выкачен на production — контрольные суммы работают только в одну сторону. Эта проблема решается дополнительным слоем с метаданными — подробнее расскажу дальше.
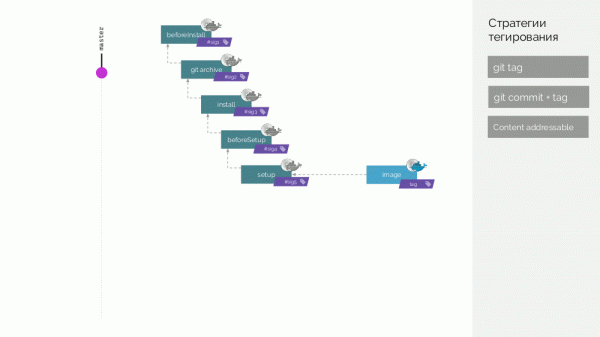
Тегирование в werf
В werf мы пошли ещё дальше и готовимся сделать распределённую сборку с кэшем, который не хранится на одной машине… Итак, у нас собираются Docker-образы двух типов, мы называем их stage и image.
В Git-репозитории werf хранятся специфичные инструкции для сборки, описывающие разные этапы сборки (beforeInstall, install, beforeSetup, setup). Первый stage-образ мы собираем с сигнатурой, определенной как контрольная сумма первых шагов. Затем добавляем исходный код, для нового stage-образа мы считаем его контрольную сумму… Эти операции повторяются для всех этапов, в результате чего мы получаем набор из stage-образов. Затем делаем финальный image-образ, содержащий также метаданные о его происхождении. И уже этот образ мы тегируем разными способами (подробности позже).

Пусть после этого появляется новый коммит, в котором изменили только код приложения. Что произойдет? Для изменений кода будет создан патч, подготовлен новый stage-образ. Его сигнатура будет определена как контрольная сумма старого stage-образа и нового патча. Из этого образа будет сформирован и новый финальный image-образ. Аналогичное поведение будет происходить при изменениях на других этапах.
Таким образом, stage-образы — кэш, который можно хранить распределенно, а уже создаваемые из него image-образы загружаются в Docker Registry.
Очистка registry
Речь пойдёт не про удаление слоёв, которые остались висящими после удалённых тегов, — это стандартная возможность самого Docker Registry. Речь о ситуации, когда накапливается множество Docker-тегов и мы понимаем, что некоторая их часть нам больше не требуется, а место они занимают (и/или мы за него платим).
Какие есть стратегии очистки?
- Можно просто ничего не чистить. Иногда действительно проще немного заплатить за лишнее пространство, чем распутывать огромный клубок из тегов. Но это работает лишь до определённого момента.
- Полный сброс. Если удалить все образы и пересобрать только актуальные в CI-системе, то может возникнуть проблема. Если на production перезапустится контейнер, для него загрузится новый образ — такой, что еще никем не тестировался. Это убивает идею immutable infrastructure.
- Blue-green. Один registry начал переполняться — загружаем образы в другой. Та же самая проблема, что в предыдущем способе: в какой момент можно очищать тот registry, что начал переполняться?
- По времени. Удалять все образы старше 1 месяца? Но обязательно найдётся сервис, который не обновлялся целый месяц…
- Вручную определять, что уже можно удалять.
По-настоящему жизнеспособных варианта два: не чистить или же комбинация из blue-green + вручную. В последнем случае речь о следующем: когда вы понимаете, что пора почистить registry, создаёте новый и добавляете все новые образы в него на протяжении, например, месяца. А через месяц смотрите, какие pod’ы в Kubernetes по-прежнему используют старый registry, и переносите их тоже в новый registry.
К чему мы пришли в werf? Мы собираем:
- Git head: все теги, все ветки, — предполагая, что всё, что протегировано в Git, нам нужно и в образах (а если нет, то надо удалить в самом Git’е);
- все pod’ы, которые выкачены сейчас в Kubernetes;
- старые ReplicaSet’ы (то, что недавно было выкачено), а также планируем сканировать Helm-релизы и отбирать последние образы там.
… и делаем из этого набора whitelist — список образов, которые мы не будем удалять. Всё остальное вычищаем, после чего находим сиротские stage-образы и удаляем их тоже.
Стадия деплоя (deploy)
Надёжная декларативность
Первый момент, на который хотелось бы обратить внимание в деплое, — выкат обновлённой конфигурации ресурсов, объявленной декларативно. Оригинальный YAML-документ с описанием Kubernetes-ресурсов всегда сильно отличается от результата, реально работающего в кластере. Потому что Kubernetes добавляет в конфигурацию:
- идентификаторы;
- служебную информацию;
- множество значений по умолчанию;
- секцию с текущим статусом;
- изменения, сделанные в рамках работы admission webhook;
- результат работы различных контроллеров (и планировщика).
Поэтому, когда появляется новая конфигурация ресурса (new), мы не можем просто взять и перезаписать ею текущую, «живую», конфигурацию (live). Для этого нам придётся сравнить new с прошлой примененённой конфигурацией (last-applied) и накатить на live полученный патч.
Такой подход называется 2-way merge. Он используется, например, в Helm.
Есть ещё и 3-way merge, который отличается тем, что:
- сравнивая last-applied и new, мы смотрим, что было удалено;
- сравнивая new и live, мы смотрим, что добавлено или изменёно;
- суммированный патч накладываем на live.
Мы деплоим 1000+ приложений с Helm, поэтому фактически живём с 2-way merge. Однако у него есть ряд проблем, которые мы решили своими патчами, помогающими Helm’у нормально работать.
Реальный статус выката
После того, как по очередному событию наша CI-система сгенерировала новую конфигурацию для Kubernetes, она передаёт её на применение (apply) в кластер — с помощью Helm или kubectl apply. Далее происходит уже описанный N-way merge, на что Kubernetes API одобрительно отвечает CI-системе, а та — своему пользователю.
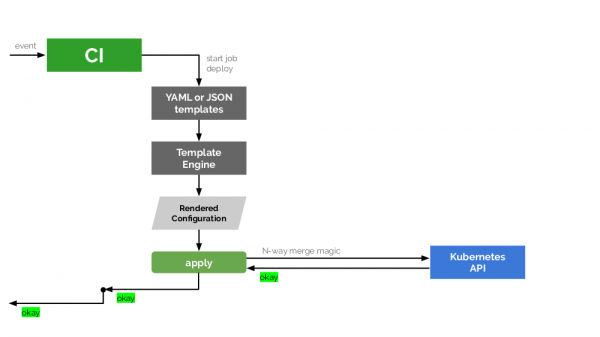
Однако есть огромная проблема: ведь успешное применение не означает успешный выкат. Если Kubernetes понял, что за изменения надо применить, применяет его — мы ещё не знаем, что получится в результате. Например, обновление и рестарт pod’ов во frontend’е может пройти успешно, а в backend’е — нет, и мы получим разные версии запущенных образов приложения.
Чтобы всё делать правильно, в этой схеме напрашивается дополнительное звено — специальный трекер, который будет получать от Kubernetes API информацию о статусе и передавать её для дальнейшего анализа реального положения вещей. Мы создали Open Source-библиотеку на Go — (см. её анонс ), — которая решает эту проблему и встроена в werf.
Поведение этого трекера на уровне werf настраивается с помощью аннотаций, которые ставятся на Deployments или StatefulSets. Главная аннотация — fail-mode — понимает следующие значения:
-
IgnoreAndContinueDeployProcess— игнорируем проблемы выката этого компонента и продолжаем деплой; -
FailWholeDeployProcessImmediately— ошибка в этом компоненте останавливает процесс деплоя; -
HopeUntilEndOfDeployProcess— надеемся, что этот компонент заработает к концу деплоя.
Например, такая комбинация из ресурсов и значений аннотации fail-mode:
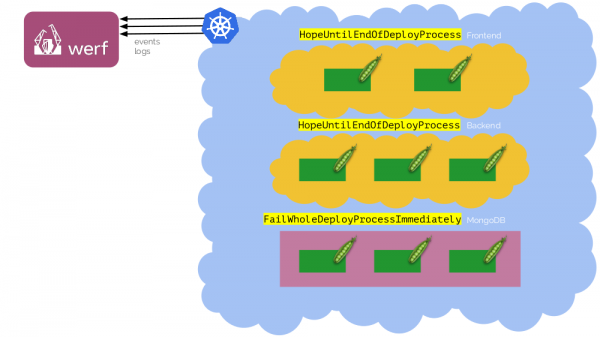
Когда деплоим в первый раз, база данных (MongoDB) ещё может быть не готова — Deployment’ы упадут. Но можно дождаться момента, чтобы она запустилась, и деплой всё же пройдёт.
Есть ещё две аннотации для kubedog в werf:
-
failures-allowed-per-replica— количество разрешённых падений на каждую реплику; -
show-logs-until— регулирует момент, до которого werf показывает (в stdout) логи из всех выкатываемых pod’ов. По умолчанию этоPodIsReady(чтобы игнорировать сообщения, которые нам вряд ли нужны, когда на pod начинает приходить трафик), однако допустимы также значенияControllerIsReadyиEndOfDeploy.
Что ещё мы хотим от деплоя?
Помимо уже описанных двух пунктов нам хотелось бы:
- видеть логи — причём только нужные, а не все подряд;
- отслеживать прогресс, потому что если job «молча» висит несколько минут, важно понимать, что там происходит;
- иметь автоматический откат на случай, если что-то пошло не так (а поэтому критично знать реальный статус деплоя). Выкат должен быть атомарным: или он проходит до конца, или всё возвращается к прежнему состоянию.
Итоги
Нам как компании для реализации всех описанных нюансов на разных этапах доставки (build, publish, deploy) достаточно CI-системы и утилиты .
Вместо заключения:

С помощью werf мы неплохо продвинулись в решении большого числа проблем DevOps-инженеров и будем рады, если более широкое сообщество хотя бы попробует эту утилиту в деле. Добиться хорошего результата вместе будет проще.
Видео и слайды
Видео с выступления (~47 минут):

Презентация доклада:
P.S.
Другие доклады про Kubernetes в нашем блоге:
- «» (Дмитрий Столяров; 27 апреля 2019 на «Стачке»);
- «» (Андрей Половов; 8 апреля 2019 на Saint HighLoad++);
- «» (Дмитрий Столяров; 8 ноября 2018 на HighLoad++);
- «» (Дмитрий Столяров; 28 мая 2018 на RootConf);
- «» (Дмитрий Столяров; 7 ноября 2017 на HighLoad++);
- «» (Дмитрий Столяров; 6 июня 2017 на RootConf).
Источник: habr.com
