

В публикациях на Хабре я уже писал о своем опыте построения партнерских отношений со своей командой ( рассказывается о том, как составить партнерское соглашение при старте нового бизнеса, чтобы бизнес не развалился). А сейчас я бы хотел рассказать о том, как строить партнерские отношения с клиентами, так как без них разваливаться будет нечему. Я надеюсь эта статья будет полезна стартапам, начинающим продажи своего продукта крупному бизнесу.
Я сейчас как раз возглавляю такой стартап MONQ Digital lab, где мы с командой разрабатываем продукт по автоматизации процессов поддержки и эксплуатации корпоративного ИТ. Выход на рынок очень не простая задача и мы начали с небольшой домашней работы, прошли по экспертам рынка, нашим партнерам и провели сегментацию рынка. Основным вопросом было понять “чьи боли мы лучше всего можем излечить?”
В ТОП3 сегментов попали банки. И конечно же первым в списке были Тинькофф и Сбербанк. Когда мы ходили по экспертам банковского рынка они говорили: внедрите свой продукт туда, и путь на рынок банков будет открыт. Мы попробовали войти и туда, и туда, но в Сбербанке нас ждал провал, а ребята из Тинькофф оказались на порядок более открытыми к продуктивному общению с российскими стартапами (может быть из-за того, что Сбер в это время почти за миллиард наших западных конкурентов). Уже через месяц мы начали пилотный проект. Как это было, читайте дальше.
Мы много лет занимаемся вопросами эксплуатации и мониторинга, сейчас внедряем наш продукт в госсекторе, в страховании, в банках, в телеком-компаниях, одно внедрение было у авиакомпании (перед проектом, мы и не думали, что авиация настолько ИТ-зависимая отрасль, и сейчас очень надеемся, несмотря на COVID, что компания выплывет и пойдет на взлет).
Тот продукт, который мы делаем относится к корпоративному ПО, сегменту AIOps (Artificial Intelligence for IT Operations, или ITOps). Основные цели внедрения таких систем по мере повышения уровня зрелости процессов в компании:
- Потушить пожары: выявить сбои, очистить поток алертов от мусора, поставить таски и инциденты на ответственных;
- Повысить эффективность работы ИТ-службы: снизить время решения инцидентов, указать на причины сбоев, повысить прозрачность состояния ИТ;
- Повысить эффективность бизнеса: сократить объем ручного труда, снизить риски, повысить лояльность клиентов.
По нашему опыту, у банков общие со всеми крупными IT-инфраструктурами “боли” с мониторингом следующие:
- “кто во что горазд”: техотделов много, практически у каждого как минимум одна своя система мониторинга, а у большинства — больше одной;
- “комариный рой” алертов: каждая система генерирует сотни и бомбит ими всех ответственных (иногда еще и между отделами). Постоянно держать фокус контроля на каждом уведомлении сложно, их срочность и важность нивелируется из-за большого количества;
- крупные банки — лидеры сектора хотят не просто непрерывно мониторить свои системы, знать, где есть сбои, но и настоящей магии AI — сделать так, чтобы системы самомониторились, самопрогнозировали и самоисправлялись.
Когда мы пришли на первую встречу в Тинькофф, нам сразу сказали, что у них нет проблем с мониторингом и у них ничего не болит, и основным вопросом было: “Что мы можем предложить для тех, у которых и так все хорошо?”
Разговор был длинный, мы обсудили как построены их микросервисы, как работают подразделения, какие проблемы инфраструктуры более чувствительны, какие менее чувствительны для пользователей, где “белые пятна”, и какие у них цели и SLA.
Кстати, SLA у банка действительно впечатляют. Например, на устранение инцидента первого приоритета, связанного с сетевой доступностью, дается всего несколько минут. Цена ошибки и простоя тут, конечно, внушительная.
В итоге мы выявили несколько направлений сотрудничества:
- первый этап — зонтичный мониторинг, для повышения скорости решения инцидентов
- второй этап — автоматизация процессов для снижения рисков и снижение затрат на масштабирование ИТ-подразделения.
Несколько “белых пятен” можно было раскрасить в яркие цвета алертов, только обработав информацию из нескольких систем мониторинга, так как напрямую снять метрики было нельзя, также нужна была централизация данных из разных систем мониторинга на “один экран”, чтобы понимать общую картину происходящего. Для этой задачи подходят “зонтики” и мы удовлетворяли тогда этим требованиям.
Очень важная штука, на наш взгляд, во взаимоотношениях с клиентами — это честность. После первого разговора и расчета стоимости лицензии было сказано, раз стоимость такая невысокая, может сразу стоит купить лицензию (по сравнению с Dynatrace Ключ-Астром из статьи выше про зеленый банк, наша лицензия стоит не треть от миллиарда, а 12 тысяч рублей в месяц за 1 гигабайт, для Сбера она обошлась бы в разы дешевле). Но мы сразу сказали им, что у нас есть и что нет. Быть может сейл из крупного интегратора мог бы сказать “да мы все можем, конечно купите нашу лицензию”, но мы решили выложить все карты на стол. В нашей коробке на момент старта не было интеграции с Prometheus, а также новая версия с подсистемой автоматизации должна была вот-вот выйти, но клиентам мы ее еще не отгружали.
Начался пилотный проект, были определены его границы и нам дали 2 месяца. Основные задачи были:
- подготовить новую версию платформы и развернуть ее в инфраструктуре банка
- подключить 2 системы мониторинга (Zabbix и Prometheus);
- отправлять оповещения ответственным в Slack и по СМС;
- запускать скрипты автохилинга.
Первый месяц пилотного проекта у нас ушел на подготовку новой версии платформы в супербыстром режиме для нужд пилотного проекта. В новую версию сразу вошла интеграция с Prometheus и автохилинг. Спасибо нашей команде разработки, они не спали несколько ночей, но выпустили обещанное без срыва сроков по другим взятым ранее обязательствам.
Пока настраивали пилот столкнулись с новой проблемой, которая могла закрыть проект досрочно: для отправки оповещений в мессенджеры и по СМС нам нужны входящие и исходящие соединения с серверами Microsoft Azure (на тот момент мы использовали данную платформу для отсылки оповещений в Slack) и внешним сервисом отправки СМС. Но в этом проекте безопасность была в особом фокусе внимания. В соответствия с политикой банка такие “дырки” не могли быть открыты ни при каких условиях. Все должно было работать из закрытого контура. Нам предложили использовать API собственных внутренних сервисов, которые отправляют оповещения в Slack и по СМС, но у нас не было возможности подключить такие сервисы из коробки.
Вечер дебатов с командой разработки закончился успешным поиском решения. Поковыряв бэклог мы нашли одну задачу, на которую никогда не хватало времени и приоритета — сделать плагинную систему, чтобы команды внедрения или клиент сами могли писать дополнения, расширяя возможности платформы.
Но у нас оставался ровно месяц, за который надо было все установить, настроить и развернуть автоматизацию.
По оценке Сергея, нашего главного архитектора, на внедрение плагинной системы нужен минимум месяц.
Мы не успевали…
Решение было одно — идти к клиенту и все рассказывать, как есть. Вместе обсуждать сдвиг сроков. И это сработало. Нам дали дополнительно 2 недели. У них тоже были свои сроки и внутренние обязательства показать результаты, но были 2 недели резервные. В итоге мы все поставили на карту. Нельзя было опростоволоситься. Честность и партнерский подход опять дал свои плоды.
В результате пилота получили несколько важных технических результатов и выводов:
Опробовали новый функционал обработки алертов
Развернутая система начала правильно принимать алерты из Prometheus и производить их группировку. Алерты по проблеме из Prometheus клиента летели каждые 30 секунд (не включена группировка по времени), и нам было интересно, можно ли их будет группировать в самом “зонтике”. Оказалось, что можно — настройка обработки алертов в платформе реализована скриптом. Это дает возможность реализации практически любой логики их обработки. Стандартную логику мы уже реализовали в платформе в виде шаблонов — если нет желания придумывать что-то свое, можно воспользоваться готовым.
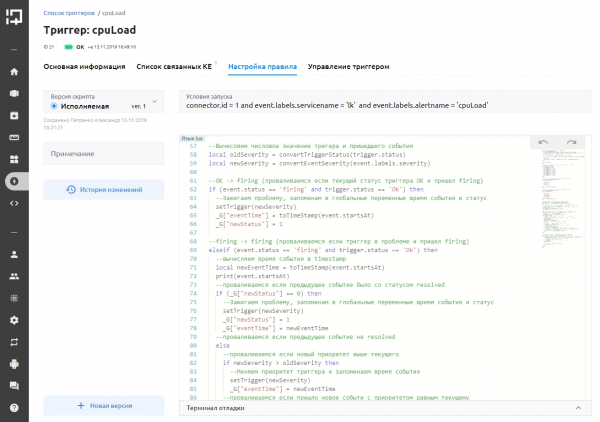
Интерфейс “синтетического триггера”. Настройка обработки алертов из подключенных систем мониторинга
Построили состояние «здоровья» системы
По алертам создавались события мониторинга, влияющие на здоровье конфигурационных единиц (КЕ). Мы реализуем ресурсно-сервисную модель (РСМ), которая может использовать либо внутреннюю CMDB, либо подключить внешнюю — на пилотном проекте клиент свою CMDB не подключал.
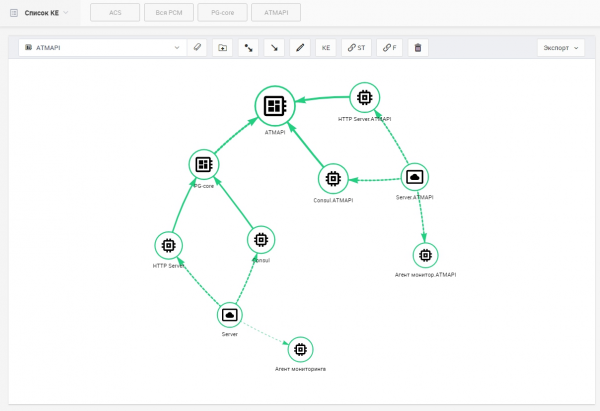
Интерфейс работы с ресурсно-сервисной моделью. Пилотная РСМ.
Ну и, собственно, у клиента появился, наконец, единый экран мониторинга, где видно события из разных систем. На текущий момент к “зонтику” подключено две системы — Zabbix и Prometheus, и внутренняя система мониторинга самой платформы.
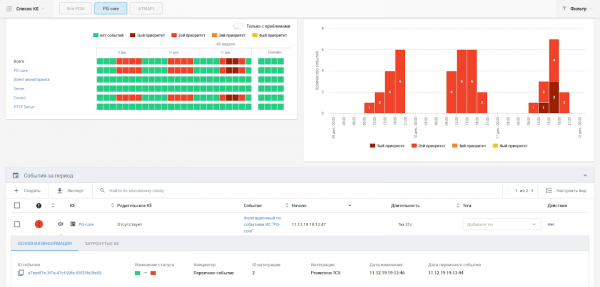
Интерфейс аналитики. Единый экран мониторинга.
Запустили автоматизацию процессов
События мониторинга инициировали запуск преднастроенных действий — отправку оповещений, запуск скриптов, регистрацию/обогащение инцидентов — последнее не попробовали именно с этим клиентом, т.к. в пилотном проекте не было интеграции с сервисдеском.
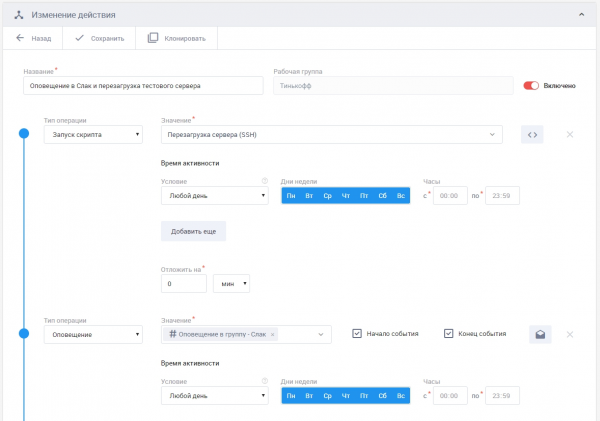
Интерфейс настройки действий. Отправка оповещений в Slack и перезагрузка сервера.
Расширили функционал продукта
При обсуждении скриптов автоматизации клиент просил поддержку bаsh и интерфейс, в котором эти скрипты можно было бы удобно настраивать. В новой версии было сделано чуть больше (возможность написания полноценных логических конструкций на Lua с поддержкой cURL, SSH и SNMP) и реализован функционал, позволяющий управлять жизненным циклом скрипта (создавать, редактировать, управлять версиями, удалять и архивировать).
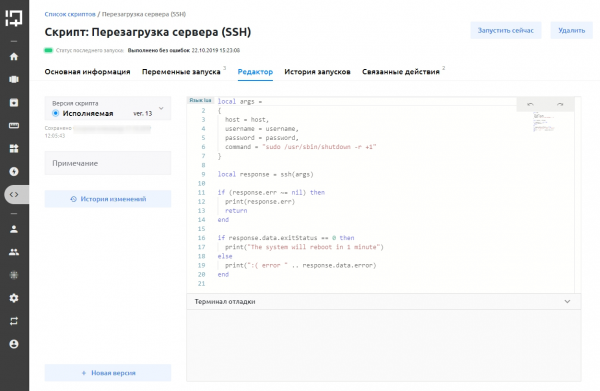
Интерфейс работы со скриптами автохилинга. Скрипт перезагрузки сервера по SSH.
Основные выводы
Во время пилота также были сформированы юзерсторис, которые улучшают текущий функционал и повышают ценность для клиента, вот некоторые из них:
- реализовать возможность проброса переменных непосредственно из аллерта в скрипт автохилинга;
- добавить на платформе авторизацию через Active Directory.
И получили более глобальные вызовы для нас — “нарастить” продукт другими возможностями:
- автопостроением ресурсно-сервисной модели на основе ML, а не правил и агентов (наверное, главный вызов сейчас);
- поддержкой дополнительных языков скриптования и логики (и это будет JavaScript).
На мой взгляд, самое главное, что показывает данный пилот, это две вещи:
- Партнерские отношения с клиентом — залог эффективности, когда на базе честности и открытости строится эффективная коммуникация, и клиент становится частью команды, которая за короткие сроки добивается значительных результатов.
- Ни при каких условиях не надо “кастомить” и строить “костыли” — только системные решения. Лучше потратить чуть больше времени, но сделать системное решение, которое будет использоваться и у других клиентов. Кстати, так и вышло, плагинная система и отказ от зависимости с Azure, дали дополнительную ценность и другим клиентам (привет, 152ой ФЗ).
Источник: habr.com
