

Компания Meta/Facebook (запрещена в РФ) представила новый звуковой кодек EnCodec, использующий методы машинного обучения для повышения степени сжатия без потери качества. Кодек может применять как для потоковой передачи звука в режиме реального времени, так и для кодирования для последующего сохранения в файлах. Эталонная реализация EnCodec написана на языке Python с использованием фреймворка PyTorch и распространяется под лицензией CC BY-NC 4.0 (Creative Commons Attribution-NonCommercial), допускающей использование только в некоммерческих целях.
Для загрузки предложены две готовые модели:
- Каузальная модель, использующая частоту дискретизации 24 kHz, поддерживающая только монофонический звук и натренированная на разноплановых звуковых данных (подходит для кодирования речи). Модель может использоваться для упаковки звуковых данных для передачи с битрейтами 1.5, 3, 6, 12 и 24 kbps.
- Некаузальная модель, использующая частоту дискретизации 48 kHz, поддерживающая стереозвук и натренированная только на музыке. Моделью поддерживаются битрейты 3, 6, 12 и 24 kbps.
Для каждой модели подготовлена дополнительная языковая модель, позволяющая добиться значительного увеличения степени сжатия (до 40%) без потери качества. В отличие от ранее развиваемых проектов по применению методов машинного обучения для сжатия звука, EnCodec может применяться не только для упаковки речи, но и для сжатия музыки с частотой дискретизации 48 kHz, соответствующей уровню звуковых CD. По заявлению разработчиков нового кодека при передаче с битрейтом 64 kbps по сравнению с форматом MP3 им удалось примерно в десять раз увеличить степень сжатия звука с сохранением того же уровня качества (например, когда при использовании MP3 требуется полоса пропускания в 64 kbps, для передачи с тем же качеством в EnCodec достаточно 6 kbps).
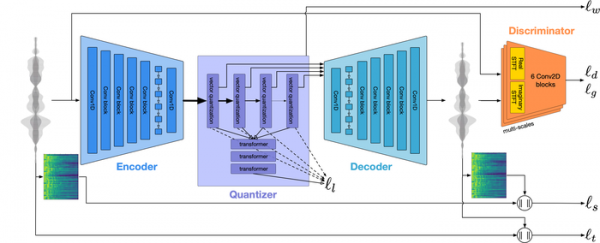
Архитектура кодека построена на базе нейронной сети с архитектурой «трансформер» и основывается на четырёх звеньях: кодировщика, квантователя, декодировщика и дискриминатора. Кодировщик извлекает параметры голосовых данных и преобразует их упакованный поток с более низкой частотой кадров. Квантователь (RVQ, Residual Vector Quantizer) преобразует выдаваемый кодировщиком поток в наборы пакетов, сжимая информацию в привязке к выбранному битрейту. На выходе квантователя образуется сжатое представление данных, пригодное для передачи по сети или сохранения на диск.
Декодировщик раскодирует сжатое представление данных и восстанавливает исходную звуковую волну. Дискриминатор улучшает качество генерируемых образцов (sample) с учётом модели человеческого слухового восприятия. Независимо от уровня качества и битрейта применяемые для кодирования и декодирования модели отличаются достаточно скромными требованиями к ресурсам (вычисления, необходимые для работы в режиме реального времени, производятся на одном ядре CPU).
Источник: opennet.ru
