

Хороший сервис для заказа такси должен быть безопасным, надёжным и быстрым. Пользователь не станет вдаваться в детали: ему важно, чтобы он нажал кнопку «Заказать» и как можно быстрее получил машину, которая доставит его из точки А в точку Б. Если рядом нет машин — сервис должен сразу об этом сообщить, чтобы у клиента не складывалось ложных ожиданий. Но если плашка «Нет машин» будет высвечиваться слишком часто, то логично, что человек просто перестанет пользоваться этим сервисом и уйдёт к конкуренту.
В этой статье я хочу рассказать о том, как при помощи машинного обучения мы решали задачу поиска машин на территории с малой плотностью (проще говоря — там, где, на первый взгляд, нет машин). И что из этого вышло.
Предыстория
Чтобы вызвать такси, пользователь совершает несколько простых действий, а что при этом происходит во внутренностях сервиса?
| Пользователь | Этап | Бэкенд Яндекс.Такси |
|---|---|---|
| Выбирает точку отправления | Пин | Запускаем упрощённый поиск кандидатов — поиск на пине. На основе найденных водителей предсказывается время приезда — ETA в пине. Рассчитывается повышающий коэффициент в данной точке. |
| Выбирает точку назначения, тариф, требования | Оффер | Строим маршрут и рассчитываем цены на все тарифы с учётом повышающего коэффициента. |
| Нажимает кнопку «Вызвать такси» | Заказ | Запускаем полноценный поиск машины. Выбираем наиболее подходящего водителя и предлагаем ему заказ. |
Про , и мы уже писали. А это история о поиске водителей. Когда создаётся заказ, поиск происходит два раза: на пине и на заказе. Поиск на заказе проходит в два этапа: набор кандидатов и ранжирование. Сначала находятся свободные водители-кандидаты, ближайшие по дорожному графу. Потом применяются бонусы и фильтрации. Оставшиеся кандидаты ранжируются, и победителю приходит предложение заказа. Если он соглашается, то назначается на заказ и едет к точке подачи. Если отказывается, то предложение приходит следующему. Если кандидатов больше нет, то поиск запускается заново. Это продолжается не более трёх минут, после чего заказ отменяется — сгорает.
Поиск на пине похож на поиск на заказе, только заказ не создаётся и сам поиск выполняется лишь один раз. Также используются упрощённые настройки числа кандидатов и радиуса поиска. Такие упрощения нужны, потому что пинов на порядок больше, чем заказов, а поиск — довольно тяжёлая операция. Ключевой момент для нашей истории: если во время предварительного поиска на пине подходящих кандидатов не нашлось, то мы не разрешаем сделать заказ. По крайней мере, раньше было так.
Вот что видел пользователь в приложении:
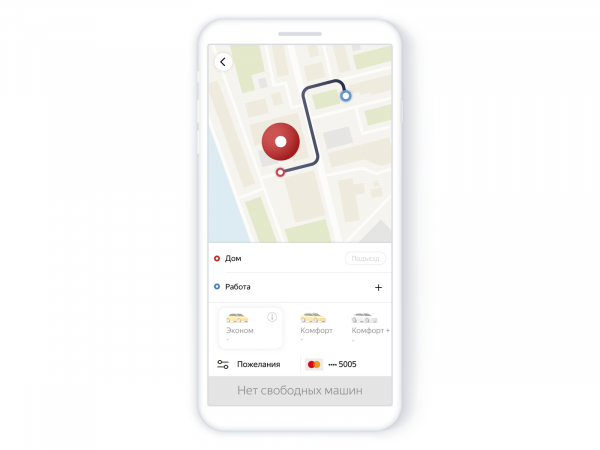
Поиск машин без машин
Однажды у нас появилась гипотеза: возможно, в некоторых случаях заказ всё же можно выполнить, даже если на пине не нашлось машин. Ведь между пином и заказом проходит какое-то время, а поиск на заказе более полный и иногда повторяется несколько раз: за это время свободные водители могут появиться. Ещё мы знали обратное: если водители нашлись на пине, то ещё не факт, что они найдутся при заказе. Порой они исчезают или все отказываются от заказа.
Чтобы проверить эту гипотезу, мы запустили эксперимент: перестали проверять наличие машин во время поиска на пине для тестовой группы пользователей, т. е. у них появилась возможность сделать «заказ без машин». Результат получился довольно неожиданным: если машина не находилась на пине, то в 29% случаев она находилась позже — при поиске на заказе! Более того, заказы без машин не сильно отличались от обычных по частоте отмен, оценкам и прочим показателям качества. Число заказов без машин составило 5% всех заказов, но чуть более 1% всех успешных поездок.
Чтобы понять, откуда берутся исполнители этих заказов, посмотрим на их статусы во время поиска на пине:
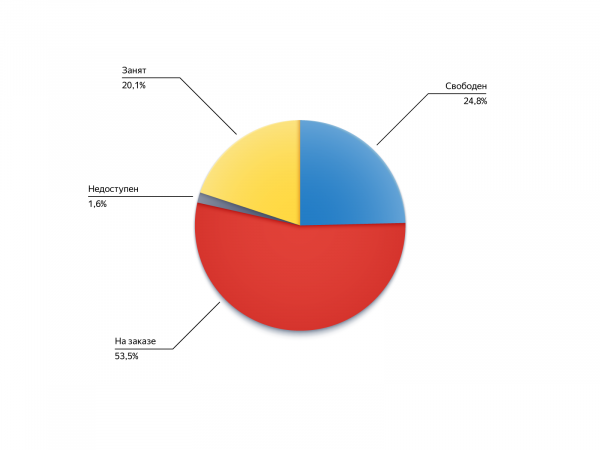
- Свободен: был доступен, но по каким-то причинам не попал в кандидаты, например был слишком далеко;
- На заказе: был занят, но успел освободиться или стать доступным для ;
- Занят: возможность принимать заказы была отключена, но потом водитель вернулся на линию;
- Недоступен: водителя не было в сети, но он появился.
Добавим надёжности
Дополнительные заказы — это замечательно, однако 29% успешных поисков означают, что в 71% случаев пользователь долго ждал и в итоге никуда не уехал. Хотя с точки зрения эффективности системы в этом нет ничего ужасного, но на самом деле, пользователь получает ложную надежду и тратит время, после чего расстраивается и (возможно) перестаёт пользоваться сервисом. Чтобы решить эту проблему, мы научились предсказывать вероятность того, что машина на заказе будет найдена.
Схема такая:
- Пользователь ставит пин.
- Проводится поиск на пине.
- Если машин нет — предсказываем: может быть, они появятся.
- И в зависимости от вероятности даём или не даём сделать заказ, но предупреждаем, что плотность машин в этом районе и в это время маленькая.
В приложении это выглядело так:
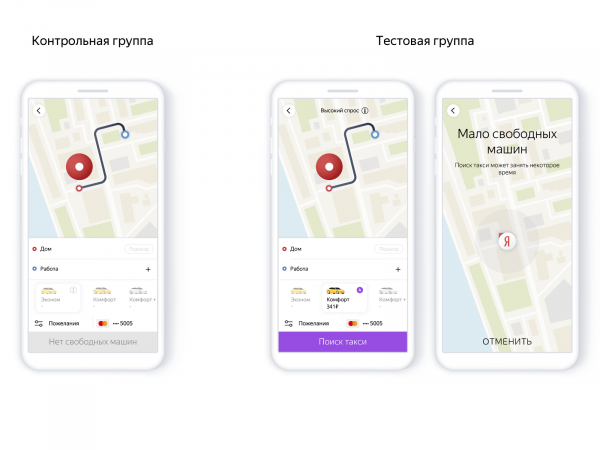
Использование модели позволяет аккуратней создавать новые заказы, не обнадёживать человека напрасно. То есть регулировать соотношение надёжности и числа заказов без машин с помощью precision-recall модели. Надёжность сервиса влияет на желание и дальше пользоваться продуктом, т. е. в итоге всё сводится к числу поездок.
Немного про precision-recallОдна из базовых задач в машинном обучении — задача классификации: отнести объект к одному из двух классов. При этом результатом работы алгоритма машинного обучения часто становится числовая оценка принадлежности к одному из классов, например оценка вероятности. Однако действия, которые совершаются, обычно бинарные: если машина будет — то даём заказать, а если нет — то нет. Для определённости назовём моделью алгоритм, который выдаёт числовую оценку, а классификатором — правило, которое относит к одному из двух классов (1 или –1). Чтобы на основе оценки модели сделать классификатор, нужно подобрать порог оценки. Как именно — сильно зависит от задачи.
Предположим, мы делаем тест (классификатор) на какую-то редкую и опасную болезнь. По результатам теста мы или отправляем пациента на более подробное обследование, или говорим: «Здоров, иди домой». Для нас отправить домой больного человека гораздо хуже, чем зря обследовать здорового. То есть мы хотим, чтобы тест срабатывал для как можно большего количества реально больных людей. Эта величина называется recall = . У идеального классификатора recall равен 100%. Вырожденная ситуация — отправлять на обследование всех, тогда recall тоже будет 100%.
. У идеального классификатора recall равен 100%. Вырожденная ситуация — отправлять на обследование всех, тогда recall тоже будет 100%.
Бывает и наоборот. Например, мы делаем тестирующую систему для студентов, и в ней есть детектор списывания. Если вдруг на какие-то случаи списывания не сработает проверка, то это неприятно, но не критично. С другой стороны, крайне плохо незаслуженно обвинять студентов в том, чего они не совершали. То есть нам важно, чтобы среди положительных ответов классификатора было как можно больше правильных, возможно, в ущерб их количеству. Значит, нужно максимизировать precision =  . Если срабатывания станут происходить на всех объектах, то precision будет равен частоте определяемого класса в выборке.
. Если срабатывания станут происходить на всех объектах, то precision будет равен частоте определяемого класса в выборке.
Если алгоритм выдаёт числовое значение вероятности, то, подбирая разные пороги, можно добиться разных значений precision-recall.
В нашей задаче ситуация следующая. Recall — число заказов, которое мы можем предложить, precision — надёжность этих заказов. Вот так выглядит precision-recall кривая нашей модели:
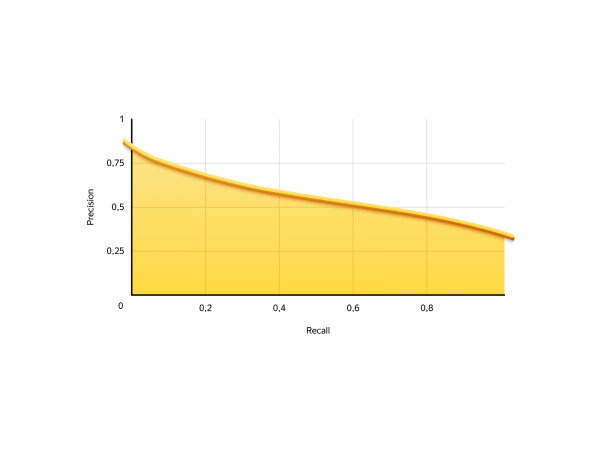
Есть два крайних случая: не разрешать заказывать никому и разрешать заказывать всем. Если не разрешать никому, то recall будет 0: мы не создаём заказов, но зато никакой из них не станет провальным. Если разрешать всем, то recall будет 100% (мы получим все возможные заказы), а precision — 29%, т. е. 71% заказов окажутся плохими.
В качестве признаков мы использовали различные параметры точки отправления:
- Время/место.
- Состояние системы (число занятых машин всех тарифов и пинов в окрестности).
- Параметры поиска (радиус, число кандидатов, ограничения).
Подробнее о признаках
Концептуально мы хотим различить две ситуации:
- «Глухой лес» — машин тут в это время не бывает.
- «Не повезло» — машины есть, но вот при поиске подходящих не оказалось.
Один из примеров «Не повезло» — если в пятницу вечером в центре большой спрос. Заказов много, желающих много, водителей на всех не хватает. Может получиться так: в пине подходящих водителей нет. Но буквально через секунды они появляются, потому что в это время в этом месте очень много водителей и их статус постоянно меняется.
Поэтому хорошими фичами оказались различные показатели системы в окрестностях точки А:
- Общее число машин.
- Число машин на заказе.
- Число недоступных для заказа машин в статусе «Занят».
- Число пользователей.
Ведь чем больше вокруг машин, тем более вероятно, что какая-нибудь из них станет доступна.
На самом деле для нас важно, чтобы не просто находились машины, но и совершались успешные поездки. Поэтому можно было предсказывать вероятность успешной поездки. Но решили так не делать, потому что эта величина сильно зависит от пользователя и водителя.
В качестве алгоритма обучения модели применяли . Для обучения использовали данные, полученные из эксперимента. После внедрения пришлось собирать обучающие данные, иногда позволяя небольшому числу пользователей делать заказ вопреки решению модели.
Итоги
Результаты эксперимента получились ожидаемыми: использование модели позволяет значимо увеличить число успешных поездок за счёт заказов без машин, но при этом не просадить надёжность.
На данный момент механизм запущен во всех городах и странах и с его помощью происходит около 1% успешных поездок. Причём в некоторых городах с небольшой плотностью машин доля таких поездок доходит до 15%.
Другие посты о технологиях Такси
Источник: habr.com
