

Недавно вышла , которая неплохо показывает тенденцию в машинном обучении последних лет. Если коротко: число стартапов в области машинного обучения в последние два года резко упало.
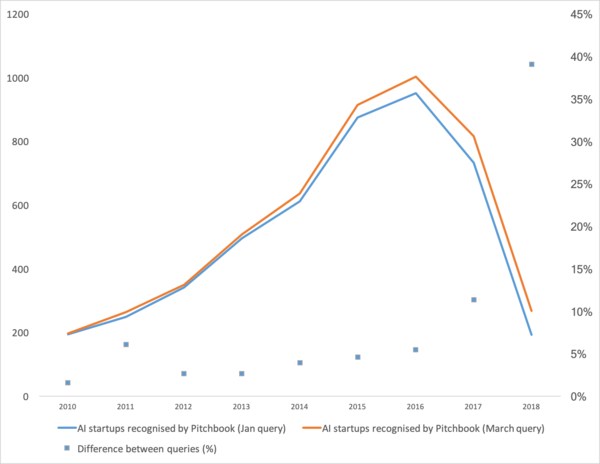
Ну что. Разберём «лопнул ли пузырь», «как дальше жить» и поговорим откуда вообще такая загогулина.
Для начала поговорим что было бустером этой кривой. Откуда она взялась. Наверное всё вспомнят машинного обучения в 2012 году на конкурсе ImageNet. Ведь это первое глобальное событие! Но в реальности это не так. Да и рост кривой начинается несколько раньше. Я бы разбил его на несколько моментов.
- 2008 год это появление термина “большие данные”. Реальные продукты начали с 2010 года. Большие данные прямо связаны с машинным обучением. Без больших данных невозможна стабильная работа алгоритмов, которые существовали на тот момент. И это не нейронные сети. До 2012 года нейронные сети — это удел маргинального меньшинства. Зато тогда начали работать совершенно другие алгоритмы, которые существовали уже годы, а то и десятилетия: (1963,1993 годы), (1995), (2003),… Стартапы тех годов в первую очередь связаны с автоматической обработкой структурированных данных: кассы, пользователи, реклама, многое другое.
Производная этой первой волны — набор фреймворков, таких как XGBoost, CatBoost, LightGBM, и.т.д.
- В 2011-2012 году выиграли ряд конкурсов по распознаванию изображений. Реальное их использование несколько затянулось. Я бы сказал что массово осмысленные стартапы и решения начали появляться с 2014 года. Два года понадобилось чтобы переварить что нейронки всё-таки работают, сделать удобные фреймворки которые можно было поставить и запустить за разумное время, разработать методы которые бы стабилизировали и ускорили время схождения.
Свёрточные сети позволили решать задачи машинного зрения: классификация изображений и объектов на изображении, детектирование объектов, распознавание объектов и людей, улучшение изображений, и.т.д., и.т.п.
- 2015-2017 годы. Бум алгоритмов и проектов завязанных на рекуррентные сети или их аналоги (LSTM, GRU, TransformerNet и.т.д.). Появились хорошо работающие алгоритмы “речь-в-текст”, системы машинного перевода. Частично они основаны на свёрточных сетях для выделения базовых фич. Частично на том что научились собирать реально большие и хорошие датасеты.
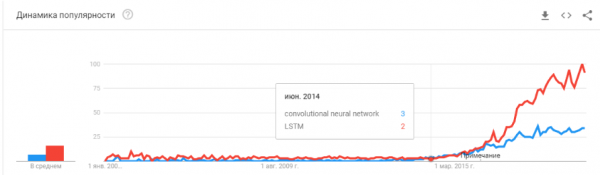
“Пузырь лопнул? Хайп перегрет? Они умерли как блокчейн?”
А то ж! Завтра в вашем телефоне перестанет работать Сири, а послезавтра Тесла не отличит поворот от кенгуру.
Нейронные сети уже работают. Они в десятках устройств. Они реально позволяют зарабатывать, изменяют рынок и окружающий мир. Хайп выглядит несколько иначе:
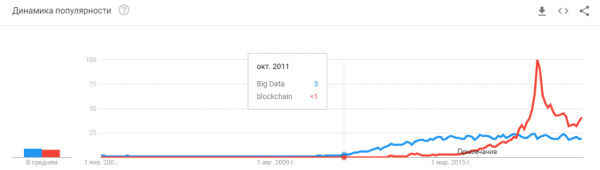
Просто нейронные сети перестали быть чем-то новым. Да, у многих людей есть завышенные ожидания. Но большое число компаний научилось применять у себя нейронки и делать продукты на их основе. Нейронки дают новый функционал, позволяют сократить рабочие места, снизить цену услуг:
- Производственные компании интегрируют алгоритмы для анализа брака на конвейере.
- Животноводческие хозяйства покупают системы для контроля коров.
- Автоматические комбайны.
- Автоматизированные Call-центры.
- Фильтры в SnapChat. (ну хоть что-то дельное!)
Но главное, и не самое очевидное: “Новых идей больше нет, или они не принесут мгновенного капитала”. Нейронные сети решили десятки проблем. И решат ещё больше. Все очевидные идеи которые были — породили множество стартапов. Но всё что было на поверхности — уже собрали. За последние два года я не встречал ни одной новой идеи для применения нейронных сетей. Ни одного нового подхода (ну, ок, там немного с GAN-ами есть заморочек).
А каждый следующий стартап всё сложнее и сложнее. Он требует уже не двух парней которые обучают нейронку на открытых данных. Он требует программистов, сервера, команду разметчиков, сложную поддержку, и.т.д.
Как результат — стартапов становится меньше. А вот продакшна больше. Нужно приделать распознавание автомобильных номеров? На рынке сотни специалистов с релевантным опытом. Можно нанять и за пару месяцев ваш сотрудник сделает систему. Или купить готовую. Но делать новый стартап?.. Безумие!
Нужно сделать систему трекинга посетителей — зачем платить за кучу лицензий, когда можно за 3-4 месяца сделать свою, заточить её для своего бизнеса.
Сейчас нейронные сети проходят тот же путь который прошли десятки других технологий.
Помните как менялось с 1995 года понятие «разработчик сайтов»? Пока рынок не насыщен специалистами. Профессионалов очень мало. Но я могу поспорить, что через 5-10 лет не будет особой разницы между программистом Java и разработчиком нейронных сетей. И тех и тех специалистов будет достаточно на рынке.
Просто будет класс задач под который решается нейронками. Возникла задача — нанимаете специалиста.
“А что дальше? Где обещанный искусственный интеллект?”
А вот тут есть небольшая, но интересная непонятчка:)
Тот стек технологий, который есть сегодня, судя по всему, нас к искусственному интеллекту всё же не приведёт. Идеи, их новизна — во многом исчерпали себя. Давайте поговорим о том что держит текущий уровень развития.
Ограничения
Начнём с авто-беспилотников. Вроде как понятно, что сделать полностью автономные автомобили при сегодняшних технологиях — возможно. Но через сколько лет это случится — не понятно. Tesla считает что это произойдет через пару лет —

Есть много других , которые оценивают это как 5-10 лет.
Скорее всего, на мой взгляд, лет через 15 инфраструктура городов уже сама изменится так, что появление автономных автомобилей станет неизбежным, станет её продолжением. Но ведь это нельзя считать интеллектом. Современная Тесла — это очень сложный конвейер по фильтрации данных, их поиску и переобучению. Это правила-правила-правила, сбор данных и фильтры над ними (вот я чуть подробнее про это написал, либо смотреть с отметки).
Первая проблема
И именно тут мы видим первую фундаментальную проблему. Большие данные. Это именно то, что породило текущую волну нейронных сетей и машинного обучения. Сейчас, чтобы сделать что-то сложное и автоматическое нужно много данных. Не просто много, а очень-очень много. Нужны автоматизированные алгоритмы их сбора, разметки, использования. Хотим сделать чтобы машина видела грузовики против солнца — надо сначала собрать достаточное их число. Хотим чтобы машина не сходила с ума от велосипеда прикрученного к багажнику — больше семплов.
Причём одного примера не хватит. Сотни? Тысячи?

Вторая проблема
Вторая проблема — визуализация того что наша нейронная сеть поняла. Это очень нетривиальная задача. До сих пор мало кто понимает как это визуализировать. Вот эти статьи весьма свежие, это всего лишь несколько примеров, пусть даже отдалённых:
зацикленности на текстурах. Хорошо показывает, на чём нейронка склонна зацикливаться + что она воспринимает как отправную информацию.

аттеншна при . Реально аттеншн часто можно использовать именно для того чтобы показать что вызвало такую реакцию сети. Я встречал такие штуки и для дебага и для продуктовых решений. На эту тему очень много статей. Но чем сложнее данные, тем сложнее понять как добиться устойчивой визуализации.

Ну и да, старый добрый набор из «посмотри что у сетки внутри в ». Эти картинки были популярны года 3-4 назад, но все быстро поняли, что картинки то красивые, да смысла в них не много.
Я не назвал десятки других примочек, способов, хаков, исследований о том как отобразить внутренности сети. Работают ли эти инструменты? Помогают ли они быстро понять в чём проблема и отладить сеть?.. Вытащить последние проценты? Ну, примерно вот так же:

Можете посмотреть любой конкурс на Kaggle. И описание того как народ финальные решения делает. Мы настакали 100-500-800 мульёнов моделек и оно заработало!
Я, конечно, утрирую. Но быстрых и прямых ответов эти подходы не дают.
Обладая достаточным опытом, потыкав разные варианты можно выдать вердикт о том почему ваша система приняла такое решение. Но поправить поведение системы будет сложно. Поставить костыль, передвинуть порог, добавить датасет, взять другую backend-сеть.
Третья проблема
Третья фундаментальная проблема — сетки учат не логику, а статистику. Статистически это :

Логически — не очень похоже. Нейронные сети не учат что-то сложное, если их не заставляют. Они всегда учат максимально простые признаки. Есть глаза, нос, голова? Значит это лицо! Либо приводи пример где глаза не будут означать лицо. И опять — миллионы примеров.
There’s Plenty of Room at the Bottom
Я бы сказал, что именно эти три глобальных проблемы на сегодняшний день и ограничивают развитие нейронных сетей и машинного обучения. А то где эти проблемы не ограничивали — уже активно используется.
Это конец? Нейронные сети встали?
Неизвестно. Но, конечно, все надеются, что нет.
Есть много подходов и направлений к решению тех фундаментальных проблем которые я осветил выше. Но пока ни один из этих подходов не позволил сделать что-то фундаментально новое, решить что-то, что до сих пор не решалось. Пока что все фундаментальные проекты делаются на основе стабильных подходов (Tesla), или остаются тестовыми проектами институтов или корпораций (Google Brain, OpenAI).
Если говорить грубо, то основное направление — создание некоторого высокоуровневого представления входных данных. В каком-то смысле “памяти”. Самый простой пример памяти — это различные “Embedding” — представления изображений. Ну, например, все системы распознавания лиц. Сеть учится получить из лица некоторое стабильное представление которое не зависит от поворота, освещения, разрешения. По сути сеть минимизирует метрику “разные лица — далеко” и “одинаковые — близко”.
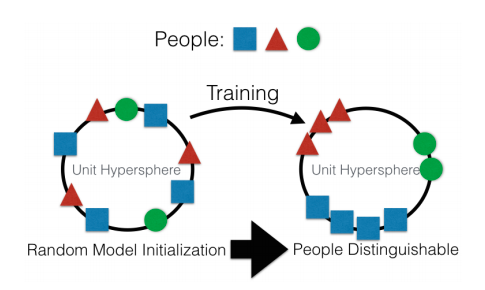
Для такого обучения нужны десятки и сотни тысяч примеров. Зато результат несёт некоторые зачатки “One-shot Learning”. Теперь нам не нужно сотни лиц чтобы запомнить человека. Всего лишь одно лицо, и всё — мы !
Только вот проблемка… Сетка может выучить только достаточно простые объекты. При попытке различать не лица, а, например, “людей по одежде” (задача ) — качество проваливается на много порядков. И сеть уже не может выучить достаточно очевидные смены ракурсов.
Да и учиться на миллионах примеров — тоже как-то так себе развлечение.
Есть работы по значительному уменьшению выборов. Например, сходу можно вспомнить одну из первых работ по OneShot Learning :
Таких работ много, например или или .
Минус один — обычно обучение неплохо работает на каких-то простых, “MNIST’овских примерах”. А при переходе к сложным задачам — нужна большая база, модель объектов, или какая-то магия.
Вообще работы по One-Shot обучению — это очень интересная тема. Много идей находишь. Но большей частью те две проблемы что я перечислил (предобучение на огромном датасете / нестабильность на сложных данных) — очень мешают обучению.
С другой стороны к теме Embedding подходят GAN — генеративно состязательные сети. Вы наверняка читали на Хабре кучу статей на эту тему. (, ,)
Особенностью GAN является формирование некоторого внутреннего пространства состояний (по сути того же Embedding), которое позволяет нарисовать изображение. Это могут быть , могут быть .
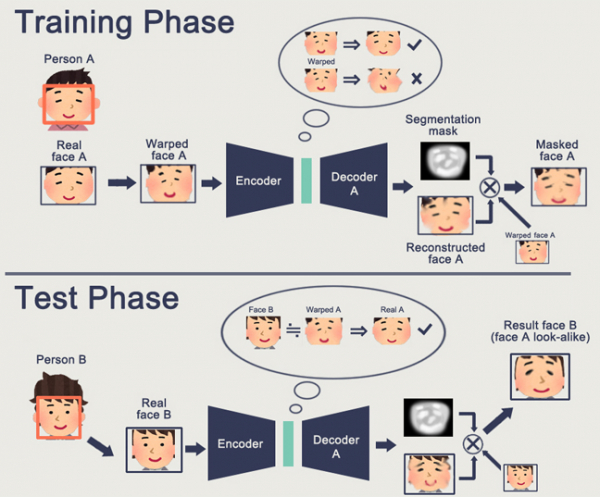
Проблема GAN — чем сложнее генерируемый объект, тем сложнее описывать его в логике “генератор-дискриминатор”. В результате из реальных применений GAN, которые на слуху -только DeepFake, который опять же, манипулирует с представлениями лиц (для которых существует огромная база).
Других полезных применений я встречал очень мало. Обычно какие-то свистелки-перделки с дорисовыванием картинок.
И опять же. Ни у кого нет понимания как это позволит нам двинуться в светлое будущее. Представление логики/пространства в нейронной сети — это хорошо. Но нужно огромное число примеров, нам непонятно как нейронка в себе это представляет, нам непонятно как заставить нейронку запомнить какое-то реально сложное представление.
Reinforcement learning — это заход совсем с другой стороны. Наверняка вы помните как Google обыграл всех в Go. Недавние победы в Starcraft и в Dota. Но тут всё далеко не так радужно и перспективно. Лучше всего про RL и его сложности рассказывает .
Если кратко просуммировать что писал автор:
- Модели из коробки не подходят/работают в большинстве случаев плохо
- Практические задачи проще решить другими способами. Boston Dynamics не использует RL из-за его сложности/непредсказуемости/сложности вычислений
- Чтобы RL заработал — нужна сложная функция. Зачастую её сложно создать/написать
- Сложно обучать модели. Приходится тратить кучу времени чтобы раскачать и вывести из локальных оптимумов
- Как следствие — сложно повторить модель, неустойчивость модели при малейших изменениях
- Часто оверфитится на какие-нибудь левые закономерности, вплоть до генератора случайных чисел
Ключевой момент — RL пока что не работает в продакшне. У гугла есть какие-то эксперименты ( , ). Но я не видел ни одной продуктовой системы.
Memory. Минус всего того что описано выше — неструктурированность. Один из подходов как всё это пытаются прибрать — предоставить нейронной сети доступ к отдельной памяти. Чтобы она могла записывать и перезаписывать там результаты своих шагов. Тогда нейронная сеть может определяться текущим состоянием памяти. Это очень похоже на классические процессоры и компьютеры.
Самая известная и популярная — от DeepMind:
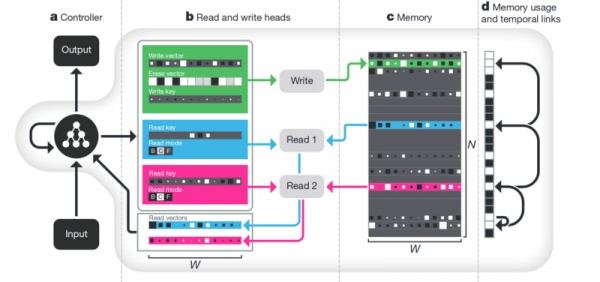
Кажется что вот он, ключ к пониманию интеллекта? Но скорее нет. Системе всё равно требуется огромный массив данных для тренировки. А работает она в основном со структурированными табличными данными. При этом когда Facebook аналогичную проблему, то они пошли по пути “нафиг память, просто сделаем нейронку посложнее, да примеров побольше — и она сама обучится”.
Disentanglement. Другой способ создать значимую память — это взять те же самые эмбединги, но при обучении ввести дополнительные критерии, которые бы позволили выделять в них “смыслы”. Например мы хотим обучить нейронную сеть различать поведение человека в магазине. Если бы мы шли по стандартному пути — мы должны были бы сделать десяток сетей. Одна ищет человека, вторая определяет что он делает, третья его возраст, четвертая — пол. Отдельная логика смотрит часть магазина где он делает/обучается на это. Третья определяет его траекторию, и.т.д.
Или, если бы было бесконечно много данных, то можно было бы обучить одну сеть на всевозможные исходы (очевидно, что такой массив данных набрать нельзя).
Дизэнтелгмент подход говорит нам — а давайте обучать сеть так чтобы она сама смогла различать понятия. Чтобы она по видео сформировала эмбединг, где одна область определяла бы действие, одна — позицию на полу во времени, одна — рост человека, а ещё одна — его пол. При этом при обучении хотелось бы почти не подсказывать сети такие ключевые понятия, а чтобы она сама выделяла и группировала области. Таких статей достаточно мало (некоторые из них , , ) и в целом они достаточно теоретические.
Но данное направление, по крайней мере теоретически, должно закрывать перечисленные в начале проблемы.
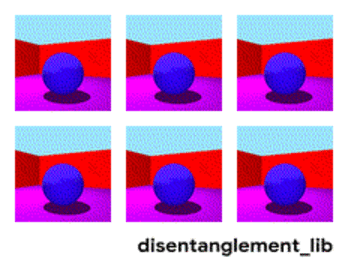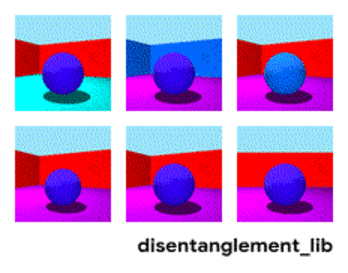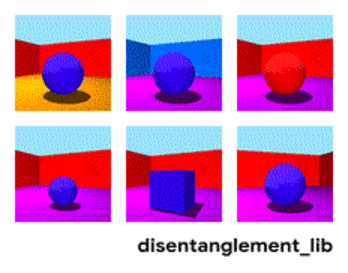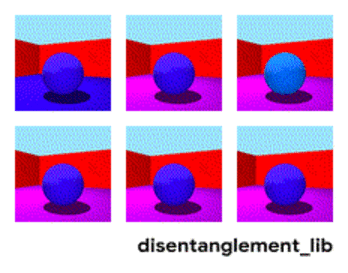
Разложение изображения по параметрам “цвет стен/цвет пола/форма объекта/цвет объекта/и.т.д.”

Разложение лица по параметрам “размер, брови, ориентация, цвет кожи, и.т.д.”
Прочее
Есть много других не столько глобальных направлений, которые позволяют как-то уменьшать базы, работать с более разнородными данными, и.т.д.
Attention. Наверное, не имеет смысла выделять это как отдельный метод. Просто подход, усиливающий другие. Ему посвящено много статей (,,). Смысл Attention в том, чтобы усилить у сети реакцию именно на значимые объекты при обучении. Зачастую каким-нибудь внешним целеуказанием, или небольшой внешней сетью.
3Д-симуляция. Если сделать хороший 3д движок, то им зачастую можно закрыть 90% обучающих данных (я даже видел пример когда почти 99% данных закрывалось хорошим движком). Есть много идей и хаков как заставить сеть обученную на 3д движке работать по реальным данным (Fine tuning, style transfer, и.т.д.). Но зачастую сделать хороший движок — на несколько порядков сложнее чем набрать данные. Примеры когда делали движки:
Обучение роботов (, )
Обучение товаров в магазине (но в двух проектах которые делали мы — мы спокойно обходились без этого).
Обучение в Tesla (опять же то видео что было выше).
Выводы
Вся статья это в каком-то смысле выводы. Наверное, основной посыл который я хотел сделать — «халява кончилась, нейронки не дают больше простых решений». Теперь надо вкалывать строя сложные решения. Или вкалывать делая сложные научные ресёрчи.
А вообще тема дискутабельная. Может у читателей есть более интересные примеры?
Источник: habr.com
