

Группа исследователей из американских, австралийских и израильских университетов предложила новую технику атаки по сторонним каналам для эксплуатации уязвимостей класса Spectre в браузерах на базе движка Chromium. Атака, которая получила кодовое имя Spook.js, позволяет через запуск JavaScript-кода обойти механизм изоляции сайтов и прочитать содержимое всего адресного пространства текущего процесса, т.е. получить доступ к данным страниц, запущенных в других вкладках, но обрабатываемых в одном процессе.
Так как Chrome запускает разные сайты в разных процессах, то возможность совершения практических атак ограничена сервисами, позволяющими разным пользователям размещать свои страницы. Метод позволяет со страницы, в которую атакующий имеет возможность встроить свой JavaScript-код, определить наличие других открытых пользователем страниц с того же сайта и извлечь из них конфиденциальную информацию, например, учётные данные или банковские реквизиты, подставленные системой автозаполнения полей в web-формах. В качестве демонстрации показано как можно атаковать чужой блог в сервисе Tumblr, если его владелец откроет в другой вкладке блог злоумышленников, размещённый в том же сервисе.
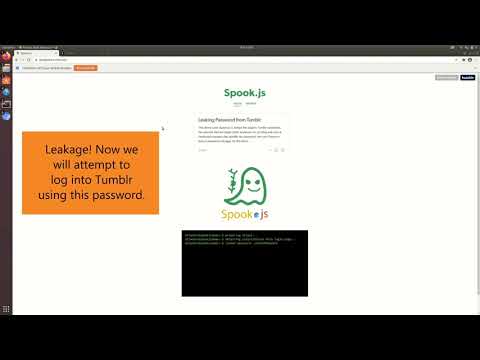
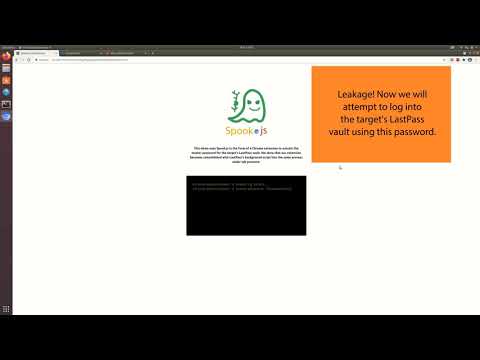
Другим вариантом применения метода является атака на браузерные дополнения, позволяющая при установке дополнения, подконтрольного атакующим, извлечь данные из других дополнений. В качестве примера показано как установив вредоносное дополнение можно извлечь конфиденциальную информацию из менеджера паролей LastPass.
Исследователями опубликован прототип эксплоита, работающий в Chrome 89 на системах с CPUIntel i7-6700K и i7-7600U. При создании эксплоита использованы ранее опубликованные компанией Google прототипы JavaScript-кода для совершения атак класса Spectre. Отмечается, что исследователям удалось подготовить рабочие эксплоиты для систем на базе процессоров Intel и Apple M1, которые даются возможность организовать чтение памяти со скоростью 500 байт в секунду и точностью 96%. Предполагается, что метод применим и для процессоров AMD, но полностью работоспособный эксплоит подготовить не удалось.
Атака применима к любым браузерам на базе движка Chromium, включая Google Chrome, Microsoft Edge и Brave. Исследователи также полагают, что метод можно адаптировать для работы с Firefox, но так как движок Firefox сильно отличается от Chrome, то работа по созданию подобного эксплоита оставлена на будущее.
Для защиты от осуществления через браузер атак, связанных со спекулятивным выполнением инструкций, в Chrome реализовано сегментирование адресного пространства — sandbox-изоляция допускает работу JavaScript только с 32-разрядными указателями и разделяет память обработчиков в непересекающихся 4ГБ кучах (heap). Для организации доступа к всему адресному пространству процесса и обхода 32-разрядного ограничения исследователи задействовали технику Type Confusion, позволяющую вынудить JavaScript-движок обработать объект с некорректным типом, что даёт возможность сформировать 64-разрядный указатель на основе комбинации из двух 32-разрядных значений.
Суть атаки в том, что при обработке специально оформленного вредоносного объекта в JavaScript-движке создаются условия, приводящие к спекулятивному исполнению инструкций, осуществляющих доступ к массиву. Объект подбирается таким образом, что контролируемые атакующими поля размещаются в области, где используется 64-разрядный указатель. Так как тип вредоносного объекта не соответствует типу обрабатываемого массива, в обычных условиях подобные действия блокируется в Chrome механизмом деоптимизации кода, применяемого для доступа к массивам. Для решения данной проблемы код для атаки Type Confusion выносится в условный блок «if», который не активируется при обычных условиях, но выполняется в спекулятивном режиме, при неверном предсказании процессором дальнейшего ветвления.
В итоге процессор спекулятивно обращается к сформированному 64-разрядному указателю и откатывает состояние после определения неудачного прогноза, но следы выполнения оседают в общем кэше и могут быть восстановлены при помощи методов определения содержимого кэша по сторонним каналам, анализирующих изменение времени доступа к прокэшированным и не прокэшированным данным. Для анализа содержимого кэша в условиях недостаточной точности таймера, доступного в JavaScript, применяется предложенный Google метод, обманывающий применяемую в процессорах стратегию вытеснения данных из кэша Tree-PLRU и позволяющий за счёт увеличения числа циклов значительно увеличить разницу во времени при наличии и отсутствии значения в кэше.
Источник: opennet.ru
