


Сегодня мы запускаем научную премию имени Ильи Сегаловича . Она будет присуждаться за достижения в области компьютерных наук. Студенты и аспиранты или выдвинуть научных руководителей. Лауреатов выберут представители академического сообщества и Яндекса. Главные критерии отбора: наличие публикаций и выступлений на конференциях, а также вклад в развитие сообщества.
Первое награждение состоится уже в апреле. В рамках премии молодые учёные получат по 350 тысяч рублей, а кроме того, смогут поехать на международную конференцию, поработать с ментором и пройти стажировку в отделе исследований Яндекса. Научные руководители получат по 700 тысяч рублей.
По случаю запуска премии мы решили рассказать здесь, на Хабре, о критериях успеха в мире компьютерных наук. Часть читателей Хабра уже знакомы с этими критериями, а у остальных могло сложиться о них ложное впечатление. Сегодня мы устраним этот разрыв — коснёмся всех основных тем, включая статьи, конференции, датасеты и перенос научных идей в сервисы.
Для учёных в области computer science основной критерий успеха — публикация своей научной работы на одной из топовых международных конференций. Это первый «чекпоинт» признания работы исследователя. Например, в области машинного обучения в целом выделяют International Conference on Machine Learning (ICML) и Conference on Neural Information Processing Systems (NeurIPS, ранее NIPS). Есть множество конференций по отдельным сферам ML, таким как компьютерное зрение, информационный поиск, речевые технологии, машинный перевод и т. д.
Зачем публиковать свои идеи
У далёких от computer science людей может сложиться заблуждение, что лучше держать самые ценные идеи в секрете и стремиться получить выгоду на их уникальности. Однако реальная ситуация в нашей сфере ровно обратная. Об авторитете учёного судят по значимости его работ, по тому, как часто на его статьи ссылаются другие учёные (индекс цитируемости). Это важная характеристика его карьеры. Исследователь продвигается по профессиональной лестнице, становясь более уважаемым в своей среде, только если он постоянно выдаёт сильные работы, которые публикуются, становятся известными и ложатся в основу работ других учёных.
Многие топовые статьи (а возможно, и большинство) — результат коллаборации исследователей в разных университетах и компаний в разных странах мира. Важным и очень ценным в карьере исследователя является момент, когда он получает возможность находить и отсеивать идеи самостоятельно на основе своего опыта — но даже после этого коллеги продолжают оказывать ему неоценимую помощь. Учёные помогают друг другу прорабатывать идеи, пишут статьи в соавторстве — и чем больше вклад учёного в науку, тем проще ему найти единомышленников.
Наконец, плотность и доступность информации сейчас настолько велика, что у разных исследователей одновременно появляются очень похожие (и действительно ценные) научные идеи. Если идею не опубликовать, кто-то почти наверняка опубликует её за вас. «Победителем» часто оказывает не тот, кто придумал новшество чуть раньше, а тот, кто чуть раньше его опубликовал. Либо — тот, кто сумел раскрыть идею максимально полно, понятно и убедительно.
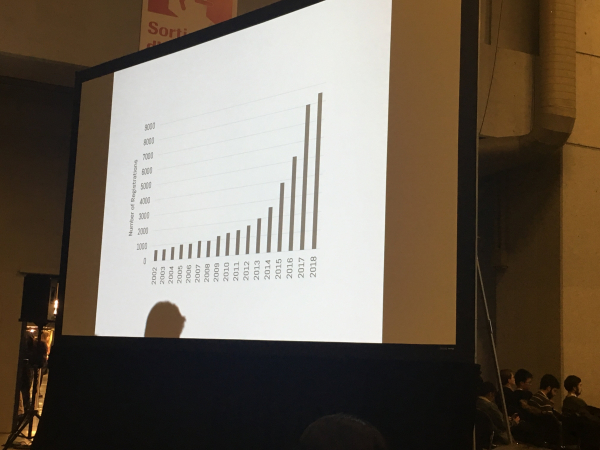
Статьи и наборы данных
Итак, научная статья строится вокруг основной идеи, которую исследователь предлагает. Эта идея — его вклад в компьютерные науки. Статья начинается с описания идеи, сформулированного в нескольких предложениях. Затем следует вступление, где описывается спектр проблем, решаемых с помощью предлагаемого новшества. Описание и вступление обычно пишутся простым языком, понятным для широкой аудитории. После вступления необходимо уже математическим языком формализовать изложенные проблемы, ввести строгие обозначения. Затем с помощью введённых обозначений нужно составить внятное и исчерпывающее изложение сути предлагаемого новшества, обозначить отличия от предыдущих, схожих методов. Все теоретические выкладки необходимо либо подкреплять ссылками на ранее составленные доказательства, либо доказывать самостоятельно. Это может быть сделано с какими-нибудь предположениями. Например, можно привести доказательство для случая, когда данных в обучении бесконечно много (очевидно недостижимая ситуация) или они полностью независимы друг от друга. Ближе к концу статьи учёный рассказывает об экспериментальных результатах, которые ему удалось получить.
Чтобы рецензенты, которых привлекли организаторы конференции, с большей вероятностью одобрили статью, она должна обладать одним или несколькими атрибутами. Ключевой фактор, увеличивающий шансы на одобрение, — научная новизна предлагаемой идеи. Часто новизна оценивается относительно уже существующих идей — причём работу по её оценке выполняет не рецензент, а сам автор статьи. В идеальном случае автор должен развёрнуто рассказать в статье о существующих методах и, если это возможно, представить их как частные случаи своего метода. Тем самым учёный показывает, что принятые подходы работают не всегда, что он их обобщил и предложил более широкую, гибкую и потому более эффективную теоретическую постановку. Если новизна неоспорима, то в остальном рецензенты оценивают статью не так придирчиво — например, могут закрыть глаза на плохой английский.
Чтобы подкрепить новизну, полезно добавить в статью сравнение с существующими методами на одном или нескольких наборах данных. Каждый из них должен быть открытым, принятым в академической среде. К примеру, есть репозиторий изображений ImageNet и базы таких институтов, как Modified National Institute of Standards and Technology (MNIST) и CIFAR (Canadian Institute For Advanced Research). Сложность в том, что подобный «академический» датасет часто отличается по структуре содержимого от реальных данных, с которыми имеет дело индустрия. Разные данные — разные результаты предлагаемого метода. Учёные, частично работающие на индустрию, стараются учитывать это и иногда вставляют оговорки вида «на наших данных результат такой-то, а на общедоступном датасете — такой-то».
Бывает, что предлагаемый метод полностью «затачивается» под открытую базу и не работает на реальных данных. Бороться с этой распространённой проблемой можно, открывая новые, более репрезентативные датасеты, но часто речь идёт о приватном контенте, который компании просто не имеют права открыть. В некоторых случаях они проводят (порой сложную и кропотливую) анонимизацию данных — удаляют любые фрагменты, указывающие на конкретного человека. Например, лица и номера на фотографиях стирают или делают неразборчивыми. Кроме того, чтобы датасет не просто был доступен всем, а стал стандартом среди учёных, на котором удобно сравнивать идеи, необходимо не только опубликовать его, но и написать о нём и его преимуществах отдельную цитируемую статью.
Хуже, когда в исследуемой теме отсутствуют открытые датасеты. Тогда рецензенту остаётся принять на веру приведённые автором результаты. Теоретически, автор даже может завысить их и остаться непойманным, но в академической среде это маловероятно, поскольку идёт вразрез со стремлением подавляющего большинства учёных развивать науку.
В ряде областей ML, включая компьютерное зрение, также принято прикреплять к статьям ссылки на код (обычно — на GitHub). В самих статьях кода либо очень мало, либо это псевдокод. И тут, опять же, возникают сложности, если статья пишется исследователем из компании, а не из университета. По умолчанию код, написанный в корпорации или стартапе, носит гриф NDA. Исследователям и их коллегам приходится прилагать немало усилий, чтобы отделить код, относящийся к описываемой идее, от внутренних и уж точно закрытых репозиториев.
Шанс на публикацию зависит и от актуальности выбранной темы. Актуальность во многом диктуется продуктами и сервисами: если корпорация или стартап заинтересованы в том, чтобы на основе идеи из статьи построить новый сервис или улучшить существующий, — это плюс.
Как уже говорилось, статьи по компьютерным наукам крайне редко пишутся в одиночку. Но как правило, один из авторов тратит гораздо больше времени и сил, чем остальные. Его вклад в научную новизну — наибольший. В списке авторов такого человека указывают первым — и в дальнейшем, ссылаясь на статью, могут упоминать только его (например, «Ivanov et al» — «Иванов и другие» в переводе с латыни). Однако вклад остальных также является крайне ценным — иначе невозможно оказаться в списке авторов.
Процесс рецензирования
Статьи обычно перестают принимать за несколько месяцев до конференции. После отправки статьи у рецензентов есть 3–5 недель на то, чтобы прочитать, оценить и прокомментировать её. Это происходит по системе single blind, когда авторы не видят имена рецензентов, или double blind, когда и сами рецензенты не видят имена авторов. Второй вариант считается более беспристрастным: в нескольких научных работах было показано, что популярность автора влияет на решение рецензента. Например, он может посчитать, что учёный с большим количеством уже опубликованных статей априори достоин более высокой оценки.
При этом даже в случае double blind рецензент наверняка угадает автора, если они работают в одной сфере. Кроме того, статья на момент прохождения ревью уже может быть опубликована в базе arXiv — крупнейшем репозитории научных работ. Организаторы конференций этого не запрещают, однако рекомендуют в публикации для arXiv использовать другое название и другую аннотацию. Но если статья была там размещена, найти её всё равно не составит труда.
Рецензентов, оценивающих статью, всегда несколько. Одному из них отводится роль метарецензента, который должен только просмотреть вердикты своих коллег и принять финальное решение. Если рецензенты разошлись в оценке статьи, метарецензент для полноты картины тоже может её прочитать.
Иногда, просмотрев оценку и комментарии, автор получает возможность вступить в дискуссию с рецензентом; есть даже шанс убедить его поменять решение (однако такая система работает далеко у не всех конференций, а всерьёз повлиять на вынесенный вердикт удаётся ещё гораздо реже). В дискуссии нельзя ссылаться на другие научные работы, за исключением тех, ссылки на которые в статье уже есть. Можно только «помочь» рецензенту лучше понять содержимое статьи.
Конференции и журналы
Статьи по компьютерным наукам чаще отправляют именно на конференции, чем в научные журналы. Причина в том, что к публикациям в журналах предъявляется требования, которые сложнее соблюсти, а процесс рецензирования может длиться месяцы и даже годы. Компьютерные науки — очень быстро развивающаяся отрасль, поэтому авторы обычно не готовы ждать публикации так долго. Однако статью, уже принятую на конференцию, можно затем дополнить (например, привести более развёрнутые результаты) и опубликовать в журнале, где ограничения по объёму не настолько жёсткие.
События на конференции
Формат присутствия авторов одобренных статей на конференции определяют рецензенты. Если статье дан зелёный свет, то вам чаще всего выделяют стенд для постера. Постер — это статичный слайд с кратким изложением статьи и иллюстрациями. Часть залов конференции наполняют длинными рядами стендов для постеров. Значительную часть времени автор проводит около своего постера, общаясь с учёными, которые заинтересовались статьёй.


Чуть более престижный вариант участия — это быстрый доклад (lightning talk). Если рецензенты посчитали статью достойной быстрого доклада, автору даётся около трёх минут на выступление перед широкой аудиторией. С одной стороны, lightning talk — хорошая возможность рассказать о своей идее не только тем, кто по собственной инициативе заинтересовался постером. С другой, инициативные посетители постера более подготовлены, сильнее погружены в вашу конкретную тему, чем среднестатический слушатель в зале. Поэтому в быстром докладе надо ещё успеть ввести людей в курс дела.

Обычно в конце своего lightning talk авторы называют номер постера — чтобы слушатели могли найти его и лучше разобраться в статье.

Последний, самый престижный вариант — это постер плюс полноценная презентация идеи, когда уже не нужно так спешить с рассказом.
Но конечно, учёные — включая авторов одобренных статей — приезжают на очередную конференцию не только себя показать. Во-первых, они по очевидным причинам стремятся найти постеры, относящиеся к своей области. И во-вторых, им важно пополнить список контактов с целью совместной академической работы в будущем. Это не хантинг — или, по крайней мере, самая первая его стадия, за которой как минимум следует взаимовыгодный обмен идеями, наработками и совместная работа над одной или несколькими статьями.
В то же время продуктивный нетворкинг на топовой конференции затруднителен из-за тотального отсутствия свободного времени. Если после целого дня, проведённого на докладах и в дискуссиях у постеров, учёный сохранил силы и уже поборол джетлаг, то он отправляется на одну из многочисленных вечеринок. Их устраивают корпорации — как следствие, вечеринки часто носят более хантинговый характер. При этом многие гости пользуются ими совсем не для того, чтобы найти новую работу, а, опять же, для нетворкинга. Вечером уже нет докладов и постеров — легче «поймать» интересующего вас специалиста.

От идеи до продакшена
Компьютерные науки — одна из считанных отраслей, где интересы корпораций и стартапов сильно связаны с академической средой. На NIPS, ICML и другие подобные конференции приезжают множество специалистов из индустрии, а не только из университетов. Для сферы computer science это типично, а для большинства других наук — наоборот.
С другой стороны, далеко не все изложенные в статьях идеи немедленно идут на создание или улучшение сервисов. Даже внутри одной компании исследователь может предложить коллегам из сервиса прорывную по научным меркам идею и получить отказ на внедрение по целому ряду причин. Об одной из них здесь уже упоминалось — это разница между «академическим» набором данных, по которому написана статья, и реальным датасетом. Кроме того, внедрение идеи может затянуться, потребовать большого количества ресурсов или улучшить только какой-нибудь один показатель ценой ухудшения остальных метрик.

Ситуацию спасает то, что многие разработчики и сами немного исследователи. Они посещают конференции, говорят с академиками на одном языке, предлагают идеи, порой участвуют в создании статей (например — в написании кода) или даже сами выступают авторами. Если разработчик погружён в академический процесс, следит за происходящим в отделе исследований, словом — если он демонстрирует встречное движение к учёным, то цикл превращения научных идей в новые возможности сервисов сокращается.
Мы желаем всем молодым исследователям удачи и крупных достижений в их работе. Если вам этот пост не рассказал ничего нового, то вы, возможно, уже публиковались на топовой конференции. Регистрируйтесь на сами и номинируйте научных руководителей.
Источник: habr.com
