


2017. godine pobijedili smo na konkursu za razvoj transakcionog jezgra investicionog poslovanja Alfa-Bank i počeli sa radom (na HighLoad++ 2018. sa izvještajem o srži investicionog poslovanja Vladimir Drynkin, rukovodilac transakcionog jezgra investicionog poslovanja Alfa banke). Ovaj sistem je trebao agregirati podatke o transakcijama iz različitih izvora u različitim formatima, dovesti podatke u jedinstvenu formu, pohraniti ih i omogućiti im pristup.
Tokom procesa razvoja, sistem je evoluirao i stekao funkcionalnost, a u nekom trenutku smo shvatili da kristalizujemo nešto mnogo više od samo aplikativnog softvera kreiranog za rešavanje strogo definisanog spektra zadataka: uspeli smo sistem za izgradnju distribuiranih aplikacija sa trajnim skladištenjem. Iskustvo koje smo stekli formiralo je osnovu za novi proizvod - (TDG).
Želim govoriti o TDG arhitekturi i rješenjima do kojih smo došli tokom procesa razvoja, upoznati vas sa glavnom funkcionalnošću i pokazati kako naš proizvod može postati osnova za izgradnju cjelovitih rješenja.
Arhitektonski smo sistem podijelili na zasebne uloge, od kojih je svaki odgovoran za rješavanje određenog niza problema. Jedna pokrenuta instanca aplikacije implementira jedan ili više tipova uloga. U klasteru može postojati nekoliko uloga istog tipa:
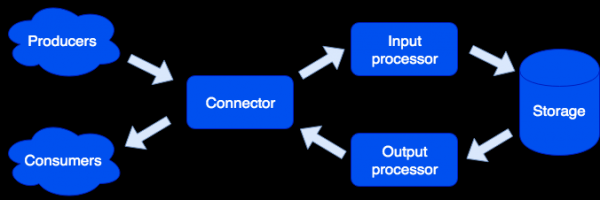
konektor
Connector je odgovoran za komunikaciju sa vanjskim svijetom; njegov zadatak je da prihvati zahtjev, raščlani ga i ako to uspije, zatim pošalje podatke na obradu ulaznom procesoru. Podržavamo HTTP, SOAP, Kafka, FIX formate. Arhitektura vam omogućava da jednostavno dodate podršku za nove formate, uz podršku za IBM MQ uskoro. Ako raščlanjivanje zahtjeva nije uspjelo, konektor će vratiti grešku; u suprotnom će odgovoriti da je zahtjev uspješno obrađen, čak i ako je došlo do greške tokom njegove dalje obrade. To je učinjeno posebno kako bi se radilo sa sistemima koji ne znaju kako ponavljati zahtjeve - ili, naprotiv, to rade previše uporno. Kako se podaci ne bi izgubili, koristi se red za popravku: objekt prvo ulazi u njega i tek nakon uspješne obrade se uklanja iz njega. Administrator može primati upozorenja o objektima koji su ostali u redu za popravku i nakon eliminisanja softverske greške ili hardverskog kvara, pokušajte ponovo.
Ulazni procesor
Ulazni procesor klasifikuje primljene podatke prema karakteristikama i poziva odgovarajuće procesore. Rukovaoci su Lua kod koji radi u sandboxu, tako da ne mogu uticati na funkcionisanje sistema. U ovoj fazi podaci se mogu svesti u traženu formu, a po potrebi se može pokrenuti proizvoljan broj zadataka koji mogu implementirati potrebnu logiku. Na primjer, u MDM (Master Data Management) proizvodu izgrađenom na Tarantool Data Grid-u, prilikom dodavanja novog korisnika, kako ne bismo usporili obradu zahtjeva, pokrećemo kreiranje zlatnog zapisa kao poseban zadatak. Sandbox podržava zahtjeve za čitanje, promjenu i dodavanje podataka, omogućava vam da izvršite neku funkciju na svim ulogama tipa skladišta i agregaciju rezultata (map/reduce).
Rukovaoci se mogu opisati u fajlovima:
sum.lua
local x, y = unpack(...)
return x + yA zatim, deklarirano u konfiguraciji:
functions:
sum: { __file: sum.lua }
Zašto Lua? Lua je veoma jednostavan jezik. Na osnovu našeg iskustva, nekoliko sati nakon što su ga upoznali, ljudi počinju pisati kod koji rješava njihov problem. I to nisu samo profesionalni programeri, već, na primjer, analitičari. Osim toga, zahvaljujući jit kompajleru, Lua radi vrlo brzo.
skladištenje
Pohrana pohranjuje trajne podatke. Prije spremanja, podaci se provjeravaju u odnosu na šemu podataka. Za opis kola koristimo prošireni format ... Primjer:
{
"name": "User",
"type": "record",
"logicalType": "Aggregate",
"fields": [
{ "name": "id", "type": "string"},
{"name": "first_name", "type": "string"},
{"name": "last_name", "type": "string"}
],
"indexes": ["id"]
}Na osnovu ovog opisa, DDL (Jezik definicije podataka) se automatski generira za Tarantula DBMS i šema za pristup podacima.
Podržana je asinhrona replikacija podataka (postoje planovi za dodavanje sinhrone).
Izlazni procesor
Ponekad je potrebno obavijestiti eksterne potrošače o pristizanju novih podataka, u tu svrhu postoji uloga Output procesora. Nakon pohranjivanja podataka, oni se mogu proslijediti odgovarajućem rukovaocu (na primjer, da ih dovede u oblik koji zahtijeva potrošač) - a zatim proslijediti konektoru za slanje. Ovdje se također koristi red za popravku: ako niko nije prihvatio objekt, administrator može pokušati ponovo kasnije.
Skaliranje
Uloge konektora, ulaznog procesora i izlaznog procesora su bez stanja, što nam omogućava horizontalno skaliranje sistema jednostavnim dodavanjem novih instanci aplikacije sa omogućenim željenim tipom uloge. Skladištenje se koristi za horizontalno skaliranje na organiziranje klastera koristeći virtuelne kante. Nakon dodavanja novog servera, neki segmenti sa starih servera se pomeraju na novi server u pozadini; ovo se dešava transparentno za korisnike i ne utiče na rad celog sistema.
Svojstva podataka
Objekti mogu biti vrlo veliki i sadržavati druge objekte. Osiguravamo atomičnost dodavanja i ažuriranja podataka pohranjivanjem objekta sa svim ovisnostima u jednu virtualnu kantu. Ovo sprečava da se objekat "rasprostire" na nekoliko fizičkih servera.
Podržano je verzioniranje: svako ažuriranje objekta stvara novu verziju i uvijek možemo uzeti vremenski odlomak i vidjeti kako je svijet tada izgledao. Za podatke kojima nije potrebna duga historija, možemo ograničiti broj verzija ili čak pohraniti samo jednu – najnoviju – odnosno u suštini onemogućiti verzioniranje za određeni tip. Isto tako možete ograničiti historiju po vremenu: na primjer, obrišite sve objekte određene vrste starije od 1 godine. Podržano je i arhiviranje: možemo isprazniti objekte starije od navedenog vremena, oslobađajući prostor u klasteru.
zadaci
Među zanimljivim karakteristikama, vrijedi istaknuti mogućnost pokretanja zadataka po rasporedu, na zahtjev korisnika ili programski iz sandbox-a:
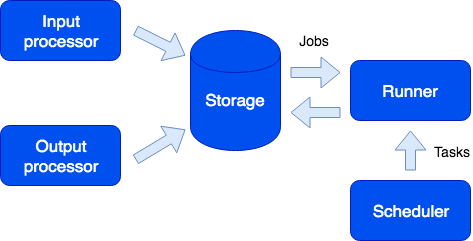
Ovdje vidimo još jednu ulogu - trkača. Ova uloga je bez državljanstva, a dodatne instance aplikacije s ovom ulogom mogu se dodati u klaster po potrebi. Odgovornost trkača je da izvrši zadatke. Kao što je spomenuto, moguće je generirati nove zadatke iz sandboxa; oni se spremaju u red čekanja na pohranu i zatim se izvršavaju na pokretaču. Ova vrsta zadatka se zove posao. Imamo i tip zadatka koji se zove Zadatak - to su korisnički definirani zadaci koji se izvode po rasporedu (koristeći cron sintaksu) ili na zahtjev. Za pokretanje i praćenje takvih zadataka imamo zgodan upravitelj zadataka. Da bi ova funkcionalnost bila dostupna, morate omogućiti ulogu planera; ova uloga ima stanje, pa se ne skalira, što, međutim, nije potrebno; istovremeno, kao i sve druge uloge, može imati repliku koja počinje raditi ako majstor iznenada odbije.
Sjekač
Druga uloga se zove logger. Prikuplja evidencije od svih članova klastera i obezbjeđuje sučelje za njihovo učitavanje i pregled kroz web sučelje.
usluge
Vrijedi napomenuti da sistem olakšava kreiranje usluga. U konfiguracijskoj datoteci možete odrediti koji se zahtjevi šalju rukovatelju napisanom od strane korisnika koji se izvodi u sandboxu. U ovom rukovatelju možete, na primjer, pokrenuti neku vrstu analitičkog upita i vratiti rezultat.
Usluga je opisana u konfiguracijskoj datoteci:
services:
sum:
doc: "adds two numbers"
function: sum
return_type: int
args:
x: int
y: int
GraphQL API se generira automatski i usluga postaje dostupna za pozivanje:
query {
sum(x: 1, y: 2)
} Ovo će pozvati rukovaoca sumkoji će vratiti rezultat:
3
Profiliranje upita i metrika
Da bismo razumeli rad sistema i zahteve za profilisanje, implementirali smo podršku za OpenTracing protokol. Sistem može slati informacije na zahtjev alatima koji podržavaju ovaj protokol, kao što je Zipkin, što će vam omogućiti da shvatite kako je zahtjev izvršen:
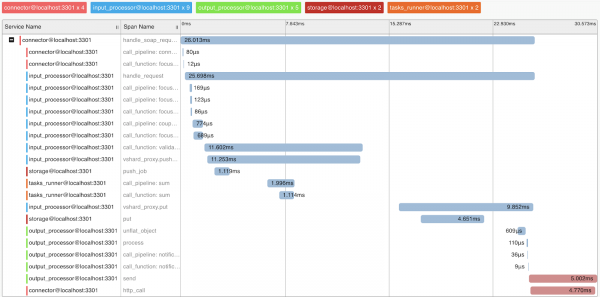
Naravno, sistem pruža interne metrike koje se mogu prikupiti pomoću Prometheusa i vizualizirati pomoću Grafane.
Razviti
Tarantool Data Grid se može implementirati iz RPM paketa ili arhive, koristeći uslužni program iz distribucije ili Ansible, postoji i podrška za Kubernetes ().
Aplikacija koja implementira poslovnu logiku (konfiguracija, rukovaoci) se učitava u raspoređeni Tarantool Data Grid klaster u obliku arhive preko korisničkog sučelja ili korištenjem skripte preko API-ja koji smo dobili.
Primjeri aplikacija
Koje aplikacije se mogu kreirati koristeći Tarantool Data Grid? U stvari, većina poslovnih zadataka je na neki način povezana s obradom, pohranjivanjem i pristupom protoku podataka. Stoga, ako imate velike tokove podataka kojima je potrebno sigurno pohraniti i pristupiti, onda vam naš proizvod može uštedjeti mnogo vremena na razvoju i fokusirati se na vašu poslovnu logiku.
Na primjer, želimo prikupiti informacije o tržištu nekretnina, kako bismo u budućnosti, na primjer, imali informacije o najboljim ponudama. U ovom slučaju ćemo istaknuti sljedeće zadatke:
- Roboti koji prikupljaju informacije iz otvorenih izvora bit će naši izvori podataka. Ovaj problem možete riješiti korištenjem gotovih rješenja ili pisanjem koda na bilo kojem jeziku.
- Zatim će Tarantool Data Grid prihvatiti i pohraniti podatke. Ako je format podataka iz različitih izvora različit, tada možete napisati kod u Lua koji će izvršiti konverziju u jedan format. U fazi predobrade također ćete moći, na primjer, filtrirati duple ponude ili dodatno ažurirati informacije o agentima koji rade na tržištu u bazi podataka.
- Sada već imate skalabilno rješenje u klasteru koje se može puniti podacima i vršiti odabir podataka. Tada možete implementirati novu funkcionalnost, na primjer, napisati uslugu koja će napraviti zahtjev za podacima i dati najpovoljniju ponudu po danu - to će zahtijevati nekoliko redaka u konfiguracijskoj datoteci i malo Lua koda.
Što je sljedeće?
Naš prioritet je da poboljšamo jednostavnost korištenja u razvoju . Na primjer, ovo je IDE s podrškom za rukovatelje profiliranja i otklanjanja grešaka koji rade u sandboxu.
Veliku pažnju posvećujemo i sigurnosnim pitanjima. Trenutno prolazimo kroz certifikaciju od strane FSTEC Rusije kako bismo potvrdili visok nivo sigurnosti i ispunili zahtjeve za sertifikaciju softverskih proizvoda koji se koriste u informacionim sistemima ličnih podataka i državnim informacionim sistemima.
izvor: www.habr.com
