


tim ponude inženjer Rahul Bhatia iz Clairvoyant-a o tome koji formati datoteka postoje u velikim podacima, koje su najčešće karakteristike Hadoop formata i koji format je bolje koristiti.
Zašto su potrebni različiti formati datoteka?
Glavno usko grlo u performansama za aplikacije koje podržavaju HDFS kao što su MapReduce i Spark je vrijeme potrebno za pretraživanje, čitanje i pisanje podataka. Ovi problemi su otežani poteškoćama u upravljanju velikim skupovima podataka ako imamo evoluirajuću shemu, a ne fiksnu, ili ako postoje neka ograničenja pohrane.
Obrada velikih podataka povećava opterećenje podsistema za skladištenje - Hadoop pohranjuje podatke redundantno kako bi postigao toleranciju grešaka. Osim diskova, učitavaju se procesor, mreža, ulazno/izlazni sistem itd. Kako obim podataka raste, tako rastu i troškovi njihove obrade i skladištenja.
Različiti formati datoteka u izmišljen da reši upravo ove probleme. Odabir odgovarajućeg formata datoteke može pružiti neke značajne prednosti:
- Brže vrijeme čitanja.
- Brže vrijeme snimanja.
- Dijeljeni fajlovi.
- Podrška za evoluciju sheme.
- Proširena podrška za kompresiju.
Neki formati datoteka su namijenjeni za opću upotrebu, drugi za specifičniju upotrebu, a neki su dizajnirani da zadovolje specifične karakteristike podataka. Tako da je izbor zaista prilično velik.
Avro format datoteke
Do serijalizacija podataka Avro se široko koristi - it string based, odnosno string format za skladištenje podataka u Hadoop-u. Pohranjuje shemu u JSON formatu, što ga čini lakim za čitanje i tumačenje bilo kojim programom. Sami podaci su u binarnom formatu, kompaktni i efikasni.
Avrov sistem serijalizacije je jezički neutralan. Fajlovi se mogu obraditi na različitim jezicima, trenutno C, C++, C#, Java, Python i Ruby.
Ključna karakteristika Avro-a je njegova robusna podrška za šeme podataka koje se mijenjaju tokom vremena, odnosno evoluiraju. Avro razumije promjene šeme—brisanje, dodavanje ili promjenu polja.
Avro podržava različite strukture podataka. Na primjer, možete kreirati zapis koji sadrži niz, nabrojani tip i podzapis.
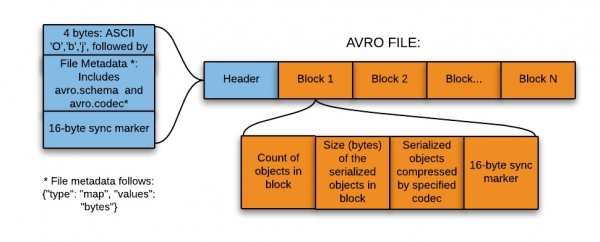
Ovaj format je idealan za pisanje u zonu sletanja (prijelaza) jezera podataka (, ili data lake – zbirka instanci za pohranjivanje različitih tipova podataka pored izvora podataka direktno).
Dakle, ovaj format je najprikladniji za pisanje u zonu slijetanja jezera podataka iz sljedećih razloga:
- Podaci iz ove zone se obično čitaju u cijelosti za dalju obradu od strane nizvodnih sistema - a format baziran na redovima je u ovom slučaju efikasniji.
- Nizvodni sistemi mogu lako da dohvate tabele šema iz fajlova – nema potrebe da se šeme posebno pohranjuju u eksternu meta memoriju.
- Svaka promjena originalne šeme se lako obrađuje (evolucija sheme).
Format datoteke za parket
Parket je format datoteke otvorenog koda za Hadoop koji pohranjuje ugniježđene strukture podataka u ravnom stupnom formatu.
U poređenju sa tradicionalnim rednim pristupom, parket je efikasniji u smislu skladištenja i performansi.
Ovo je posebno korisno za upite koji čitaju određene stupce iz široke (mnogo kolona) tablice. Zahvaljujući formatu datoteke, čitaju se samo potrebne kolone, tako da je ulaz/izlaz sveden na minimum.
Mala digresija i objašnjenje: Da bismo bolje razumjeli format datoteke Parketa u Hadoop-u, hajde da vidimo šta je format zasnovan na stupcima - tj. stupasti - format. Ovaj format pohranjuje slične vrijednosti za svaku kolonu zajedno.
, zapis uključuje polja ID, Ime i Odjeljenje. U ovom slučaju, sve vrijednosti stupca ID-a bit će pohranjene zajedno, kao i vrijednosti stupca Ime, i tako dalje. Tabela će izgledati otprilike ovako:
ID
Ime
Odjel
1
emp1
d1
2
emp2
d2
3
emp3
d3
U formatu stringa podaci će biti sačuvani na sljedeći način:
1
emp1
d1
2
emp2
d2
3
emp3
d3
U kolonskom formatu datoteke, isti podaci će biti sačuvani ovako:
1
2
3
emp1
emp2
emp3
d1
d2
d3
Kolumni format je efikasniji kada trebate upiti više kolona iz tabele. Čitat će samo tražene kolone jer su susjedne. Na ovaj način, I/O operacije su svedene na minimum.
Na primjer, potrebna vam je samo kolona NAME. IN Svaki zapis u skupu podataka treba učitati, raščlaniti po polju, a zatim izdvojiti podatke NAME. Format kolone vam omogućava da se izvučete direktno na kolonu Ime jer se sve vrijednosti za tu kolonu pohranjuju zajedno. Ne morate skenirati cijeli snimak.
Dakle, kolonski format poboljšava performanse upita jer zahtijeva manje vremena traženja da se dođe do potrebnih stupaca i smanjuje broj I/O operacija jer se čitaju samo željeni stupci.
Jedna od jedinstvenih karakteristika je da u ovom formatu može pohranjuju podatke sa ugniježđenim strukturama. To znači da se u datoteci Parket čak i ugniježđena polja mogu čitati pojedinačno bez potrebe za čitanjem svih polja u ugniježđenoj strukturi. Parket koristi algoritam za usitnjavanje i sastavljanje za pohranjivanje ugniježđenih struktura.
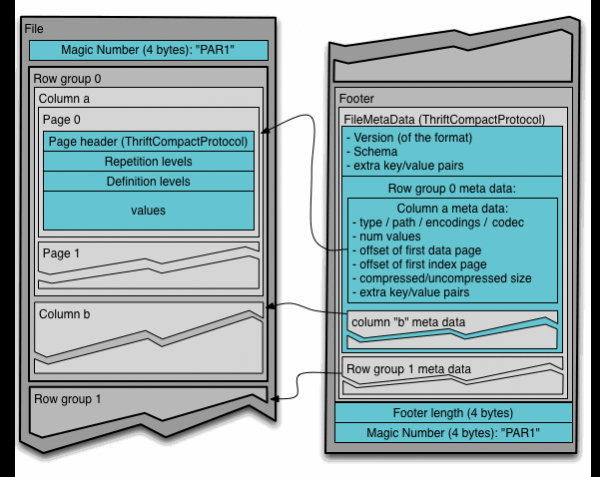
Da biste razumjeli format datoteke Parket u Hadoop-u, trebate znati sljedeće pojmove:
- Grupa žica (grupa redova): logička horizontalna podjela podataka u redove. Grupa redova se sastoji od fragmenta svake kolone u skupu podataka.
- Fragment kolone (komad kolone): Fragment određene kolone. Ovi fragmenti stupaca žive u određenoj grupi redova i garantirano su susjedni u datoteci.
- Stranica (stranica): Fragmenti kolona podijeljeni su na stranice koje se pišu jedna za drugom. Stranice imaju zajednički naslov, tako da prilikom čitanja možete preskočiti nepotrebne.
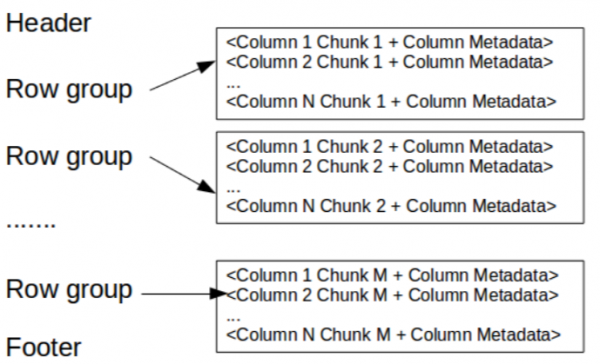
Ovdje naslov samo sadrži magični broj PAR1 (4 bajta) koji identifikuje fajl kao Parket fajl.
Podnožje kaže sljedeće:
- Metapodaci datoteke koji sadrže početne koordinate metapodataka svake kolone. Kada čitate, prvo morate pročitati metapodatke datoteke da biste pronašli sve fragmente stupaca koji vas zanimaju. Dijelove stupaca tada treba čitati uzastopno. Ostali metapodaci uključuju verziju formata, shemu i sve dodatne parove ključ/vrijednost.
- Dužina metapodataka (4 bajta).
- magični broj PAR1 (4 bajta).
ORC format datoteke
Optimiziran format datoteke red-kolona (Optimizirana kolona reda, ) nudi veoma efikasan način skladištenja podataka i dizajniran je da prevaziđe ograničenja drugih formata. Pohranjuje podatke u savršeno kompaktnom obliku, omogućavajući vam da preskočite nepotrebne detalje - bez potrebe za konstrukcijom velikih, složenih ili ručno održavanih indeksa.
Prednosti ORC formata:
- Jedna datoteka je izlaz svakog zadatka, što smanjuje opterećenje na NameNode (naziv čvor).
- Podrška za tipove podataka Hive, uključujući datum i vrijeme, decimalne i složene tipove podataka (struktura, lista, mapa i unija).
- Istovremeno čitanje iste datoteke od strane različitih RecordReader procesa.
- Mogućnost podjele datoteka bez skeniranja markera.
- Procjena maksimalno moguće alokacije memorije hrpe za procese čitanja/pisanja na osnovu informacija u podnožju datoteke.
- Metapodaci se pohranjuju u formatu binarne serijalizacije Protocol Buffers, koji omogućava dodavanje i uklanjanje polja.
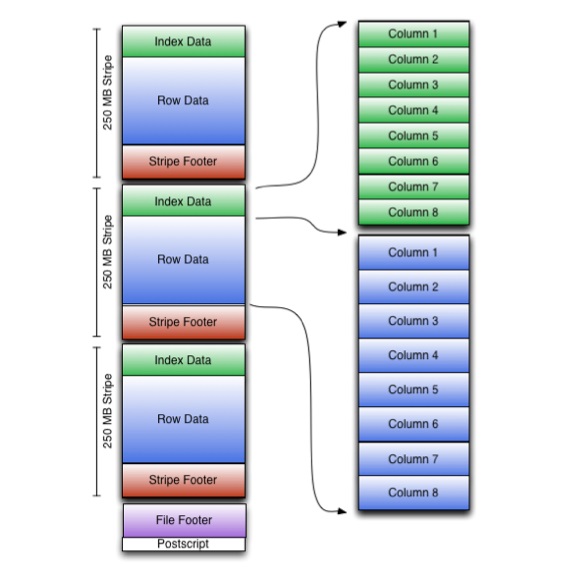
ORC pohranjuje kolekcije stringova u jednoj datoteci, au okviru kolekcije podaci stringova se pohranjuju u kolonskom formatu.
ORC datoteka pohranjuje grupe linija koje se zovu trake i prateće informacije u podnožju datoteke. Postscript na kraju datoteke sadrži parametre kompresije i veličinu kompresovanog podnožja.
Zadana veličina trake je 250 MB. Zbog tako velikih pruga, čitanje iz HDFS-a se obavlja efikasnije: u velikim susednim blokovima.
Podnožje datoteke bilježi listu traka u datoteci, broj redova po traci i tip podataka svake kolone. Rezultirajuća vrijednost count, min, max i sum za svaku kolonu je također upisana tamo.
Podnožje trake sadrži direktorij lokacija tokova.
Podaci reda se koriste prilikom skeniranja tabela.
Podaci indeksa uključuju minimalne i maksimalne vrijednosti za svaku kolonu i poziciju redova u svakoj koloni. ORC indeksi se koriste samo za odabir traka i grupa redova, a ne za odgovaranje na upite.
Poređenje različitih formata datoteka
Avro u odnosu na Parket
- Avro je format za pohranu u redovima, dok Parket pohranjuje podatke u stupce.
- Parket je prikladniji za analitičke upite, što znači da su operacije čitanja i upiti podataka mnogo efikasniji od upisivanja.
- Operacije pisanja u Avru se izvode efikasnije nego u Parketu.
- Avro se zrelije bavi evolucijom kola. Parket podržava samo dodavanje sheme, dok Avro podržava multifunkcionalnu evoluciju, odnosno dodavanje ili promjenu stupaca.
- Parket je idealan za ispitivanje podskupa kolona u tabeli sa više kolona. Avro je pogodan za ETL operacije u kojima ispitujemo sve kolone.
ORC vs Parket
- Parket bolje pohranjuje ugniježđene podatke.
- ORC je prikladniji za predikatno potiskivanje.
- ORC podržava svojstva ACID-a.
- ORC bolje kompresuje podatke.
Šta još pročitati na temu:
- .
- .
- .
izvor: www.habr.com
