

U ovom članku ću opisati situaciju koja se nedavno dogodila s jednim od naših VPS cloud servera, koja me je nekoliko sati zbunjivala. Konfigurišem i rješavam probleme sa serverima već oko 15 godina. Linux, ali ovaj slučaj se uopšte ne uklapa u moju praksu - napravio sam nekoliko pogrešnih pretpostavki i bio sam pomalo očajan prije nego što sam uspio ispravno identificirati uzrok problema i riješiti ga.
Preambula
Mi upravljamo oblakom srednje veličine, koji gradimo na standardnim serverima sa sljedećom konfiguracijom - 32 jezgra, 256 GB RAM-a i 4500TB PCI-E Intel P4 NVMe drajv. Zaista nam se sviđa ova konfiguracija jer eliminiše potrebu da brinete o IO overhead-u pružanjem ispravnog ograničenja na nivou tipa VM instance. Jer NVMe Intel ima impresivne performanse, možemo istovremeno da obezbedimo punu IOPS obezbeđivanje mašinama i rezervnu pohranu na backup serveru sa nultim IOWAIT-om.
Mi smo jedni od onih starih vernika koji ne koriste hiperkonvergentni SDN i druge moderne, moderne, omladinske stvari za skladištenje VM volumena, verujući da što je sistem jednostavniji, lakše ga je rešiti u uslovima „glavnog gurua je otišao u planine.” Kao rezultat toga, pohranjujemo volumene VM-a u QCOW2 formatu u XFS ili EXT4, koji je raspoređen na vrhu LVM2.
Također smo prisiljeni koristiti QCOW2 od strane proizvoda koji koristimo za orkestraciju - Apache CloudStack.
Da bismo napravili rezervnu kopiju, uzimamo punu sliku volumena kao LVM2 snimak (da, znamo da su LVM2 snimke spore, ali nam Intel P4500 takođe pomaže). Mi radimo lvmcreate -s .. i uz pomoć dd šaljemo rezervnu kopiju na udaljeni server sa ZFS skladištem. Ovdje smo još uvijek malo progresivni - na kraju krajeva, ZFS može pohraniti podatke u komprimiranom obliku, a možemo ih brzo vratiti koristeći DD ili koristite pojedinačne volumene VM-a mount -o loop ....
Možete, naravno, ukloniti ne punu sliku LVM2 volumena, već montirati sistem datoteka u
ROi kopirajte same QCOW2 slike, međutim, bili smo suočeni sa činjenicom da je XFS postao loš od ovoga, i to ne odmah, već na nepredvidiv način. Zaista ne volimo kada se hipervizorski domaćini iznenada "zaglave" vikendom, noću ili praznicima zbog grešaka za koje nije jasno kada će se dogoditi. Stoga, za XFS ne koristimo montažu snimkaROda bismo izdvojili volumene, jednostavno kopiramo cijeli volumen LVM2.
Brzina backup-a na backup server je u našem slučaju određena performansama backup servera, koje su oko 600-800 MB/s za nekomprimirane podatke; daljnji limiter je kanal od 10Gbit/s s kojim je backup server povezan. u klaster.
Istovremeno, 8 sigurnosnih kopija se istovremeno otprema na jedan server za sigurnosne kopije. serveri Hipervizori. Dakle, diskovni i mrežni podsistemi rezervnog servera, iako sporiji, sprječavaju preopterećenje diskovnih podsistema hipervizorskih hostova, jer oni jednostavno nisu u stanju da obrade, recimo, 8 GB/sec, što hipervizorski hostovi mogu lako obraditi.
Gore navedeni proces kopiranja je veoma važan za dalju priču, uključujući i detalje - korišćenjem brzog Intel P4500 drajva, korišćenjem NFS-a i, verovatno, korišćenjem ZFS-a.
Rezervna priča
Na svakom hipervizorskom čvoru imamo malu SWAP particiju veličine 8 GB, a sam hipervizorski čvor „razvaljujemo“ koristeći DD sa referentne slike. Za sistemski volumen na serverima koristimo 2xSATA SSD RAID1 ili 2xSAS HDD RAID1 na LSI ili HP hardverskom kontroleru. Generalno, uopšte nas nije briga šta je unutra, jer naš sistemski volumen radi u režimu „skoro samo za čitanje“, osim za SWAP. A pošto imamo dosta RAM-a na serveru i on je 30-40% besplatan, ne razmišljamo o SWAP-u.
Backup proces. Ovaj zadatak izgleda otprilike ovako:
#!/bin/bash
mkdir -p /mnt/backups/volumes
DIR=/mnt/images-snap
VOL=images/volume
DATE=$(date "+%d")
HOSTNAME=$(hostname)
lvcreate -s -n $VOL-snap -l100%FREE $VOL
ionice -c3 dd iflag=direct if=/dev/$VOL-snap bs=1M of=/mnt/backups/volumes/$HOSTNAME-$DATE.raw
lvremove -f $VOL-snapObrati paćnju ionice -c3, zapravo, ova stvar je potpuno beskorisna za NVMe uređaje, jer je IO planer za njih postavljen kao:
cat /sys/block/nvme0n1/queue/scheduler
[none] Međutim, imamo niz naslijeđenih čvorova s konvencionalnim SSD RAID-ovima, za njih je to relevantno, pa se pomiču KAO ŠTO JE. Sve u svemu, ovo je samo zanimljiv dio koda koji objašnjava uzaludnost ionice u slučaju takve konfiguracije.
Obratite pažnju na zastavu iflag=direct do DD. Koristimo direktni IO zaobilazeći keš bafera kako bismo izbjegli nepotrebnu zamjenu IO bafera prilikom čitanja. Kako god, oflag=direct nemamo jer smo naišli na probleme sa ZFS performansama kada smo ga koristili.
Ovu šemu uspješno koristimo nekoliko godina bez problema.
A onda je počelo... Otkrili smo da jedan od čvorova više nije sigurnosno kopiran, a prethodni radi sa monstruoznim IOWAIT-om od 50%. Prilikom pokušaja da shvatimo zašto ne dolazi do kopiranja, naišli smo na sljedeći fenomen:
Volume group "images" not foundPočeli smo razmišljati o tome „došao je kraj Intelu P4500“, međutim, prije isključivanja servera radi zamjene drajva, ipak je bilo potrebno napraviti rezervnu kopiju. Popravili smo LVM2 vraćanjem metapodataka iz LVM2 sigurnosne kopije:
vgcfgrestore imagesPokrenuli smo rezervnu kopiju i vidjeli ovu sliku ulja:
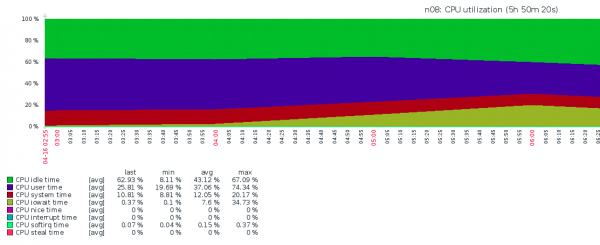
Opet smo bili jako tužni - bilo je jasno da ne možemo ovako da živimo, jer bi svi VPS-ovi patili, što znači da bismo i mi patili. Šta se desilo potpuno je nejasno - iostat pokazao jadan IOPS i najveći IOWAIT. Nije bilo drugih ideja osim "zamenimo NVMe", ali uvid se desio baš na vreme.
Analiza situacije korak po korak
Historical magazine. Nekoliko dana ranije, na ovom serveru je bilo potrebno napraviti veliki VPS sa 128 GB RAM-a. Činilo se da ima dovoljno memorije, ali da bismo bili sigurni, dodijelili smo još 32 GB za swap particiju. VPS je kreiran, uspješno je izvršio svoj zadatak i incident je zaboravljen, ali je SWAP particija ostala.
Značajke konfiguracije. Za sve servere u oblaku parametar vm.swappiness je postavljeno na zadano 60. I SWAP je kreiran na SAS HDD RAID1.
Šta se desilo (prema urednicima). Prilikom pravljenja rezervne kopije DD proizveo je mnogo podataka za upisivanje, koji su stavljeni u RAM bafere prije pisanja u NFS. Jezgro sistema, vođeno politikom swappiness, je premeštao mnoge stranice VPS memorije u swap oblast, koja se nalazila na sporom HDD RAID1 volumenu. To je dovelo do jakog rasta IOWAIT-a, ali ne zbog IO NVMe, već zbog IO HDD RAID1.
Kako je problem riješen. Swap particija od 32 GB je onemogućena. Ovo je trajalo 16 sati; možete zasebno pročitati kako i zašto se SWAP tako sporo isključuje. Postavke su promijenjene swappiness na vrijednost jednaku 5 svuda po oblaku.
Kako se ovo ne bi dogodilo?. Prvo, da je SWAP na SSD RAID ili NVMe uređaju, i drugo, da nema NVMe uređaja, već sporijeg uređaja koji ne bi proizvodio toliki obim podataka - ironično, problem se dogodio jer je taj NVMe prebrz.
Nakon toga, sve je počelo raditi kao i prije - sa nula IOWAIT.
izvor: www.habr.com
