

Podsjetimo, Elastic Stack je baziran na nerelacijskoj bazi podataka Elasticsearch, web interfejsu Kibana i kolektorima i procesorima podataka (najpoznatiji Logstash, razni Beats, APM i drugi). Jedan od lijepih dodataka cijelom navedenom steku proizvoda je analiza podataka korištenjem algoritama strojnog učenja. U članku razumijemo koji su to algoritmi. Molimo pod kat.
Mašinsko učenje je plaćena karakteristika shareware Elastic Stack-a i uključena je u X-Pack. Da biste ga počeli koristiti, samo aktivirajte 30-dnevnu probnu verziju nakon instalacije. Nakon što probni period istekne, možete zatražiti podršku za produženje ili kupiti pretplatu. Cijena pretplate se ne obračunava na osnovu količine podataka, već na osnovu broja korištenih čvorova. Ne, količina podataka, naravno, utiče na broj potrebnih čvorova, ali je ipak ovakav pristup licenciranju humaniji u odnosu na budžet kompanije. Ako nema potrebe za visokom produktivnošću, možete uštedjeti novac.
ML u Elastic Stack-u je napisan u C++ i radi izvan JVM-a, u kojem se pokreće i sam Elasticsearch. To jest, proces (usput rečeno, zove se autodetect) troši sve što JVM ne proguta. Na demo štandu ovo nije toliko kritično, ali u proizvodnom okruženju važno je dodijeliti odvojene čvorove za ML zadatke.
Algoritmi mašinskog učenja spadaju u dve kategorije − и . U Elastic Stack, algoritam je u kategoriji „nenadziranih“. By Možete vidjeti matematički aparat algoritama mašinskog učenja.
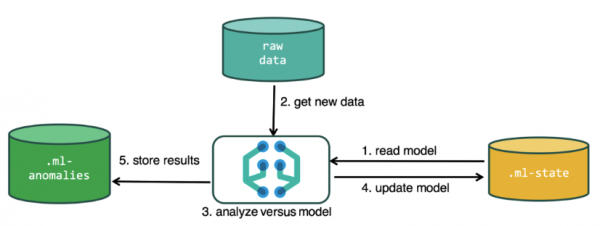
Za izvođenje analize, algoritam mašinskog učenja koristi podatke pohranjene u Elasticsearch indeksima. Zadatke za analizu možete kreirati i iz Kibana interfejsa i preko API-ja. Ako to radite preko Kibane, onda neke stvari ne morate znati. Na primjer, dodatni indeksi koje algoritam koristi tokom svog rada.
Dodatni indeksi koji se koriste u procesu analize.ml-state — informacije o statističkim modelima (postavke analize);
.ml-anomalies-* — rezultati ML algoritama;
.ml-notifications — postavke za obavještenja na osnovu rezultata analize.
Struktura podataka u bazi podataka Elasticsearch sastoji se od indeksa i dokumenata pohranjenih u njima. Kada se uporedi sa relacionom bazom podataka, indeks se može uporediti sa šemom baze podataka, a dokument sa zapisom u tabeli. Ovo poređenje je uslovno i predviđeno je kako bi se pojednostavilo razumijevanje daljnjeg materijala za one koji su samo čuli za Elasticsearch.
Ista funkcionalnost je dostupna preko API-ja kao i preko web sučelja, pa ćemo zbog jasnoće i razumijevanja koncepata pokazati kako je konfigurirati putem Kibane. U meniju na lijevoj strani nalazi se odjeljak Machine Learning u kojem možete kreirati novi posao. U interfejsu Kibana izgleda kao na slici ispod. Sada ćemo analizirati svaku vrstu zadatka i pokazati tipove analize koje se ovdje mogu konstruirati.
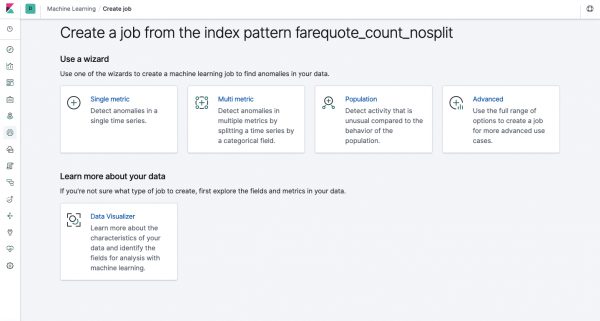
Single Metric - analiza jedne metrike, Multi Metric - analiza dvije ili više metrika. U oba slučaja, svaka metrika se analizira u izolovanom okruženju, tj. algoritam ne uzima u obzir ponašanje paralelno analiziranih metrika, kao što bi moglo izgledati u slučaju Multi Metric. Da biste izvršili proračune uzimajući u obzir korelaciju različitih metrika, možete koristiti analizu stanovništva. A Advanced fino podešava algoritme s dodatnim opcijama za određene zadatke.
Pojedinačna metrika
Analiza promjena u jednoj jedinici je najjednostavnija stvar koja se ovdje može učiniti. Nakon što kliknete na Kreiraj posao, algoritam će tražiti anomalije.
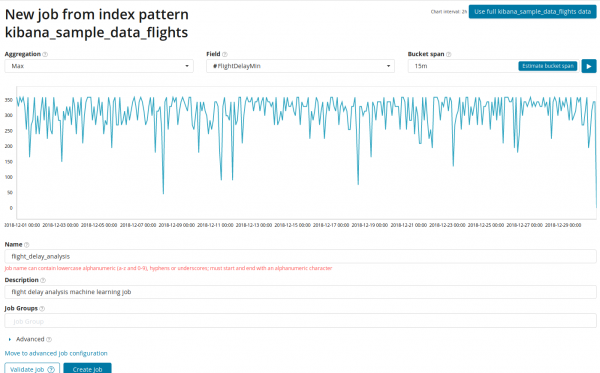
U polju sakupljanje možete odabrati pristup traženju anomalija. Na primjer, kada min vrijednosti ispod tipičnih vrijednosti će se smatrati anomalnim. Jedi Max, High Mean, Low, Mean, Distinct i drugi. Opisi svih funkcija se mogu naći .
U polju polje označava numeričko polje u dokumentu na kojem ćemo izvršiti analizu.
U polju — granularnost intervala na vremenskoj liniji duž koje će se analiza vršiti. Možete vjerovati automatizaciji ili odabrati ručno. Slika ispod je primjer preniske granularnosti - možda ćete propustiti anomaliju. Koristeći ovu postavku, možete promijeniti osjetljivost algoritma na anomalije.
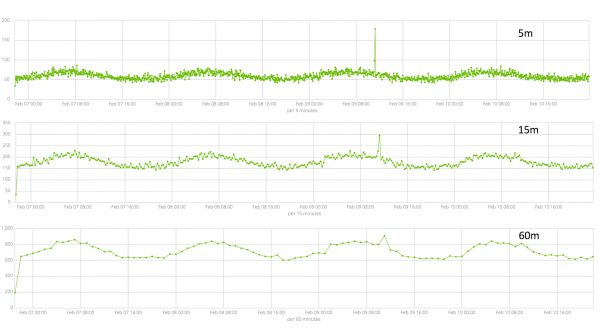
Trajanje prikupljenih podataka je ključna stvar koja utiče na efikasnost analize. Tokom analize, algoritam identifikuje intervale koji se ponavljaju, izračunava intervale poverenja (osnovne linije) i identifikuje anomalije – atipična odstupanja od uobičajenog ponašanja metrike. Samo na primjer:
Polazne osnove s malim dijelom podataka:
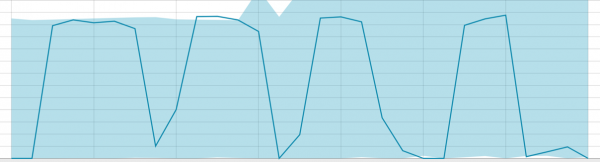
Kada algoritam ima nešto iz čega naučiti, osnovna linija izgleda ovako:
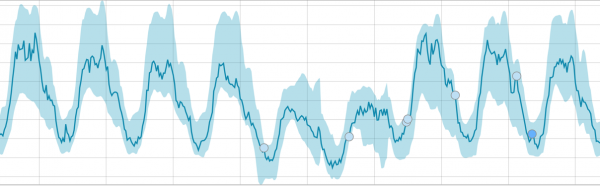
Nakon pokretanja zadatka, algoritam utvrđuje anomalna odstupanja od norme i rangira ih prema vjerovatnoći anomalije (boja odgovarajuće oznake je naznačena u zagradama):
Upozorenje (plavo): manje od 25
Minor (žuti): 25-50
Major (narandžasta): 50-75
Kritično (crveno): 75-100
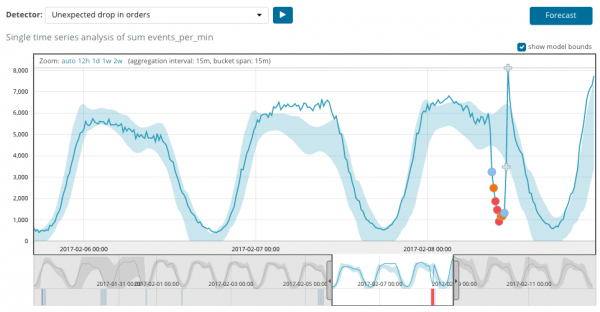
Grafikon ispod prikazuje primjer pronađenih anomalija.
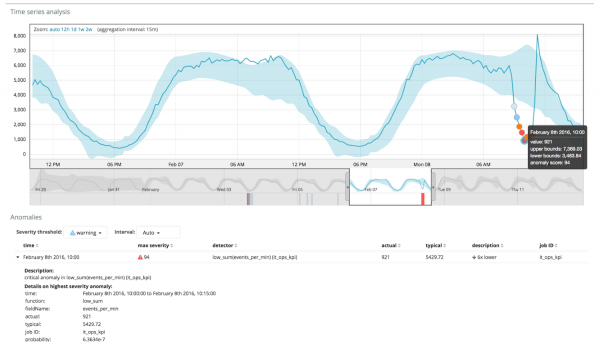
Ovdje možete vidjeti broj 94, koji označava vjerovatnoću anomalije. Jasno je da pošto je vrijednost blizu 100, to znači da imamo anomaliju. Kolona ispod grafikona pokazuje pežorativno malu vjerovatnoću od 0.000063634% metričke vrijednosti koja se tamo pojavljuje.
Osim traženja anomalija, možete pokrenuti prognozu u Kibani. To se radi jednostavno i iz istog pogleda sa anomalijama - dugme prognoza u gornjem desnom uglu.
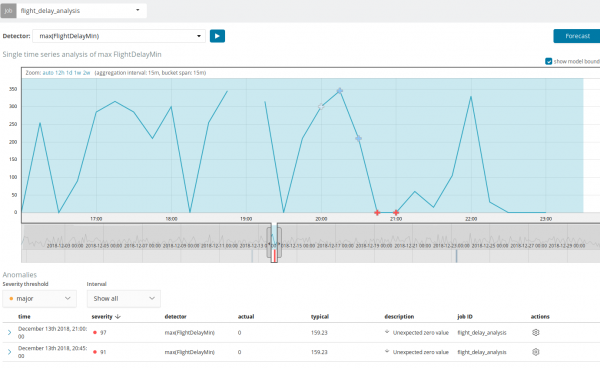
Prognoza se pravi za maksimalno 8 sedmica unaprijed. Čak i ako to zaista želite, dizajnom to više nije moguće.
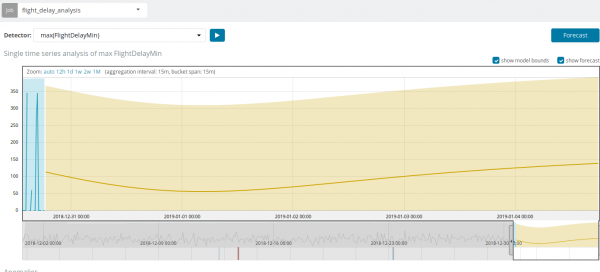
U nekim situacijama, prognoza će biti vrlo korisna, na primjer, kada se prati opterećenje korisnika na infrastrukturi.
Multi Metric
Pređimo na sljedeću ML funkciju u Elastic Stack-u - analizu nekoliko metrika u jednoj seriji. Ali to ne znači da će se analizirati zavisnost jedne metrike od druge. Ovo je isto kao i Single Metric, ali sa više metrika na jednom ekranu za jednostavno poređenje uticaja jednog na drugi. Razgovaraćemo o analizi zavisnosti jedne metrike od druge u odjeljku Populacija.
Nakon klika na kvadratić sa višestrukim metrikom, pojavit će se prozor s postavkama. Pogledajmo ih detaljnije.
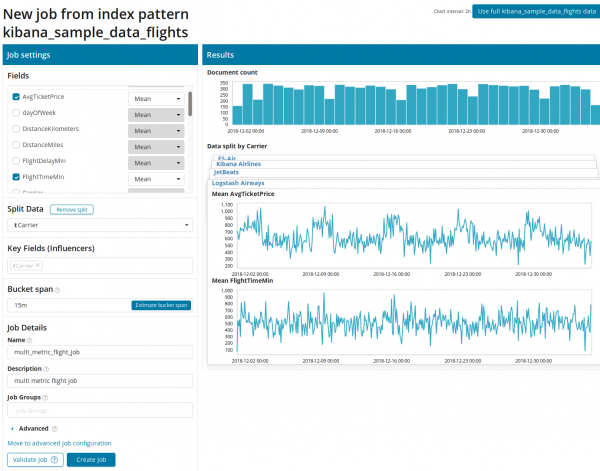
Prvo morate odabrati polja za analizu i agregaciju podataka o njima. Opcije agregacije ovdje su iste kao i za Single Metric (Max, High Mean, Low, Mean, Distinct i drugi). Nadalje, po želji, podaci se dijele u jedno od polja (polje Split Data). U primjeru smo to uradili po polju OriginAirportID. Primijetite da je metrički graf na desnoj strani sada predstavljen kao više grafova.
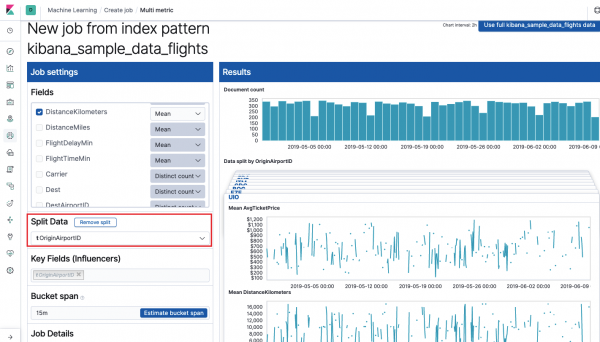
polje Ključna polja (influenceri) direktno utiče na otkrivene anomalije. Podrazumevano će uvijek biti barem jedna vrijednost ovdje, a možete dodati dodatne. Algoritam će uzeti u obzir uticaj ovih polja prilikom analize i pokazati najuticajnije vrednosti.
Nakon pokretanja, ovako nešto će se pojaviti u interfejsu Kibana.
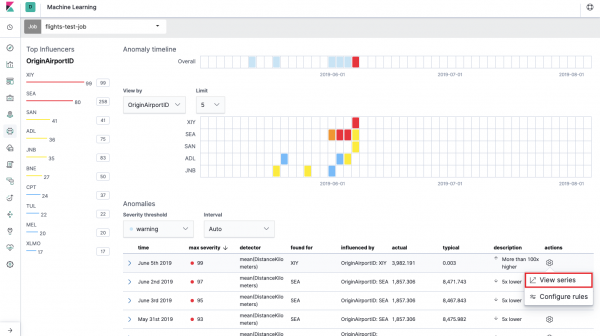
Ovo je tzv toplotna karta anomalija za svaku vrijednost polja OriginAirportID, što smo naveli u Split Data. Kao i kod Single Metric, boja označava nivo abnormalnog odstupanja. Zgodno je napraviti sličnu analizu, na primjer, na radnim stanicama za praćenje onih sa sumnjivo velikim brojem ovlaštenja itd. Već smo pisali , koji se također ovdje može prikupiti i analizirati.
Ispod toplotne karte nalazi se lista anomalija, sa svake se možete prebaciti na jednostruki metrički prikaz za detaljnu analizu.
populacija
Za traženje anomalija među korelacijama između različitih metrika, Elastic Stack ima specijaliziranu analizu stanovništva. Uz njegovu pomoć možete tražiti anomalne vrijednosti u performansama servera u odnosu na druge kada se, na primjer, poveća broj zahtjeva prema ciljnom sistemu.
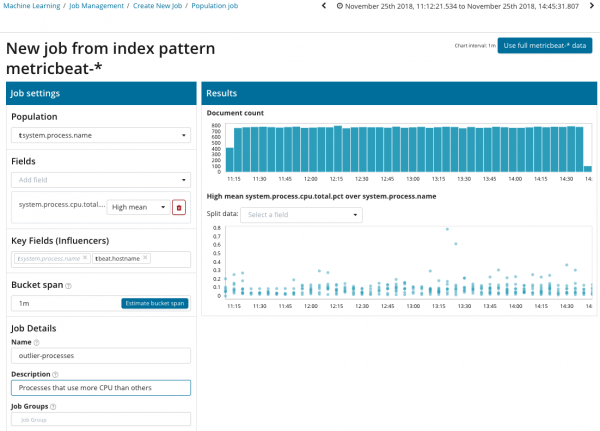
Na ovoj ilustraciji, polje Populacija označava vrijednost na koju će se analizirani pokazatelji odnositi. U ovom slučaju to je naziv procesa. Kao rezultat toga, vidjet ćemo kako je opterećenje procesora svakog procesa utjecalo jedno na drugo.
Napominjemo da se grafikon analiziranih podataka razlikuje od slučajeva sa jednom metrikom i više metrikom. Ovo je urađeno u Kibani dizajnom radi poboljšane percepcije distribucije vrijednosti analiziranih podataka.
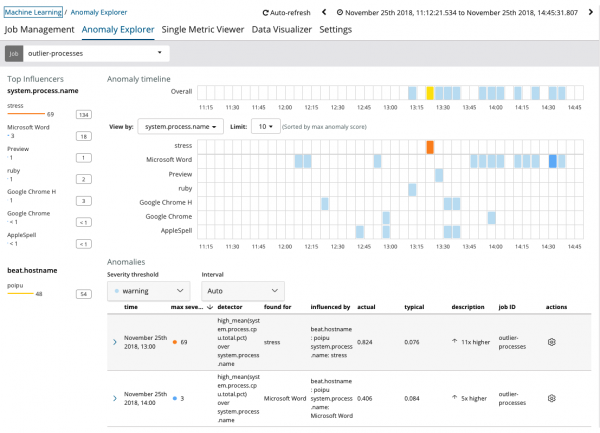
Grafikon pokazuje da se proces ponašao nenormalno stres (usput, generiran posebnim uslužnim programom) na serveru poipu, koji je uticao (ili se pokazao kao influenser) na pojavu ove anomalije.
Napredan
Analitika sa finim podešavanjem. Uz naprednu analizu, dodatna podešavanja se pojavljuju u Kibani. Nakon što kliknete na pločicu Napredno u meniju za kreiranje, pojavljuje se ovaj prozor sa karticama. Tab Detalji posla Namjerno smo to preskočili, postoje osnovne postavke koje nisu direktno vezane za postavljanje analize.
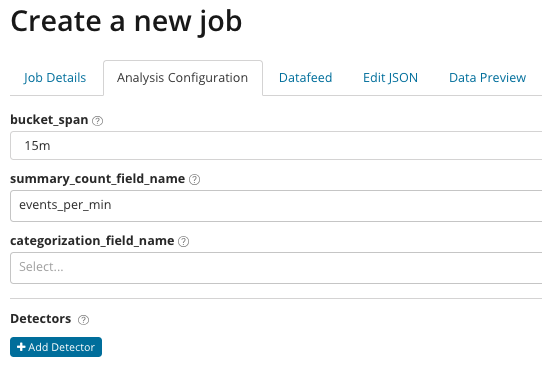
В summary_count_field_name Opciono, možete odrediti ime polja iz dokumenata koji sadrže agregirane vrijednosti. U ovom primjeru, broj događaja u minuti. IN označava ime i vrijednost polja iz dokumenta koje sadrži neku vrijednost varijable. Koristeći masku na ovom polju, možete podijeliti analizirane podatke u podskupove. Obratite pažnju na dugme Dodajte detektor na prethodnoj ilustraciji. Ispod je rezultat klika na ovo dugme.
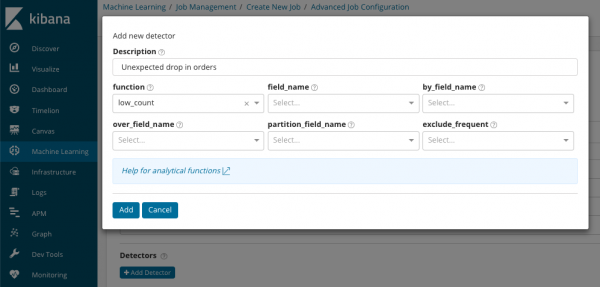
Ovdje je dodatni blok postavki za konfiguriranje detektora anomalija za određeni zadatak. Planiramo da razgovaramo o specifičnim slučajevima upotrebe (posebno o bezbednosnim) u sledećim člancima. Na primjer, jedan od rastavljenih kućišta. Povezan je s potragom za vrijednostima koje se rijetko pojavljuju i implementiran .
U polju Funkcija Možete odabrati određenu funkciju za traženje anomalija. Osim retko, ima još par zanimljivih funkcija - . Oni identifikuju anomalije u ponašanju metrike tokom dana, odnosno nedelje. Druge funkcije analize .
В field_name označava polje dokumenta na kojem će se izvršiti analiza. By_field_name može se koristiti za odvajanje rezultata analize za svaku pojedinačnu vrijednost polja dokumenta navedenog ovdje. Ako popunite naziv_polja dobijate analizu stanovništva o kojoj smo gore govorili. Ako navedete vrijednost u partition_field_name, tada će se za ovo polje dokumenta izračunati odvojene osnovne linije za svaku vrijednost (vrijednost može biti, na primjer, ime servera ili procesa na serveru). IN exclude_frequent mogu da biraju sve ili nijedan, što će značiti isključivanje (ili uključivanje) vrijednosti polja dokumenta koje se često pojavljuju.
U ovom članku pokušali smo da damo što jezgrovitiju predstavu o mogućnostima mašinskog učenja u Elastic Stack-u; još uvijek je puno detalja ostalo iza kulisa. Recite nam u komentarima koje ste slučajeve uspjeli riješiti koristeći Elastic Stack i za koje zadatke ga koristite. Da biste nas kontaktirali, možete koristiti lične poruke na Habré ili .
izvor: www.habr.com
