

Abans de l'inici del curs preparat per a tu una traducció d'un altre material útil.
La codificació Huffman és un algorisme de compressió de dades que formula la idea bàsica de la compressió de fitxers. En aquest article, parlarem de la codificació de longitud fixa i variable, codis descodificables de manera única, regles de prefix i construcció d'un arbre Huffman.
Sabem que cada caràcter s'emmagatzema com una seqüència de 0 i 1 i ocupa 8 bits. Això s'anomena codificació de longitud fixa perquè cada caràcter utilitza el mateix nombre fix de bits per emmagatzemar.
Suposem que ens donen text. Com podem reduir la quantitat d'espai necessari per emmagatzemar un sol caràcter?
La idea principal és la codificació de longitud variable. Podem utilitzar el fet que alguns caràcters del text apareixen més sovint que d'altres () per desenvolupar un algorisme que representi la mateixa seqüència de caràcters en menys bits. En la codificació de longitud variable, assignem als caràcters un nombre variable de bits, en funció de la freqüència amb què apareixen en un text determinat. Finalment, alguns caràcters poden trigar només 1 bit, mentre que altres poden trigar 2 bits, 3 o més. El problema amb la codificació de longitud variable és només la descodificació posterior de la seqüència.
Com, coneixent la seqüència de bits, descodificar-la sense ambigüitats?
Considereu la línia "abacdab". Té 8 caràcters i, en codificar una longitud fixa, necessitarà 64 bits per emmagatzemar-lo. Tingueu en compte que la freqüència del símbol "a", "b", "c" и "D" és igual a 4, 2, 1, 1 respectivament. Intentem imaginar-nos "abacdab" menys bits, utilitzant el fet que «A» es produeix amb més freqüència que «B»I «B» es produeix amb més freqüència que "c" и "D". Comencem codificant «A» amb un bit igual a 0, «B» assignarem un codi 11 de dos bits, i amb tres bits 100 i 011 codificarem "c" и "D".
Com a resultat, obtindrem:
a
0
b
11
c
100
d
011
Així que la línia "abacdab" codificarem com 00110100011011 (0|0|11|0|100|011|0|11)utilitzant els codis anteriors. Tanmateix, el principal problema estarà en la descodificació. Quan intentem descodificar la cadena 00110100011011, obtenim un resultat ambigu, ja que es pot representar com:
0|011|0|100|011|0|11 adacdab
0|0|11|0|100|0|11|011 aabacabd
0|011|0|100|0|11|0|11 adacabab
...
etcètera
Per evitar aquesta ambigüitat, hem d'assegurar-nos que la nostra codificació compleix un concepte com regla del prefix, que al seu torn implica que els codis només es poden descodificar d'una manera única. La regla del prefix assegura que cap codi és un prefix d'un altre. Per codi, ens referim als bits utilitzats per representar un caràcter determinat. A l'exemple anterior 0 és un prefix 011, que infringeix la regla del prefix. Per tant, si els nostres codis compleixen la regla del prefix, podem descodificar de manera única (i viceversa).
Repassem l'exemple anterior. Aquesta vegada assignarem símbols "a", "b", "c" и "D" codis que compleixen la regla del prefix.
a
0
b
10
c
110
d
111
Amb aquesta codificació, la cadena "abacdab" es codificarà com a 00100100011010 (0|0|10|0|100|011|0|10). Però el 00100100011010 ja podrem descodificar sense ambigüitats i tornar a la nostra cadena original "abacdab".
Codificació Huffman
Ara que hem tractat amb la codificació de longitud variable i la regla del prefix, parlem de la codificació Huffman.
El mètode es basa en la creació d'arbres binaris. En ell, el node pot ser final o intern. Inicialment, tots els nodes es consideren fulles (terminals), que representen el símbol en si i el seu pes (és a dir, la freqüència d'ocurrència). Els nodes interns contenen el pes del caràcter i fan referència a dos nodes descendents. Per acord general, una mica «0» representa seguint la branca esquerra, i «1» - a la dreta. en ple arbre N fulles i N-1 nodes interns. Es recomana que quan es construeix un arbre Huffman, es descarti els símbols no utilitzats per obtenir codis de longitud òptims.
Utilitzarem una cua de prioritats per construir un arbre Huffman, on el node amb la freqüència més baixa tindrà la màxima prioritat. Els passos de construcció es descriuen a continuació:
- Creeu un node fulla per a cada caràcter i afegiu-los a la cua de prioritats.
- Mentre hi hagi més d'un full a la cua, feu el següent:
- Elimina els dos nodes amb la prioritat més alta (freqüència més baixa) de la cua;
- Creeu un nou node intern, on aquests dos nodes seran fills, i la freqüència d'ocurrència serà igual a la suma de les freqüències d'aquests dos nodes.
- Afegiu un nou node a la cua de prioritats.
- L'únic node restant serà l'arrel, i això completarà la construcció de l'arbre.
Imagineu que tenim un text que només consta de caràcters "a", "b", "c", "d" и «E», i les seves freqüències d'aparició són 15, 7, 6, 6 i 5, respectivament. A continuació es mostren il·lustracions que reflecteixen els passos de l'algorisme.
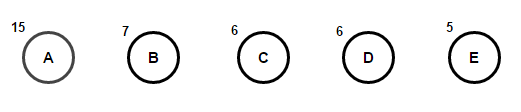
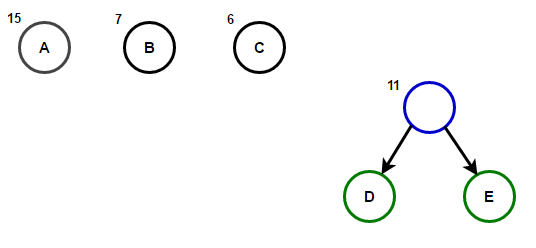
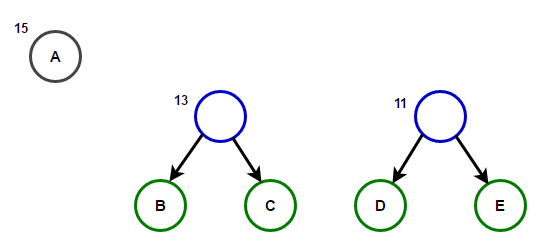
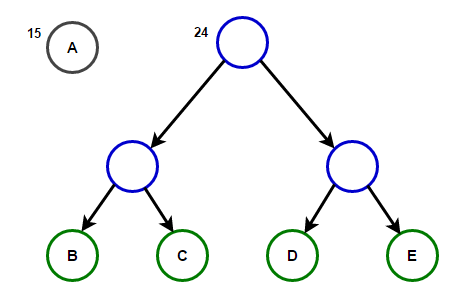
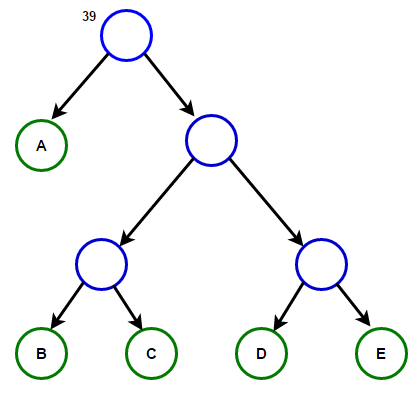
Un camí des de l'arrel fins a qualsevol node final emmagatzemarà el codi de prefix òptim (també conegut com a codi Huffman) corresponent al caràcter associat amb aquest node final.
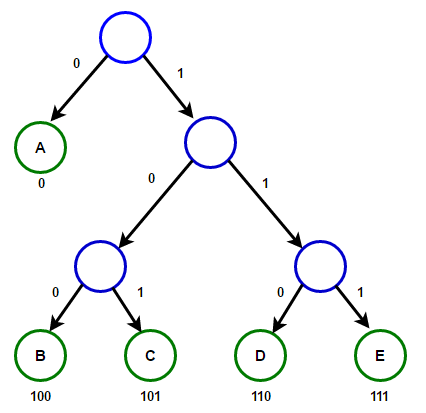
Arbre de Huffman
A continuació trobareu la implementació de l'algorisme de compressió Huffman en C++ i Java:
#include <iostream>
#include <string>
#include <queue>
#include <unordered_map>
using namespace std;
// A Tree node
struct Node
{
char ch;
int freq;
Node *left, *right;
};
// Function to allocate a new tree node
Node* getNode(char ch, int freq, Node* left, Node* right)
{
Node* node = new Node();
node->ch = ch;
node->freq = freq;
node->left = left;
node->right = right;
return node;
}
// Comparison object to be used to order the heap
struct comp
{
bool operator()(Node* l, Node* r)
{
// highest priority item has lowest frequency
return l->freq > r->freq;
}
};
// traverse the Huffman Tree and store Huffman Codes
// in a map.
void encode(Node* root, string str,
unordered_map<char, string> &huffmanCode)
{
if (root == nullptr)
return;
// found a leaf node
if (!root->left && !root->right) {
huffmanCode[root->ch] = str;
}
encode(root->left, str + "0", huffmanCode);
encode(root->right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
void decode(Node* root, int &index, string str)
{
if (root == nullptr) {
return;
}
// found a leaf node
if (!root->left && !root->right)
{
cout << root->ch;
return;
}
index++;
if (str[index] =='0')
decode(root->left, index, str);
else
decode(root->right, index, str);
}
// Builds Huffman Tree and decode given input text
void buildHuffmanTree(string text)
{
// count frequency of appearance of each character
// and store it in a map
unordered_map<char, int> freq;
for (char ch: text) {
freq[ch]++;
}
// Create a priority queue to store live nodes of
// Huffman tree;
priority_queue<Node*, vector<Node*>, comp> pq;
// Create a leaf node for each character and add it
// to the priority queue.
for (auto pair: freq) {
pq.push(getNode(pair.first, pair.second, nullptr, nullptr));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node *left = pq.top(); pq.pop();
Node *right = pq.top(); pq.pop();
// Create a new internal node with these two nodes
// as children and with frequency equal to the sum
// of the two nodes' frequencies. Add the new node
// to the priority queue.
int sum = left->freq + right->freq;
pq.push(getNode(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node* root = pq.top();
// traverse the Huffman Tree and store Huffman Codes
// in a map. Also prints them
unordered_map<char, string> huffmanCode;
encode(root, "", huffmanCode);
cout << "Huffman Codes are :n" << 'n';
for (auto pair: huffmanCode) {
cout << pair.first << " " << pair.second << 'n';
}
cout << "nOriginal string was :n" << text << 'n';
// print encoded string
string str = "";
for (char ch: text) {
str += huffmanCode[ch];
}
cout << "nEncoded string is :n" << str << 'n';
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
cout << "nDecoded string is: n";
while (index < (int)str.size() - 2) {
decode(root, index, str);
}
}
// Huffman coding algorithm
int main()
{
string text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
return 0;
}import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
// A Tree node
class Node
{
char ch;
int freq;
Node left = null, right = null;
Node(char ch, int freq)
{
this.ch = ch;
this.freq = freq;
}
public Node(char ch, int freq, Node left, Node right) {
this.ch = ch;
this.freq = freq;
this.left = left;
this.right = right;
}
};
class Huffman
{
// traverse the Huffman Tree and store Huffman Codes
// in a map.
public static void encode(Node root, String str,
Map<Character, String> huffmanCode)
{
if (root == null)
return;
// found a leaf node
if (root.left == null && root.right == null) {
huffmanCode.put(root.ch, str);
}
encode(root.left, str + "0", huffmanCode);
encode(root.right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
public static int decode(Node root, int index, StringBuilder sb)
{
if (root == null)
return index;
// found a leaf node
if (root.left == null && root.right == null)
{
System.out.print(root.ch);
return index;
}
index++;
if (sb.charAt(index) == '0')
index = decode(root.left, index, sb);
else
index = decode(root.right, index, sb);
return index;
}
// Builds Huffman Tree and huffmanCode and decode given input text
public static void buildHuffmanTree(String text)
{
// count frequency of appearance of each character
// and store it in a map
Map<Character, Integer> freq = new HashMap<>();
for (int i = 0 ; i < text.length(); i++) {
if (!freq.containsKey(text.charAt(i))) {
freq.put(text.charAt(i), 0);
}
freq.put(text.charAt(i), freq.get(text.charAt(i)) + 1);
}
// Create a priority queue to store live nodes of Huffman tree
// Notice that highest priority item has lowest frequency
PriorityQueue<Node> pq = new PriorityQueue<>(
(l, r) -> l.freq - r.freq);
// Create a leaf node for each character and add it
// to the priority queue.
for (Map.Entry<Character, Integer> entry : freq.entrySet()) {
pq.add(new Node(entry.getKey(), entry.getValue()));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node left = pq.poll();
Node right = pq.poll();
// Create a new internal node with these two nodes as children
// and with frequency equal to the sum of the two nodes
// frequencies. Add the new node to the priority queue.
int sum = left.freq + right.freq;
pq.add(new Node(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node root = pq.peek();
// traverse the Huffman tree and store the Huffman codes in a map
Map<Character, String> huffmanCode = new HashMap<>();
encode(root, "", huffmanCode);
// print the Huffman codes
System.out.println("Huffman Codes are :n");
for (Map.Entry<Character, String> entry : huffmanCode.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
System.out.println("nOriginal string was :n" + text);
// print encoded string
StringBuilder sb = new StringBuilder();
for (int i = 0 ; i < text.length(); i++) {
sb.append(huffmanCode.get(text.charAt(i)));
}
System.out.println("nEncoded string is :n" + sb);
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
System.out.println("nDecoded string is: n");
while (index < sb.length() - 2) {
index = decode(root, index, sb);
}
}
public static void main(String[] args)
{
String text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
}
}Nota: la memòria utilitzada per la cadena d'entrada és de 47 * 8 = 376 bits i la cadena codificada només és de 194 bits, és a dir. les dades es comprimeixen un 48%. Al programa C++ anterior, utilitzem la classe de cadena per emmagatzemar la cadena codificada per fer que el programa sigui llegible.
Perquè les estructures de dades de cua de prioritat eficients requereixen per inserció O(log(N)) temps, però en un arbre binari complet amb N fulles presents 2N-1 nodes, i l'arbre Huffman és un arbre binari complet, llavors s'executa l'algorisme O(Nlog(N)) temps, on N - Personatges.
Fonts:
Font: www.habr.com
