

Com podeu traduir els requisits empresarials en estructures de dades específiques utilitzant l'exemple de disseny d'una base de dades de missatgeria des de zero.
- Part 1: disseny del marc base

La nostra base no serà tan gran i distribuïda, o , però “així que fos”, però era bo: funcional, ràpid i cabre en un servidor PostgreSQL - perquè pugueu desplegar una instància separada del servei en algun lloc del costat, per exemple.
Per tant, no tocarem els problemes de fragmentació, replicació i sistemes geodistribuïts, sinó que ens centrarem en solucions de circuits dins de la base de dades.
Pas 1: algunes característiques empresarials
No dissenyarem els nostres missatges de manera abstracta, sinó que els integrarem a l'entorn . És a dir, la nostra gent no "només es correspon", sinó que es comuniquen entre elles en el context de resoldre determinats problemes empresarials.
I quines són les tasques d'un negoci?... Vegem l'exemple de Vasily, el cap del departament de desenvolupament.
- "Nikolai, per a aquesta tasca necessitem un pegat avui!"
Això vol dir que la correspondència es pot dur a terme en el context d'alguns document. - "Kolya, vas a Dota aquesta nit?"
És a dir, fins i tot una parella d'interlocutors es pot comunicar simultàniament sobre diversos temes. - "Peter, Nikolay, mira al fitxer adjunt la llista de preus del nou servidor".
Per tant, un missatge pot tenir diversos destinataris. En aquest cas, el missatge pot contenir Fitxers adjunts. - "Semyon, fes una ullada també."
I hi hauria d'haver l'oportunitat d'entrar a la correspondència existent convidar un nou membre.
Anem a detenir-nos ara en aquesta llista de necessitats "òbvies".
Sense comprendre les especificitats aplicades del problema i les limitacions que se li donen, dissenyar efectiu L'esquema de la base de dades per resoldre'l és gairebé impossible.
Pas 2: Circuit lògic mínim
Fins ara, tot funciona molt semblant a la correspondència per correu electrònic: una eina comercial tradicional. Sí, "algorítmicament" molts problemes empresarials són similars entre si, per tant, les eines per resoldre'ls seran estructuralment semblants.
Arreglem el diagrama lògic ja obtingut de les relacions d'entitats. Per facilitar la comprensió del nostre model, utilitzarem l'opció de visualització més primitiva sense les complicacions de les notacions UML o IDEF:
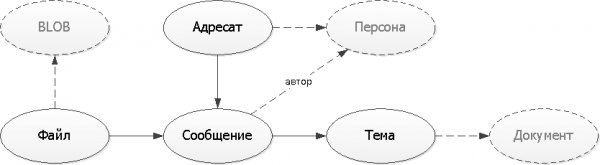
En el nostre exemple, la persona, el document i el "cos" binari del fitxer són entitats "externes" que existeixen de manera independent sense el nostre servei. Per tant, simplement els percebrem en el futur com alguns enllaços "en algun lloc" per UUID.
Dibuixa esquemes el més senzills possible - La majoria de les persones a qui els mostrareu no són experts en llegir UML/IDEF. Però assegureu-vos de dibuixar.
Pas 3: esbós de l'estructura de la taula
Sobre els noms de taules i campsEls noms "russos" de camps i taules es poden tractar de manera diferent, però això és una qüestió de gustos. Perquè el no hi ha desenvolupadors estrangers, i PostgreSQL ens permet donar noms fins i tot en jeroglífics, si tancat entre cometes, llavors preferim anomenar objectes de manera clara i inequívoca perquè no hi hagi discrepàncies.
Com que moltes persones ens escriuen missatges alhora, alguns d'ells fins i tot poden fer-ho fora de línia, llavors l'opció més senzilla és utilitzar UUID com a identificadors no només per a entitats externes, sinó també per a tots els objectes dins del nostre servei. A més, es poden generar fins i tot al costat del client; això ens ajudarà a enviar missatges quan la base de dades no estigui disponible temporalment i la probabilitat d'una col·lisió sigui extremadament baixa.
L'estructura de la taula esborrany a la nostra base de dades serà així:
Taules: RU
CREATE TABLE "Тема"(
"Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "Сообщение"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "Автор"
uuid
, "ДатаВремя"
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат"(
"Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл"(
"Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);Taules: EN
CREATE TABLE theme(
theme
uuid
PRIMARY KEY
, document
uuid
, title
text
);
CREATE TABLE message(
message
uuid
PRIMARY KEY
, theme
uuid
, author
uuid
, dt
timestamp
, body
text
);
CREATE TABLE message_addressee(
message
uuid
, person
uuid
, PRIMARY KEY(message, person)
);
CREATE TABLE message_file(
file
uuid
PRIMARY KEY
, message
uuid
, content
uuid
, filename
text
);El més senzill quan es descriu un format és començar a "desbobinar" el gràfic de connexió de taules que no estan referenciades ells mateixos a ningú.
Pas 4: esbrineu les necessitats no òbvies
Això és tot, hem dissenyat una base de dades en la qual pots escriure perfectament i d’alguna manera llegir.
Posem-nos a la pell de l'usuari del nostre servei: què en volem fer?
- Últims missatges
El ordenats cronològicament un registre dels "meus" missatges basat en diversos criteris. On sóc un dels destinataris, on sóc l'autor, on em van escriure i no vaig contestar, on no em van contestar,... - Participants de la correspondència
Qui participa fins i tot en aquesta llarga i llarga xerrada?
La nostra estructura ens permet resoldre aquests dos problemes "en general", però no ràpidament. El problema és que per ordenar dins de la primera tasca no es pot crear l'índex, apte per a cadascun dels participants (i hauràs d'extreure tots els registres), i per resoldre el segon cal extreu tots els missatges sobre aquest tema.
Les tasques d'usuari no desitjades poden posar en negreta creuar la productivitat.
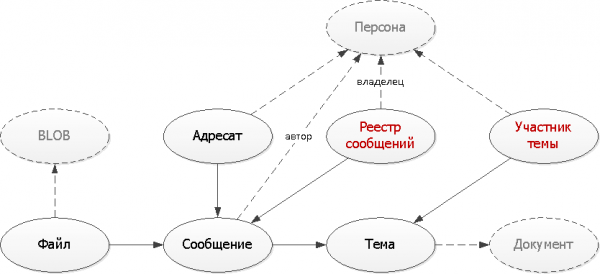
Pas 5: Desnormalització intel·ligent
Els nostres dos problemes es resoldran mitjançant taules addicionals en les quals ho farem duplicar part de les dades, necessaris per formar sobre ells índexs adequats a les nostres tasques.
Taules: RU
CREATE TABLE "РеестрСообщений"(
"Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
CREATE TABLE "УчастникТемы"(
"Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);Taules: EN
CREATE TABLE message_registry(
owner
uuid
, registry
smallint
, dt
timestamp
, message
uuid
, PRIMARY KEY(owner, registry, message)
);
CREATE INDEX ON message_registry(owner, registry, dt DESC);
CREATE TABLE theme_participant(
theme
uuid
, person
uuid
, PRIMARY KEY(theme, person)
);Aquí hem aplicat dos enfocaments típics utilitzats per crear taules auxiliars:
- Multiplicació de registres
Utilitzant un registre de missatge inicial, creem diversos registres de seguiment en diferents tipus de registres per a diferents propietaris, tant per al remitent com per al destinatari. Però cadascun dels registres ara cau a l'índex; després de tot, en un cas típic, voldríem veure només la primera pàgina. - Records únics
Cada vegada que envieu un missatge dins d'un tema concret, n'hi ha prou amb comprovar si aquesta entrada ja existeix. Si no, afegiu-lo al nostre "diccionari".
A la següent part de l'article en parlarem a l'estructura de la nostra base de dades.
Font: www.habr.com
