

Hem dissenyat amb èxit l'estructura de la nostra base de dades PostgreSQL per emmagatzemar correspondència, ha passat un any, els usuaris l'estan omplint activament i ara milions de registres, i... alguna cosa va començar a frenar-ho tot.
- Part 2: seccionar "benefici"

El fet és que amb el creixement del volum de la taula, també creix la "profunditat" dels índexs - encara que logarítmicament. Però amb el temps obliga al servidor a fer les mateixes tasques de lectura/escriptura processar moltes vegades més pàgines de dadesque al principi.
Aquí és on es tracta del rescat seccionament.
Observo que no es tracta de fragmentació, és a dir, de la distribució de dades entre diferents bases de dades o servidors. Perquè fins i tot dividint les dades per alguns servidors, no us desferreu del problema de la "inflació" dels índexs amb el pas del temps. Està clar que si us podeu permetre el luxe de posar en funcionament un nou servidor cada dia, els vostres problemes ja no estaran en el pla d'una base de dades concreta.
Considerarem no scripts específics per implementar particions "al maquinari", sinó l'enfocament en si mateix: què i com s'ha de "tallar en rodanxes" i a què comporta aquest desig.
Concepte
Un cop més, definim el nostre objectiu: volem assegurar-nos que avui, demà i un any després, la quantitat de dades llegides per PostgreSQL per a qualsevol operació de lectura/escriptura es mantingui aproximadament igual.
Per ningu dades acumulades cronològicament (missatges, documents, registres, arxius, ...) l'opció natural per a una clau de partició és data/hora de l'esdeveniment. En el nostre cas, aquest esdeveniment és el moment en què es va enviar el missatge.
Tingueu en compte que els usuaris gairebé sempre treballar només amb l'últim aquestes dades: llegeixen els missatges més recents, analitzen els registres més recents, ... No, és clar, poden desplaçar-se més enrere en el temps, només que ho fan molt poques vegades.
A partir d'aquestes restriccions, es fa obvi que la solució òptima per als missatges serà seccions "diàries". - al cap i a la fi, gairebé sempre el nostre usuari llegirà el que li va venir "avui" o "ahir".
Si escrivim i llegim pràcticament només en una secció durant el dia, això també ens dóna ús més eficient de la memòria i el disc - ja que tots els índexs de secció encaixen fàcilment a la memòria RAM, en contrast amb els "grans i grossos" de tota la taula.
pas a pas
En general, tot l'anterior sembla un gran benefici. I és possible, però per això haurem de treballar molt, perquè la decisió de partició d'una de les entitats porta a la necessitat de "serrar" i associar-se.
Missatge, les seves propietats i projeccions
Com que vam decidir tallar els missatges per dates, també és raonable dividir les propietats de l'entitat que en depenen (fitxers adjunts, llista de destinataris) i també per data de correu.
Com que una de les nostres tasques típiques és només veure els registres de missatges (no llegits, entrants, tots), també és lògic "dibuixar-los" en seccions per dates de missatges.
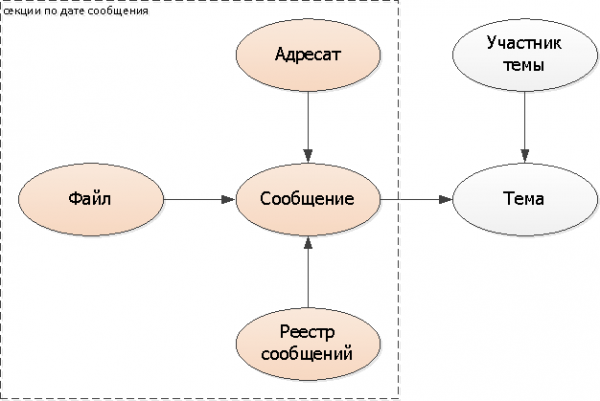
Afegim la clau de partició (data del missatge) a totes les taules: destinataris, fitxer, registres. No es pot afegir al missatge en si, però utilitzar el DateTime existent.
Темы
Com que el tema és un per a diversos missatges, no es podrà "tallar" en el mateix model, cal confiar en una altra cosa. Perfecte per al nostre cas. data del primer missatge de la correspondència - és a dir, el moment de la creació, de fet, del tema.
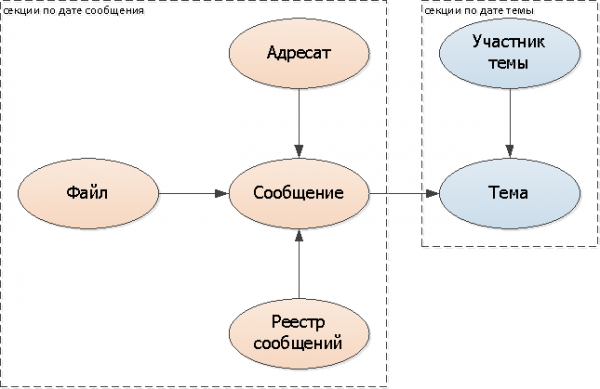
Afegiu una clau de partició (data de l'assumpte) a totes les taules: tema, membre.
Però ara tenim dos problemes alhora:
- en quina secció buscar missatges sobre el tema?
- en quina secció cercar el tema del missatge?
Pots, per descomptat, seguir cercant a totes les seccions, però serà molt trist i anul·larà tots els nostres guanys. Per tant, per saber on buscar exactament, farem enllaços lògics/apuntadors a seccions:
- afegir al missatge camp de data del tema
- afegir al tema data del missatge establerta aquesta correspondència (podeu utilitzar una taula separada, o podeu utilitzar una sèrie de dates)
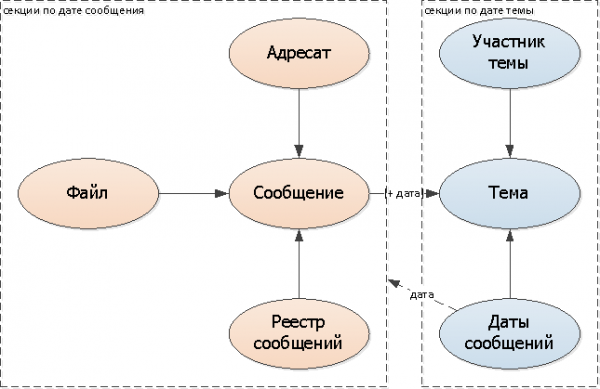
Com que hi haurà poques modificacions a la llista de dates dels missatges per a cada correspondència individual (després de tot, gairebé tots els missatges cauen en 1-2 dies adjacents), em centraré en aquesta opció.
En total, l'estructura de la nostra base de dades va prendre la forma següent, tenint en compte la partició:
Taules: RU
-- секции по дате сообщения
CREATE TABLE "Сообщение_YYYYMMDD"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "ДатаТемы"
date
, "Автор"
uuid
, "ДатаВремя" -- используем как дату
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат_YYYYMMDD"(
"ДатаСообщения"
date
, "Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл_YYYYMMDD"(
"ДатаСообщения"
date
, "Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);
CREATE TABLE "РеестрСообщений_YYYYMMDD"(
"ДатаСообщения"
date
, "Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений_YYYYMMDD"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
-- секции по дате темы
CREATE TABLE "Тема_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "УчастникТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);
CREATE TABLE "ДатыСообщенийТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Дата"
date
);
Estalvieu un bon cèntim
Bé, què passa si fem servir en funció de la distribució dels valors de camp (mitjançant activadors i herència o PARTITION BY), però "manualment" a nivell d'aplicació, notareu que el valor de la clau de partició ja està emmagatzemat al nom de la pròpia taula.
Així que si ets així estan molt preocupats per la quantitat de dades emmagatzemades, llavors podeu desfer-vos d'aquests camps "extra" i dirigir-vos específicament a taules específiques. És cert que totes les seleccions de diverses seccions en aquest cas ja s'hauran de transferir al costat de l'aplicació.
Font: www.habr.com
