

Avui dia, el servei Bitrix24 no té centenars de gigabits de trànsit, ni té una flota enorme de servidors (tot i que, és clar, n'hi ha força). Però per a molts clients és la principal eina per treballar a l'empresa, és una autèntica aplicació crítica per al negoci. Per tant, no hi ha manera de caure. Què passaria si l'accident va passar, però el servei es "recupera" tan ràpidament que ningú no es va adonar de res? I com és possible implementar el failover sense perdre la qualitat del treball i el nombre de clients? Alexander Demidov, director de serveis al núvol de Bitrix24, va parlar per al nostre bloc sobre com ha evolucionat el sistema de reserves al llarg dels 7 anys d'existència del producte.

"Vam llançar Bitrix24 com a SaaS fa 7 anys. La principal dificultat va ser probablement la següent: abans de llançar-se públicament com a SaaS, aquest producte simplement existia en el format d'una solució en caixa. Els clients ens el van comprar, el van allotjar als seus servidors, van configurar un portal corporatiu: una solució general per a la comunicació amb els empleats, l'emmagatzematge de fitxers, la gestió de tasques, el CRM, això és tot. I el 2012, vam decidir que volíem llançar-lo com a SaaS, administrant-lo nosaltres mateixos, assegurant la tolerància a errors i la fiabilitat. Vam guanyar experiència al llarg del camí, perquè fins aleshores simplement no en teníem: només érem fabricants de programari, no proveïdors de serveis.
A l'hora de posar en marxa el servei, vam entendre que el més important és garantir la tolerància a errors, la fiabilitat i la disponibilitat constant del servei, perquè si tens un lloc web normal i senzill, una botiga, per exemple, i recau sobre tu i s'asseu allà per una hora, només pateixes tu, perds comandes, perds clients, però per al teu propi client això no és molt crític per a ell. Estava molest, és clar, però el va anar a comprar en un altre lloc. I si es tracta d'una aplicació a la qual està lligada tota la feina dins de l'empresa, les comunicacions, les decisions, aleshores el més important és guanyar-se la confiança dels usuaris, és a dir, no defraudar-los i no caure. Perquè tot el treball pot aturar-se si alguna cosa dins no funciona.
Bitrix.24 com a SaaS
Vam muntar el primer prototip un any abans del llançament públic, el 2011. El vam muntar en aproximadament una setmana, el vam mirar, el vam girar, fins i tot funcionava. És a dir, podríeu entrar al formulari, introduir-hi el nom del portal, s'obriria un nou portal i es crearia una base d'usuaris. El vam mirar, vam valorar el producte en principi, el vam desballestar i vam continuar perfeccionant-lo durant tot un any. Com que teníem una gran tasca: no volíem fer dues bases de codi diferents, no volíem donar suport a un producte empaquetat separat, solucions al núvol separades; volíem fer-ho tot dins d'un codi.
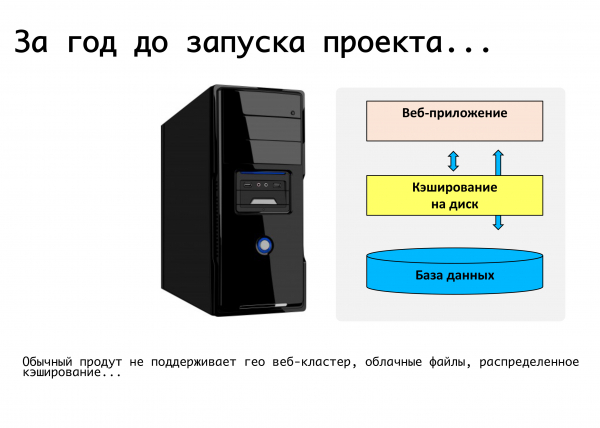
Una aplicació web típica en aquell moment era un servidor on s'executava algun codi PHP, una base de dades mysql, es penjaven fitxers, es posaven documents i imatges a la carpeta de càrrega, bé, tot funciona. Per desgràcia, és impossible llançar un servei web críticament estable amb això. Allà, la memòria cau distribuïda no és compatible, la replicació de bases de dades no és compatible.
Vam formular els requisits: aquesta és la capacitat d'ubicar-se en diferents ubicacions, de suportar la replicació i, idealment, d'estar situat en diferents centres de dades distribuïts geogràficament. Separeu la lògica del producte i, de fet, l'emmagatzematge de dades. Ser capaç d'escalar dinàmicament segons la càrrega i tolerar completament l'estàtica. D'aquestes consideracions, de fet, van sorgir els requisits del producte, que vam anar perfeccionant al llarg de l'any. Durant aquest temps, a la plataforma, que va resultar ser unificada -per a solucions en caixa, per al nostre propi servei- vam fer suport per aquelles coses que necessitàvem. Suport per a la replicació de mysql a nivell del propi producte: és a dir, el desenvolupador que escriu el codi no pensa en com es distribuiran les seves peticions, fa servir la nostra API i sabem com distribuir correctament les sol·licituds d'escriptura i lectura entre mestres. i esclaus.
Hem fet suport a nivell de producte per a diversos emmagatzematges d'objectes al núvol: emmagatzematge de Google, amazon s3, a més de suport per a open stack swift. Per tant, això va ser convenient tant per a nosaltres com a servei com per als desenvolupadors que treballen amb una solució empaquetada: si només utilitzen la nostra API per a la feina, no pensen en on es desarà finalment el fitxer, localment al sistema de fitxers o a l'emmagatzematge de fitxers objecte.
Com a resultat, de seguida vam decidir que reservaríem a nivell de tot el centre de dades. El 2012, ens vam llançar completament a Amazon AWS perquè ja teníem experiència amb aquesta plataforma: el nostre propi lloc web hi estava allotjat. Ens va atreure el fet que a cada regió Amazon té diverses zones de disponibilitat; de fet, (segons la seva terminologia) diversos centres de dades més o menys independents els uns dels altres i ens permeten reservar a nivell d'un centre de dades sencer: si falla de sobte, les bases de dades es repliquen mestre-mestre, es fa una còpia de seguretat dels servidors d'aplicacions web i les dades estàtiques es mouen a l'emmagatzematge d'objectes s3. La càrrega està equilibrada, en aquell moment per Amazon elb, però una mica més tard vam arribar als nostres propis equilibradors de càrrega, perquè necessitàvem una lògica més complexa.
El que volien és el que van aconseguir...
Totes les coses bàsiques que volíem assegurar -tolerància a errors dels propis servidors, aplicacions web, bases de dades- tot funcionava bé. L'escenari més senzill: si una de les nostres aplicacions web falla, tot és senzill: es desactiva l'equilibri.
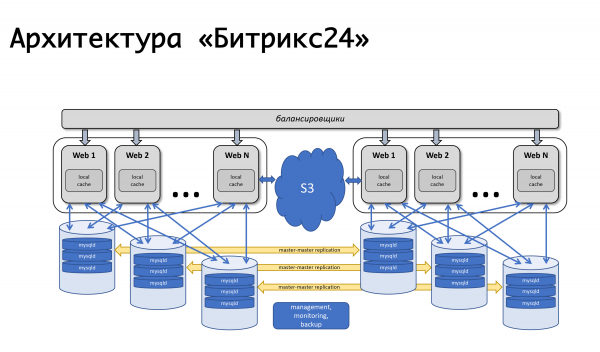
L'equilibrador (en aquell moment era el elb d'Amazon) va marcar les màquines que estaven fora de servei com a insalubres i va desactivar la distribució de càrrega. L'escalat automàtic d'Amazon va funcionar: quan la càrrega va créixer, s'hi van afegir noves màquines al grup d'escalat automàtic, la càrrega es va distribuir a màquines noves; tot estava bé. Amb els nostres equilibradors, la lògica és aproximadament la mateixa: si li passa alguna cosa al servidor d'aplicacions, eliminem les sol·licituds d'aquest, llencem aquestes màquines, en posem de noves i continuem treballant. L'esquema ha canviat una mica amb els anys, però continua funcionant: és senzill, comprensible i no hi ha dificultats.
Treballem a tot el món, els pics de càrrega dels clients són completament diferents i, d'una manera amistosa, hauríem de poder dur a terme determinats treballs de servei en qualsevol dels components del nostre sistema en qualsevol moment, sense que els clients s'apercebin. Per tant, tenim l'oportunitat de desactivar la base de dades del funcionament, redistribuint la càrrega a un segon centre de dades.
Com funciona tot? — Canviem el trànsit a un centre de dades que funcioni: si hi ha un accident al centre de dades, llavors completament, si aquest és el nostre treball previst amb una base de dades, canviem part del trànsit que serveix aquests clients a un segon centre de dades, suspendint la seva replicació. Si es necessiten màquines noves per a aplicacions web perquè la càrrega del segon centre de dades ha augmentat, s'iniciaran automàticament. Acabem el treball, es restaura la rèplica i retornem tota la càrrega. Si necessitem reflectir algun treball al segon DC, per exemple, instal·lar actualitzacions del sistema o canviar la configuració a la segona base de dades, en general, repetim el mateix, només en l'altra direcció. I si això és un accident, ho fem tot de manera trivial: fem servir el mecanisme de gestors d'esdeveniments al sistema de monitorització. Si es desencadenen diverses comprovacions i l'estat passa a crític, executem aquest controlador, un controlador que pot realitzar aquesta o aquella lògica. Per a cada base de dades, especifiquem quin servidor és la migració per error i on s'ha de canviar el trànsit si no està disponible. Històricament, fem servir nagios o algunes de les seves forquilles d'una forma o una altra. En principi, existeixen mecanismes similars en gairebé qualsevol sistema de monitorització; encara no fem servir res més complex, però potser algun dia ho farem. Ara la supervisió s'activa per la indisponibilitat i té la capacitat de canviar alguna cosa.
Ho tenim tot reservat?
Tenim molts clients dels EUA, molts clients d'Europa, molts clients que estan més a prop de l'Est: Japó, Singapur, etc. Per descomptat, una gran part dels clients es troben a Rússia. És a dir, el treball no és en una regió. Els usuaris volen una resposta ràpida, hi ha requisits per complir amb diverses lleis locals, i dins de cada regió reservem dos centres de dades, a més d'hi ha alguns serveis addicionals, que, de nou, són còmodes de col·locar dins d'una regió, per als clients que es troben a aquesta regió està treballant. Els gestors REST, servidors d'autorització, són menys crítics per al funcionament del client en conjunt, podeu canviar-los amb un petit retard acceptable, però no voleu reinventar la roda sobre com controlar-los i què fer. amb ells. Per tant, estem intentant utilitzar les solucions existents al màxim, en lloc de desenvolupar algun tipus de competència en productes addicionals. I en algun lloc utilitzem trivialment la commutació a nivell de DNS i determinem la vivacitat del servei pel mateix DNS. Amazon té un servei Route 53, però no és només un DNS al qual podeu fer entrades i ja està: és molt més flexible i còmode. A través d'ell podeu construir serveis geodistribuïts amb geolocalitzacions, quan ho feu servir per determinar d'on prové el client i donar-li determinats registres: amb la seva ajuda podeu construir arquitectures de failover. Les mateixes comprovacions de salut es configuren a la mateixa Ruta 53, establiu els punts finals que es monitoritzen, establiu mètriques, establiu quins protocols per determinar la "vivència" del servei: tcp, http, https; establir la freqüència de les comprovacions que determinen si el servei està viu o no. I al mateix DNS especifiqueu què serà principal, què serà secundari, on canviar si la comprovació de salut s'activa dins de la ruta 53. Tot això es pot fer amb algunes altres eines, però per què és convenient: ho configurem aixequem una vegada i després no hi pensis gens com fem les comprovacions, com canviem: tot funciona sol.
El primer "però": com i amb què reservar la mateixa ruta 53? Qui sap, què passa si li passa alguna cosa? Afortunadament, mai vam trepitjar aquest rastell, però de nou, tindreu una història per davant de per què vam pensar que encara havíem de fer una reserva. Aquí ens vam posar palletes per endavant. Diverses vegades al dia fem una descàrrega completa de totes les zones que tenim a la ruta 53. L'API d'Amazon us permet enviar-los fàcilment en JSON, i tenim diversos servidors de còpia de seguretat on el convertim, el pugem en forma de configuracions i disposem, a grans trets, d'una configuració de còpia de seguretat. Si passa alguna cosa, podem implementar-lo ràpidament manualment sense perdre les dades de configuració de DNS.
Segon "però": Què d'aquesta imatge encara no s'ha reservat? El propi equilibrador! La nostra distribució de clients per regió és molt senzilla. Tenim els dominis bitrix24.ru, bitrix24.com, .de; ara n'hi ha 13 de diferents, que operen en una varietat de zones. Hem arribat al següent: cada regió té els seus propis equilibradors. Això fa que sigui més convenient distribuir entre regions, depenent d'on es trobi la càrrega màxima a la xarxa. Si es tracta d'una fallada a nivell d'un equilibrador únic, simplement es treu del servei i s'elimina del dns. Si hi ha algun problema amb un grup d'equilibradors, es fa una còpia de seguretat en altres llocs i el canvi entre ells es fa mitjançant la mateixa ruta53, perquè a causa del TTL curt, el canvi es produeix en un màxim de 2, 3, 5 minuts. .
Tercer "però": Què encara no està reservat? S3, correcte. Quan vam col·locar els fitxers que emmagatzemem per als usuaris a s3, vam creure sincerament que perforava l'armadura i no calia reservar-hi res. Però la història demostra que les coses passen d'una altra manera. En general, Amazon descriu S3 com un servei fonamental, perquè el mateix Amazon utilitza S3 per emmagatzemar imatges de màquina, configuracions, imatges AMI, instantànies... I si s3 falla, com va passar una vegada durant aquests 7 anys, sempre que estem utilitzant bitrix24, el segueix com un fan. Hi ha un munt de coses que apareixen: incapacitat per iniciar màquines virtuals, fallada de l'API, etc.
I S3 pot caure: va passar una vegada. Per tant, vam arribar al següent esquema: fa uns anys no hi havia instal·lacions públiques d'emmagatzematge d'objectes seriosos a Rússia, i vam plantejar l'opció de fer alguna cosa pròpia... Afortunadament, no vam començar a fer-ho, perquè ho faríem. hem aprofundit en l'experiència que no tenim, i probablement ens embrutaria. Ara Mail.ru té emmagatzematge compatible amb s3, Yandex el té i molts altres proveïdors el tenen. Finalment vam arribar a la idea que volíem tenir, en primer lloc, una còpia de seguretat i, en segon lloc, la capacitat de treballar amb còpies locals. Per a la regió russa específicament, utilitzem el servei Mail.ru Hotbox, que és compatible amb l'API amb s3. No vam necessitar cap modificació important al codi dins de l'aplicació, i vam fer el següent mecanisme: a s3 hi ha activadors que desencadenen la creació/supressió d'objectes, Amazon té un servei anomenat Lambda: aquest és un llançament de codi sense servidor. que s'executarà just quan es desencadenen determinats activadors.
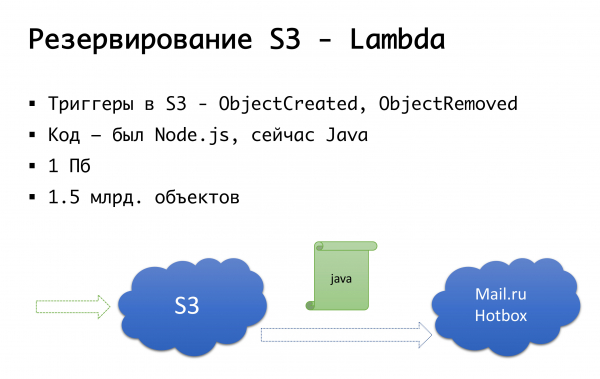
Ho vam fer de manera molt senzilla: si el nostre activador s'activa, executem codi que copiarà l'objecte a l'emmagatzematge de Mail.ru. Per iniciar completament el treball amb còpies locals de dades, també necessitem la sincronització inversa perquè els clients que es troben al segment rus puguin treballar amb un emmagatzematge més proper. El correu està a punt de completar els activadors al seu emmagatzematge: serà possible realitzar una sincronització inversa a nivell d'infraestructura, però de moment ho fem a nivell del nostre propi codi. Si veiem que un client ha publicat un fitxer, a nivell de codi col·loquem l'esdeveniment en una cua, el processem i fem una replicació inversa. Per què és dolent: si fem algun tipus de treball amb els nostres objectes fora del nostre producte, és a dir, per algun mitjà extern, no ho tindrem en compte. Per tant, esperem fins al final, quan apareixen els disparadors a nivell d'emmagatzematge, de manera que des d'on executem el codi, l'objecte que ens ha arribat es copia en l'altra direcció.
A nivell de codi, registrem els dos emmagatzematges per a cada client: un es considera el principal, l'altre es considera una còpia de seguretat. Si tot va bé, treballem amb l'emmagatzematge més proper: és a dir, els nostres clients que estan a Amazon, treballen amb S3, i els que treballen a Rússia, treballen amb Hotbox. Si s'activa la marca, s'hauria de connectar la migració per error i canviarem els clients a un altre emmagatzematge. Podem marcar aquesta casella de manera independent per regió i podem canviar-les d'anada i tornada. Encara no l'hem utilitzat a la pràctica, però hem previst aquest mecanisme i pensem que algun dia necessitarem aquest interruptor i serà útil. Això ja ha passat una vegada.
Ah, i Amazon va fugir...
Aquest mes d'abril es commemora l'aniversari de l'inici del bloqueig de Telegram a Rússia. El proveïdor més afectat que va caure sota això és Amazon. I, malauradament, les empreses russes que treballaven per a tot el món van patir més.
Si l'empresa és global i Rússia és un segment molt petit per a ella, un 3-5%, bé, d'una manera o una altra, podeu sacrificar-los.
Si es tracta d'una empresa purament russa, estic segur que s'ha de localitzar localment, bé, simplement serà convenient per als mateixos usuaris, còmode i hi haurà menys riscos.
Què passa si es tracta d'una empresa que opera a nivell mundial i té aproximadament el mateix nombre de clients de Rússia i d'arreu del món? La connectivitat dels segments és important, i han de treballar entre si d'una manera o altra.
A finals de març de 2018, Roskomnadzor va enviar una carta als operadors més grans informant-los dels seus plans per bloquejar diversos milions d'adreces IP d'Amazon per tal de bloquejar... el missatger Zello. Gràcies a aquests mateixos proveïdors, van aconseguir filtrar la carta a tothom i va quedar clar que la connectivitat amb Amazon podria col·lapsar. Era divendres i vam córrer espantats als nostres companys de servers.ru dient: "Amics, necessitem diversos servidors que no seran a Rússia, no a Amazon, sinó, per exemple, en algun lloc d'Amsterdam", per tal que almenys d'alguna manera puguem configurar-hi els nostres propis servidors. vpn I els proxies per a alguns punts finals sobre els quals no tenim control, com els punts finals S3: no podem intentar configurar un servei nou i obtenir una adreça IP diferent; encara necessitem poder arribar-hi. En pocs dies, teníem aquests servidors configurats, en funcionament i bàsicament estàvem preparats perquè comencés el bloqueig. Curiosament, Roskomnadzor, després de veure l'enrenou i el pànic, va dir: "No, no estem bloquejant res ara mateix". (Però això va ser fins al moment en què van començar a bloquejar Telegram.) Després de configurar opcions d'evitació i adonar-nos que el bloqueig no s'havia implementat, vam decidir no investigar-ho tot. Per si de cas.

I el 2019, encara vivim en condicions de bloqueig. Vaig mirar ahir a la nit: un milió d'IPs continuen bloquejades. És cert que Amazon es va desbloquejar quasi del tot, en el seu punt àlgid va arribar als 20 milions d'adreces... En general, la realitat és que potser no hi ha coherència, bona coherència. De sobte. Potser no existeix per motius tècnics: incendis, excavadores, tot això. O, com hem vist, no del tot tècnics. Per tant, algú gran i gran, amb els seus propis AS, probablement pot gestionar-ho d'altres maneres: la connexió directa i altres coses ja estan al nivell l2. Però en una versió senzilla, com la nostra o fins i tot més petita, podeu, per si de cas, tenir redundància a nivell de servidors plantejats en un altre lloc, configurats prèviament vpn, proxy, amb la possibilitat de canviar-los ràpidament la configuració en aquests segments. que són crítics per a la vostra connectivitat. Això ens va ser útil més d'una vegada, quan va començar el bloqueig d'Amazon; en el pitjor dels casos, només vam permetre el trànsit S3 a través d'ells, però a poc a poc tot es va resoldre.
Com reservar... un proveïdor sencer?
Ara mateix no tenim un escenari en cas que tot Amazon cau. Tenim un escenari similar per a Rússia. A Rússia, vam ser allotjats per un proveïdor, del qual vam triar tenir diversos llocs. I fa un any ens vam enfrontar a un problema: tot i que es tracta de dos centres de dades, és possible que ja hi hagi problemes a nivell de configuració de xarxa del proveïdor que encara afectaran els dos centres de dades. I és possible que acabem no disponible als dos llocs. És clar que això va passar. Vam acabar replantejant l'arquitectura interior. No ha canviat gaire, però per a Rússia ara tenim dos llocs, que no són del mateix proveïdor, sinó de dos diferents. Si un falla, podem canviar a l'altre.
Hipotèticament, per a Amazon estem considerant la possibilitat de reservar a nivell d'un altre proveïdor; potser Google, potser algú altre... Però fins ara hem observat a la pràctica que si bé Amazon té accidents a nivell d'una zona de disponibilitat, els accidents a nivell de tota una regió són força rars. Per tant, teòricament tenim la idea que podríem fer una reserva "Amazon no és Amazon", però a la pràctica encara no és així.
Unes paraules sobre l'automatització
L'automatització és sempre necessària? Aquí convé recordar l'efecte Dunning-Kruger. A l'eix "x" hi ha el nostre coneixement i experiència que obtenim, i a l'eix "y" hi ha la confiança en les nostres accions. Al principi no sabem res i no estem gens segurs. Aleshores en sabem una mica i ens tornem mega-confiats: aquest és l'anomenat "pic de l'estupidesa", ben il·lustrat per la imatge "demència i coratge". Després hem après una mica i estem preparats per entrar a la batalla. Aleshores trepitgem alguns errors mega-greus i ens trobem en una vall de desesperació, quan sembla que sabem alguna cosa, però de fet no en sabem gaire. Aleshores, a mesura que anem guanyant experiència, ens tornem més segurs.
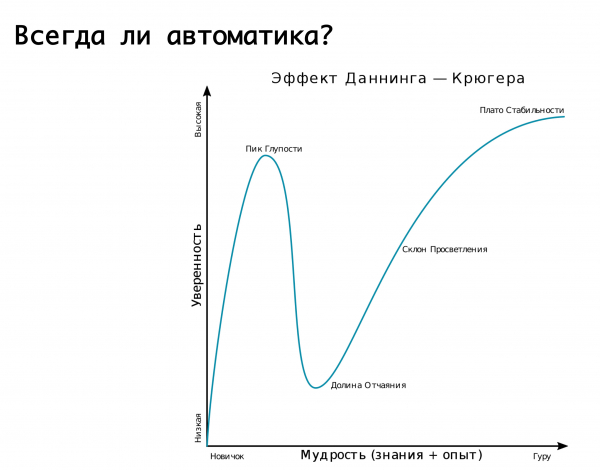
La nostra lògica sobre diversos canvis automàtics a determinats accidents està molt ben descrita en aquest gràfic. Vam començar: no sabíem com fer res, gairebé tota la feina es feia a mà. Aleshores ens vam adonar que podríem connectar l'automatització a tot i, com, dormir tranquils. I de sobte trepitgem un mega-rake: s'activa un fals positiu i canviem el trànsit d'anada i tornada quan, en el bon sentit, no hauríem d'haver fet això. En conseqüència, la replicació es trenca o una altra cosa: aquesta és la mateixa vall de la desesperació. I llavors arribem a la comprensió que hem d'abordar-ho tot amb prudència. És a dir, té sentit confiar en l'automatització, que preveu la possibilitat de falses alarmes. Però! si les conseqüències poden ser devastadores, llavors és millor deixar-ho al torn de servei, als enginyers de torn, que s'asseguraran i controlaran que realment hi hagi un accident, i realitzaran manualment les accions necessàries...
Conclusió
Al llarg de 7 anys hem passat del fet que quan cau alguna cosa, hi ha pànic-pànic, a entendre que els problemes no existeixen, només hi ha tasques, s'han -i poden- resoldre. Quan esteu construint un servei, mireu-lo des de dalt, avalueu tots els riscos que poden passar. Si els veieu de seguida, preveu la redundància per endavant i la possibilitat de construir una infraestructura tolerant a fallades, perquè qualsevol punt que pugui fallar i conduir a la inoperabilitat del servei ho farà definitivament. I encara que us sembli que alguns elements de la infraestructura definitivament no fallaran, com el mateix s3, tingueu en compte que sí. I almenys en teoria, tingueu una idea de què en fareu si passa alguna cosa. Tenir un pla de gestió de riscos. Quan estigueu pensant a fer-ho tot automàticament o manualment, avalueu els riscos: què passarà si l'automatització comença a canviar-ho tot?, això no comportarà una situació encara pitjor en comparació amb un accident? Potser en algun lloc cal utilitzar un compromís raonable entre l'ús de l'automatització i la reacció de l'enginyer de servei, que avaluarà la imatge real i entendrà si cal canviar alguna cosa al moment o "sí, però no ara".
Un compromís raonable entre el perfeccionisme i l'esforç real, el temps, els diners que podeu gastar en l'esquema que finalment tindreu.
Aquest text és una versió actualitzada i ampliada de l'informe d'Alexander Demidov a la conferència .
Font: www.habr.com
