


Hola a tothom! Em dic Dmitry Samsonov i treballo com a administrador principal de sistemes a Odnoklassniki. Tenim més de 7 servidors físics, 11 contenidors al núvol i 200 aplicacions, que en diverses configuracions formen 700 clústers diferents. La gran majoria dels servidors s'executen... CentOS 7.
El 14 d'agost de 2018 es va publicar informació sobre la vulnerabilitat FragmentSmack
() i SegmentSmack (). Es tracta de vulnerabilitats amb un vector d'atac a la xarxa i una puntuació força alta (7.5), que amenaça amb la denegació de servei (DoS) a causa de l'esgotament dels recursos (CPU). En aquell moment no es va proposar una solució del nucli per a FragmentSmack; a més, va sortir molt més tard de la publicació d'informació sobre la vulnerabilitat. Per eliminar SegmentSmack, es va suggerir actualitzar el nucli. El mateix dia es va publicar el paquet d'actualització, només quedava instal·lar-lo.
No, no estem en absolut en contra d'actualitzar el nucli! Tanmateix, hi ha matisos...
Com actualitzem el nucli en producció
En general, res complicat:
- Descarregar paquets;
- Instal·leu-los en diversos servidors (inclosos servidors que allotgen el nostre núvol);
- Assegureu-vos que no es trenqui res;
- Assegureu-vos que tots els paràmetres estàndard del nucli s'apliquen sense errors;
- Espera uns dies;
- Comproveu el rendiment del servidor;
- Canvia el desplegament de nous servidors al nou nucli;
- Actualitzeu tots els servidors per centre de dades (un centre de dades a la vegada per minimitzar l'efecte sobre els usuaris en cas de problemes);
- Reinicieu tots els servidors.
Repetiu per a totes les branques dels nuclis que tenim. De moment és:
- Estoc CentOS 7 3.10 - per a la majoria de servidors normals;
- Vainilla 4.19 - per als nostres , perquè necessitem BFQ, BBR, etc.;
- Elrepo kernel-ml 5.2 - per a , perquè 4.19 solia tenir un comportament inestable, però calen les mateixes característiques.
Com haureu endevinat, reiniciar milers de servidors triga el temps més llarg. Com que no totes les vulnerabilitats són crítiques per a tots els servidors, només reiniciem aquells als quals es pot accedir directament des d'Internet. Al núvol, per no limitar la flexibilitat, no lliguem contenidors accessibles externament a servidors individuals amb un nucli nou, sinó que reiniciem tots els amfitrions sense excepció. Afortunadament, el procediment allà és més senzill que amb els servidors habituals. Per exemple, els contenidors sense estat només poden moure's a un altre servidor durant un reinici.
No obstant això, encara hi ha molta feina, i pot trigar diverses setmanes, i si hi ha cap problema amb la nova versió, fins a uns quants mesos. Els atacants ho entenen molt bé, així que necessiten un pla B.
FragmentSmack/SegmentSmack. Solució alternativa
Afortunadament, per a algunes vulnerabilitats existeix un pla B, i s'anomena Solució alternativa. Molt sovint, es tracta d'un canvi en la configuració del nucli/aplicació que pot minimitzar el possible efecte o eliminar completament l'explotació de vulnerabilitats.
En el cas de FragmentSmack/SegmentSmack aquesta solució alternativa:
«Podeu canviar els valors per defecte de 4MB i 3MB a net.ipv4.ipfrag_high_thresh i net.ipv4.ipfrag_low_thresh (i els seus homòlegs per a ipv6 net.ipv6.ipfrag_high_thresh i net.ipv6.ipfrag_low_thresh) a 256 kB i respectivament més baix. Les proves mostren caigudes petites o significatives en l'ús de la CPU durant un atac depenent del maquinari, la configuració i les condicions. Tanmateix, pot haver-hi algun impacte en el rendiment a causa de ipfrag_high_thresh=192 bytes, ja que només dos fragments de 262144K poden cabre a la cua de muntatge alhora. Per exemple, hi ha el risc que les aplicacions que funcionen amb paquets UDP grans es trenquin».
Els propis paràmetres descrit de la següent manera:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
No tenim grans UDP en serveis de producció. No hi ha trànsit fragmentat a la LAN; hi ha trànsit fragmentat a la WAN, però no significatiu. No hi ha cap senyal: podeu implementar una solució alternativa!
FragmentSmack/SegmentSmack. Primera sang
El primer problema que vam trobar va ser que els contenidors del núvol de vegades aplicaven la nova configuració només parcialment (només ipfrag_low_thresh) i de vegades no les aplicaven en absolut; simplement es van estavellar al principi. No va ser possible reproduir el problema de manera estable (tots els paràmetres es van aplicar manualment sense cap dificultat). Entendre per què el contenidor s'estavella a l'inici tampoc és tan fàcil: no s'han trobat errors. Una cosa era certa: el fet de revertir la configuració resol el problema dels bloquejos de contenidors.
Per què no n'hi ha prou amb aplicar Sysctl a l'amfitrió? El contenidor viu al seu propi espai de noms de xarxa dedicat, almenys al contenidor pot diferir de l'amfitrió.
Com s'aplica exactament la configuració de Sysctl al contenidor? Com que els nostres contenidors no tenen privilegis, no podreu canviar cap configuració de Sysctl entrant al propi contenidor; simplement no teniu prou drets. Per executar contenidors, el nostre núvol en aquell moment utilitzava Docker (ara ). Els paràmetres del nou contenidor es van passar a Docker mitjançant l'API, inclosa la configuració necessària de Sysctl.
En cercar entre les versions, va resultar que l'API de Docker no va retornar tots els errors (almenys a la versió 1.10). Quan vam intentar iniciar el contenidor mitjançant "docker run", finalment vam veure almenys alguna cosa:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
El valor del paràmetre no és vàlid. Però perquè? I per què no és vàlid només de vegades? Va resultar que Docker no garanteix l'ordre en què s'apliquen els paràmetres Sysctl (l'última versió provada és la 1.13.1), de manera que de vegades ipfrag_high_thresh intentava establir-se a 256K quan ipfrag_low_thresh encara era de 3M, és a dir, el límit superior era inferior. que el límit inferior, que va provocar l'error.
En aquell moment, ja vam utilitzar el nostre propi mecanisme per reconfigurar el contenidor després de l'inici (congelar el contenidor després i executant ordres a l'espai de noms del contenidor via ), i també hem afegit paràmetres d'escriptura Sysctl a aquesta part. El problema es va resoldre.
FragmentSmack/SegmentSmack. Primera sang 2
Abans que tinguéssim temps d'entendre l'ús de Workaround al núvol, van començar a arribar les primeres queixes rares dels usuaris. En aquell moment, havien passat diverses setmanes des que es va començar a utilitzar la solució alternativa als primers servidors. La investigació inicial va demostrar que es van rebre queixes contra serveis individuals, i no tots els servidors d'aquests serveis. El problema ha tornat a ser extremadament incert.
Primer de tot, vam intentar revertir la configuració del Sysctl, però no va tenir cap efecte. Diverses manipulacions de la configuració del servidor i de l'aplicació tampoc van ajudar. Un reinici va ajudar. Reinicieu per a Linux tan antinatural com era una condició normal per treballar amb Windows Antigament. Funcionava, però, i ho vam atribuir a un "error del nucli" en aplicar la nova configuració del Sysctl. Que ximples que hem estat...
Tres setmanes després, el problema va tornar a repetir-se. La configuració d'aquests servidors era bastant senzilla: Nginx en mode proxy/equilibrador. Poc trànsit. Nova nota introductòria: el nombre d'errors 504 als clients augmenta cada dia (). El gràfic mostra el nombre d'errors 504 per dia per a aquest servei:
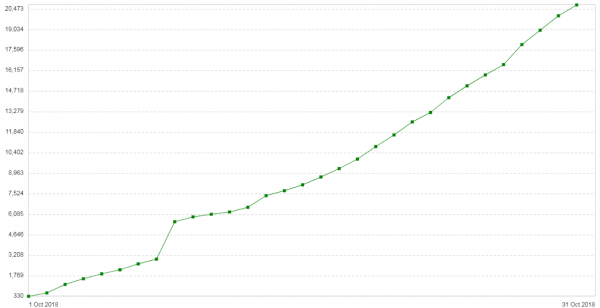
Tots els errors són aproximadament el mateix backend, sobre el que hi ha al núvol. El gràfic de consum de memòria per als fragments de paquets d'aquest backend tenia aquest aspecte:
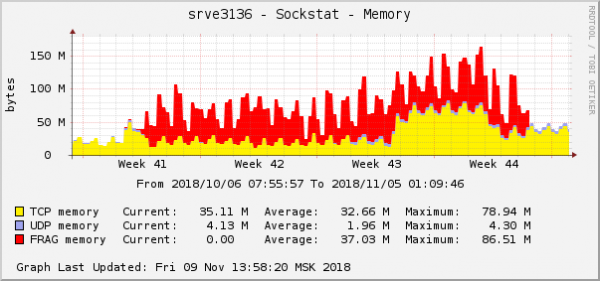
Aquesta és una de les manifestacions més òbvies del problema en els gràfics del sistema operatiu. Al núvol, al mateix temps, es va solucionar un altre problema de xarxa amb la configuració de QoS (control de trànsit). Al gràfic del consum de memòria dels fragments de paquets, semblava exactament igual:
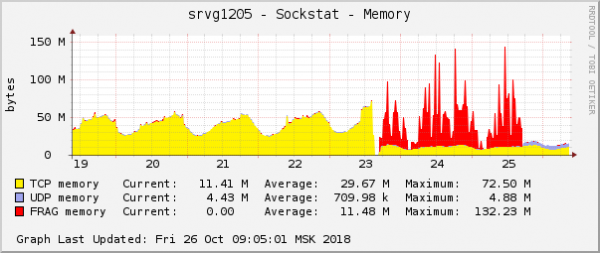
La suposició era senzilla: si tenen el mateix aspecte als gràfics, llavors tenen el mateix motiu. A més, qualsevol problema amb aquest tipus de memòria és extremadament rar.
L'essència del problema solucionat va ser que vam utilitzar el programador de paquets fq amb la configuració predeterminada a QoS. Per defecte, per a una connexió, permet afegir 100 paquets a la cua, i algunes connexions, en situacions d'escassetat de canals, van començar a obstruir la cua fins a la seva capacitat. En aquest cas, els paquets s'eliminen. A tc statistics (tc -s qdisc) es pot veure així:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545 flows_plimit" són els paquets abandonats a causa de la superació del límit de la cua d'una connexió, i "dropped 464545" és la suma de tots els paquets abandonats d'aquest planificador. Després d'augmentar la longitud de la cua a 1 i reiniciar els contenidors, el problema va deixar de produir-se. Pots seure i beure un batut.
FragmentSmack/SegmentSmack. Última Sang
En primer lloc, diversos mesos després que s'anunciessin les vulnerabilitats del nucli, finalment es va publicar una correcció per a FragmentSmack (recordeu que l'anunci d'agost només va publicar una correcció per a SegmentSmack), cosa que ens va donar l'oportunitat d'abandonar Workaround, que ens havia causat força problemes. Ja havíem migrat alguns servidors al nou nucli durant aquest temps i ara havíem de començar de zero. Per què vam actualitzar el nucli sense esperar la correcció de FragmentSmack? El fet és que el procés de protecció contra aquestes vulnerabilitats va coincidir (i es va fusionar) amb el procés d'actualització del mateix Workaround. CentOS (cosa que triga fins i tot més que actualitzar només el nucli). A més, SegmentSmack és una vulnerabilitat més perillosa, i hi havia una solució disponible immediatament, així que tenia sentit de totes maneres. Tanmateix, simplement actualitzar el nucli CentOS no vam poder a causa de la vulnerabilitat de FragmentSmack que va aparèixer durant el CentOS La versió 7.5 només es va solucionar a la versió 7.6, així que vam haver d'aturar l'actualització a la 7.5 i començar de nou amb l'actualització a la 7.6. Això també passa.
En segon lloc, ens han tornat les queixes rares dels usuaris sobre problemes. Ara ja sabem del cert que tots estan relacionats amb la pujada d'arxius dels clients a alguns dels nostres servidors. A més, un nombre molt reduït de càrregues de la massa total van passar per aquests servidors.
Com recordem de la història anterior, tornar Sysctl no va ajudar. El reinici va ajudar, però temporalment.
Les sospites respecte a Sysctl no es van eliminar, però aquesta vegada va ser necessari recollir la màxima informació possible. També hi havia una gran manca de capacitat per reproduir el problema de càrrega al client per tal d'estudiar amb més precisió què estava passant.
L'anàlisi de totes les estadístiques i registres disponibles no ens va apropar a entendre què estava passant. Hi havia una manca aguda de capacitat per reproduir el problema per tal de "sentir" una connexió específica. Finalment, els desenvolupadors, utilitzant una versió especial de l'aplicació, van aconseguir una reproducció estable dels problemes en un dispositiu de prova quan es connectava mitjançant Wi-Fi. Aquest va ser un avenç en la investigació. El client es va connectar a Nginx, que es va enviar al backend, que era la nostra aplicació Java.
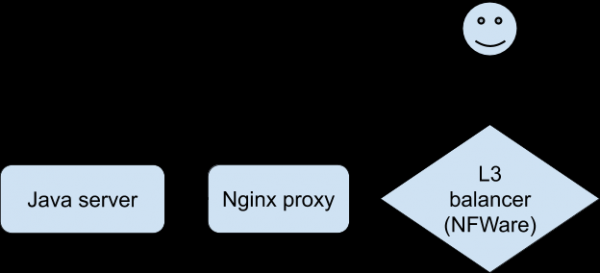
El diàleg per als problemes era així (corregit al costat del servidor intermediari Nginx):
- Client: sol·licitud de rebre informació sobre la baixada d'un fitxer.
- Servidor Java: resposta.
- Client: POST amb fitxer.
- Servidor Java: error.
Al mateix temps, el servidor Java escriu al registre que s'han rebut 0 bytes de dades del client i el servidor intermediari Nginx escriu que la sol·licitud va trigar més de 30 segons (30 segons és el temps d'espera de l'aplicació client). Per què el temps d'espera i per què 0 bytes? Des d'una perspectiva HTTP, tot funciona com hauria de ser, però el POST amb el fitxer sembla desaparèixer de la xarxa. A més, desapareix entre el client i Nginx. És hora d'armar-se amb Tcpdump! Però primer heu d'entendre la configuració de la xarxa. El proxy Nginx està darrere de l'equilibrador L3 . El túnel s'utilitza per lliurar paquets des de l'equilibrador L3 al servidor, que afegeix les seves capçaleres als paquets:
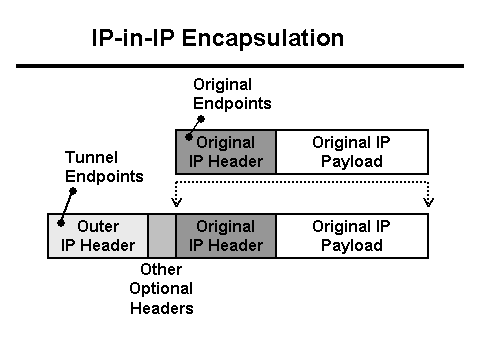
En aquest cas, la xarxa arriba a aquest servidor en forma de trànsit etiquetat amb Vlan, que també afegeix els seus propis camps als paquets:
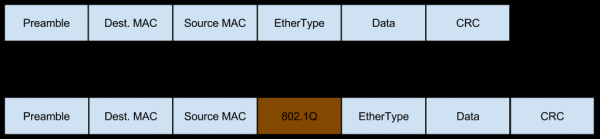
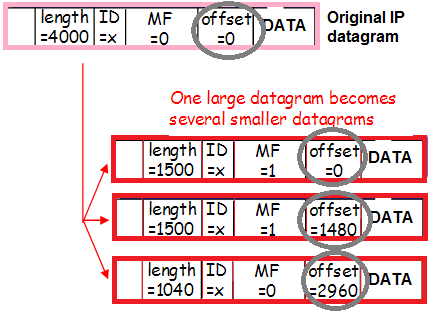
I aquest trànsit també es pot fragmentar (el mateix petit percentatge de trànsit fragmentat entrant del qual parlàvem a l'hora d'avaluar els riscos de la solució alternativa), cosa que també modifica el contingut de les capçaleres:
Una vegada més: els paquets s'encapsulen amb una etiqueta Vlan, s'encapsulen amb un túnel, es fragmenten. Per entendre millor com passa això, tracem la ruta del paquet des del client fins al servidor intermediari Nginx.
- El paquet arriba a l'equilibrador L3. Per a l'encaminament correcte dins del centre de dades, el paquet s'encapsula en un túnel i s'envia a la targeta de xarxa.
- Com que les capçaleres de paquet + túnel no encaixen a la MTU, el paquet es talla en fragments i s'envia a la xarxa.
- El commutador després de l'equilibrador L3, quan rep un paquet, afegeix una etiqueta Vlan i l'envia.
- El commutador davant del servidor intermediari Nginx veu (segons la configuració del port) que el servidor espera un paquet encapsulat en Vlan, de manera que l'envia tal com és, sense eliminar l'etiqueta Vlan.
- Linux rep fragments de paquets individuals i els enganxa en un paquet gran.
- A continuació, el paquet arriba a la interfície Vlan, on se n'elimina la primera capa: encapsulació Vlan.
- Llavors Linux l'envia a la interfície del túnel, on se'n treu una altra capa: encapsulació del túnel.
La dificultat és passar tot això com a paràmetres a tcpdump.
Comencem pel final: hi ha paquets IP nets (sense capçaleres innecessàries) dels clients, amb vlan i encapsulació de túnel eliminats?
tcpdump host <ip клиента>
No, no hi havia cap tipus de paquets al servidor. Per tant, el problema ha de ser allà abans. Hi ha paquets amb només eliminada l'encapsulació de Vlan?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx és l'adreça IP del client en format hexadecimal.
32:4 — adreça i longitud del camp en què s'escriu l'IP SCR al paquet del túnel.
L'adreça de camp s'havia de seleccionar per força bruta, ja que a Internet escriuen uns 40, 44, 50, 54, però no hi havia cap adreça IP. També podeu mirar un dels paquets en hexadecimal (el paràmetre -xx o -XX a tcpdump) i calcular l'adreça IP que coneixeu.
Hi ha fragments de paquets sense eliminació de l'encapsulació de Vlan i Tunnel?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Aquesta màgia ens mostrarà tots els fragments, inclòs l'últim. Probablement, es pot filtrar el mateix per IP, però no ho vaig intentar, perquè no hi ha molts paquets d'aquest tipus, i els que necessitava es trobaven fàcilment al flux general. Aquí estan:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 A 00:de:ff:1a:94:11 tipus d'etèter IPv4 (0x0800), longitud 62: (tos 0x0, ttl 63, id 53652, offset 1480, banderes [cap], proto IPIP (4), longitud 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Es tracta de dos fragments d'un paquet (mateix ID 53652) amb una fotografia (la paraula Exif és visible al primer paquet). A causa del fet que hi ha paquets a aquest nivell, però no en la forma fusionada als abocadors, el problema és clarament amb el muntatge. Per fi hi ha una prova documental d'això!
El descodificador de paquets no va revelar cap problema que impediria la compilació. Ho vas provar aquí: . Al principi, quan intenteu emplenar alguna cosa allà, al descodificador no li agrada el format del paquet. Va resultar que hi havia dos octets addicionals entre Srcmac i Ethertype (no relacionats amb la informació del fragment). Després d'eliminar-los, el descodificador va començar a funcionar. No obstant això, no va mostrar cap problema.
Sigui el que es digui, no es va trobar res més excepte aquells Sysctl. Només quedava trobar una manera d'identificar els servidors amb problemes per tal d'entendre l'escala i decidir sobre accions posteriors. El comptador necessari es va trobar prou ràpidament:
netstat -s | grep "packet reassembles failed”
També es troba a snmpd sota OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
"El nombre d'errors detectats per l'algoritme de remuntatge d'IP (per qualsevol motiu: temps d'espera, errors, etc.)."
Entre el grup de servidors en què es va estudiar el problema, en dos aquest comptador va augmentar més ràpidament, en dos més lentament i en dos més no va augmentar gens. La comparació de la dinàmica d'aquest comptador amb la dinàmica dels errors HTTP al servidor Java va revelar una correlació. És a dir, es podria controlar el comptador.
Tenir un indicador fiable dels problemes és molt important perquè pugueu determinar amb precisió si la recuperació de Sysctl ajuda, ja que per la història anterior sabem que això no es pot entendre immediatament des de l'aplicació. Aquest indicador ens permetria identificar totes les àrees problemàtiques en producció abans que els usuaris ho descobreixin.
Després de tornar a Sysctl, els errors de monitorització es van aturar, per la qual cosa es va demostrar la causa dels problemes, així com el fet que la recuperació ajuda.
Vam revertir la configuració de fragmentació d'altres servidors, on va entrar en joc un nou monitoratge, i en algun lloc vam assignar encara més memòria per als fragments de la que abans era la predeterminada (es tractava d'estadístiques UDP, la pèrdua parcial de les quals no es notava en el fons general). .
Les preguntes més importants
Per què es fragmenten els paquets al nostre equilibrador L3? La majoria dels paquets que arriben dels usuaris als equilibradors són SYN i ACK. Les mides d'aquests paquets són petites. Però com que la quota d'aquests paquets és molt gran, en el seu rerefons no vam notar la presència de paquets grans que van començar a fragmentar-se.
El motiu va ser un script de configuració trencat en servidors amb interfícies Vlan (en aquell moment hi havia molt pocs servidors amb trànsit etiquetat en producció). Advmss ens permet transmetre al client la informació que els paquets en la nostra direcció haurien de ser de mida més petita perquè després d'adjuntar-hi capçaleres de túnel no s'hagin de fragmentar.
Per què la recuperació de Sysctl no va ajudar, però el reinici sí? La recuperació de Sysctl va canviar la quantitat de memòria disponible per combinar paquets. Al mateix temps, aparentment, el fet mateix del desbordament de memòria dels fragments va provocar una desacceleració de les connexions, fet que va provocar que els fragments es retardessin durant molt de temps a la cua. És a dir, el procés va anar en cicles.
El reinici va esborrar la memòria i tot va tornar a l'ordre.
Era possible prescindir de la solució alternativa? Sí, però hi ha un alt risc de deixar els usuaris sense servei en cas d'atac. Per descomptat, l'ús de Workaround va comportar diversos problemes, entre els quals l'alentiment d'un dels serveis per als usuaris, però tanmateix creiem que les accions estaven justificades.
Moltes gràcies a Andrey Timofeev () per l'ajuda per dur a terme la investigació, així com Alexey Krenev () - per la titànica tasca d'actualització Centos i nuclis de servidor. En aquest cas, el procés s'ha hagut de reiniciar diverses vegades, cosa que ha fet que trigui molts mesos.
Font: www.habr.com
