

Salutacions habr.
Si algú està operant el sistema i es va trobar amb un problema de rendiment d'emmagatzematge (IO, espai de disc consumit), aleshores la possibilitat que ClickHouse es considerés un substitut hauria de ser propera a una. Aquesta declaració implica que una implementació de tercers ja s'utilitza com a dimoni receptor, per exemple o .
ClickHouse resol bé els problemes descrits. Per exemple, després d'abocar 2 TiB de dades del xiuxiueig, encaixen en 300 GiB. No em detendré en la comparació en detall, hi ha prou articles sobre aquest tema. A més, fins fa poc, no tot era perfecte amb el nostre emmagatzematge ClickHouse.
Problemes d'espai consumit
A primera vista, tot hauria de funcionar bé. Seguint , creeu una configuració per a l'esquema d'emmagatzematge de mètriques (d'ara endavant retention), després creeu una taula segons la recomanació del backend web de grafit seleccionat: + o , depenent de la pila que s'utilitzi. I... s'activa una bomba de rellotgeria.
Per entendre quina, cal saber com funcionen les insercions i el camí de vida posterior de les dades a les taules dels motors familiars *MergeTree ClickHouse (diagrames extrets de Alexey Zatelepin):
- S'ha inserit
блокdades. En el nostre cas, aquestes són mètriques.

- Cada bloc d'aquests s'ordena segons la clau abans de ser escrit al disc.
ORDER BYL'especificat quan es va crear la taula. - Després de classificar,
кусок(part) les dades s'escriuen al disc.
- El servidor supervisa en segon pla perquè no hi hagi moltes peces d'aquest tipus, i llança en segon pla
слияния(merge, després fusionar).
- El servidor deixa de llançar fusions per si mateix tan bon punt les dades deixen de fluir activament
партицию(partition), però podeu iniciar el procés manualment amb l'ordreOPTIMIZE. - Si només queda una peça a la partició, no podreu iniciar la fusió amb l'ordre habitual, heu d'utilitzar
OPTIMIZE ... FINAL
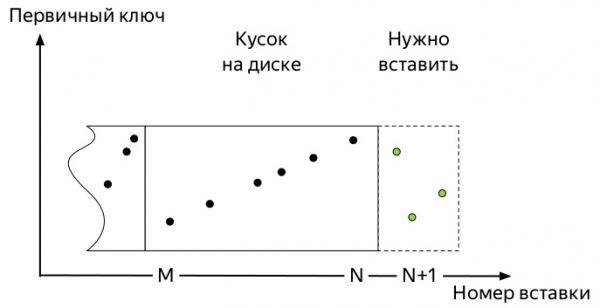
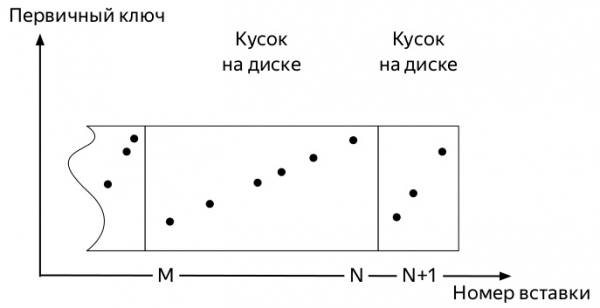
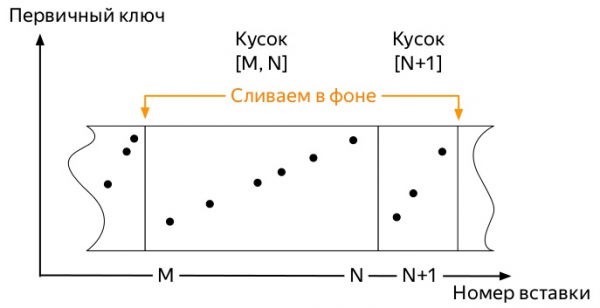
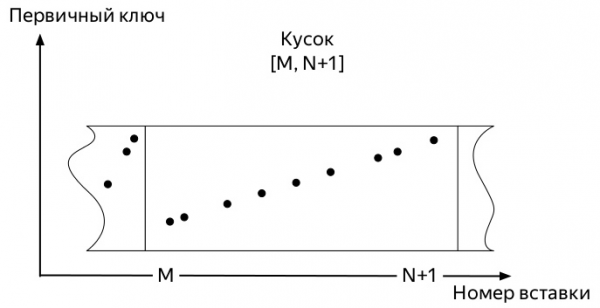
Així, arriben les primeres mètriques. I ocupen una mica d'espai. Els esdeveniments posteriors poden variar una mica en funció de molts factors:
- La clau de partició pot ser molt petita (un dia) o molt gran (diversos mesos).
- La configuració de retenció pot adaptar-se a diversos llindars d'agregació de dades significatius dins de la partició activa (on s'escriuen les mètriques), o potser no.
- Si hi ha moltes dades, aleshores els primers trossos, que ja poden ser enormes a causa de la fusió en segon pla (quan es trieu una clau de partició no òptima), no es fusionaran amb trossos petits nous.
I sempre acaba igual. El lloc que ocupen les mètriques a ClickHouse només creix si:
- no s'apliquen
OPTIMIZE ... FINALmanualment o - no inseriu dades a totes les particions de manera contínua per tal d'iniciar una fusió de fons tard o d'hora
El segon mètode sembla ser el més fàcil d'implementar i, per tant, és incorrecte i es va provar en primer lloc.
Vaig escriure un script Python bastant senzill que envia mètriques simulades per a cada dia durant els últims 4 anys i s'executa cada hora amb cron.
Com que tot el treball de ClickHouse DBMS es basa en el fet que aquest sistema, tard o d'hora, farà tot el treball de fons, però no se sap quan, no vaig aconseguir esperar el moment en què les antigues peces enormes es dignen a començar a fusionar-se. amb de petits nous. Va quedar clar que havíem de trobar una manera d'automatitzar les optimitzacions forçades.

Informació a les taules del sistema ClickHouse
Fem una ullada a l'estructura de la taula . Aquesta és informació completa sobre cada peça de totes les taules del servidor ClickHouse. Conté, entre altres coses, les columnes següents:
- nom de la base de dades (
database); - nom de la taula (
table); - nom i identificador de la partició (
partition&partition_id); - quan es va crear la peça (
modification_time); - data mínima i màxima al tros (la partició és per dia) (
min_date&max_date);
També hi ha una taula , amb els següents camps interessants:
- nom de la base de dades (
Tables.database); - nom de la taula (
Tables.table); - l'edat de la mètrica quan s'ha d'aplicar la següent agregació (
age);
Per tant:
- Tenim una taula de trossos i una taula de regles d'agregació.
- Unim la seva intersecció i rebem totes les taules *GraphiteMergeTree.
- Estem buscant totes les particions en què:
- més d'una peça
- o ha arribat el moment d'aplicar la següent regla d'agregació, i
modification_timemés antiga que aquest moment.
Implementació
Aquesta petició
SELECT
concat(p.database, '.', p.table) AS table,
p.partition_id AS partition_id,
p.partition AS partition,
-- Самое "старое" правило, которое может быть применено для
-- партиции, но не в будущем, см (*)
max(g.age) AS age,
-- Количество кусков в партиции
countDistinct(p.name) AS parts,
-- За самую старшую метрику в партиции принимается 00:00:00 следующего дня
toDateTime(max(p.max_date + 1)) AS max_time,
-- Когда партиция должна быть оптимизированна
max_time + age AS rollup_time,
-- Когда самый старый кусок в партиции был обновлён
min(p.modification_time) AS modified_at
FROM system.parts AS p
INNER JOIN
(
-- Все правила для всех таблиц *GraphiteMergeTree
SELECT
Tables.database AS database,
Tables.table AS table,
age
FROM system.graphite_retentions
ARRAY JOIN Tables
GROUP BY
database,
table,
age
) AS g ON
(p.table = g.table)
AND (p.database = g.database)
WHERE
-- Только активные куски
p.active
-- (*) И только строки, где правила аггрегации уже должны быть применены
AND ((toDateTime(p.max_date + 1) + g.age) < now())
GROUP BY
table,
partition
HAVING
-- Только партиции, которые младше момента оптимизации
(modified_at < rollup_time)
-- Или с несколькими кусками
OR (parts > 1)
ORDER BY
table ASC,
partition ASC,
age ASCretorna cadascuna de les particions de la taula *GraphiteMergeTree que s'han de combinar per alliberar espai al disc. Només segueix sent el cas de les petites coses: repassa-les totes amb una petició OPTIMIZE ... FINAL. La implementació final també va tenir en compte el fet que no cal tocar particions amb un registre actiu.
Això és el que fa el projecte. . Antics companys de Yandex.Market ho van provar en producció, el resultat del treball es pot veure a continuació.
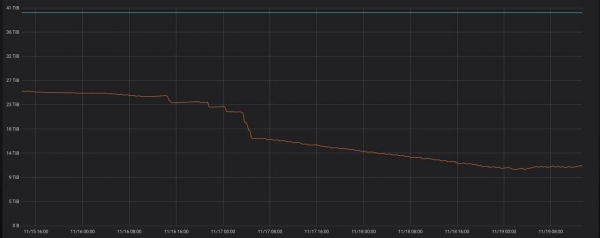
Si executeu el programa en un servidor amb ClickHouse, simplement començarà a funcionar en mode dimoni. Cada hora s'executarà una consulta, comprovant si hi ha particions noves de més de tres dies que es puguin optimitzar.
En un futur proper, per proporcionar almenys paquets deb i, si és possible, també rpm.
En lloc d'una conclusió
Durant els últims 9 mesos, he estat dins de la meva empresa Va passar molt de temps cuinant a la cruïlla de ClickHouse i grafit-web. Va ser una bona experiència, que va donar lloc a una ràpida transició del xiuxiueig a ClickHouse com a repositori de mètriques. Espero que aquest article sigui com l'inici d'un cicle sobre quines millores hem fet a diverses parts d'aquesta pila i què es farà en el futur.
Es van dedicar diversos litres de cervesa i dies d'administració en el desenvolupament de la sol·licitud, juntament amb pel que vull expressar-li el meu agraïment. I també per revisar aquest article.
Font: www.habr.com
