

Benvolguda comunitat, Aquest article se centrarà a emmagatzemar i recuperar de manera eficient centenars de milions de fitxers petits. En aquesta fase, es proposa la solució final per a sistemes de fitxers compatibles amb POSIX amb suport total per a bloquejos, inclosos els de clúster, i aparentment fins i tot sense crosses.
Així que vaig escriure el meu propi servidor personalitzat per a aquest propòsit.
En el curs d'implementar aquesta tasca, hem aconseguit resoldre el problema principal i, al mateix temps, aconseguir estalvis d'espai en disc i RAM, que el nostre sistema de fitxers de clúster consumia sense pietat. De fet, aquest nombre de fitxers és perjudicial per a qualsevol sistema de fitxers agrupat.
La idea és aquesta:
En paraules senzilles, els fitxers petits es carreguen a través del servidor, es guarden directament a l'arxiu i també es llegeixen d'ell, i els fitxers grans es col·loquen un al costat de l'altre. Esquema: 1 carpeta = 1 arxiu, en total tenim diversos milions d'arxius amb fitxers petits, i no diversos centenars de milions d'arxius. I tot això s'implementa completament, sense cap script ni posar fitxers en arxius tar/zip.
Intentaré fer-ho breu, demano disculpes per endavant si la publicació és llarga.
Tot va començar amb el fet que no podia trobar un servidor adequat al món que pogués desar les dades rebudes mitjançant el protocol HTTP directament als arxius, sense els inconvenients inherents als arxius convencionals i l'emmagatzematge d'objectes. I el motiu de la cerca va ser el clúster Origin de 10 servidors que havia crescut a gran escala, en el qual ja s'havien acumulat 250,000,000 de fitxers petits i la tendència de creixement no s'aturava.
Per a aquells a qui no els agrada llegir articles, una mica de documentació és més fàcil:
и .
I Docker alhora, ara només hi ha una opció amb nginx dins per si de cas:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdSegüent:
Si hi ha molts fitxers, calen recursos importants, i el pitjor és que alguns es malgasten. Per exemple, quan s'utilitza un sistema de fitxers en clúster (en aquest cas, MooseFS), el fitxer, independentment de la seva mida real, sempre ocupa almenys 64 KB. És a dir, per a fitxers de 3, 10 o 30 KB de mida, calen 64 KB al disc. Si hi ha un quart de mil milions de fitxers, perdem de 2 a 10 terabytes. No serà possible crear nous fitxers indefinidament, ja que MooseFS té una limitació: no més de 1 milions amb una rèplica de cada fitxer.
A mesura que augmenta el nombre de fitxers, es necessita molta memòria RAM per a les metadades. Els abocaments freqüents de metadades grans també contribueixen al desgast de les unitats SSD.
servidor wZD. Posem les coses en ordre als discos.
El servidor està escrit a Go. En primer lloc, necessitava reduir el nombre d'arxius. Com fer-ho? A causa de l'arxiu, però en aquest cas sense compressió, ja que els meus fitxers són només imatges comprimides. BoltDB va venir al rescat, que encara s'havia d'eliminar de les seves mancances, això es reflecteix a la documentació.
En total, en lloc d'un quart de mil milions d'arxius, en el meu cas només quedaven 10 milions d'arxius Bolt. Si tingués l'oportunitat de canviar l'estructura de fitxers del directori actual, seria possible reduir-la a aproximadament un milió de fitxers.
Tots els fitxers petits s'empaqueten en arxius Bolt, que reben automàticament els noms dels directoris en què es troben, i tots els fitxers grans romanen al costat dels arxius; no té sentit empaquetar-los, això és personalitzable. Els petits s'arxiven, els grans es deixen sense canvis. El servidor funciona de manera transparent amb tots dos.
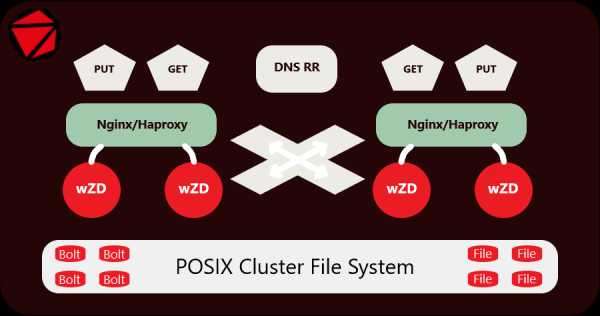
Arquitectura i característiques del servidor wZD.

El servidor funciona sota el control dels sistemes operatius Linux, BSD, Solaris i OSX. Només vaig provar l'arquitectura AMD64 sota Linux, però també hauria de funcionar per a ARM64, PPC64, MIPS64.
Principals característiques:
- Multithreading;
- Multiservidor, que proporciona tolerància a errors i equilibri de càrrega;
- Màxima transparència per a l'usuari o desenvolupador;
- Mètodes HTTP compatibles: GET, HEAD, PUT i DELETE;
- Control del comportament de lectura i escriptura mitjançant les capçaleres del client;
- Suport per a amfitrions virtuals flexibles;
- Admet la integritat de les dades CRC en escriure/llegir;
- Buffers semi-dinàmics per a un consum mínim de memòria i un ajustament òptim del rendiment de la xarxa;
- Compactació de dades ajornada;
- A més, s'ofereix un arxivador multifils wZA per migrar fitxers sense aturar el servei.
Experiència real:
He estat desenvolupant i provant el servidor i l'arxivador en dades en directe durant força temps, ara funciona amb èxit en un clúster que inclou 250,000,000 de fitxers petits (imatges) situats en 15,000,000 de directoris en unitats SATA separades. Un clúster de 10 servidors és un servidor Origin instal·lat darrere d'una xarxa CDN. Per donar-hi servei, s'utilitzen 2 servidors Nginx + 2 servidors wZD.
Per a aquells que decideixen utilitzar aquest servidor, seria convenient planificar l'estructura de directoris, si escau, abans d'utilitzar-lo. Permeteu-me fer una reserva immediatament que el servidor no té la intenció d'emmagatzemar-ho tot en un arxiu 1 Bolt.
Prova de rendiment:
Com més petita sigui la mida del fitxer comprimit, més ràpides es realitzen les operacions GET i PUT. Comparem el temps total d'escriptura del client HTTP amb fitxers normals i arxius Bolt, així com la lectura. Es compara el treball amb fitxers de mides de 32 KB, 256 KB, 1024 KB, 4096 KB i 32768 KB.
Quan es treballa amb arxius Bolt, es comprova la integritat de les dades de cada fitxer (s'utilitza CRC), abans de la gravació i també després de l'enregistrament, es produeix la lectura i el recàlcul sobre la marxa, això introdueix, naturalment, retards, però el més important és la seguretat de les dades.
Vaig realitzar proves de rendiment en unitats SSD, ja que les proves en unitats SATA no mostren una diferència clara.
Gràfics basats en els resultats de les proves:
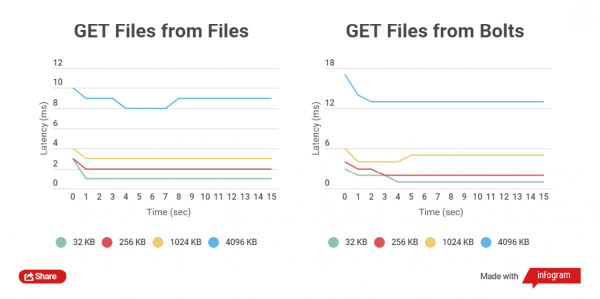
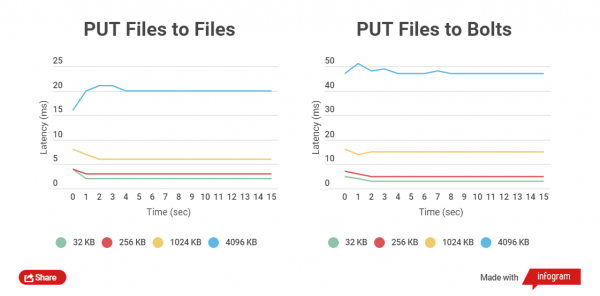
Com podeu veure, per a fitxers petits la diferència de temps de lectura i escriptura entre fitxers arxivats i no arxivats és petita.
Tenim una imatge completament diferent en provar fitxers de lectura i escriptura de 32 MB de mida:
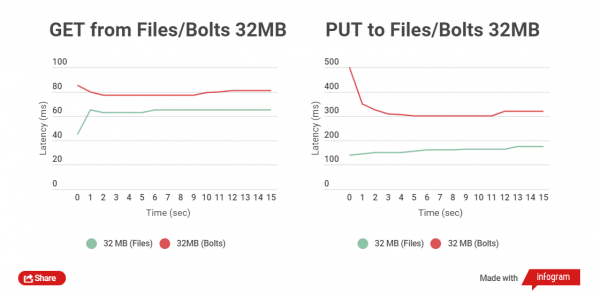
La diferència de temps entre la lectura dels fitxers és d'entre 5 i 25 ms. Amb la gravació, les coses van pitjor, la diferència és d'uns 150 ms. Però en aquest cas no cal carregar fitxers grans; simplement no té sentit fer-ho; poden viure separats dels arxius.
*Tècnicament, podeu utilitzar aquest servidor per a tasques que requereixen NoSQL.
Mètodes bàsics per treballar amb el servidor wZD:
Carregant un fitxer normal:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgCàrrega d'un fitxer a l'arxiu Bolt (si no es supera el paràmetre de servidor fmaxsize, que determina la mida màxima del fitxer que es pot incloure a l'arxiu; si se supera, el fitxer es pujarà com és habitual al costat de l'arxiu):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgDescàrrega d'un fitxer (si hi ha fitxers amb els mateixos noms al disc i a l'arxiu, quan es descarrega, es dóna prioritat per defecte al fitxer no arxivat):
curl -o test.jpg http://localhost/test/test.jpgDescàrrega d'un fitxer de l'arxiu Bolt (forçat):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgLes descripcions d'altres mètodes es troben a la documentació.
Actualment, el servidor només admet el protocol HTTP; encara no funciona amb HTTPS. El mètode POST tampoc és compatible (encara no s'ha decidit si és necessari o no).
Qui busqui el codi font hi trobarà el caramel, no a tothom li agrada, però jo no vaig lligar el codi principal a les funcions del marc web, excepte el gestor d'interrupcions, de manera que en el futur el puc reescriure ràpidament per a gairebé qualsevol. motor.
Fer:
- Desenvolupament del teu propi replicador i distribuïdor + geo per a la possibilitat d'ús en sistemes grans sense sistemes de fitxers clúster (Tot per a adults)
- Possibilitat de recuperació inversa completa de metadades si es perden completament (si s'utilitza un distribuïdor)
- Protocol natiu per a la capacitat d'utilitzar connexions de xarxa persistents i controladors per a diferents llenguatges de programació
- Possibilitats avançades per utilitzar el component NoSQL
- Compressions de diferents tipus (gzip, zstd, snappy) per a fitxers o valors dins d'arxius Bolt i per a fitxers normals
- Xifratge de diferents tipus per a fitxers o valors dins d'arxius Bolt i per a fitxers normals
- Conversió de vídeo del costat del servidor retardada, inclosa la GPU
Ho tinc de tot, espero que aquest servidor sigui útil a algú, llicència BSD-3, doble copyright, ja que si no hi hagués empresa on treballi, el servidor no hauria estat escrit. Sóc l'únic desenvolupador. Agrairia qualsevol error i sol·licitud de funcions que trobeu.
Font: www.habr.com
