

Avui dia, a més del codi monolític, desenes de microserveis operen al nostre projecte. Cadascun d'ells requereix un seguiment. És problemàtic fer-ho en aquests volums per part dels enginyers de DevOps. Hem desenvolupat un sistema de monitorització que funciona com un servei per als desenvolupadors. Poden escriure mètriques de manera independent al sistema de monitorització, utilitzar-les, crear taulers de control basats en elles, adjuntar-hi alertes que s'activaran quan s'assoleixin els valors de llindar. Amb enginyers de DevOps: només infraestructura i documentació.
Aquesta entrada és una transcripció del meu discurs des del nostre a RIT++. Molts ens van demanar que fessim versions de text dels informes a partir d'aquí. Si has estat a una conferència o has vist un vídeo, no trobaràs res de nou. I a tots els altres: benvinguts sota el gat. Us explicaré com hem arribat a aquest sistema, com funciona i com pensem actualitzar-lo.

Passat: esquemes i plans
Com hem arribat al sistema de seguiment existent? Per respondre a aquesta pregunta, cal anar al 2015. Aquí és com es veia aleshores:
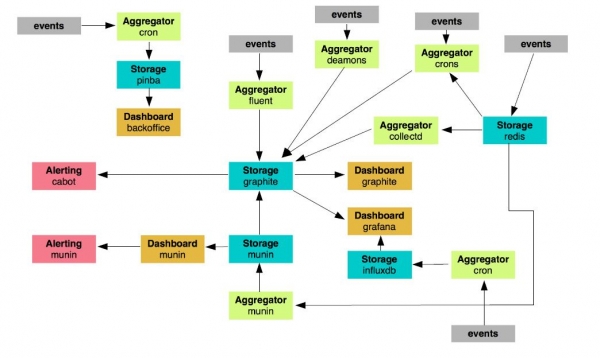
Teníem uns 24 nodes que s'encarregaven del seguiment. Hi ha un munt de crons, scripts i dimonis diferents que supervisen alguna cosa en algun lloc, envien missatges i realitzen funcions. Pensàvem que com més lluny, menys viable seria aquest sistema. No té sentit desenvolupar-lo: és massa feixuc.
Vam decidir triar aquells elements de seguiment que deixarem i desenvoluparem, i els que abandonarem. N'hi havia 19. Només quedaven grafits, agregadors i Grafana com a quadre de comandament. Però, com serà el nou sistema? Com això:
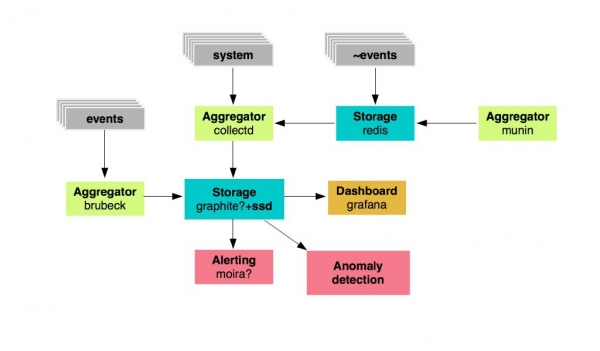
Tenim un repositori de mètriques: es tracta de grafits que es basaran en unitats SSD ràpides, aquests són certs agregadors de mètriques. Següent: Grafana per mostrar taulers i Moira com a alerta. També hem volgut desenvolupar un sistema per trobar anomalies.
Estàndard: Monitorització 2.0
Així es veien els plans l'any 2015. Però vam haver de preparar no només la infraestructura i el servei en si, sinó també la documentació. Hem desenvolupat un estàndard corporatiu per a nosaltres mateixos, que hem anomenat monitoring 2.0. Quins eren els requisits del sistema?
- disponibilitat constant;
- interval d'emmagatzematge mètric = 10 segons;
- emmagatzematge estructurat de mètriques i quadres de comandament;
- SLA > 99,99%
- recollida de mètriques d'esdeveniments mitjançant UDP (!).
Necessitàvem UDP perquè tenim molt trànsit i esdeveniments que generen mètriques. Si tots estan escrits en grafit alhora, el repositori es col·lapsarà. També vam triar prefixos de primer nivell per a totes les mètriques.
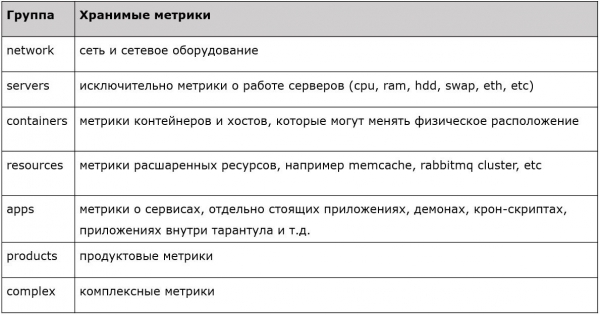
Cadascun dels prefixos té alguna propietat. Hi ha mètriques per a servidors, xarxes, contenidors, recursos, aplicacions, etc. S'ha implementat un filtrat clar, estricte i mecanografiat, on acceptem les mètriques de primer nivell i simplement deixem la resta. Així és com vam planificar aquest sistema el 2015. Què hi ha en el present?
Present: l'esquema d'interacció dels components de seguiment
En primer lloc, monitoritzem les aplicacions: el nostre codi PHP, aplicacions i microserveis, en una paraula, tot el que escriuen els nostres desenvolupadors. Totes les aplicacions envien mètriques mitjançant UDP a l'agregador Brubeck (statsd, reescrita en C). Va resultar ser el més ràpid segons els resultats de les proves sintètiques. I envia les mètriques ja agregades a Graphite mitjançant TCP.
Té un tipus de mètriques com els temporitzadors. Això és una cosa molt útil. Per exemple, per a cada connexió d'usuari al servei, envieu una mètrica de temps de resposta a Brubeck. Va arribar un milió de respostes i l'agregador només va donar 10 mètriques. Tens el nombre de persones que han vingut, els temps de resposta màxim, mínim i mitjà, la mediana i els 4 percentils. Després les dades es transfereixen a Graphite i les veiem totes en directe.
També tenim agregació de maquinari, programari, mètriques del sistema i el nostre antic sistema de monitorització Munin (va funcionar amb nosaltres fins al 2015). Tot això ho recollim a través del dimoni C'ish CollectD (hi ha cosit un munt de plug-ins diversos, pot consultar tots els recursos del sistema amfitrió en el qual està instal·lat, només cal especificar a la configuració on escriure les dades). ) i escriviu dades a través d'ell en grafit. També admet connectors de Python i scripts d'intèrpret d'ordres, de manera que podeu escriure les vostres pròpies solucions personalitzades: CollectD recopilarà aquestes dades d'un host local o remot (suposem que hi ha Curl) i les enviarà a Graphite.
A més, totes les mètriques que hem recollit s'envien a Carbon-c-relay. Es tracta de la solució Carbon Relay de Graphite, modificada en C. Aquest és un encaminador que recull totes les mètriques que enviem dels nostres agregadors i les encamina pels nodes. També en l'etapa d'encaminament, comprova la validesa de les mètriques. En primer lloc, han de coincidir amb l'esquema de prefix que he mostrat anteriorment i, en segon lloc, han de ser vàlids per al grafit. En cas contrari, cauen.
A continuació, Carbon-c-relay envia les mètriques al clúster de grafit. Utilitzem Carbon-cache reescrit a Go com a emmagatzematge principal per a mètriques. Go-carbon, a causa del seu multi-threading, és molt superior en rendiment a Carbon-cache. Pren les dades en si mateix i les escriu al disc mitjançant el paquet whisper (estàndard, escrit en Python). Per llegir les dades dels nostres magatzems, utilitzem l'API Graphite. Funciona molt més ràpid que el Graphite WEB estàndard. Què passa amb les dades a continuació?
Van a Grafana. Utilitzem els nostres clústers de grafit com a font de dades principal, a més, tenim Grafana com a interfície web per mostrar mètriques i crear taulers de control. Per a cadascun dels seus serveis, els desenvolupadors creen el seu propi tauler de control. A continuació, construeixen gràfics basats en ells, que mostren les mètriques que escriuen des de les seves aplicacions. A més de Grafana, també tenim SLAM. Aquest és un dimoni pitònic que calcula el SLA a partir de dades del grafit. Com he dit, tenim diverses desenes de microserveis, cadascun dels quals té els seus propis requisits. Amb l'ajuda de SLAM, anem a la documentació i la comparem amb la que hi ha a Graphite i comparem com es corresponen els requisits amb la disponibilitat dels nostres serveis.
Anar més enllà: alertar. Està organitzat amb un sistema fort - Moira. És independent perquè té el seu propi grafit sota el capó. Desenvolupat pels nois de SKB Kontur, escrit en python i Go, totalment de codi obert. Moira rep el mateix flux que passa als grafits. Si per algun motiu el vostre emmagatzematge s'apaga, la vostra alerta funcionarà.
Hem desplegat Moira a Kubernetes, utilitza un clúster de servidors Redis com a base de dades principal. El resultat és un sistema tolerant a errors. Compara el flux de mètriques amb la llista de desencadenants: si no hi ha mencions, elimina la mètrica. Així que és capaç de digerir gigabytes de mètriques per minut.
També hi hem afegit un LDAP corporatiu, amb l'ajuda del qual cada usuari del sistema corporatiu pot crear notificacions per si mateix en activadors existents (o de nova creació). Com que Moira conté grafit, admet totes les seves característiques. Així que primer agafeu la línia i la copieu a Grafana. Vegeu com es mostren les dades als gràfics. I després agafes la mateixa línia i la copies a Moira. Pengeu-lo amb límits i obteniu una alerta a la sortida. Per fer tot això, no cal cap coneixement específic. Moira pot alertar per SMS, correu electrònic, Jira, Slack... També admet scripts personalitzats. Quan té un activador i està subscrita a un script o binari personalitzat, l'engega i envia aquest binari JSON a stdin. En conseqüència, el vostre programa hauria d'analitzar-lo. El que faràs amb aquest JSON depèn de tu. Si vols, envia'l a Telegram, si vols, obre tasques a Jira, fes el que vulguis.
També fem servir el nostre propi desenvolupament per alertar: Imagotag. Hem adaptat el panell, que s'utilitza habitualment per a les etiquetes de preus electròniques de les botigues, a les nostres necessitats. Vam portar-hi detonants de Moira. Indica en quina condició es troben, quan van passar. Alguns dels nois del desenvolupament van abandonar les notificacions a Slack i al correu a favor d'aquest panell.

Bé, com que som una empresa progressista, també hem monitoritzat Kubernetes en aquest sistema. Inclòs al sistema mitjançant Heapster, que hem instal·lat al clúster, recull dades i les envia a Graphite. Com a resultat, l'esquema té aquest aspecte:
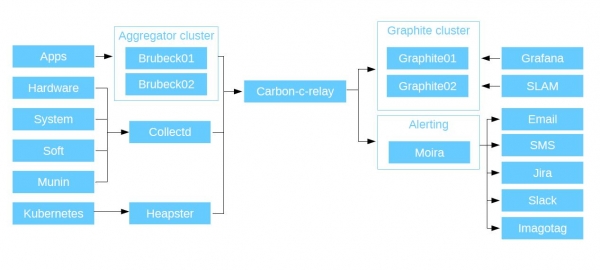
Components de seguiment
Aquí teniu una llista d'enllaços als components que hem utilitzat per a aquesta tasca. Tots ells són de codi obert.
Grafit:
- go-carbon:
- xiuxiuejar:
- grafit-api:
Relé de carboni-c:
Brubeck:
Recollida:
Moira:
Grafana:
heapster:
estadística
I aquí teniu alguns números sobre com funciona el sistema per a nosaltres.
Agregador (brubeck)
Nombre de mètriques: ~ 300/s
Interval d'enviament de mètriques de grafit: 30 segons
Ús de recursos del servidor: ~ 6% CPU (estem parlant de servidors complets); ~ 1 Gb de RAM; ~ 3 Mbps LAN
Grafit (go-carbon)
Nombre de mètriques: ~ 1/min
Interval d'actualització de mètriques: 30 segons
Esquema d'emmagatzematge de mètriques: 30 segons 35 d, 5 min 90 d, 10 min 365 d (ofereix una comprensió del que passa amb el servei durant un llarg període de temps)
Ús de recursos del servidor: ~10% CPU; ~ 20 Gb de RAM; ~ 30 Mbps LAN
Flexibilitat
A Avito agraïm molt la flexibilitat del nostre servei de monitoratge. Per què realment va resultar així? En primer lloc, els seus components són intercanviables: tant els mateixos components com les seves versions. En segon lloc, manteniment. Com que tot el projecte es basa en codi obert, podeu editar el codi vosaltres mateixos, fer canvis i implementar funcions que no estan disponibles de manera immediata. S'utilitzen piles força habituals, principalment Go i Python, de manera que això es fa de manera senzilla.
Aquí teniu un exemple d'un problema real. Una mètrica a Graphite és un fitxer. Té un nom. El nom del fitxer és el nom de la mètrica. I hi ha una ruta d'accés. Els noms de fitxer a Linux Estan limitats a 255 caràcters. I tenim (com a "clients interns") els nois del departament de bases de dades. Ens diuen: "Volem monitoritzar les nostres consultes SQL. I no tenen 255 caràcters, sinó 8 MB cadascuna. Volem mostrar-les a Grafana, veure els paràmetres d'aquesta consulta i, encara millor, volem veure les consultes més freqüents. Seria fantàstic si es mostrés en temps real. I seria encara més interessant incloure-les en una alerta".
L'exemple de consulta SQL es pren com a exemple de
Aixequem el servidor Redis i els nostres connectors Collectd que van a Postgres i agafem totes les dades d'allà, enviem mètriques a Graphite. Però substituïm el nom de la mètrica amb hash. El mateix hash s'envia simultàniament a Redis com a clau i tota la consulta SQL com a valor. Ens queda fer que Grafana pugui anar a Redis i agafar aquesta informació. Estem obrint l'API Graphite perquè aquesta és la interfície principal per a la interacció de tots els components de monitorització amb grafit, i hi introduïm una nova funció anomenada aliasByHash () - obtenim el nom de la mètrica de Grafana i l'utilitzem en una sol·licitud a Redis com a clau, en resposta obtenim el valor de la clau, que és la nostra "consulta SQL". Així, vam portar a Grafana la visualització d'una consulta SQL, que, en teoria, no s'hi podia mostrar, juntament amb les estadístiques sobre ella (trucades, files, total_time, ...).
Resultats de
Disponibilitat El nostre servei de monitorització està disponible les 24 hores del dia des de qualsevol aplicació i qualsevol codi. Si teniu accés als emmagatzematges, podeu escriure dades al servei. La llengua no és important, les decisions no són importants. Només cal saber com obrir un sòcol, llançar-hi una mètrica i tancar el sòcol.
Fiabilitat Tots els components són tolerants a errors i gestionen bé les nostres càrregues de treball.
Llindar d'entrada baix. Per utilitzar aquest sistema, no cal aprendre llenguatges de programació i consultes a Grafana. Només has d'obrir la teva aplicació, afegir-hi un sòcol que enviarà mètriques a Graphite, tancar-la, obrir Grafana, crear-hi taulers i mirar el comportament de les teves mètriques, rebent notificacions a través de Moira.
Independència. Tot això ho pots fer tu mateix, sense l'ajuda dels enginyers de DevOps. I això és un excés, perquè podeu supervisar el vostre projecte ara mateix, no heu de demanar a ningú, ni per començar a treballar ni per fer canvis.
Per què ens esforcem?
Tot el que s'esmenta a continuació no són només pensaments abstractes, sinó quelcom cap al qual almenys s'han fet els primers passos.
- detector d'anomalies. Volem crear un servei que anirà als nostres magatzems de grafit i comprovarà cada mètrica mitjançant diversos algorismes. Ja hi ha algorismes que volem veure, hi ha dades, sabem com treballar-hi.
- metadades. Tenim molts serveis, canvien amb el temps, així com les persones que hi treballen. Mantenir els registres manualment no és una opció. Per tant, ara les metadades estan incrustades als nostres microserveis. S'indica qui el va desenvolupar, els idiomes amb què interactua, els requisits de SLA, on i a qui enviar notificacions. Quan es desplega un servei, totes les dades de l'entitat es creen de manera independent. Com a resultat, obteniu dos enllaços: un per als activadors i l'altre per als taulers de control a Grafana.
- Seguiment a cada llar. Creiem que tots els desenvolupadors haurien d'utilitzar aquest sistema. En aquest cas, sempre entens on és el teu trànsit, què li passa, on cau, on té punts febles. Si, per exemple, arriba alguna cosa i bloqueja el vostre servei, ho descobrireu no durant una trucada del gestor, sinó a partir d'una alerta, i immediatament podreu obrir registres nous i veure què hi va passar.
- Gran actuació. El nostre projecte està en constant creixement, i avui processa uns 2 de valors mètrics per minut. Fa un any, aquesta xifra era de 000. I el creixement continua, i això significa que al cap d'un temps Graphite (xiuxiueig) començarà a carregar molt el subsistema del disc. Com he dit, aquest sistema de monitorització és força versàtil a causa de la intercanviabilitat de components. Algú específicament per a Graphite manté i amplia constantment la seva infraestructura, però vam decidir anar al contrari: utilitzar com a repositori de les nostres mètriques. Aquesta transició està gairebé acabada, i molt aviat us explicaré amb més detall com es va fer: quines van ser les dificultats i com es van superar, com va anar el procés de migració, descriuré els components seleccionats com a vinculants i les seves configuracions.
Gràcies per la vostra atenció! Fes les teves preguntes sobre el tema, intentaré respondre aquí o en els posts següents. Potser algú té experiència en la construcció d'un sistema de supervisió similar o en canviar a Clickhouse en una situació similar; compartiu-ho als comentaris.
Font: www.habr.com
