

1. Dades inicials
La neteja de dades és un dels reptes a què s'enfronten les tasques d'anàlisi de dades. Aquest material reflectia les novetats i solucions sorgides com a conseqüència de resoldre un problema pràctic d'anàlisi de la base de dades en la formació del valor cadastral. Fonts aquí .
S'ha considerat el fitxer “Model comparatiu total.ods” de l'”Annex B. Resultats de la determinació de KS 5. Informació sobre el mètode de determinació del valor cadastral 5.1 Enfocament comparatiu”.
Taula 1. Indicadors estadístics del conjunt de dades del fitxer “Model comparatiu total.ods”
Nombre total de camps, unitats. —44
Nombre total de registres, unitats. — 365 490
Nombre total de caràcters, unitats. — 101 714 693
Nombre mitjà de caràcters en un registre, unitats. — 278,297
Desviació estàndard dels caràcters d'un registre, unitats. — 15,510
Nombre mínim de caràcters en una entrada, pcs. —198
Nombre màxim de caràcters en una entrada, unitats. —363
2. Part introductòria. Normes bàsiques
Mentre s'analitzava la base de dades especificada, es va formar una tasca per especificar els requisits del grau de purificació, ja que, com és clar per a tothom, la base de dades especificada genera conseqüències legals i econòmiques per als usuaris. Durant el treball, va resultar que no hi havia requisits específics per al grau de neteja de big data. Analitzant les normes jurídiques en aquesta matèria, vaig arribar a la conclusió que totes estan formades a partir de possibilitats. És a dir, ha aparegut una tasca determinada, es compilen fonts d'informació per a la tasca, després es forma un conjunt de dades i, a partir del conjunt de dades creat, eines per resoldre el problema. Les solucions resultants són punts de referència per triar entre alternatives. Ho vaig presentar a la figura 1.
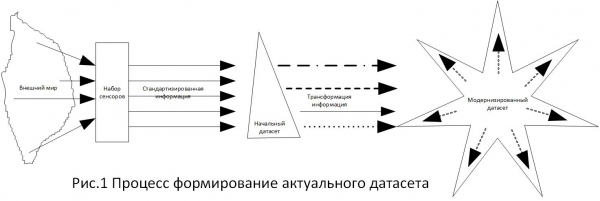
Com que, en matèria de determinació de qualsevol estàndard, és preferible confiar en tecnologies provades, vaig triar els requisits establerts a , perquè he considerat aquest document el més complet per a aquest tema. En particular, en aquest document la secció diu "Cal tenir en compte que els requisits d'integritat de les dades s'apliquen igualment a les dades manuals (en paper) i electròniques". (traducció: “... els requisits d'integritat de les dades s'apliquen igualment a les dades manuals (en paper) i electròniques”). Aquesta formulació s'associa força específicament al concepte de “prova escrita”, en el que disposa l'article 71 del Codi d'enjudiciament civil, art. 70 CAS, Art 75 APC, “per escrit” Art. 84 Codi d'enjudiciament civil.
La figura 2 presenta un diagrama de la formació dels enfocaments dels tipus d'informació en jurisprudència.
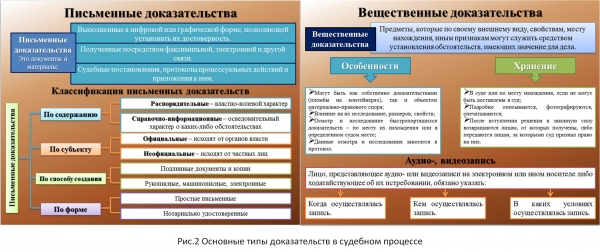
Arròs. 2. Font .
La figura 3 mostra el mecanisme de la figura 1, per a les tasques de la "Guia" anterior. És fàcil, fent una comparació, veure que els enfocaments utilitzats per complir els requisits d'integritat de la informació en els estàndards moderns per als sistemes d'informació són significativament limitats en comparació amb el concepte legal d'informació.
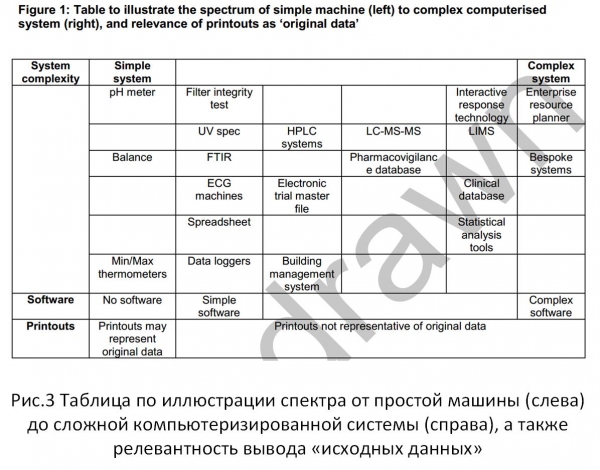
Fig. 3
En el document especificat (guia), la connexió amb la part tècnica, les capacitats per processar i emmagatzemar dades, es confirma bé amb una cita del capítol 18.2. Base de dades relacional: "Aquesta estructura de fitxers és inherentment més segura, ja que les dades es mantenen en un format de fitxer gran que preserva la relació entre dades i metadades".
De fet, en aquest plantejament -a partir de les capacitats tècniques existents, no hi ha res anormal i, en si mateix, es tracta d'un procés natural, ja que l'ampliació de conceptes prové de l'activitat més estudiada: el disseny de bases de dades. Però, d'altra banda, apareixen normes legals que no preveuen descomptes en les capacitats tècniques dels sistemes existents, per exemple: .

Arròs. 4. Embut de capacitats tècniques ().
En aquests aspectes, queda clar que el conjunt de dades original (Fig. 1) haurà de ser, en primer lloc, desat i, en segon lloc, ser la base per extreure'n informació addicional. Bé, a tall d'exemple: les càmeres que enregistren les normes de trànsit són omnipresents, els sistemes de processament d'informació eliminen els infractors, però també es pot oferir altra informació a altres consumidors, per exemple, com el seguiment de màrqueting de l'estructura del flux de clients a un centre comercial. I això és una font de valor afegit addicional quan s'utilitza BigDat. És molt possible que els conjunts de dades que es recullen ara, en algun lloc del futur, tinguin valor segons un mecanisme similar al valor de les edicions rares de 1700 en l'actualitat. Després de tot, de fet, els conjunts de dades temporals són únics i és poc probable que es repeteixin en el futur.
3. Part introductòria. Criteris d'avaluació
Durant el procés de processament, es va desenvolupar la següent classificació d'errors.
1. Classe d'error (basada en GOST R 8.736-2011): a) errors sistemàtics; b) errors aleatoris; c) un error.
2. Per multiplicitat: a) monodistorsió; b) multidistorsió.
3. Segons la criticitat de les conseqüències: a) crítica; b) no crític.
4. Per font d'ocurrència:
A) Tècnics: errors que es produeixen durant el funcionament de l'equip. Un error força rellevant per als sistemes IoT, sistemes amb un grau important d'influència en la qualitat de la comunicació, equips (maquinari).
B) Errors de l'operador: errors en un ampli ventall, des d'errors tipogràfics de l'operador durant l'entrada fins a errors en les especificacions tècniques per al disseny de la base de dades.
C) Errors de l'usuari: aquí hi ha errors de l'usuari en tot el rang des de "m'he oblidat de canviar el disseny" fins a confondre metres amb peus.
5. Separat en una classe separada:
a) la “tasca del separador”, és a dir, l'espai i “:” (en el nostre cas) quan es va duplicar;
b) paraules escrites juntes;
c) sense espai després dels caràcters de servei
d) Símbols múltiples simètricament: (), "", "...".
En conjunt, amb la sistematització dels errors de la base de dades presentada a la figura 5, es forma un sistema de coordenades força eficaç per a la recerca d'errors i el desenvolupament d'un algorisme de neteja de dades per a aquest exemple.
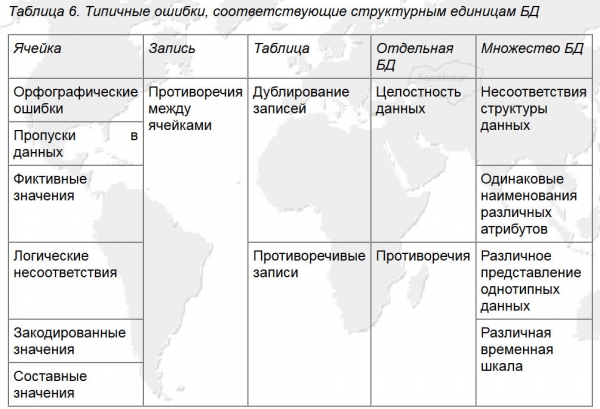
Arròs. 5. Errors típics corresponents a les unitats estructurals de la base de dades (Font: ).
Precisió, Integritat del domini, Tipus de dades, Coherència, Redundància, Complet, Duplicació, Conformitat amb les regles empresarials, Definició estructural, Anomalia de dades, Claredat, Oportunitat, Adhesió a les regles d'integritat de les dades. (Pàgina 334. Fonaments de l'emmagatzematge de dades per a professionals de les TI / Paulraj Ponniah.—2a ed.)
S'ha presentat la redacció en anglès i la traducció automàtica del rus entre parèntesis.
Precisió. El valor emmagatzemat al sistema per a un element de dades és el valor correcte per a l'aparició de l'element de dades. Si teniu un nom de client i una adreça emmagatzemats en un registre, l'adreça és l'adreça correcta per al client amb aquest nom. Si trobeu la quantitat demanada com a 1000 unitats al registre de la comanda número 12345678, aleshores aquesta quantitat és la quantitat exacta per a aquesta comanda.
[Precisió. El valor emmagatzemat al sistema per a un element de dades és el valor correcte per a l'aparició de l'element de dades. Si teniu un nom i una adreça de client emmagatzemats en un registre, l'adreça és l'adreça correcta per al client amb aquest nom. Si trobeu la quantitat demanada com a 1000 unitats al registre de la comanda número 12345678, aleshores aquesta quantitat és la quantitat exacta per a aquesta comanda.]
Integritat del domini. El valor de les dades d'un atribut es troba en l'interval de valors definits i permesos. L'exemple comú són els valors permesos que són "mascle" i "femení" per a l'element de dades de gènere.
[Integritat del domini. El valor de les dades de l'atribut es troba dins de l'interval de valors definits i vàlids. Un exemple general són els valors vàlids "home" i "female" per a un element de dades de gènere.]
Tipus de dades. El valor d'un atribut de dades s'emmagatzema realment com el tipus de dades definit per a aquest atribut. Quan el tipus de dades del camp del nom de la botiga es defineix com a "text", totes les instàncies d'aquest camp contenen el nom de la botiga que es mostra en format textual i no en codis numèrics.
[Tipus de dades. El valor d'un atribut de dades s'emmagatzema realment com el tipus de dades definit per a aquest atribut. Si el tipus de dades del camp del nom de la botiga es defineix com a "text", totes les instàncies d'aquest camp contenen el nom de la botiga que es mostra en format de text en lloc de codis numèrics.]
Coherència. La forma i el contingut d'un camp de dades són els mateixos en diversos sistemes d'origen. Si el codi de producte del producte ABC en un sistema és 1234, el codi d'aquest producte és 1234 en tots els sistemes font.
[Coherència. La forma i el contingut del camp de dades són els mateixos en diferents sistemes font. Si el codi de producte del producte ABC en un sistema és 1234, el codi d'aquest producte és 1234 a cada sistema font.]
Redundància. Les mateixes dades no s'han d'emmagatzemar en més d'un lloc d'un sistema. Si, per raons d'eficiència, un element de dades s'emmagatzema intencionadament en més d'un lloc d'un sistema, s'ha d'identificar i verificar clarament la redundància.
[Redundància. Les mateixes dades no s'han d'emmagatzemar en més d'un lloc del sistema. Si, per raons d'eficiència, un element de dades s'emmagatzema intencionadament en diverses ubicacions d'un sistema, la redundància s'ha de definir i verificar clarament.]
Completitud. No hi ha valors que falten per a un atribut determinat al sistema. Per exemple, en un fitxer de client, ha d'haver un valor vàlid per al camp "estat" per a cada client. Al fitxer de detalls de la comanda, tots els registres de detalls d'una comanda s'han d'omplir completament.
[Completitud. No hi ha valors que falten al sistema per a aquest atribut. Per exemple, el fitxer de client ha de tenir un valor vàlid per al camp "estat" de cada client. Al fitxer de detalls de la comanda, cada registre de detalls de comanda s'ha d'omplir completament.]
Duplicació. La duplicació de registres en un sistema està completament resolta. Si se sap que el fitxer del producte té registres duplicats, s'identifiquen tots els registres duplicats de cada producte i es crea una referència creuada.
[Duplicat. S'ha eliminat completament la duplicació de registres al sistema. Si se sap que un fitxer de producte conté entrades duplicades, s'identifiquen totes les entrades duplicades de cada producte i es crea una referència creuada.]
Compliment de les normes empresarials. Els valors de cada element de dades s'adhereixen a les regles comercials prescrites. En un sistema de subhasta, el preu de martell o de venda no pot ser inferior al preu de reserva. En un sistema de préstec bancari, el saldo del préstec sempre ha de ser positiu o zero.
[Compliment de les normes empresarials. Els valors de cada element de dades compleixen les normes comercials establertes. En un sistema de subhasta, el preu de martell o de venda no pot ser inferior al preu de reserva. En un sistema de crèdit bancari, el saldo del préstec sempre ha de ser positiu o zero.]
Definició estructural. Sempre que un element de dades es pugui estructurar naturalment en components individuals, l'element ha de contenir aquesta estructura ben definida. Per exemple, el nom d'una persona es divideix naturalment en nom, inicial del segon i cognom. Els valors dels noms de les persones s'han d'emmagatzemar com a nom, inicial del segon i cognom. Aquesta característica de la qualitat de les dades simplifica l'aplicació dels estàndards i redueix els valors que falten.
[Certesa estructural. Quan un element de dades es pot estructurar de manera natural en components individuals, l'element ha de contenir aquesta estructura ben definida. Per exemple, el nom d'una persona es divideix naturalment en nom, inicial del segon i cognom. Els valors dels noms individuals s'han d'emmagatzemar com a nom, inicial del segon i cognom. Aquesta característica de qualitat de les dades simplifica l'aplicació dels estàndards i redueix els valors que falten.]
Anomalia de dades. Un camp s'ha d'utilitzar només per a la finalitat per a la qual està definit. Si el camp Adreça-3 està definit per a qualsevol tercera línia d'adreça possible per a adreces llargues, aquest camp només s'ha d'utilitzar per registrar la tercera línia d'adreça. No s'ha d'utilitzar per introduir un número de telèfon o fax per al client.
[Anomalia de dades. Un camp només s'ha d'utilitzar per a la finalitat per a la qual està definit. Si el camp Adreça-3 es defineix per a qualsevol possible tercera línia d'adreça per a adreces llargues, aquest camp només s'utilitzarà per registrar la tercera línia d'adreça. No s'ha d'utilitzar per introduir un número de telèfon o fax per a un client.]
Claredat. Un element de dades pot tenir totes les altres característiques de les dades de qualitat, però si els usuaris no entenen el significat clarament, aleshores l'element de dades no té cap valor per als usuaris. Les convencions de denominació adequades ajuden a fer que els usuaris entenguin els elements de dades.
[Claredat. Un element de dades pot tenir totes les altres característiques de les bones dades, però si els usuaris no entenen clarament el seu significat, aleshores l'element de dades no té cap valor per als usuaris. Les convencions de denominació correctes ajuden a que els usuaris entenguin bé els elements de les dades.]
Oportú. Els usuaris determinen l'actualitat de les dades. Si els usuaris esperen que les dades de la dimensió del client no siguin més antigues d'un dia, els canvis a les dades del client als sistemes d'origen s'han d'aplicar al magatzem de dades diàriament.
[D'una manera oportuna. Els usuaris determinen l'actualitat de les dades. Si els usuaris esperen que les dades de la dimensió del client no tinguin més d'un dia d'antiguitat, els canvis a les dades del client als sistemes d'origen s'han d'aplicar al magatzem de dades diàriament.]
Utilitat. Cada element de dades del magatzem de dades ha de satisfer alguns requisits de la col·lecció d'usuaris. Un element de dades pot ser precís i d'alta qualitat, però si no té cap valor per als usuaris, és totalment innecessari que aquest element de dades estigui al magatzem de dades.
[Utilitat. Cada element de dades del magatzem de dades ha de satisfer alguns requisits de la recollida d'usuaris. Un element de dades pot ser precís i de gran qualitat, però si no aporta valor als usuaris, no és necessari que aquest element de dades estigui al magatzem de dades.]
Adhesió a les normes d'integritat de dades. Les dades emmagatzemades a les bases de dades relacionals dels sistemes font han d'adherir-se a les regles d'integritat de l'entitat i d'integritat referencial. Qualsevol taula que permeti null com a clau primària no té integritat de l'entitat. La integritat referencial obliga a establir correctament les relacions pares-fills. En una relació client a comanda, la integritat referencial garanteix l'existència d'un client per a cada comanda de la base de dades.
[Compliment de les normes d'integritat de dades. Les dades emmagatzemades en bases de dades relacionals dels sistemes font han de complir les regles d'integritat de l'entitat i integritat referencial. Qualsevol taula que permeti null com a clau primària no té integritat de l'entitat. La integritat referencial obliga a establir correctament la relació entre pares i fills. En una relació client-comanda, la integritat referencial assegura que existeix un client per a cada comanda de la base de dades.]
4. Qualitat de la neteja de dades
La qualitat de la neteja de dades és un problema bastant problemàtic en bigdata. Respondre a la pregunta de quin grau de neteja de dades és necessari per completar la tasca és fonamental per a cada analista de dades. En la majoria de problemes actuals, cada analista ho determina ell mateix i és poc probable que algú de l'exterior sigui capaç d'avaluar aquest aspecte en la seva solució. Però per a la tasca que ens ocupa en aquest cas, aquest tema era extremadament important, ja que la fiabilitat de les dades legals hauria de tendir a un.
Tenir en compte les tecnologies de prova de programari per determinar la fiabilitat operativa. Avui n'hi ha més que aquests models . Molts dels models utilitzen un model de servei de reclamacions:
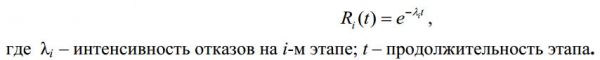
La figura. 6
Pensant de la següent manera: "Si l'error trobat és un esdeveniment similar a l'esdeveniment de fallada en aquest model, llavors com trobar un anàleg del paràmetre t?" I vaig compilar el següent model: imaginem que el temps que triga un verificador a comprovar un registre és d'1 minut (per a la base de dades en qüestió), després per trobar tots els errors necessitarà 365 minuts, que són aproximadament 494 anys i 3 mesos de temps de treball. Com entenem, això és una quantitat de treball molt gran i els costos de comprovar la base de dades seran prohibitius per al compilador d'aquesta base de dades. En aquesta reflexió apareix el concepte econòmic de costos i després de l'anàlisi vaig arribar a la conclusió que es tracta d'una eina força eficaç. Segons la llei de l'economia: “El volum de producció (en unitats) en què s'aconsegueix el benefici màxim d'una empresa es troba en el punt on es compara el cost marginal de produir una nova unitat de producció amb el preu que aquesta empresa pot rebre. per a una nova unitat”. Partint del postulat que trobar cada error posterior requereix cada cop més comprovació dels registres, aquest és un factor de cost. És a dir, el postulat adoptat en models de prova adquireix un significat físic en el següent patró: si per trobar l'i-èsimo error calia comprovar n registres, llavors per trobar el següent error (i+3) serà necessari. per comprovar m registres i alhora n
- Quan el nombre de registres comprovats abans de trobar un nou error s'estabilitza;
- Quan augmentarà el nombre de registres comprovats abans de trobar el següent error.
Per determinar el valor crític, vaig recórrer al concepte de viabilitat econòmica, que en aquest cas, utilitzant el concepte de costos socials, es pot formular de la següent manera: “Els costos de corregir l'error han de ser a càrrec de l'agent econòmic que pot fer-ho. al menor cost." Tenim un agent: un verificador que passa 1 minut comprovant un registre. En termes monetaris, si guanyeu 6000 rubles/dia, això serà de 12,2 rubles. (aproximadament avui). Queda per determinar el segon costat de l'equilibri en dret econòmic. Vaig raonar així. Un error existent requerirà que la persona interessada dediqui esforços per corregir-lo, és a dir, el propietari de l'immoble. Suposem que això requereix 1 dia d'acció (enviar una sol·licitud, rebre un document corregit). Aleshores, des del punt de vista social, els seus costos seran iguals al salari mitjà diari. Salari mitjà acumulat a Khanty-Mansi Autonomous Okrug 73285 fregar. o 3053,542 rubles/dia. En conseqüència, obtenim un valor crític igual a:
3053,542: 12,2 = 250,4 unitats de registres.
Això vol dir, des del punt de vista social, si un verificador ha comprovat 251 registres i ha trobat un error, equival a que l'usuari corregi aquest error ell mateix. En conseqüència, si el provador va passar un temps equivalent a comprovar 252 registres per trobar el següent error, en aquest cas, és millor traslladar el cost de la correcció a l'usuari.
Aquí es presenta un enfocament simplificat, ja que des del punt de vista social cal tenir en compte tot el valor addicional que genera cada especialista, és a dir, els costos inclosos els impostos i pagaments socials, però el model és clar. Una conseqüència d'aquesta relació és el següent requisit per als especialistes: un especialista del sector informàtic ha de tenir un sou superior a la mitjana nacional. Si el seu sou és inferior al salari mitjà dels usuaris potencials de la base de dades, llavors ell mateix ha de comprovar tota la base de dades cos a mà.
Quan s'utilitza el criteri descrit, es forma el primer requisit per a la qualitat de la base de dades:
jo (tr). La proporció d'errors crítics no ha de superar 1/250,4 = 0,39938%. Una mica menys que or a la indústria. I en termes físics no hi ha més de 1459 registres amb errors.
Recull econòmic.
De fet, en cometre aquest nombre d'errors en els registres, la societat accepta pèrdues econòmiques per la quantitat de:
1459*3053,542 = 4 rubles.
Aquesta quantitat ve determinada pel fet que la societat no disposa d'eines per reduir aquests costos. Es dedueix que si algú disposa d'una tecnologia que li permeti reduir el nombre de registres amb errors a, per exemple, 259, això permetrà a la societat estalviar:
1200*3053,542 = 3 rubles.
Però al mateix temps, pot demanar el seu talent i el seu treball, bé, diguem: 1 milió de rubles.
És a dir, els costos socials es redueixen per:
3 – 664 = 250 rubles.
En essència, aquest efecte és el valor afegit de l'ús de tecnologies BigDat.
Però aquí s'ha de tenir en compte que es tracta d'un efecte social, i el propietari de la base de dades són les autoritats municipals, els seus ingressos per l'ús de la propietat registrada en aquesta base de dades, a una taxa del 0,3%, són: 2,778 milions de rubles/ curs. I aquests costos (4 rubles) no li molesten gaire, ja que es transfereixen als propietaris. I, en aquest aspecte, el desenvolupador de tecnologies més refinades a Bigdata haurà de demostrar la capacitat de convèncer el propietari d'aquesta base de dades, i aquestes coses requereixen un talent considerable.
En aquest exemple, l'algoritme d'avaluació d'errors es va escollir basant-se en el model Schumann [2] de verificació del programari durant les proves de fiabilitat. Per la seva prevalença a Internet i la capacitat d'obtenir els indicadors estadístics necessaris. La metodologia està extreta de Monakhov Yu.M. "Estabilitat funcional dels sistemes d'informació", vegeu sota el spoiler de la Fig. 7-9.
Arròs. 7 – 9 Metodologia del model Schumann


La segona part d'aquest material presenta un exemple de neteja de dades, en el qual s'obtenen els resultats de l'ús del model de Schumann.
Permeteu-me presentar els resultats obtinguts:
Nombre estimat d'errors N = 3167 n.
Paràmetre C, lambda i funció de fiabilitat:
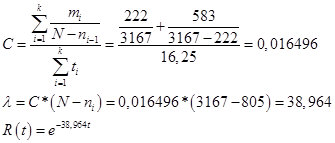
Fig. 17
Bàsicament, lambda és un indicador real de la intensitat amb què es detecten errors en cada etapa. Si ens fixem en la segona part, l'estimació d'aquest indicador era de 42,4 errors per hora, que és força comparable a l'indicador de Schumann. Més amunt, es va determinar que la velocitat a la qual un desenvolupador troba errors no hauria de ser inferior a 1 error per cada 250,4 registres, en comprovar 1 registre per minut. D'aquí el valor crític de lambda per al model de Schumann:
60 / 250,4 = 0,239617.
És a dir, la necessitat de realitzar tràmits de detecció d'errors s'ha de dur a terme fins que lambda, de l'existent 38,964, disminueixi a 0,239617.
O fins que l'indicador N (nombre potencial d'errors) menys n (nombre d'errors corregit) disminueixi per sota del nostre llindar acceptat: 1459 peces.
Literatura
- Monakhov, Yu. M. Estabilitat funcional dels sistemes d'informació. En 3 hores Part 1. Fiabilitat del programari: llibre de text. subsidi / Yu. M. Monakhov; Vladim. estat univ. – Vladimir: Izvo Vladim. estat Universitat, 2011. – 60 p. – ISBN 978-5-9984-0189-3.
- Martin L. Shooman, "Models probabilistes per a la predicció de la fiabilitat del programari".
- Fonaments de l'emmagatzematge de dades per a professionals de les TI / Paulraj Ponniah.—2a ed.
Font: www.habr.com
