

Hola a tothom, em dic Alexander i sóc un enginyer de qualitat de dades que en comprova la qualitat de les dades. Aquest article parlarà de com vaig arribar a això i per què el 2020 aquesta àrea de proves estava a la cresta d'una onada.

Tendència global
El món actual està vivint una altra revolució tecnològica, un aspecte de la qual és l'ús de les dades acumulades per part de tot tipus d'empreses per promoure el seu propi volant de vendes, beneficis i relacions públiques. Sembla que la presència de dades de bona (de qualitat), així com de cervells qualificats que en puguin guanyar diners (processar, visualitzar correctament, construir models d'aprenentatge automàtic, etc.), s'han convertit en la clau de l'èxit per a molts avui dia. Si fa 15-20 anys les grans empreses es dedicaven principalment a un treball intensiu amb l'acumulació de dades i la monetització, avui aquesta és la part de gairebé totes les persones sensates.
En aquest sentit, fa uns quants anys, tots els portals dedicats a la recerca de feina d'arreu del món es van començar a cobrir amb vacants de Data Scientists, ja que tothom estava segur que, havent contractat aquest especialista, seria possible construir un supermodel d'aprenentatge automàtic. , predir el futur i fer un "salt quàntic" per a l'empresa. Amb el pas del temps, la gent es va adonar que aquest enfocament gairebé mai funciona enlloc, ja que no totes les dades que cauen en mans d'aquests especialistes són adequades per a models de formació.
I van començar les peticions dels Data Scientists: "Comprem més dades d'aquests i d'aquells...", "No tenim prou dades...", "Necessitem més dades, preferiblement d'alta qualitat..." . A partir d'aquestes sol·licituds, es van començar a construir nombroses interaccions entre empreses que posseeixen un o altre conjunt de dades. Naturalment, això va requerir l'organització tècnica d'aquest procés: connectar-se a la font de dades, descarregar-lo, comprovar que s'ha carregat completament, etc. El nombre d'aquests processos va començar a créixer i avui tenim una gran necessitat d'un altre tipus de especialistes: enginyers de qualitat de dades: aquells que supervisarien el flux de dades al sistema (canalitats de dades), la qualitat de les dades a l'entrada i la sortida, i extreuen conclusions sobre la seva suficiència, integritat i altres característiques.
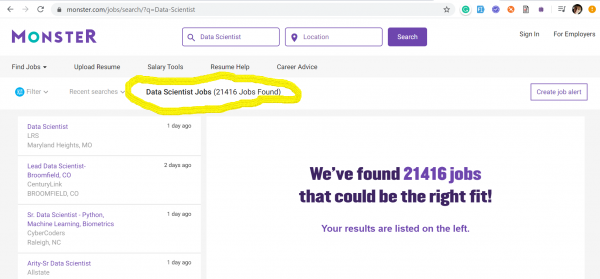
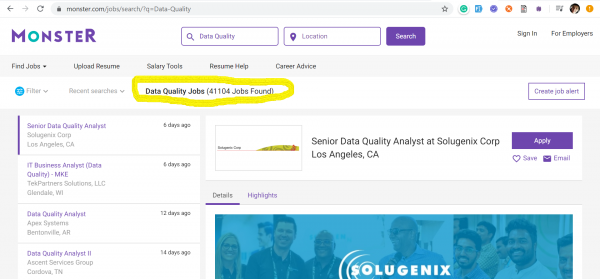
La tendència dels enginyers de qualitat de dades ens va arribar des dels EUA, on, enmig de l'era furiosa del capitalisme, ningú està disposat a perdre la batalla per les dades. A continuació, he proporcionat captures de pantalla de dos dels llocs de recerca de feina més populars dels EUA: и — que mostra dades a partir del 17 de març de 2020 sobre el nombre de vacants publicades rebudes mitjançant les paraules clau: Data Quality and Data Scientist.
Data Scientists – 21416 vacants
Qualitat de les dades – 41104 vacants
Data Scientists – 404 vacants
Data Quality – vacants 2020
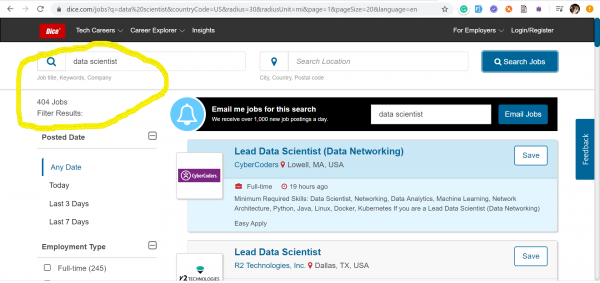
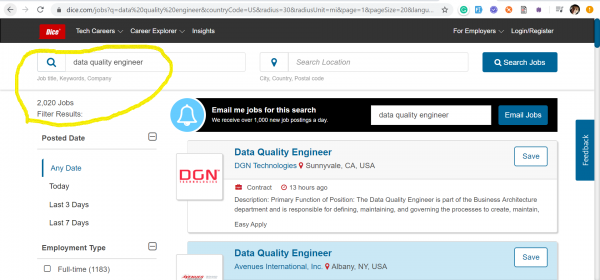
Evidentment, aquestes professions no competeixen de cap manera entre elles. Amb captures de pantalla només volia il·lustrar la situació actual del mercat laboral pel que fa a les sol·licituds d'enginyers de Qualitat de Dades, dels quals ara calen molt més que Data Scientists.
El juny de 2019, EPAM, responent a les necessitats del mercat informàtic modern, va separar Data Quality en una pràctica independent. Els enginyers de Data Quality, en el transcurs de la seva tasca diària, gestionen les dades, comproven el seu comportament en noves condicions i sistemes, vigilen la rellevància de les dades, la seva suficiència i rellevància. Amb tot això, en un sentit pràctic, els enginyers de qualitat de dades realment dediquen poc temps a les proves funcionals clàssiques, PERÒ això depèn molt del projecte (en posaré un exemple a continuació).
Les responsabilitats d'un enginyer de qualitat de dades no es limiten només a les comprovacions manuals/automàtiques rutinàries de "nul·litats, recomptes i sumes" a les taules de bases de dades, sinó que requereixen una comprensió profunda de les necessitats comercials del client i, en conseqüència, la capacitat de transformar les dades disponibles en informació comercial útil.
Teoria de la qualitat de les dades

Per tal d'imaginar millor el paper d'aquest enginyer, anem a esbrinar què és la qualitat de les dades en teoria.
Qualitat de les dades — una de les etapes de la Gestió de Dades (tot un món que us deixarem estudiar pel vostre compte) i s'encarrega d'analitzar les dades d'acord amb els criteris següents:
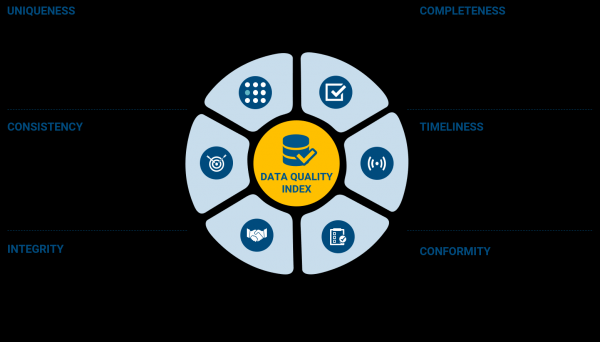
Crec que no cal desxifrar cadascun dels punts (en teoria s'anomenen "dimensions de dades"), estan força ben descrits a la imatge. Però el procés de prova en si no implica copiar estrictament aquestes funcions als casos de prova i comprovar-les. En Data Quality, com en qualsevol altre tipus de proves, cal, en primer lloc, basar-se en els requisits de qualitat de dades acordats amb els participants del projecte que prenen decisions empresarials.
Segons el projecte Data Quality, un enginyer pot realitzar diferents funcions: des d'un verificador d'automatització normal amb una avaluació superficial de la qualitat de les dades, fins a una persona que realitza un perfil profund de les dades d'acord amb els criteris anteriors.
Una descripció molt detallada de la gestió de dades, la qualitat de les dades i els processos relacionats està ben descrita al llibre anomenat "DAMA-DMBOK: Cos de coneixements de gestió de dades: 2a edició". Recomano molt aquest llibre com a introducció a aquest tema (hi trobareu un enllaç al final de l'article).
La meva història
A la indústria informàtica, vaig passar d'un provador júnior en empreses de productes a un enginyer principal de qualitat de dades a l'EPAM. Després d'uns dos anys treballant com a provador, vaig tenir la ferma convicció que havia fet absolutament tot tipus de proves: regressió, funcional, d'estrès, estabilitat, seguretat, interfície d'usuari, etc.- i vaig provar un gran nombre d'eines de prova, havent-hi treballava alhora en tres llenguatges de programació: Java, Scala, Python.
Mirant enrere, entenc per què el meu conjunt d'habilitats era tan divers: vaig participar en projectes basats en dades, grans i petits. Això és el que em va portar a un món de moltes eines i oportunitats de creixement.
Per apreciar la varietat d'eines i oportunitats per adquirir nous coneixements i habilitats, només cal que mireu la imatge següent, que mostra les més populars al món de "Dades i IA".

Aquest tipus d'il·lustració és compilada anualment per un dels famosos capitalistes de risc Matt Turck, que prové del desenvolupament de programari. Aquí al seu blog i , on treballa com a soci.
Vaig créixer professionalment especialment ràpidament quan era l'únic provador del projecte, o almenys al començament del projecte. És en aquest moment que has de ser responsable de tot el procés de prova i no tens oportunitat de retirar-te, només endavant. Al principi feia por, però ara tots els avantatges d'aquesta prova són evidents per a mi:
- Comences a comunicar-te amb tot l'equip com mai abans, ja que no hi ha cap proxy per a la comunicació: ni el responsable de la prova ni els companys de prova.
- La immersió en el projecte es fa increïblement profunda i tens informació sobre tots els components, tant en general com en detall.
- Els desenvolupadors no et veuen com "aquell noi de les proves que no sap què està fent", sinó com un igual que produeix beneficis increïbles per a l'equip amb les seves proves automatitzades i l'anticipació d'errors que apareixen en un component específic del sistema. producte.
- Com a resultat, sou més eficaç, més qualificat i més demandat.
A mesura que el projecte anava creixent, en el 100% dels casos em vaig convertir en mentor de nous testers, ensenyant-los i transmetent els coneixements que havia après jo mateix. Al mateix temps, segons el projecte, no sempre vaig rebre el màxim nivell d'especialistes en proves d'automòbils de la direcció i calia formar-los en automatització (per als interessats) o crear eines per utilitzar-les en les activitats quotidianes (eines). per generar dades i carregar-les al sistema, una eina per realitzar proves de càrrega/proves d'estabilitat "ràpidament", etc.).
Exemple d'un projecte concret
Malauradament, a causa de les obligacions de no divulgació, no puc parlar amb detall dels projectes en els quals he treballat, però donaré exemples de tasques típiques d'un enginyer de qualitat de dades en un dels projectes.
L'essència del projecte és implementar una plataforma per preparar dades per entrenar models d'aprenentatge automàtic basats en ella. El client era una gran empresa farmacèutica dels EUA. Tècnicament era un clúster , pujant a instàncies, amb diversos microserveis i el projecte de codi obert subjacent d'EPAM - , adaptat a les necessitats d'un client concret (ara el projecte ha tornat a néixer ). Els processos ETL es van organitzar mitjançant i mogut dades de sistemes de client en Cubells. A continuació, es va desplegar una imatge de Docker d'un model d'aprenentatge automàtic a la plataforma, que es va entrenar amb dades noves i, mitjançant la interfície de l'API REST, va produir prediccions que eren d'interès per al negoci i van resoldre problemes específics.
Visualment, tot semblava així:
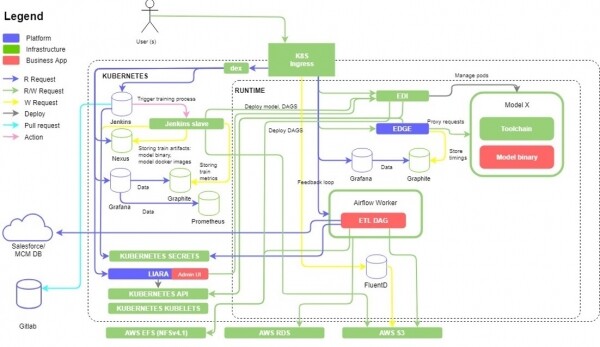
Hi va haver moltes proves funcionals en aquest projecte, i donada la velocitat del desenvolupament de funcions i la necessitat de mantenir el ritme del cicle de llançament (esprints de dues setmanes), va ser necessari pensar immediatament a automatitzar les proves dels components més crítics de el sistema. La major part de la plataforma basada en Kubernetes estava coberta per autotests implementats a + Python, però també calia donar-los suport i ampliar-los. A més, per a la comoditat del client, es va crear una GUI per gestionar els models d'aprenentatge automàtic desplegats al clúster, així com la possibilitat d'especificar on i on s'han de transferir les dades per entrenar els models. Aquesta àmplia incorporació va comportar una ampliació de les proves funcionals automatitzades, que es van fer principalment mitjançant trucades a l'API REST i un petit nombre de proves d'IU d'extrem 2. Al voltant de l'equador de tot aquest moviment, ens va unir un verificador manual que va fer un treball excel·lent amb les proves d'acceptació de les versions del producte i comunicant-se amb el client sobre l'acceptació de la propera versió. A més, a causa de l'arribada d'un nou especialista, vam poder documentar la nostra feina i afegir diverses comprovacions manuals molt importants que van ser difícils d'automatitzar de seguida.
I, finalment, després d'aconseguir l'estabilitat de la plataforma i del complement GUI sobre ella, vam començar a construir canonades ETL mitjançant Apache Airflow DAG. La comprovació automatitzada de la qualitat de les dades es va dur a terme mitjançant l'escriptura de DAG especials de flux d'aire que verificaven les dades en funció dels resultats del procés ETL. Com a part d'aquest projecte, vam tenir sort i el client ens va donar accés a conjunts de dades anònims sobre els quals vam provar. Vam comprovar el compliment de les dades línia per línia, la presència de dades trencades, el nombre total de registres abans i després, comparació de transformacions fetes pel procés ETL per a l'agregació, canvi de noms de columnes i altres coses. A més, aquestes comprovacions es van escalar a diferents fonts de dades, per exemple, a més de SalesForce, també a MySQL.
Les comprovacions finals de la qualitat de les dades ja es van dur a terme al nivell S3, on es van emmagatzemar i estaven llestes per utilitzar per a la formació de models d'aprenentatge automàtic. Per obtenir dades del fitxer CSV final situat a l'S3 Bucket i validar-lo, es va escriure codi .
També hi havia un requisit del client per emmagatzemar part de les dades en un S3 Bucket i part en un altre. Això també requeria escriure comprovacions addicionals per comprovar la fiabilitat d'aquesta classificació.
Experiència generalitzada d'altres projectes
Un exemple de la llista més general d'activitats d'un enginyer de qualitat de dades:
- Prepareu les dades de prova (vàlid no vàlid gran petit) mitjançant una eina automatitzada.
- Carregueu el conjunt de dades preparat a la font original i comproveu que estigui llest per utilitzar-lo.
- Inicieu processos ETL per processar un conjunt de dades des de l'emmagatzematge d'origen fins a l'emmagatzematge final o intermedi mitjançant un determinat conjunt de paràmetres (si és possible, establiu paràmetres configurables per a la tasca ETL).
- Verificar la qualitat de les dades processades pel procés ETL i el compliment dels requisits empresarials.
Al mateix temps, l'enfocament principal de les comprovacions hauria de ser no només en el fet que el flux de dades del sistema, en principi, ha funcionat i ha arribat a la seva finalització (que forma part de les proves funcionals), sinó sobretot en comprovar i validar les dades per compliment dels requisits esperats, identificació d'anomalies i altres coses.
Instruments
Una de les tècniques per a aquest control de dades pot ser l'organització de controls en cadena a cada etapa del processament de dades, l'anomenada "cadena de dades" a la literatura: control de dades des de la font fins al punt d'ús final. Aquest tipus de comprovacions s'implementen més sovint escrivint consultes SQL de verificació. És clar que aquestes consultes han de ser tan lleugeres com sigui possible i comprovar la qualitat de les dades individuals (metadades de taules, línies en blanc, NULL, errors de sintaxi, altres atributs necessaris per a la verificació).
En el cas de les proves de regressió, que utilitzen conjunts de dades ja fets (incanviables, lleugerament canviables), el codi de prova automàtica pot emmagatzemar plantilles ja fetes per comprovar el compliment de les dades amb la qualitat (descripcions de les metadades de la taula esperades; objectes de mostra de fila que es poden seleccionats aleatòriament durant la prova, etc.).
A més, durant les proves, heu d'escriure processos de prova ETL utilitzant marcs com Apache Airflow, o fins i tot una eina tipus núvol de caixa negra , Etcètera. Aquesta circumstància obliga l'enginyer de proves a submergir-se en els principis de funcionament de les eines anteriors i de manera encara més eficaç tant a realitzar proves funcionals (per exemple, processos ETL existents en un projecte) com a utilitzar-les per comprovar les dades. En particular, Apache Airflow té operadors preparats per treballar amb bases de dades analítiques populars, per exemple . L'exemple més bàsic del seu ús ja s'ha esbossat , així que no em repetiré.
A part de les solucions ja fetes, ningú us prohibeix implementar les vostres pròpies tècniques i eines. Això no només serà beneficiós per al projecte, sinó també per al propi Data Quality Engineer, que millorarà així els seus horitzons tècnics i habilitats de codificació.
Com funciona en un projecte real
Una bona il·lustració dels últims paràgrafs sobre la "cadena de dades", ETL i comprovacions ubiquas és el següent procés d'un dels projectes reals:
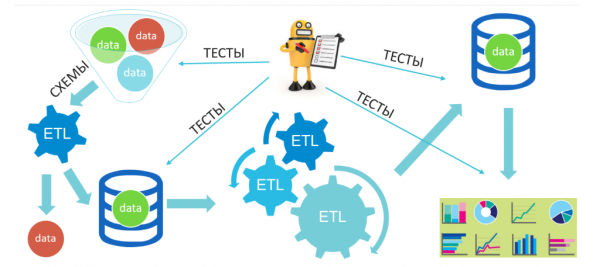
Aquí, diverses dades (naturalment, preparades per nosaltres) entren a l'"embut" d'entrada del nostre sistema: vàlides, no vàlides, mixtes, etc., després es filtren i acaben en un emmagatzematge intermedi, després tornen a patir una sèrie de transformacions. i es col·loquen a l'emmagatzematge final, des del qual, al seu torn, es durà a terme l'anàlisi, la construcció de data marts i la recerca de coneixements empresarials. En aquest sistema, sense comprovar funcionalment el funcionament dels processos ETL, ens centrem en la qualitat de les dades abans i després de les transformacions, així com en la sortida a l'anàlisi.
Per resumir l'anterior, independentment dels llocs on he treballat, a tot arreu he participat en projectes de dades que comparteixen les següents característiques:
- Només mitjançant l'automatització podeu provar alguns casos i aconseguir un cicle de llançament acceptable per al negoci.
- Un provador d'aquest projecte és un dels membres més respectats de l'equip, ja que aporta grans beneficis a cadascun dels participants (acceleració de les proves, bones dades del Data Scientist, identificació de defectes en les primeres etapes).
- No importa si treballeu al vostre propi maquinari o als núvols: tots els recursos s'abstreuen en un clúster com Hortonworks, Cloudera, Mesos, Kubernetes, etc.
- Els projectes es construeixen amb un enfocament de microserveis, predomina la informàtica distribuïda i paral·lela.
M'agradaria assenyalar que quan fa proves en l'àmbit de la qualitat de les dades, un especialista en proves desplaça el seu enfocament professional cap al codi del producte i les eines utilitzades.
Característiques distintives de les proves de qualitat de dades
A més, per mi mateix, he identificat els següents trets distintius (de seguida faré una reserva perquè són MOLT generalitzats i exclusivament subjectius) de les proves en projectes (sistemes) de dades (Big Data) i altres àrees:

links útils
- Teoria: .
- EPAM
- Materials recomanats per a un enginyer de qualitat de dades principiant:
- Curs gratuït sobre Stepik: .
- Curs sobre LinkedIn Learning: .
- Articles:
- ;
- ;
- ;
- Vídeo:
- ;
- ;
Conclusió
Qualitat de les dades és una direcció molt jove i prometedora, formar part de la qual significa formar part d'una startup. Un cop a Data Quality, estaràs immers en un gran nombre de tecnologies modernes i demanades, però el més important, s'obriran enormes oportunitats perquè puguis generar i implementar les teves idees. Podreu utilitzar l'enfocament de millora contínua no només en el projecte, sinó també per a vosaltres mateixos, desenvolupant-vos contínuament com a especialista.
Font: www.habr.com
