


Salutu à tutti ! Mi chjamu Dmitry Samsonov, è travagliu cum'è amministratore di sistema principale in Odnoklassniki. Avemu più di 7 servitori fisichi, 11 container in u nostru cloud, è 200 applicazioni, chì in varie cunfigurazioni formanu 700 cluster diversi. A grande maggioranza di i servitori sò in esecuzione. CentOS 7.
U 14 d'aostu di u 2018, infurmazione nantu à a vulnerabilità FragmentSmack hè stata publicata
() è SegmentSmack (). Il s'agit de vulnérabilités avec un vecteur d'attaque de réseau et un score assez élevé (7.5), qui menace le déni de service (DoS) à cause de l'épuisement des ressources (CPU). Una correzione di u kernel per FragmentSmack ùn hè micca stata pruposta à quellu tempu; in più, hè surtitu assai più tardi di a publicazione di l'infurmazioni nantu à a vulnerabilità. Per eliminà SegmentSmack, hè stata suggerita per aghjurnà u kernel. U pacchettu d'aghjurnamentu stessu hè statu liberatu u stessu ghjornu, tuttu ciò chì restava era di stallà.
Innò, ùn simu micca contru à l'aghjurnamentu di u kernel ! Tuttavia, ci sò sfumature ...
Cumu aghjurnà u kernel nantu à a produzzione
In generale, nunda complicatu:
- Scaricate i pacchetti;
- Installali nantu à una quantità di servitori (cumpresi i servitori chì ospitanu a nostra nuvola);
- Assicuratevi chì nunda hè rottu;
- Assicuratevi chì tutti i paràmetri di u kernel standard sò applicati senza errori;
- Aspetta uni pochi di ghjorni;
- Verificate u rendiment di u servitore;
- Cambia l'implementazione di novi servitori à u novu kernel;
- Aghjurnate tutti i servitori da u centru di dati (un centru di dati à u tempu per minimizzà l'effettu nantu à l'utilizatori in casu di prublemi);
- Reboot tutti i servitori.
Repetite per tutti i rami di i kernels chì avemu. À u mumentu hè:
- Stock CentOS 7 3.10 - per a maiò parte di i servitori regulari;
- Vanilla 4.19 - per i nostri , perchè avemu bisognu di BFQ, BBR, etc.;
- Elrepo kernel-ml 5.2 - per , perchè 4.19 usava cumportanu inestabile, ma i stessi funziunalità sò necessarii.
Cum'è avete capitu, u reboot di millaie di servitori piglia u più longu tempu. Siccomu micca tutte e vulnerabilità sò critichi per tutti i servitori, riavviate solu quelli chì sò direttamente accessibili da Internet. In u nuvulu, per ùn limità micca a flessibilità, ùn ligate micca cuntenituri accessibili esternamente à i servitori individuali cù un novu kernel, ma riavviate tutti l'ospiti senza eccezzioni. Fortunatamente, a prucedura hè più simplice chè cù i servitori regulari. Per esempiu, i cuntenituri apatridi ponu simpricimenti spustà à un altru servitore durante un reboot.
Tuttavia, ci hè sempre assai di travagliu, è pò piglià parechje settimane, è s'ellu ci sò prublemi cù a nova versione, finu à parechji mesi. L'attaccanti capiscenu assai bè, cusì anu bisognu di un pianu B.
FragmentSmack/SegmentSmack. Soluzione
Fortunatamente, per alcune vulnerabilità un tali pianu B esiste, è hè chjamatu Workaround. A maiò spessu, questu hè un cambiamentu in i paràmetri di u kernel / l'applicazione chì ponu minimizzà l'effettu pussibule o eliminà cumplettamente a sfruttamentu di vulnerabili.
In u casu di FragmentSmack/SegmentSmack sta soluzione:
«Pudete cambià i valori predeterminati di 4MB è 3MB in net.ipv4.ipfrag_high_thresh è net.ipv4.ipfrag_low_thresh (è e so contraparti per ipv6 net.ipv6.ipfrag_high_thresh è net.ipv6.ipfrag_low_thresh) è rispettivamente à 256 kB o kB. più bassu. I testi mostranu gocce da piccule à significative in l'usu di CPU durante un attaccu secondu u hardware, i paràmetri è e cundizioni. Tuttavia, pò esse qualchì impattu di rendiment per via di ipfrag_high_thresh = 192 bytes, postu chì solu dui frammenti di 262144K ponu esse inseriti in a fila di riassembly à volta. Per esempiu, ci hè un risicu chì l'applicazioni chì travaglianu cù grandi pacchetti UDP si romperanu».
I paràmetri stessi descrittu cusì:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Ùn avemu micca grandi UDP nantu à i servizii di produzzione. Ùn ci hè micca un trafficu frammentatu nantu à a LAN; ci hè un trafficu frammentatu nantu à a WAN, ma micca significativu. Ùn ci sò micca signali - pudete lancià a Soluzione!
FragmentSmack/SegmentSmack. Primu sangue
U primu prublema chì avemu scontru era chì i cuntenituri di nuvola anu appiicatu à qualchì volta i novi paràmetri solu parzialmente (solu ipfrag_low_thresh), è à volte ùn l'anu micca appiicatu à tutti - simpricamente s'hè lampatu à u principiu. Ùn era micca pussibule di ripruduce u prublema in modu stabile (tutti i paràmetri sò stati applicati manualmente senza difficultà). Capisce perchè u cuntinuu crash à l'iniziu ùn hè micca cusì faciule: ùn sò micca stati trovati errori. Una cosa era certa: rinvià i paràmetri risolve u prublema cù i crash di container.
Perchè ùn hè micca abbastanza per applicà Sysctl nantu à l'ospite? U cuntainer vive in a so propria rete dedicata Namespace, cusì almenu in u cuntinuu pò esse diffirenti da l'ospiti.
Cume sò esattamente i paràmetri Sysctl applicati in u containeru? Siccomu i nostri cuntenituri ùn sò micca privilegiati, ùn puderete micca cambià alcuna paràmetru Sysctl andendu in u cuntainer stessu - ùn avete micca abbastanza diritti. Per eseguisce cuntenituri, a nostra nuvola in quellu tempu usava Docker (ora ). I paràmetri di u novu containeru sò stati passati à Docker via l'API, cumprese i paràmetri Sysctl necessarii.
Mentre cercava in e versioni, hè risultatu chì l'API Docker ùn hà micca restituutu tutti l'errori (almenu in a versione 1.10). Quandu avemu pruvatu à inizià u cuntinuu via "docker run", avemu finalmente vistu almenu qualcosa:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
U valore di u paràmetru ùn hè micca validu. Ma perchè ? E perchè ùn hè micca validu solu qualchì volta? Hè risultatu chì Docker ùn guarantisci micca l'ordine in quale i paràmetri Sysctl sò applicati (l'ultima versione pruvata hè 1.13.1), cusì à volte ipfrag_high_thresh hà pruvatu à esse stabilitu à 256K quandu ipfrag_low_thresh era sempre 3M, vale à dì, u limitu superiore era più bassu. cà u limitu minimu, chì hà purtatu à l'errore.
À quellu tempu, avemu digià utilizatu u nostru propiu mecanismu per cunfigurà u cuntinuu dopu l'iniziu (congelà u cuntinuu dopu è eseguisce cumandamenti in u namespace di u container via ), è avemu aghjustatu ancu scrive paràmetri Sysctl à sta parte. U prublema hè stata risolta.
FragmentSmack/SegmentSmack. Primu Sangue 2
Prima chì avemu avutu u tempu di capisce l'usu di Workaround in u nuvulu, i primi rari lagnanza di l'utilizatori cuminciaru à ghjunghje. À quellu tempu, parechje settimane avianu passatu da u principiu di l'usu di Workaround in i primi servitori. L'investigazione iniziale hà dimustratu chì e lagnanze sò state ricevute contr'à i servizii individuali, è micca tutti i servitori di sti servizii. U prublema hè torna torna assai incerta.
Prima di tuttu, avemu pruvatu à annullà i paràmetri Sysctl, ma questu ùn hà avutu nisun effettu. Diverse manipulazioni di i paràmetri di u servitore è di l'applicazione ùn anu micca aiutatu. Un riavviu hà aiutatu. Riavviate per Linux cum'è innaturale cum'è era una cundizione nurmale per travaglià cù Windows In i tempi antichi. Funzionava, però, è l'avemu attribuitu à un "errore di u kernel" quandu applicavamu novi paràmetri Sysctl. Chì scemi di a nostra parte...
Trè simane dopu, u prublema si ripresentò. A cunfigurazione di questi servitori era abbastanza simplice: Nginx in modu proxy / balancer. Pocu trafficu. Nova nota introduttiva: u numeru di errori 504 nantu à i clienti aumenta ogni ghjornu (). U graficu mostra u numeru di 504 errori per ghjornu per stu serviziu:
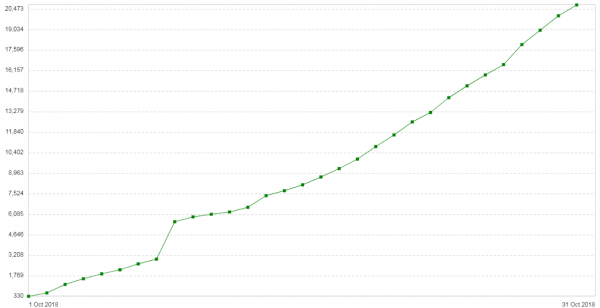
Tutti l'errori sò circa u listessu backend - circa quellu chì hè in u nuvulu. U graficu di cunsumu di memoria per i frammenti di pacchettu nantu à questu backend pareva cusì:
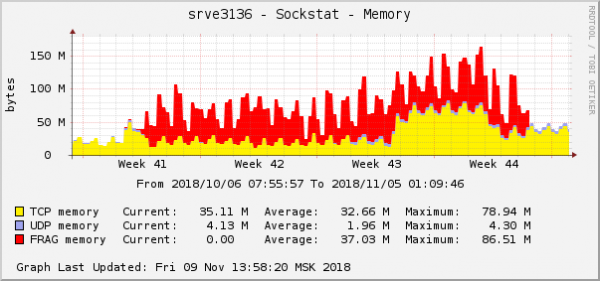
Questa hè una di e manifestazioni più evidenti di u prublema in i grafici di u sistema operatore. In u nuvulu, ghjustu à u stessu tempu, un altru prublema di rete cù i paràmetri di QoS (Control di Traffic) hè stata riparata. Nantu à u graficu di u cunsumu di memoria per i frammenti di pacchetti, pareva esattamente u listessu:
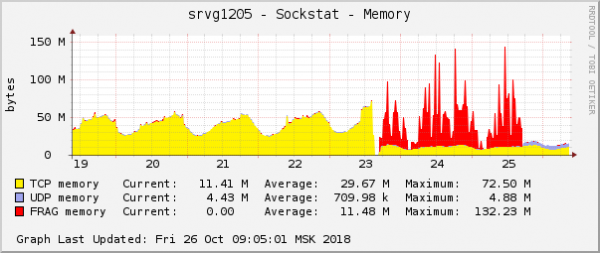
L'assunzione era simplice: s'ellu si vedenu listessi nantu à i grafici, allora anu u listessu mutivu. Inoltre, ogni prublema cù stu tipu di memoria hè assai raru.
L'essenza di u prublema fissu era chì avemu usatu u pianificatore di pacchetti fq cù paràmetri predeterminati in QoS. Per automaticamente, per una cunnessione, vi permette di aghjunghje 100 pacchetti à a fila, è alcune cunnessione, in situazione di mancanza di canali, cuminciaru à impiccà a fila à a capacità. In questu casu, i pacchetti sò abbandunati. In statistiche tc (tc -s qdisc) questu pò esse vistu cusì:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545 flows_plimit" hè i pacchetti abbandunati per via di u limitu di fila di una cunnessione, è "dropped 464545" hè a somma di tutti i pacchetti abbandunati di stu pianificatore. Dopu avè aumentatu a lunghezza di a fila à 1 mila è riavviatu i cuntenituri, u prublema hà cessatu di accade. Pudete pusà è beie un smoothie.
FragmentSmack/SegmentSmack. Ultimu Sangue
Prima di tuttu, parechji mesi dopu à l'annunziu di e vulnerabilità di u kernel, hè stata finalmente publicata una correzione per FragmentSmack (ricurdatevi, l'annunziu d'aostu hà publicatu solu una correzione per SegmentSmack), chì ci hà datu a pussibilità di abbandunà Workaround, chì ci avia causatu parechji prublemi. Avemu digià migratu alcuni servitori versu u novu kernel durante questu tempu, è avà duvemu ricumincià da zero. Perchè avemu aggiornatu u kernel senza aspittà a correzione di FragmentSmack? U fattu hè chì u prucessu di prutezzione contr'à queste vulnerabilità hà cuincisu (è si hè fusu) cù u prucessu di aghjurnamentu di Workaround stessu. CentOS (chì piglia ancu più tempu chè l'aghjurnamentu solu di u kernel). Inoltre, SegmentSmack hè una vulnerabilità più periculosa, è una correzione per ella era dispunibule subitu, dunque avia sensu in ogni modu. Tuttavia, basta à aghjurnà u kernel CentOS ùn pudemu micca per via di a vulnerabilità FragmentSmack chì hè apparsa durante u CentOS A versione 7.5 hè stata riparata solu in a versione 7.6, dunque avemu avutu à piantà l'aghjurnamentu à 7.5 è ricumincià da capu cù l'aghjurnamentu à 7.6. Questu succede ancu.
In segundu, i rari reclami di l'utilizatori nantu à i prublemi sò tornati à noi. Avà sapemu di sicuru chì sò tutti ligati à a carica di i schedari da i clienti à alcuni di i nostri servitori. Inoltre, un numeru assai chjucu di carichi da a massa tutale passava per questi servitori.
Cumu ricurdamu da a storia sopra, rolling back Sysctl ùn hà micca aiutu. Reboot hà aiutatu, ma temporaneamente.
I suspetti riguardanti Sysctl ùn sò micca stati eliminati, ma sta volta era necessariu di cullà quant'è più infurmazione pussibule. Ci era ancu una grande mancanza di capacità di ripruduce u prublema di upload nantu à u cliente per studià più precisamente ciò chì succede.
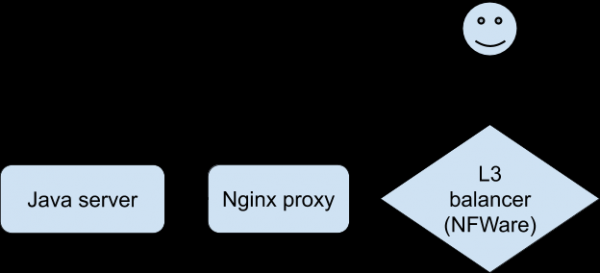
L'analisi di tutte e statistiche è i logs dispunibuli ùn ci anu purtatu più vicinu à capisce ciò chì succede. Ci era una mancanza aguda di capacità di ripruduce u prublema per "senti" una cunnessione specifica. Infine, i sviluppatori, aduprendu una versione speciale di l'applicazione, anu sappiutu ottene una riproduzione stabile di prublemi nantu à un dispositivu di prova quandu cunnessu via Wi-Fi. Questu hè statu un avanzu in l'inchiesta. U cliente cunnessu à Nginx, chì proxy à u backend, chì era a nostra applicazione Java.
U dialogu per i prublemi era cusì (fissatu nantu à u latu proxy Nginx):
- Cliente: dumanda di riceve infurmazione nantu à u scaricamentu di un schedariu.
- Servitore Java: risposta.
- Cliente: POST cù u schedariu.
- Servitore Java: errore.
À u listessu tempu, u servitore Java scrive à u logu chì 0 bytes di dati sò stati ricevuti da u cliente, è u proxy Nginx scrive chì a dumanda hà pigliatu più di 30 seconde (30 seconde hè u timeout di l'applicazione cliente). Perchè u timeout è perchè 0 bytes? Da una perspettiva HTTP, tuttu funziona cum'è deve, ma u POST cù u schedariu pare sparisce da a reta. Inoltre, sparisce trà u cliente è Nginx. Hè ora di armassi cù Tcpdump ! Ma prima ci vole à capisce a cunfigurazione di a reta. Nginx proxy hè daretu à u balancer L3 . Tunneling hè utilizatu per furnisce i pacchetti da u balancer L3 à u servitore, chì aghjunghje i so intestazioni à i pacchetti:
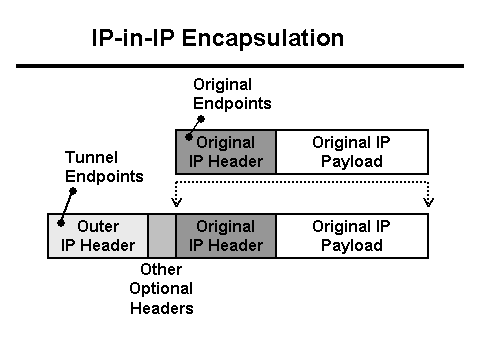
In questu casu, a reta vene à stu servitore in a forma di trafficu Vlan-tagged, chì aghjunghje ancu i so propii campi à i pacchetti:
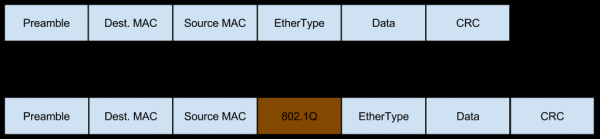
È stu trafficu pò ancu esse frammentatu (u stessu picculu percentuale di u trafficu frammentatu in entrata chì avemu parlatu quandu evaluà i risichi da Workaround), chì cambia ancu u cuntenutu di l'intestazione:
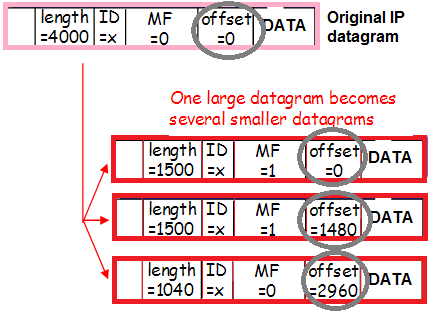
Una volta: i pacchetti sò incapsulati cù un tag Vlan, incapsulati cù un tunnel, frammentati. Per capisce megliu cumu succede questu, tracciamu a strada di u pacchettu da u cliente à u proxy Nginx.
- U pacchettu righjunghji u balancer L3. Per u routing currettu in u centru di dati, u pacchettu hè incapsulatu in un tunnel è mandatu à a carta di rete.
- Siccomu l'intestazione di u pacchettu + tunnel ùn si mette in u MTU, u pacchettu hè tagliatu in frammenti è mandatu à a reta.
- U cambiamentu dopu à u balancer L3, quandu riceve un pacchettu, aghjunghje un tag Vlan à ellu è u manda.
- U cambiamentu davanti à u proxy Nginx vede (basatu nantu à i paràmetri di u portu) chì u servitore aspetta un pacchettu incapsulatu in Vlan, cusì u manda cum'è, senza sguassà l'etichetta Vlan.
- Linux riceve frammenti di pacchetti individuali è li incolla in un grande pacchettu.
- Dopu, u pacchettu righjunghji l'interfaccia Vlan, induve a prima capa hè sguassata da questu - Vlan encapsulation.
- tandu Linux u manda à l'interfaccia di u Tunnel, induve un altru stratu hè eliminatu da ellu - Incapsulazione di u Tunnel.
A difficultà hè di passà tuttu questu cum'è paràmetri à tcpdump.
Cuminciamu da a fine: ci sò pacchetti IP puliti (senza intestazioni innecessarii) da i clienti, cù l'incapsulazione di vlan è tunnel eliminata?
tcpdump host <ip клиента>
Innò, ùn ci era micca tali pacchetti nantu à u servitore. Allora u prublema deve esse quì prima. Ci hè qualchì pacchettu cù solu l'incapsulazione Vlan eliminata?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx hè l'indirizzu IP di u cliente in formatu hex.
32:4 - indirizzu è lunghezza di u campu in quale l'IP SCR hè scrittu in u pacchettu Tunnel.
L'indirizzu di u campu duvia esse sceltu da a forza bruta, postu chì in Internet scrivenu circa 40, 44, 50, 54, ma ùn ci era micca indirizzu IP. Pudete ancu vede unu di i pacchetti in hex (u paràmetru -xx o -XX in tcpdump) è calculà l'indirizzu IP chì cunnosci.
Ci sò frammenti di pacchetti senza incapsulazione Vlan è Tunnel eliminati?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Sta magia ci mostrarà tutti i frammenti, cumpresu l'ultimu. Probabilmente, a listessa cosa pò esse filtrata da IP, ma ùn aghju micca pruvatu, perchè ùn ci sò micca assai tali pacchetti, è quelli chì avia bisognu sò facilmente truvati in u flussu generale. Eccu sò:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 In 00:de:ff:1a:94:11 tipu ether IPv4 (0x0800), lunghezza 62: (tos 0x0, ttl 63, id 53652, offset 1480, bandiere [nisuna], proto IPIP (4), lunghezza 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Quessi sò dui frammenti di un pacchettu (stessu ID 53652) cù una fotografia (a parolla Exif hè visibile in u primu pacchettu). A causa di u fattu chì ci sò pacchetti à questu livellu, ma micca in a forma fusionata in i dumps, u prublema hè chjaramente cù l'assemblea. Finalmente ci hè una prova documentaria di questu!
U decodificatore di pacchetti ùn hà revelatu nisun prublema chì impediscenu a custruzzione. Pruvate quì: . À u primu, quandu pruvate à stuff qualcosa quì, u decoder ùn piace micca u formatu di pacchettu. Risultava chì ci era qualchi dui ottetti extra trà Srcmac è Ethertype (micca ligati à l'infurmazioni di frammentu). Dopu avè sguassatu, u decoder hà cuminciatu à travaglià. Tuttavia, ùn hà dimustratu micca prublemi.
Qualunque cosa si pò dì, nunda di più hè statu trovu fora di quelli Sysctl. Tuttu ciò chì restava era di truvà un modu per identificà i servitori di prublema per capiscenu a scala è decide nantu à più azzioni. U cuntatore necessariu hè statu trovu abbastanza rapidamente:
netstat -s | grep "packet reassembles failed”
Hè ancu in snmpd sottu OID = 1.3.6.1.2.1.4.31.1.1.16.1 ().
"U numeru di fallimenti rilevati da l'algoritmu di re-assemblea IP (per qualsiasi mutivu: timed out, errori, etc.)."
Trà u gruppu di servitori nantu à quale u prublema hè statu studiatu, nantu à dui stu cuntatore hà aumentatu più veloce, nantu à dui più lentamente, è in dui più ùn hà micca crescita in tuttu. Paragunendu a dinamica di stu contatore cù a dinamica di l'errori HTTP in u servitore Java hà revelatu una correlazione. Questu hè, u metru puderia esse monitoratu.
Avè un indicatore affidabile di prublemi hè assai impurtante per pudè determinà accuratamente se rolling back Sysctl aiuta, postu chì da a storia precedente sapemu chì questu ùn pò micca esse capitu immediatamente da l'applicazione. Questu indicatore ci permetterà di identificà tutte e zone problematiche in a produzzione prima chì l'utilizatori scopranu.
Dopu à ritruvà Sysctl, l'errori di monitoraghju si fermanu, cusì a causa di i prublemi hè stata pruvata, è ancu u fattu chì u rollback aiuta.
Avemu ritruvatu i paràmetri di frammentazione in altri servitori, induve un novu monitoraghju hè ghjuntu in ghjocu, è in qualchì locu avemu attribuitu ancu più memoria per i frammenti di quellu chì era prima predeterminatu (questu era statistiche UDP, a perdita parziale di quale ùn era micca notu in u sfondate generale) .
E dumande più impurtanti
Perchè i pacchetti sò frammentati in u nostru balancer L3? A maiò parte di i pacchetti chì arrivanu da l'utilizatori à i balancers sò SYN è ACK. E dimensioni di questi pacchetti sò chjuchi. Ma postu chì a parte di tali pacchetti hè assai grande, in u so sfondate ùn avemu micca nutatu a presenza di pacchetti grossi chì cuminciaru à frammentà.
U mutivu era un script di cunfigurazione rottu nantu à i servitori cù interfacce Vlan (ci era assai pochi servitori cù u trafficu tagged in produzzione à quellu tempu). Advmss ci permette di trasmette à u cliente l'infurmazioni chì i pacchetti in a nostra direzzione duveranu esse più chjuchi in grandezza per chì dopu avè attaccatu l'intestazione di u tunnel ùn anu micca esse frammentatu.
Perchè Sysctl rollback ùn hà micca aiutu, ma u reboot hà fattu? Rolling back Sysctl hà cambiatu a quantità di memoria dispunibule per unisce i pacchetti. À u listessu tempu, apparentemente u fattu stessu di a memoria overflow per i frammenti hà purtatu à a rallentazione di e cunnessione, chì hà purtatu à i frammenti ritardati per un bellu pezzu in a fila. Questu hè, u prucessu hè andatu in cicli.
U reboot hà sbulicatu a memoria è tuttu torna à l'ordine.
Era pussibule di fà senza Workaround? Iè, ma ci hè un altu risicu di lascià l'utilizatori senza serviziu in casu d'attaccu. Di sicuru, l'usu di Workaround hà risultatu in diversi prublemi, cumpresu a rallentazione di unu di i servizii per l'utilizatori, ma quantunque credemu chì l'azzioni eranu ghjustificate.
Grazie mille à Andrey Timofeev () per l'assistenza in a realizazione di l'inchiesta, è ancu Alexey Krenev () - per u travagliu titanicu di aghjurnamentu Centos è i core di u servitore. In questu casu, u prucessu hà avutu à esse riavviatu parechje volte, ciò chì hà purtatu à parechji mesi.
Source: www.habr.com
