

Ehi Habr!
Vi ricurdemu chì seguitu u libru circa avemu publicatu un travagliu ugualmente interessante nantu à a biblioteca .

Per avà, a cumunità hè solu à amparà i limiti di stu putente strumentu. Dunque, un articulu hè statu publicatu pocu tempu, a traduzzione di quale vulemu presentà. Da a so propria sperienza, l'autore dice cumu trasfurmà Kafka Streams in un almacenamentu di dati distribuitu. Prufittate a lettura!
biblioteca Apache utilizatu in u mondu sanu in l'imprese per l'elaborazione di flussu distribuitu nantu à Apache Kafka. Unu di l'aspetti sottovalutati di stu quadru hè chì vi permette di almacenà u statu lucale pruduttu basatu nantu à u processu di filu.
In questu articulu, vi dicu cumu a nostra sucietà hà sappiutu aduprà sta opportunità in u sviluppu di un pruduttu per a sicurità di l'applicazioni in nuvola. Utilizendu Kafka Streams, avemu criatu microservizi statali spartuti, ognunu di quali serve cum'è una fonte d'infurmazione affidabile è altamente tolerante à i difetti nantu à u statu di l'uggetti in u sistema. Per noi, questu hè un passu avanti sia in termini di affidabilità è di facilità di supportu.
Sè site interessatu in un approcciu alternativu chì vi permette di utilizà una sola basa di dati cintrali per sustene u statu formale di i vostri oggetti, leghjite, serà interessante ...
Perchè avemu pensatu chì era ora di cambià a manera di travaglià cù u statu spartutu
Avemu bisognu di mantene u statu di diversi ogetti basati nantu à i rapporti di l'agenti (per esempiu: u situ era attaccatu)? Prima di migrà à Kafka Streams, avemu spessu basatu nantu à una sola basa di dati cintrali (+ API di serviziu) per a gestione statale. Stu approcciu hà i so inconvenienti: mantene a coherenza è a sincronizazione diventa una vera sfida. A basa di dati pò diventà un collu di bottiglia o finisce in è soffre di imprevisibilità.
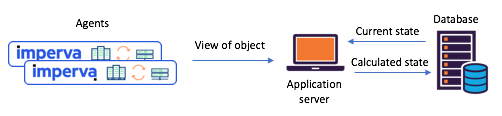
Figura 1: Un scenariu tipicu di split-state vistu prima di a transizione à
Kafka è Kafka Streams: l'agenti cumunicanu i so punti di vista via API, u statu aghjurnatu hè calculatu attraversu una basa di dati cintrali
Incuntrà Kafka Streams, facendu faciule fà creà microservizi statali spartuti
Circa un annu fà, avemu decisu di piglià un ochju duru à i nostri scenarii statali cumuni per affruntà questi prublemi. Avemu subitu decisu di pruvà Kafka Streams - sapemu quantu hè scalabile, assai dispunibile è tollerante à i difetti, quale ricchezza di funzionalità di streaming hà (trasformazioni, cumpresi stateful). Solu ciò chì avemu bisognu, per ùn dì micca quantu maturu è affidabile u sistema di messageria hè diventatu in Kafka.
Ognunu di i microservices stateful chì avemu creatu hè statu custruitu nantu à una istanza di Kafka Streams cù una topologia abbastanza simplice. Hè custituitu da 1) una fonte 2) un processore cù un magazinu di chjave-valore persistente 3) un lavabo:
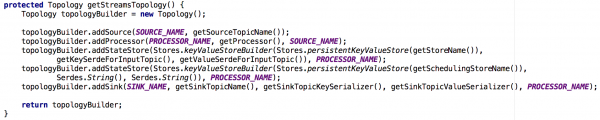
Figura 2: A topologia predeterminata di e nostre istanze di streaming per i microservizi stateful. Nota chì ci hè ancu un repository quì chì cuntene metadata di pianificazione.
In questu novu approcciu, l'agenti cumponenu messagi chì sò alimentati in u tema di fonte, è i cunsumatori - per dì, un serviziu di notificazione di mail - ricevenu u statu cumunu calculatu attraversu u lavamanu (tema di output).
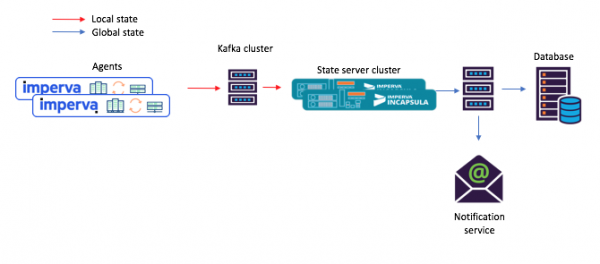
Figura 3: Un novu esempiu di flussu di travagliu per un scenariu cù microservizi cumuni: 1) l'agente genera un missaghju chì ghjunghje à u tema fonte Kafka; 2) un microserviziu cù u statu spartutu (using Kafka Streams) u processa è scrive u statu calculatu à u tema finale Kafka; dopu chì 3) i cunsumatori accettanu u novu statu
Ehi, sta tenda di chjave-valore integrata hè veramente assai utile!
Cum'è l'esitatu sopra, a nostra topologia di u statu spartutu cuntene un magazinu di chjave-valore. Avemu trovu parechje scelte per usà, è dui di elli sò descritti quì sottu.
Opzione #1: Aduprate un magazinu di chjave-valore per i calculi
U nostru primu magazzinu chjave-valore cuntene i dati ausiliarii chì avemu bisognu per i calculi. Per esempiu, in certi casi, u statu spartutu hè statu determinatu da u principiu di "voti a majuranza". U repositoriu puderia cuntene tutti l'ultimi rapporti di l'agenti nantu à u statutu di qualchì ughjettu. Allora, quandu avemu ricivutu un novu rapportu da un agentu o un altru, pudemu salvà, ricuperà rapporti da tutti l'altri agenti nantu à u statu di u stessu ughjettu da u almacenamiento, è ripetite u calculu.
A figura 4 sottu mostra cumu avemu espunutu u magazzinu chjave / valore à u metudu di trasfurmazioni di u processatore per chì u novu missaghju puderia esse processatu.
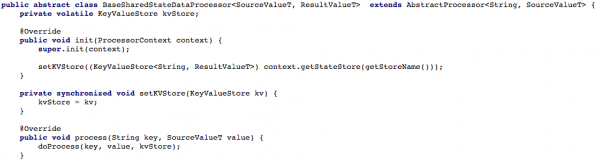
Illustrazione 4: Apertura l'accessu à u magazzinu di chjave-valore per u metudu di trasfurmazioni di u processatore (dopu à questu, ogni script chì travaglia cù u statu spartutu deve implementà u metudu). doProcess)
Opzione #2: Crea una API CRUD sopra Kafka Streams
Dopu avè stabilitu u nostru flussu di travagliu di basa, avemu cuminciatu à pruvà à scrive un RESTful CRUD API per i nostri microservizi statali spartuti. Vulemu esse capace di ricuperà u statu di alcuni o tutti l'uggetti, è ancu stabilisce o sguassate u statu di un ughjettu (utile per u supportu backend).
Per sustene tutte l'API Get State, ogni volta chì avemu bisognu di ricalculate u statu durante u processu, l'avemu guardatu in un magazinu di valore chjave integratu per un bellu pezzu. In questu casu, diventa abbastanza simplice per implementà una tale API utilizendu una sola istanza di Kafka Streams, cum'è mostra in a lista sottu:
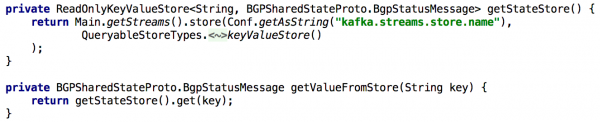
Figura 5: Utilizà a tenda di chjave-valore integrata per ottene u statu precalculatu di un ughjettu
L'aghjurnamentu di u statu di un ughjettu via l'API hè ancu faciule da implementà. Bastamente, tuttu ciò chì deve fà hè di creà un pruduttore Kafka è l'utilizanu per fà un registru chì cuntene u novu statu. Questu assicura chì tutti i missaghji generati attraversu l'API seranu processati in u listessu modu chì quelli ricevuti da altri pruduttori (per esempiu, agenti).

Figura 6: Pudete stabilisce u statu di un ughjettu cù u produtore Kafka
Piccola complicazione: Kafka hà parechje partizioni
In seguitu, avemu vulsutu distribuisce a carica di trasfurmazioni è migliurà a dispunibilità fornendu un cluster di microservizi di u statu spartutu per scenariu. A stallazione hè stata una brisa: una volta chì avemu cunfiguratu tutte e istanze per eseguisce sottu u listessu ID di l'applicazione (è i stessi servitori di bootstrap), quasi tuttu u restu hè statu fattu automaticamente. Avemu ancu specificatu chì ogni tema di fonte hè custituitu da parechje partizioni, cusì chì ogni istanza puderia esse assignatu un subset di tali partizioni.
Aghju dettu ancu chì hè una pratica cumuna per fà una copia di salvezza di u magazinu statale in modu chì, per esempiu, in casu di ricuperazione dopu un fallimentu, trasfiriu sta copia à un altru esempiu. Per ogni magazzini statali in Kafka Streams, un tema replicatu hè creatu cù un logu di cambiamentu (chì traccia l'aghjurnamenti lucali). Cusì, Kafka sustene constantemente a tenda statale. Dunque, in casu di fallimentu di una o una altra istanza di Kafka Streams, u magazinu statale pò esse restauratu rapidamente in un altru esempiu, induve andaranu e partizioni currispundenti. I nostri testi anu dimustratu chì questu hè fattu in una materia di sicondi, ancu s'ellu ci sò milioni di dischi in a tenda.
Passendu da un unicu microserviziu cù un statu spartutu à un cluster di microservizi, diventa menu triviale per implementà l'API Get State. In a nova situazione, u magazinu statale di ogni microserviziu cuntene solu una parte di l'imaghjini generale (quelli ogetti chì i chjavi sò stati mappati à una partizione specifica). Avemu avutu a determinà quale istanza cuntene u statu di l'ughjettu chì avemu bisognu, è avemu fattu questu basatu annantu à i metadati di filu, cum'è mostratu quì sottu:
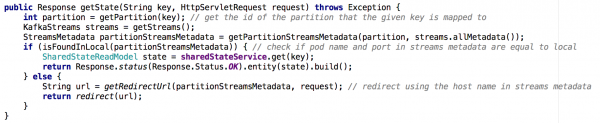
Figura 7: Utilizendu i metadati di u flussu, determinamu da quale istanza per dumandà u statu di l'ughjettu desideratu; un approcciu simili hè statu utilizatu cù l'API GET ALL
Risultati chjave
I magazzini statali in Kafka Streams ponu serve cum'è una basa di dati distribuita de facto,
- constantemente replicatu in Kafka
- Un CRUD API pò esse facilmente custruitu nantu à un tali sistema
- A gestione di parechje partizioni hè un pocu più complicata
- Hè ancu pussibule aghjunghje unu o più magazzini statali à a topologia di streaming per almacenà dati ausiliari. Questa opzione pò esse usata per:
- U almacenamentu à longu andà di e dati necessarii per i calculi durante u processu di flussu
- L'almacenamiento à longu andà di dati chì ponu esse utili a prossima volta chì l'istanza di streaming hè furnita
- assai di più...
Questi è altri vantaghji facenu Kafka Streams bè adattatu per mantene u statu globale in un sistema distribuitu cum'è u nostru. Kafka Streams hà dimustratu chì hè assai affidabile in a produzzione (avemu praticamente nisuna perdita di missaghju dapoi u so implementazione), è simu cunfidenti chì e so capacità ùn si fermanu micca quì!
Source: www.habr.com
