

Prucessu di aghjurnamentu per u vostru cluster Kubernetes
À un certu puntu, quandu si usa un cluster Kubernetes, ci hè bisognu di aghjurnà i nodi in esecuzione. Questu pò include l'aghjurnamenti di u pacchettu, l'aghjurnamenti di u kernel, o l'implementazione di novi imagine di macchina virtuale. In a terminologia di Kubernetes questu hè chjamatu .
Questu post face parte di una serie di 4 posti:
- Stu postu.
- Arregu currettu di pods in un cluster Kubernetes
- A terminazione ritardata di un pod quandu hè sguassatu
- Cumu evità i tempi di inattività di Kubernetes Cluster Utilizendu PodDisruptionBudgets
(circa Aspettate traduzioni di l'articuli rimanenti in a serie in un futuru vicinu)
In questu articulu, descriveremu tutte l'arnesi chì Kubernetes furnisce per ottene zero downtime per i nodi in esecuzione in u vostru cluster.
Definizione di u prublema
Avemu da piglià un accostu ingenu in prima, identificà i prublemi è valutà i risichi putenziali di stu approcciu, è custruiscenu cunniscenze per risolve ogni prublema chì scontru in tuttu u ciculu. U risultatu hè una cunfigurazione chì usa i ganci di u ciclu di vita, sonde di prontezza è i bilanci di disrupzione di Pod per ottene u nostru tempu di fermu zero.
Per principià u nostru viaghju, pigliemu un esempiu cuncrettu. Diciamu chì avemu un cluster Kubernetes di dui nodi, in quale una applicazione funziona cù dui pods situati daretu. Service:
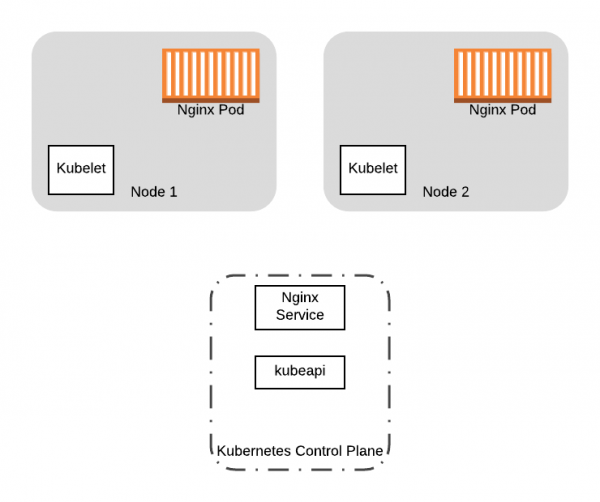
Cuminciamu cù dui pods cù Nginx è Service in esecuzione nantu à i nostri dui nodi di cluster Kubernetes.
Vulemu aghjurnà a versione di u kernel di dui nodi di u travagliu in u nostru cluster. Cumu facemu questu? Una suluzione simplice seria di avvià novi nodi cù a cunfigurazione aghjurnata è dopu chjude i vechji nodi mentre cumincianu i novi. Mentre chì questu funziona, ci saranu uni pochi di prublemi cù questu approcciu:
- Quandu si disattiveghjanu i vechji nodi, i baccelli chì correnu nantu à elli seranu ancu disattivati. E se i baccelli anu da esse sbulicati per un chjusu graziosu? U sistema di virtualizazione chì site aduprate ùn pò micca aspittà chì u prucessu di pulizia finisci.
- E se spegnete tutti i nodi à u stessu tempu? Averete un downtime decentu mentre i baccelli si movenu in novi nodi.
Avemu bisognu di un modu per migrà graziamente pods da i vechji nodi, assicurendu chì nimu di i nostri prucessi di u travagliu sò in esecuzione mentre facemu cambiamenti à u node. O quandu facemu una sustituzione cumpleta di u cluster, cum'è in l'esempiu (vale à dì, rimpiazzà l'imaghjini VM), vulemu trasfiriri l'applicazioni in esecuzione da i vechji nodi à novi. In i dui casi, vulemu impedisce chì i novi pods sò pianificati nantu à i vechji nodi, è poi scacciate tutti i pods in esecuzione da elli. Per ottene questi scopi, pudemu usà u cumandamentu kubectl drain.
Ridistribuzione di tutti i pods da un node
L'operazione di drenu permette di redistribuisce tutti i podi da un node. Durante l'esecuzione di drain, u node hè marcatu cum'è unschedulable (bandiera NoSchedule). Questu impedisce chì novi baccelli apparsu nantu à questu. Allora u drenu principia à scacciate pods da u node, chjude i cuntenituri chì sò attualmente in esecuzione nantu à u node, mandendu un signalu. TERM contenitori in un pod.
Ancu sì kubectl drain farà un grande travagliu di evicting pods, ci sò dui altri fattori chì ponu causà l'operazione di drenaje per fallu:
- A vostra applicazione deve esse capace di finisce grazia à a sottumissione
TERMsignale. Quandu i podi sò scacciati, Kubernetes manda un signaluTERMcuntenituri è aspetta ch'elli si fermanu per una quantità specifica di tempu, dopu à quale, s'ellu ùn anu micca firmatu, li finisce in forza. In ogni casu, se u vostru cuntinuu ùn percepisce micca u signale currettamente, pudete sempre extinguish pods incorrectly si sò attualmente in esecuzione (per esempiu, una transazzione di basa di dati hè in corso). - Perdi tutti i pods chì cuntenenu a vostra applicazione. Pò esse micca dispunibile quandu i novi cuntenituri sò lanciati nantu à novi nodi, o se i vostri pods sò disposti senza cuntrolli, ùn ponu micca riavvia in tuttu.
Evitendu i tempi di inattività
Per minimizzà i tempi di inattività da l'interruzzione voluntaria, cum'è da una operazione di drenu in un node, Kubernetes furnisce e seguenti opzioni di gestione di fallimentu:
In u restu di a serie, useremu queste caratteristiche Kubernetes per mitigà l'impattu di a migrazione di pod. Per fà più faciule per seguità l'idea principale, useremu u nostru esempiu sopra cù a seguente cunfigurazione di risorse:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
targetPort: 80
port: 80Sta cunfigurazione hè un esempiu minimu Deployment, chì gestisce nginx pods in u cluster. Inoltre, a cunfigurazione descrive a risorsa Service, chì pò esse usatu per accede à pods nginx in un cluster.
In tuttu u ciculu, espansione iterativamente sta cunfigurazione in modu chì eventualmente include tutte e capacità chì Kubernetes furnisce per riduce i tempi di inattività.
Per una versione cumpletamente implementata è testata di l'aghjurnamenti di cluster Kubernetes per zero downtime in AWS è oltre, visitate .
Leghjite ancu altri articuli nantu à u nostru blog:
Source: www.habr.com
