

Parechji mesi fà - publicu à PostgreSQL.
L'avete digià utilizatu più di 6000 XNUMX volte, ma una funzione utile chì pò esse passata inosservata hè indizi strutturali, chì parenu qualcosa cusì:
Ascoltateli, è e vostre richieste "diventaranu lisci è setosi". 🙂
Ma in seriu, parechje situazioni chì facenu una dumanda lenta è affamata di risorse sò tipici è ponu esse ricunnisciuti da a struttura è dati di u pianu.
In questu casu, ogni sviluppatore individuale ùn hà micca bisognu di circà una opzione d'ottimisazione per sè stessu, affittendu solu à a so sperienza - pudemu dì ciò chì succede quì, quale puderia esse u mutivu, è cumu avvicinà una suluzione. Hè ciò chì avemu fattu.

Fighjemu un ochju più vicinu à questi casi - cumu si sò definiti è à quali cunsiglii portanu.
Per megliu immerse in u tema, pudete prima sente à u bloccu currispundenti da , è solu dopu passà à un analisi detallatu di ogni esempiu:

#1: indice "undersorting"
Quandu nasce
Mostra l'ultima fattura per u cliente "LLC Kolokolchik".
Cumu identificà
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
ci voli
Indice utilizatu espansione cù campi di sorte.
Esempiu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
fk_cli = 1 -- отбор по конкретной связи
ORDER BY
pk DESC -- хотим всего одну "последнюю" запись
LIMIT 1; 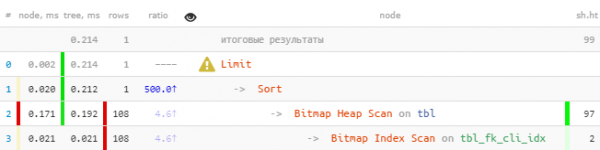
Puderete immediatamente avvistà chì più di 100 records sò stati sottratti da l'indici, chì sò stati allora tutti ordinati, è dopu l'unicu hè statu lasciatu.
Currezzione:
DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC); -- добавили ключ сортировки

Ancu nantu à una mostra cusì primitiva - 8.5 volte più veloce è 33 volte menu leghje. U più "fatti" avete per ogni valore, u più ovvi l'effettu fk.
Aghju nutatu chì un tali indexu hà da travaglià cum'è un indexu "prefissu" micca peghju chè prima per altre dumande cù fk, induve sorte pk ùn ci era micca è ùn ci hè (pudete leghje più nantu à questu ). Cumpresu, furnisce u normale supportu esplicitu di chjave straniera nantu à stu campu.
# 2: intersezzione d'indici (BitmapAnd)
Quandu nasce
Mostra tutti l'accordi per u cliente "LLC Kolokolchik", cunclusu in nome di "NAO Buttercup".
Cumu identificà
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scanci voli
creà indice composite per campi da i dui originali o espansione unu di quelli esistenti cù campi da u sicondu.
Esempiu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org); -- индекс для foreign key
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999); -- отбор по конкретной паре 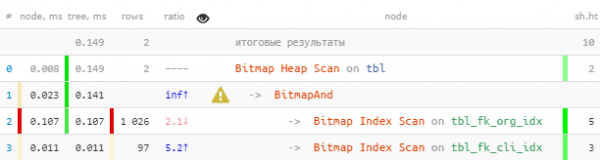
Currezzione:
DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);

U pagamentu quì hè più chjucu, postu chì Bitmap Heap Scan hè abbastanza efficace per sè stessu. Ma in ogni modu 7 volte più veloce è 2.5 volte menu leghje.
#3: Unisci indici (BitmapOr)
Quandu nasce
Mostra i primi 20 più antichi "noi" o richieste micca assignate per u trattamentu, cù u vostru in priorità.
Cumu identificà
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scanci voli
Aduprate UNIONE [TUTTI] per cumminà subqueries per ognunu di i blocchi OR di cundizioni.
Esempiu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL -- с вероятностью 1:16 запись "ничья"
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own;
CREATE INDEX ON tbl(fk_own, pk); -- индекс с "вроде как подходящей" сортировкой
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR -- свои
fk_own IS NULL -- ... или "ничьи"
ORDER BY
pk
, (fk_own = 1) DESC -- сначала "свои"
LIMIT 20;
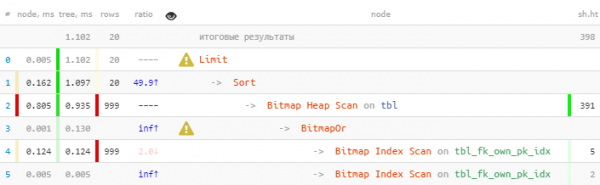
Currezzione:
(
SELECT
*
FROM
tbl
WHERE
fk_own = 1 -- сначала "свои" 20
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL -- потом "ничьи" 20
ORDER BY
pk
LIMIT 20
)
LIMIT 20; -- но всего - 20, больше и не надо 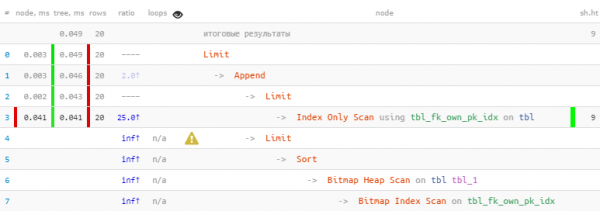
Avemu apprufittatu di u fattu chì tutti i 20 registri richiesti sò stati immediatamente ricevuti in u primu bloccu, cusì u sicondu, cù u più "caru" Bitmap Heap Scan, ùn hè statu ancu eseguitu - à a fine. 22 volte più veloce, 44 volte menu letture!
Una storia più dettagliata nantu à stu metudu di ottimisazione usendu esempi specifichi pò esse leghje in articuli и .
Versione generalizata selezzione urdinata basatu nantu à parechje chjave (è micca solu u paru const / NULL) hè discutitu in l'articulu .
# 4: Leghjemu assai cose inutili
Quandu nasce
In regula, si sviluppa quandu vulete "attache un altru filtru" à una dumanda digià esistente.
"È ùn avete micca u listessu, ma cù i buttoni di madreperla? film "U bracciu di diamante"
Per esempiu, mudificà u compitu sopra, mostra i primi 20 più antichi dumande "critiche" per u processu, indipendentemente da u so scopu.
Cumu identificà
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- отфильтровано >80% прочитанного
&& loops × RRbF > 100 -- и при этом больше 100 записей суммарно
ci voli
Crea [più] specializatu indice cù cundizione WHERE o include campi supplementari in l'indici.
Se a cundizione di filtru hè "statica" per i vostri scopi - questu hè ùn implica micca espansione lista di valori in u futuru - hè megliu aduprà un indice WHERE. Diversi stati booleani/enum si adattanu bè in questa categuria.
Sì a cundizione di filtrazione pò piglià diversi significati, Allora hè megliu espansione l'indici cù questi campi - cum'è in a situazione cù BitmapAnd sopra.
Esempiu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own
, (random() < 1::real/50) critical; -- 1:50, что заявка "критичная"
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20; 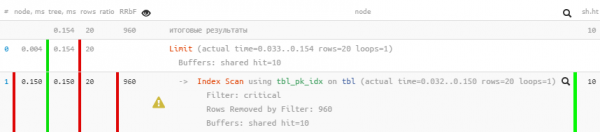
Currezzione:
CREATE INDEX ON tbl(pk)
WHERE critical; -- добавили "статичное" условие фильтрации

Comu pudete vede, u filtru hè sparitu cumplettamente da u pianu, è a dumanda hè diventata 5 volte più veloce.
# 5: tavula sparsa
Quandu nasce
Diversi tentativi di creà a vostra propria fila di processazione di u travagliu, quandu un gran numaru d'aghjurnamenti / eliminazioni di registri nantu à a tavula portanu à una situazione di un gran numaru di registri "morti".
Cumu identificà
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
ci voli
Eseguite manualmente regularmente VACUUM [PIENU] o ottene una furmazione abbastanza frequente per fine-tuning i so paràmetri, cumpresi .
In a maiò parte di i casi, tali prublemi sò causati da una povera cumpusizioni di quistione quandu chjamanu da a logica cummerciale cum'è quelli discututi in .
Ma avete bisognu di capisce chì ancu VACUUM FULL ùn pò micca sempre aiutà. Per tali casi, vale a pena familiarizàvi cù l'algoritmu di l'articulu .
# 6: Lettura da u "mezzu" di l'indici
Quandu nasce
Sembra chì avemu lettu un pocu, è tuttu era indexatu, è ùn avemu micca filtratu nimu in eccessu - ma ancu leghjemu significativamente più pagine di ciò chì vuleriamu.
Cumu identificà
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
ci voli
Fighjate attente à a struttura di l'indici utilizatu è i campi chjave specificati in a dumanda - più prubabile parte di l'indici ùn hè micca specificatu. Probabilmente avete da creà un indice simili, ma senza i campi di prefissu o .
Esempiu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org, fk_cli); -- все почти как в #2
-- только вот отдельный индекс по fk_cli мы уже посчитали лишним и удалили
SELECT
*
FROM
tbl
WHERE
fk_cli = 999 -- а fk_org не задано, хотя стоит в индексе раньше
LIMIT 20; 
Tuttu pare esse bè, ancu sicondu l'indici, ma hè in qualchì modu suspettu - per ognunu di i 20 records lettu, avemu avutu a sottrae 4 pagine di dati, 32KB per record - ùn hè micca cusì grassu? È u nome indice tbl_fk_org_fk_cli_idx induce à pensà.
Currezzione:
CREATE INDEX ON tbl(fk_cli); 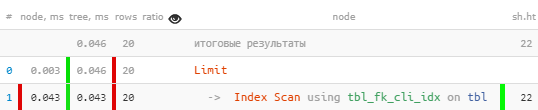
di colpu - 10 volte più veloce, è 4 volte menu à leghje!
Altri esempi di situazioni di usu inefficace di l'indici ponu esse vistu in l'articulu .
#7: CTE × CTE
Quandu nasce
In dumanda hà puntuatu CTE "grassu". da diverse tavule, è dopu decisu di fà trà elli JOIN.
U casu hè pertinente per versioni sottu v12 o richieste cù WITH MATERIALIZED.
Cumu identificà
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- слишком большое декартово произведение CTE
ci voli
Analizà currettamente a dumanda - è ? Sì sì, allora applicà "dizziunariu" in hstore/json secondu u mudellu descrittu in .
# 8: scambià à u discu (tempu scrittu)
Quandu nasce
U processamentu unicu (selezzione o unicità) di un gran numaru di registri ùn si mette micca in a memoria attribuita per questu.
Cumu identificà
-> *
&& temp written > 0ci voli
Se a quantità di memoria utilizata da l'operazione ùn supera assai u valore specificatu di u paràmetru , vale a pena di currezzione. Pudete subitu in a cunfigurazione per tutti, o pudete attraversu SET [LOCAL] per una dumanda / transazzione specifica.
Esempiu:
SHOW work_mem;
-- "16MB"
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1; 
Currezzione:
SET work_mem = '128MB'; -- перед выполнением запроса 
Per ragioni evidenti, se solu a memoria hè aduprata è micca u discu, allora a quistione serà eseguita assai più veloce. À u listessu tempu, parte di a carica da u HDD hè ancu eliminata.
Ma avete bisognu di capisce chì ùn sarete micca sempre capaci di attribuisce assai è assai memoria - ùn serà micca abbastanza per tutti.
# 9: statistiche irrilevanti
Quandu nasce
Anu versatu assai in a basa di dati à una volta, ma ùn avianu micca tempu di caccià ANALYZE.
Cumu identificà
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10ci voli
Fatela ANALYZE.
Sta situazione hè descritta in più detail in .
# 10: "Qualcosa hè andatu male"
Quandu nasce
Ci hè stata una aspittà per una serratura imposta da una dumanda cuncurrente, o ùn ci era micca abbastanza risorse hardware CPU / ipervisore.
Cumu identificà
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- читали мало, но слишком долго
ci voli
Aduprà esterni sistema di monitoraghju servitore per bluccà o cunsumu di risorse anormali. Avemu digià parlatu di a nostra versione di urganizà stu prucessu per centinaie di servitori и .
Source: www.habr.com
