

Periòdicamente, u compitu di ricerca di dati cunnessi da un inseme di chjave nasce, finu à ottene u numeru tutale necessariu di records.
L'esempiu più "realisticu" hè di vede 20 prublemi più antichi, listatu nantu à a lista di l'impiegati (per esempiu, in u stessu dipartimentu). Per parechji "dashboards" manageriali cù brevi riassunti di e zone di travagliu, un tema simili hè necessariu abbastanza spessu.

In l'articulu, cunsideremu l'implementazione nantu à PostgreSQL di una versione "ingenu" di risolve un tali prublema, un algoritmu "più intelligente" è assai cumplessu. "loop" in SQL cù una cundizione di uscita da i dati truvati, chì pò esse utile per u sviluppu generale è per l'usu in altri casi simili.
Pigliemu un set di dati di prova da . Cusì chì i registri di output ùn "saltanu" di tantu in tantu quandu i valori ordinati currispondenu, allargà l'indici di u sughjettu aghjunghjendu una chjave primaria. À u listessu tempu, questu darà immediatamente unicità, è ci guarantisci l'unicità di l'ordine di sorte:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;Cumu si sente, cusì hè scrittu
Prima, abbozzemu a versione più simplice di a dumanda, passendu l'ID di l'esecutori :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
Un pocu tristu - avemu urdinatu solu 20 dischi, è Index Scan ci hà tornatu 960 linee, chì tandu ci vole ancu esse urdinatu... È pruvemu à leghje menu.
unnest + ARRAY
A prima cunsiderazione chì ci aiuterà - se avemu bisognu in totale 20 ordinati records, basta à leghje micca più di 20 ordinati in u listessu ordine per ognunu chjave. Bene, indice adattatu (owner_id, task_date, id) avemu.
Utilizemu u listessu mecanismu di estrazione è "turnà in culonne" entrata integrale di a tavola, cum'è in . È ancu applicà a cunvoluzione à un array usendu a funzione ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 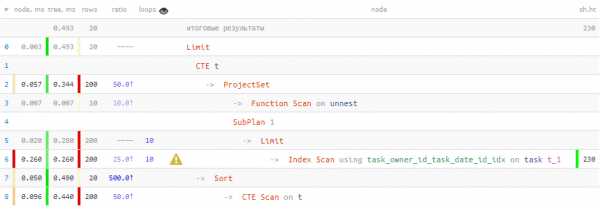
Oh, hè digià assai megliu ! 40% più veloce è 4.5 volte menu dati avia da leghje.
Materializazione di i registri di a tavula via CTEAghju nutatu chì in certi casi un tentativu di travaglià immediatamente cù i campi di registrazione dopu a ricerca in una subquery, senza "wrapping" in un CTE, pò purtà à "multiplicazione" InitPlan proporzionale à u numeru di sti stessi campi:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
U stessu registru hè statu "cercatu" 4 volte ... Finu à PostgreSQL 11, stu cumpurtamentu si faci regularmente, è a suluzione hè di "imballà" in un CTE, chì hè un cunfini incondizionatu per l'ottimisatore in queste versioni.
accumulateur recursive
In a versione precedente, in totale, leghjemu 200 linee per u bisognu di 20. Dighjà micca 960, ma ancu menu - hè pussibule?
Pruvemu di utilizà a cunniscenza chì avemu bisognu in totale 20 records. Questu hè, iteraremu a sottrazione di dati solu finu à chì a quantità chì avemu bisognu hè ghjunta.
Passu 1: Start List
Ovviamente, a nostra lista "destinazione" di 20 entrate deve principià cù e "prime" entrate per una di e nostre chjave owner_id. Dunque, truvamu prima tali "assai prima" per ognuna di e chjave è mette in a lista, sortendu in l'ordine chì vulemu - (task_date, id).
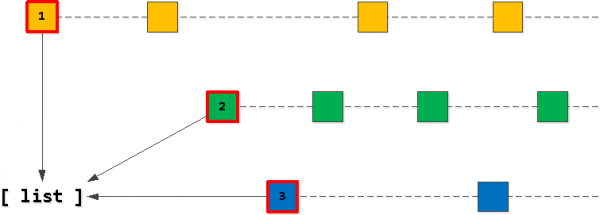
Passu 2: truvà i dischi "prossime".
Avà si pigliamu a prima entrata da a nostra lista è cuminciamu "passu" più in basso l'indice cù a salvezza di u owner_id-key, allora tutti i registri truvati sò solu i prossimi in a selezzione resultanti. Di sicuru, solu finu à noi attraversà a chjave applicata seconda entrata in a lista.
S'ellu hè risultatu chì avemu "attraversatu" a seconda entrata, allora l'ultima entrata di lettura deve esse aghjuntu à a lista invece di a prima (cù u stessu owner_id), dopu chì a lista hè ordinata di novu.
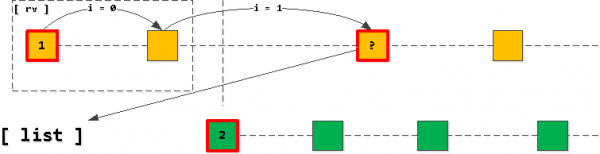
Vale à dì, avemu sempre chì a lista ùn hà micca più di una entrata per ognuna di e chjave (se l'entrate sò finite, è ùn avemu micca "attraversatu", allora a prima entrata simpricamente sparirà da a lista è nunda serà aghjuntu. ), è elli sempre ordinati in ordine crescente di a chjave di l'applicazione (task_date, id).
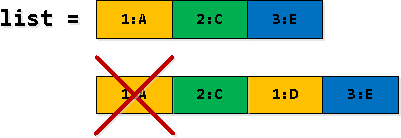
Step 3: Filtering and Expanding Records
In a parte di e fila di a nostra selezzione recursiva, certi registri rv sò duplicati - prima truvemu cum'è "attraversà u cunfini di a 2ª entrata di a lista", è dopu avemu sustituitu cum'è u 1u da a lista. È cusì a prima occorrenza deve esse filtrata.
Terribile dumanda finale
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 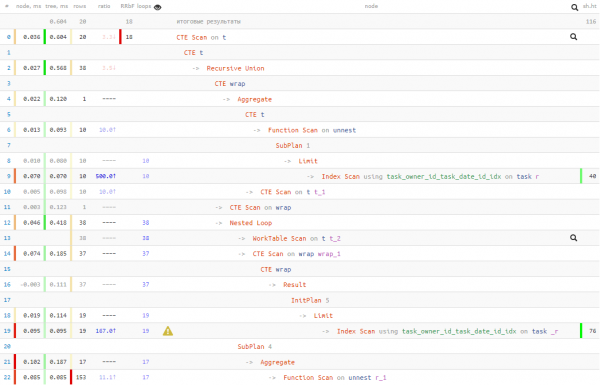
Cusì, noi scambiatu 50% di leghje di dati per 20% di tempu di esecuzione. Questu hè, s'è vo avete ragiò per crede chì a lettura pò esse longu (per esempiu, i dati ùn sò spessu micca in u cache, è avete da andà à u discu per questu), allora in questu modu pudete dipende di leghje menu.
In ogni casu, u tempu d'esekzione hè stata megliu cà in a prima opzione "ingenu". Ma quale di sti 3 opzioni à aduprà hè à voi.
Source: www.habr.com
