

L'articulu discute parechje manere di determinà l'equazioni matematiche di una linea di regressione simplice (accoppiata).
Tutti i metudi di risolve l'equazioni discututi quì sò basati nantu à u metudu di i minimi quadrati. Denotemu i metudi cusì:
- Soluzione analitica
- Descente à gradient
- Descente di gradiente stochasticu
Per ogni metudu di risolve l'equazioni di una linea recta, l'articulu furnisce diverse funzioni, chì sò principarmenti divisu in quelli chì sò scritti senza aduprà a biblioteca. numpy è quelli chì utilizanu per i calculi numpy. Hè cridutu chì l'usu skillful numpy riducerà i costi di l'informatica.
Tuttu u codice datu in l'articulu hè scrittu pitone 2.7 aduprendu Notebook Jupyter. U codice fonte è u schedariu cù dati di mostra sò publicati
L'articulu hè più destinatu à i principianti è quelli chì anu digià principiatu gradualmente à ammaistrà u studiu di una sezione assai larga in intelligenza artificiale - machine learning.
Per illustrà u materiale, usemu un esempiu assai simplice.
Cundizioni di esempiu
Avemu cinque valori chì carattirizzanu a dependenza Y от X (Table No. 1):
Table N ° 1 "Condizioni di esempiu"

Assumiremu chì i valori  hè u mese di l'annu, è
hè u mese di l'annu, è  - Ingressu stu mese. In autri paroli, i rivenuti dipende di u mese di l'annu, è
- Ingressu stu mese. In autri paroli, i rivenuti dipende di u mese di l'annu, è  - l'unicu signu da quale dipende l'ingressu.
- l'unicu signu da quale dipende l'ingressu.
L'esempiu hè cusì cusì, sia da u puntu di vista di a dependenza condicionale di i rivenuti nantu à u mese di l'annu, sia da u puntu di vista di u numeru di valori - ci sò assai pochi. Tuttavia, una tale simplificazione permetterà, cum'è dicenu, di spiegà, micca sempre cun facilità, u materiale chì i principianti assimilanu. È ancu a simplicità di i numeri permetterà à quelli chì vulianu risolve l'esempiu nantu à carta senza costu di travagliu significativu.
Assumimu chì a dependenza data in l'esempiu pò esse apprussimata bè da l'equazioni matematiche di una linea di regressione simplice (accoppiata) di a forma:

induve  hè u mese in u quale i rivenuti sò stati ricevuti,
hè u mese in u quale i rivenuti sò stati ricevuti,  - entrate currispondenti à u mese,
- entrate currispondenti à u mese,  и
и  sò i coefficienti di regressione di a linea stimata.
sò i coefficienti di regressione di a linea stimata.
Nota chì u coefficient  spessu chjamatu a pendenza o gradiente di a linea stimata; rapprisenta a quantità da quale u
spessu chjamatu a pendenza o gradiente di a linea stimata; rapprisenta a quantità da quale u  quandu cambia
quandu cambia  .
.
Ovviamente, u nostru compitu in l'esempiu hè di selezziunà tali coefficienti in l'equazioni  и
и  , à quale i deviazioni di i nostri valori di rivenuti calculati per mese da e risposte veri, i.e. i valori presentati in a mostra seranu minimi.
, à quale i deviazioni di i nostri valori di rivenuti calculati per mese da e risposte veri, i.e. i valori presentati in a mostra seranu minimi.
Metudu minimu quadru
Sicondu u metudu di i minimi quadrati, a deviazione deve esse calculata da u quadru. Sta tecnica permette di evità l'annullamentu mutuale di deviazioni s'ellu anu segni opposti. Per esempiu, se in un casu, a deviazione hè +5 (più cinque), è in l'altru -5 (minus cinque), allora a somma di e deviazioni s'annullarà l'una l'altra è ammonta à 0 (zero). Hè pussibule micca di squadrà a deviazione, ma di utilizà a pruprietà di u modulu è poi tutte e deviazioni seranu pusitivi è accumularanu. Ùn avemu micca aspittà nantu à questu puntu in detail, ma simpricimenti indicà chì, per a cunvenzione di i calculi, hè abitudine di quadratu a deviazione.
Eccu ciò chì a formula s'assumiglia cù quale determineremu a minima somma di deviazioni quadrate (errori):

induve  hè una funzione di l'approssimazione di e risposte veri (vale à dì, i rivenuti chì avemu calculatu),
hè una funzione di l'approssimazione di e risposte veri (vale à dì, i rivenuti chì avemu calculatu),
 sò e risposte veri (ingudu furnitu in u campione),
sò e risposte veri (ingudu furnitu in u campione),
 hè l'indice di mostra (numeru di u mese in quale a deviazione hè determinata)
hè l'indice di mostra (numeru di u mese in quale a deviazione hè determinata)
Diferenze a funzione, definisce l'equazioni differenziali parziali, è esse pronti per passà à a suluzione analitica. Ma prima, facemu una breve escursione nantu à ciò chì a differenziazione hè è ricurdate u significatu geomètrico di a derivativa.
Differenciazione
A differenziazione hè l'operazione di truvà a derivativa di una funzione.
A cosa serve u derivatu? A derivativa di una funzione carattirizza u ritmu di cambiamentu di a funzione è ci dice a so direzzione. Se a derivativa in un puntu datu hè pusitiva, allora a funzione aumenta; altrimenti, a funzione diminuisce. E u più grande u valore di a derivativa assuluta, u più altu hè u ritmu di cambiamentu di i valori di a funzione, è ancu più a pendenza di u graficu di a funzione.
Per esempiu, in e cundizioni di un sistema di coordenate cartesiane, u valore di a derivativa in u puntu M(0,0) hè uguali à + 25 significa chì in un puntu datu, quandu u valore hè spustatu  a diritta da una unità cunvinziunali, valore
a diritta da una unità cunvinziunali, valore  aumenta di 25 unità convenzionali. Nantu à u graficu, pare una crescita di i valori abbastanza forte
aumenta di 25 unità convenzionali. Nantu à u graficu, pare una crescita di i valori abbastanza forte  da un puntu datu.
da un puntu datu.
Un altru esempiu. U valore derivativu hè uguali -0,1 significa chì quandu hè spustatu  per una unità cunvinziunali, valore
per una unità cunvinziunali, valore  diminuisce da solu 0,1 unità cunvinziunali. À u listessu tempu, nantu à u graficu di a funzione, pudemu osservà una pendenza à pocu pressu. Tracendu una analogia cù una muntagna, hè cum'è s'ellu si scendeva assai lentamente da una pendita dolce da una muntagna, à u cuntrariu di l'esempiu precedente, induve duvemu cullà cime assai ripidi :)
diminuisce da solu 0,1 unità cunvinziunali. À u listessu tempu, nantu à u graficu di a funzione, pudemu osservà una pendenza à pocu pressu. Tracendu una analogia cù una muntagna, hè cum'è s'ellu si scendeva assai lentamente da una pendita dolce da una muntagna, à u cuntrariu di l'esempiu precedente, induve duvemu cullà cime assai ripidi :)
Cusì, dopu a differenziazione di a funzione  per probabilità
per probabilità  и
и  , avemu definitu equazioni differenziali parziali di 1u ordine. Dopu a determinazione di l'equazioni, riceveremu un sistema di duie equazioni, risolvendu quale pudemu selezziunà tali valori di i coefficienti.
, avemu definitu equazioni differenziali parziali di 1u ordine. Dopu a determinazione di l'equazioni, riceveremu un sistema di duie equazioni, risolvendu quale pudemu selezziunà tali valori di i coefficienti.  и
и  , per quale i valori di i derivati currispundenti in punti dati cambianu da una quantità assai, assai chjuca, è in u casu di una suluzione analitica ùn cambia micca in tuttu. In altre parolle, a funzione d'errore à i coefficienti truvati righjunghji u minimu, postu chì i valori di derivati parziali in questi punti seranu uguali à zero.
, per quale i valori di i derivati currispundenti in punti dati cambianu da una quantità assai, assai chjuca, è in u casu di una suluzione analitica ùn cambia micca in tuttu. In altre parolle, a funzione d'errore à i coefficienti truvati righjunghji u minimu, postu chì i valori di derivati parziali in questi punti seranu uguali à zero.
Dunque, secondu e regule di differenziazione, l'equazione derivata parziale di u 1u ordine rispettu à u coefficient  prendrà a forma:
prendrà a forma:

Equazioni derivate parziali di u 1u ordine rispettu à  prendrà a forma:
prendrà a forma:

In u risultatu, avemu ricevutu un sistema di equazioni chì hà una suluzione analitica abbastanza simplice:
principià {equazione*}
principià {casi}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
fine {casi}
fine {equazione*}
Prima di risolve l'equazioni, preloademu, verificate chì a carica hè curretta, è formate e dati.
Caricà è furmatu di dati
Semu devi esse nutatu chì, per via di u fattu chì per a suluzione analitica, è in seguitu per a discesa di gradiente è stochastic gradient, avemu aduprà u codice in duie variazioni: usendu a biblioteca. numpy è senza usà, allura avemu bisognu di furmatu di dati apprupriati (vede codice).
Carica di dati è codice di trasfurmazioni
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Visualizazione
Avà, dopu avè, prima, caricatu i dati, in segundu, verificatu a correttezza di u caricamentu è infine furmatu i dati, avemu da fà a prima visualizazione. U metudu spessu usatu per questu hè coppie librarii Natu di mare. In u nostru esempiu, per via di i numeri limitati, ùn ci hè nunda di usu di a biblioteca Natu di mare. Avemu aduprà a biblioteca regulare matplotlib è basta à fighjà u scatterplot.
Codice Scatterplot
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Graficu N ° 1 "Dipendenza di i rivenuti annantu à u mese di l'annu"
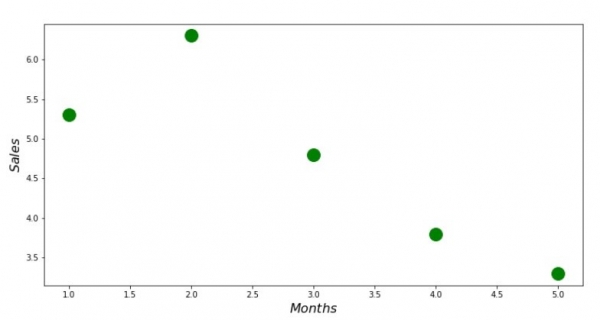
Soluzione analitica
Utilizemu i strumenti più cumuni in pitone è risolve u sistema di equazioni:
principià {equazione*}
principià {casi}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
fine {casi}
fine {equazione*}
Sicondu a regula di Cramer truveremu u determinanti generale, è ancu i determinanti per  è da
è da  , dopu chì, dividendu u determinante da
, dopu chì, dividendu u determinante da  à u determinante generale - truvà u coefficient
à u determinante generale - truvà u coefficient  , simuli truvamu u coefficient
, simuli truvamu u coefficient  .
.
Codice di suluzione analitica
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Eccu ciò chì avemu avutu:

Dunque, i valori di i coefficienti sò stati truvati, a somma di e deviazioni quadrate hè stata stabilita. Fighjemu una linea recta nantu à l'istogramma di scattering in cunfurmità cù i coefficienti truvati.
Codice di linea di regressione
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Chart No. 2 "Risposte currette è calculate"
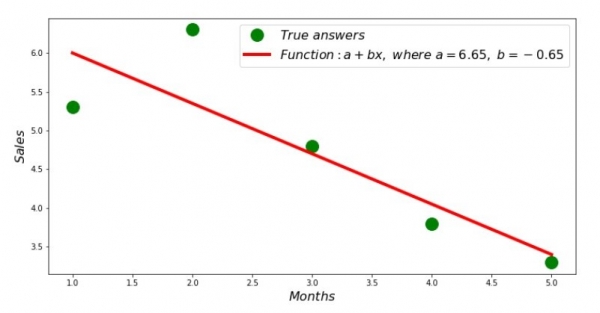
Pudete vede u graficu di deviazione per ogni mese. In u nostru casu, ùn deriveremu micca un valore praticu significativu da ellu, ma avemu da suddisfà a nostra curiosità nantu à quantu l'equazioni di regressione lineale simplice carattirizza a dependenza di i rivenuti nantu à u mese di l'annu.
Codice di carta di deviazione
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Graficu n ° 3 "Deviazioni, %"
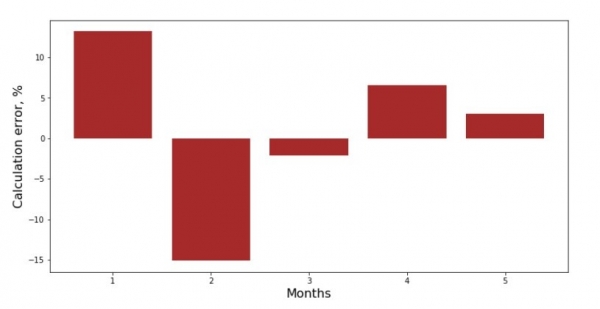
Micca perfetta, ma avemu finitu u nostru compitu.
Scrivemu una funzione chì, per determinà i coefficienti  и
и  usa a biblioteca numpy, più precisamente, scriveremu duie funzioni: una utilizendu una matrice pseudoinversa (micca cunsigliata in a pratica, postu chì u prucessu hè computazionale cumplessu è inestabile), l'altru utilizendu una equazione matricial.
usa a biblioteca numpy, più precisamente, scriveremu duie funzioni: una utilizendu una matrice pseudoinversa (micca cunsigliata in a pratica, postu chì u prucessu hè computazionale cumplessu è inestabile), l'altru utilizendu una equazione matricial.
Codice di Soluzione Analitica (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npComparamu u tempu passatu per a determinazione di i coefficienti  и
и  , in cunfurmità cù i metudi 3 presentati.
, in cunfurmità cù i metudi 3 presentati.
Codice per u calculu di u tempu di calculu
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Cù una piccula quantità di dati, una funzione "autore scritta" esce avanti, chì trova i coefficienti cù u metudu di Cramer.
Avà pudete passà à altre manere di truvà coefficienti  и
и  .
.
Descente à gradient
Prima, definiscemu ciò chì hè un gradiente. Bastamente, u gradiente hè un segmentu chì indica a direzzione di a crescita massima di una funzione. Per analogia cù l'arrampicata in una muntagna, induve u gradiente face hè induve a scalata più ripida à a cima di a muntagna. Sviluppendu l'esempiu cù a muntagna, ricurdemu chì in fattu avemu bisognu di a discesa più ripida per ghjunghje à u pianu più prestu pussibule, vale à dì u minimu - u locu induve a funzione ùn aumenta o diminuisce. À questu puntu, a derivativa serà uguali à zero. Dunque, ùn avemu micca bisognu di un gradiente, ma un antigradiente. Per truvà l'antigradiente basta à multiplicà u gradiente per -1 (menu unu).
Fighjemu attente à u fattu chì una funzione pò avè parechji minimi, è dopu avè scendinu in unu di elli cù l'algoritmu prupostu quì sottu, ùn pudemu micca truvà un altru minimu, chì pò esse più bassu di quellu trovu. Rilassemu, questu ùn hè micca una minaccia per noi ! In u nostru casu avemu trattatu cù un solu minimu, postu chì a nostra funzione  nantu à u graficu hè una parabola regulare. È cum'è tutti duvemu sapè bè da u nostru cursu di matematica di a scola, una parabola hà solu un minimu.
nantu à u graficu hè una parabola regulare. È cum'è tutti duvemu sapè bè da u nostru cursu di matematica di a scola, una parabola hà solu un minimu.
Dopu avemu scupertu perchè avemu bisognu di un gradiente, è ancu chì u gradiente hè un segmentu, vale à dì, un vettore cù coordenate datu, chì sò precisamente i stessi coefficienti.  и
и  pudemu implementà a discesa di gradiente.
pudemu implementà a discesa di gradiente.
Prima di principià, vi cunsigliu di leghje uni pochi di frasi nantu à l'algoritmu di discendenza:
- Determinemu in modu pseudo-aleatoriu e coordenate di i coefficienti
 и . In u nostru esempiu, determineremu i coefficienti vicinu à cero. Questa hè una pratica cumuni, ma ogni casu pò avè a so propria pratica.
и . In u nostru esempiu, determineremu i coefficienti vicinu à cero. Questa hè una pratica cumuni, ma ogni casu pò avè a so propria pratica. - Da coordenada sottrae u valore di a derivata parziale di 1u ordine à u puntu . Allora, se u derivativu hè pusitivu, allora a funzione aumenta. Dunque, sottraendu u valore di u derivatu, andemu in a direzzione opposta di a crescita, vale à dì in a direzzione di a discendenza. Se u derivativu hè negativu, a funzione in questu puntu diminuisce è sottraendu u valore di a derivativa si move in a direzzione di a discendenza.
- Facemu una operazione simili cù a coordenada : sottrae u valore di a derivata parziale à u puntu .
- Per ùn saltà sopra u minimu è vola in u spaziu prufondu, hè necessariu di stabilisce a dimensione di u passu in a direzzione di a discesa. In generale, pudete scrive un articulu sanu nantu à cumu stabilisce u passu currettamente è cumu cambià durante u prucessu di discendenza per riduce i costi di computazione. Ma avà avemu un compitu ligeramente sfarente davanti à noi, è stabiliremu a dimensione di u passu utilizendu u metudu scientificu di "poke" o, cum'è dicenu in lingua cumuni, empirically.
- Una volta simu da e coordenate datu и sottrae i valori di i derivati, avemu ottene coordenate novi и . Facemu u prossimu passu (sustrà), digià da e coordenate calculate. È cusì u ciculu principia una volta è una volta, finu à chì a cunvergenza necessaria hè ottenuta.
 и
и  . In u nostru esempiu, determineremu i coefficienti vicinu à cero. Questa hè una pratica cumuni, ma ogni casu pò avè a so propria pratica.
. In u nostru esempiu, determineremu i coefficienti vicinu à cero. Questa hè una pratica cumuni, ma ogni casu pò avè a so propria pratica. sottrae u valore di a derivata parziale di 1u ordine à u puntu
sottrae u valore di a derivata parziale di 1u ordine à u puntu  . Allora, se u derivativu hè pusitivu, allora a funzione aumenta. Dunque, sottraendu u valore di u derivatu, andemu in a direzzione opposta di a crescita, vale à dì in a direzzione di a discendenza. Se u derivativu hè negativu, a funzione in questu puntu diminuisce è sottraendu u valore di a derivativa si move in a direzzione di a discendenza.
. Allora, se u derivativu hè pusitivu, allora a funzione aumenta. Dunque, sottraendu u valore di u derivatu, andemu in a direzzione opposta di a crescita, vale à dì in a direzzione di a discendenza. Se u derivativu hè negativu, a funzione in questu puntu diminuisce è sottraendu u valore di a derivativa si move in a direzzione di a discendenza.  : sottrae u valore di a derivata parziale à u puntu
: sottrae u valore di a derivata parziale à u puntu  .
. и
и  sottrae i valori di i derivati, avemu ottene coordenate novi
sottrae i valori di i derivati, avemu ottene coordenate novi  и
и  . Facemu u prossimu passu (sustrà), digià da e coordenate calculate. È cusì u ciculu principia una volta è una volta, finu à chì a cunvergenza necessaria hè ottenuta.
. Facemu u prossimu passu (sustrà), digià da e coordenate calculate. È cusì u ciculu principia una volta è una volta, finu à chì a cunvergenza necessaria hè ottenuta.Tuttu ! Avà simu pronti à andà in cerca di a gola più prufonda di a Fossa di Mariana. Cuminciamu.
Codice per a discesa di gradiente
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Immersi finu à u fondu di a fossa Mariana è quì avemu trovu tutti i stessi valori di coefficient  и
и  , chì hè esattamente ciò chì era aspittatu.
, chì hè esattamente ciò chì era aspittatu.
Facemu un'altra immersione, solu sta volta, u nostru veiculu di mare prufonda serà pienu di altre tecnulugia, à dì una biblioteca. numpy.
Codice per a discesa di gradiente (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Valori di coefficient  и
и  immutabile.
immutabile.
Fighjemu cumu l'errore hà cambiatu durante a discesa di gradiente, vale à dì cumu a somma di e deviazioni quadrate hà cambiatu cù ogni passu.
Codice per tracciare sume di deviazioni quadrate
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Graficu n ° 4 "Suma di deviazioni quadrate durante a discesa di gradiente"
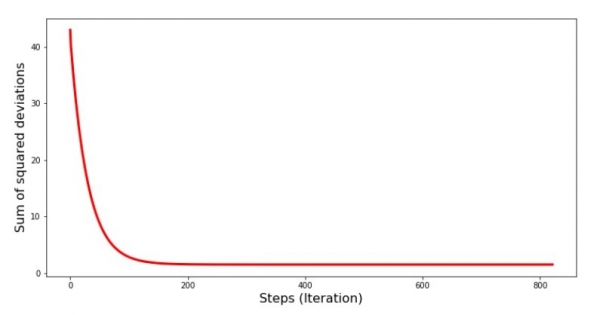
Nantu à u graficu vedemu chì cù ogni passu l'errore diminuite, è dopu un certu nùmeru di iterazioni observemu una linea quasi horizontale.
Infine, stimu a diffarenza in u tempu di esecuzione di codice:
Codice per determinà u tempu di calculu di discendenza di gradiente
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Forse facemu qualcosa di sbagliatu, ma dinò hè una funzione simplice "scritta in casa" chì ùn usa micca a biblioteca. numpy supera u tempu di calculu di una funzione cù a biblioteca numpy.
Ma ùn simu fermu, ma andemu versu studià un altru modu eccitante per risolve l'equazioni di regressione lineale simplice. Scuntràci!
Descente di gradiente stochasticu
Per capisce rapidamente u principiu di funziunamentu di a discesa di gradiente stochastic, hè megliu per determinà e so differenzi da a discendenza di gradiente ordinariu. Avemu, in u casu di discendenza gradiente, in l'equazioni di derivati di  и
и  hà utilizatu a summa di i valori di tutte e caratteristiche è e risposte veri dispunibuli in u sample (vale à dì, i sume di tutti
hà utilizatu a summa di i valori di tutte e caratteristiche è e risposte veri dispunibuli in u sample (vale à dì, i sume di tutti  и
и  ). In a discesa di gradiente stochasticu, ùn avemu micca aduprà tutti i valori prisenti in u campionu, ma invece, selezziunate pseudo-aleatoriu u chjamatu indice di mostra è utilizate i so valori.
). In a discesa di gradiente stochasticu, ùn avemu micca aduprà tutti i valori prisenti in u campionu, ma invece, selezziunate pseudo-aleatoriu u chjamatu indice di mostra è utilizate i so valori.
Per esempiu, se l'indici hè determinatu per esse u numeru 3 (trè), allora pigliamu i valori  и
и  , tandu sustituemu i valori in l'equazioni derivative è determinanu novi coordenate. Dopu, dopu avè determinatu e coordenate, determinemu di novu pseudo-aleatoriu l'indice di mostra, sustituisci i valori currispondenti à l'indice in l'equazioni differenziali parziali, è determinanu e coordenate in una nova manera.
, tandu sustituemu i valori in l'equazioni derivative è determinanu novi coordenate. Dopu, dopu avè determinatu e coordenate, determinemu di novu pseudo-aleatoriu l'indice di mostra, sustituisci i valori currispondenti à l'indice in l'equazioni differenziali parziali, è determinanu e coordenate in una nova manera.  и
и  ecc. finu à chì a cunvergenza diventa verde. À u primu sguardu, ùn pare micca chì questu puderia travaglià in tuttu, ma hè cusì. Hè veru chì vale a pena nutà chì l'errore ùn diminuite micca cù ogni passu, ma ci hè certamente una tendenza.
ecc. finu à chì a cunvergenza diventa verde. À u primu sguardu, ùn pare micca chì questu puderia travaglià in tuttu, ma hè cusì. Hè veru chì vale a pena nutà chì l'errore ùn diminuite micca cù ogni passu, ma ci hè certamente una tendenza.
Chì sò i vantaghji di a discendenza di gradiente stochasticu nantu à una cunvinziunali? Se a nostra dimensione di mostra hè assai grande è misurata in decine di millaie di valori, allora hè assai più faciule di processà, per dì, un milla aleatoriu d'elli, piuttostu cà a mostra sana. Hè quì chì a discesa di gradiente stochasticu entra in ghjocu. In u nostru casu, sicuru, ùn avemu micca nutatu assai di differenza.
Fighjemu u codice.
Codice per a discesa di gradiente stochasticu
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Fighjemu attentamente à i coefficienti è pigliamu a dumanda "Cumu pò esse?" Avemu altri valori di coefficienti  и
и  . Forse a discesa di gradiente stochasticu hà trovu parametri più ottimali per l'equazioni? Sfurtunatamente no. Hè abbastanza per fighjà a summa di deviazioni quadrate è vede chì cù novi valori di i coefficienti, l'errore hè più grande. Ùn avemu micca fretta di disperarà. Custruemu un graficu di u cambiamentu di errore.
. Forse a discesa di gradiente stochasticu hà trovu parametri più ottimali per l'equazioni? Sfurtunatamente no. Hè abbastanza per fighjà a summa di deviazioni quadrate è vede chì cù novi valori di i coefficienti, l'errore hè più grande. Ùn avemu micca fretta di disperarà. Custruemu un graficu di u cambiamentu di errore.
Codice per tracciare a somma di deviazioni quadrate in a discesa di gradiente stochasticu
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Graficu n ° 5 "Suma di deviazioni quadrate durante a discesa di gradiente stochasticu"
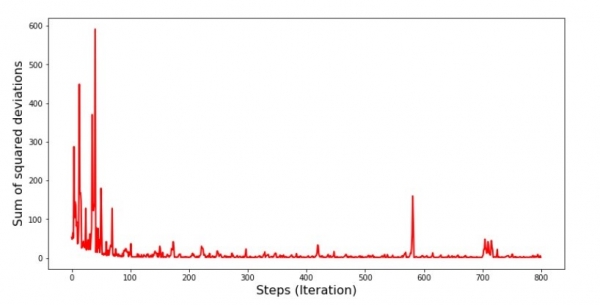
Fighjendu u calendariu, tuttu cade in u locu è avà riparà tuttu.
Allora chì hè accadutu ? I seguenti successi. Quandu selezziunate un mese aleatoriu, allora hè per u mese sceltu chì u nostru algoritmu cerca di riduce l'errore in u calculu di i rivenuti. Allora selezziunate un altru mese è ripetite u calculu, ma riducemu l'errore per u secondu mese sceltu. Avà ricordate chì i primi dui mesi deviate significativamente da a linea di l'equazioni di regressione lineale simplice. Questu significa chì quandu qualchissia di sti dui mesi hè sceltu, riducendu l'errore di ognuna di elli, u nostru algoritmu aumenta seriamente l'errore per a mostra sana. Allora chì fà ? A risposta hè simplice: avete bisognu di riduce u passu di discendenza. Dopu tuttu, riducendu u passu di discesa, l'errore ferma ancu di "saltà" in sopra è in falà. O piuttostu, l'errore di "saltà" ùn si ferma micca, ma ùn farà micca cusì rapidamente :) Cuntrollamu.
Codice per eseguisce SGD cù incrementi più chjuchi
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Graficu n ° 6 "Suma di deviazioni quadrate durante a discesa di gradiente stochasticu (80 mila passi)"
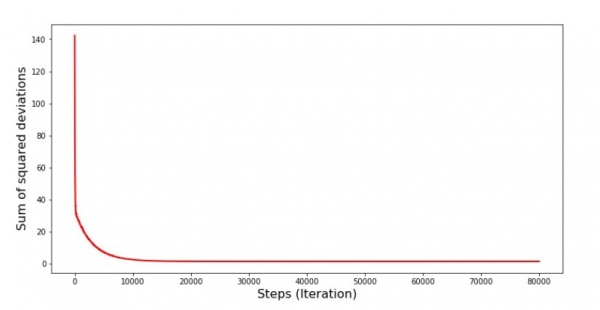
I coefficienti anu migliuratu, ma sò ancu micca ideali. Ipoteticamente, questu pò esse currettu in questu modu. Selezziunà, per esempiu, in l'ultimi 1000 iterazioni i valori di i coefficienti cù quale l'errore minimu hè statu fattu. True, per questu avemu da scrive ancu i valori di i coefficienti stessi. Ùn faremu micca questu, ma piuttostu attente à u calendariu. Sembra liscia è l'errore pare diminuisce in modu uniforme. In verità questu ùn hè micca veru. Fighjemu i primi 1000 iterazioni è paragunemu cù l'ultimi.
Codice per u graficu SGD (primi 1000 passi)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
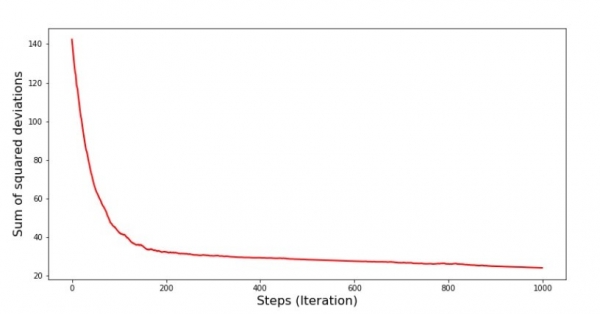
plt.show()Graficu n ° 7 "Suma di deviazioni quadrate SGD (primi 1000 passi)"
Graficu n ° 8 "Suma di deviazioni quadrate SGD (ultimi passi 1000)"
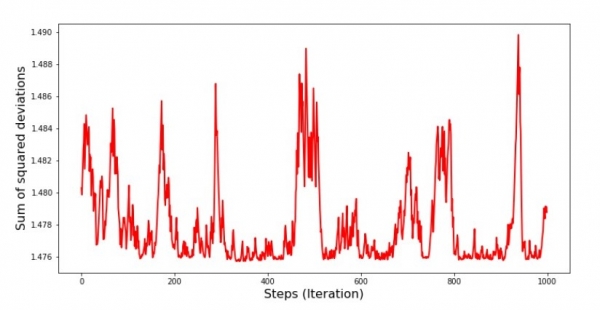
À u principiu di a discesa, observemu una diminuzione abbastanza uniforme è ripida di l'errore. In l'ultime iterazioni, vedemu chì l'errore gira intornu à u valore di 1,475 è in certi mumenti ancu uguali à stu valore ottimale, ma poi sempre cullà... Ripeti, pudete scrive i valori di u valore. coefficienti  и
и  , è dopu selezziunate quelli chì l'errore hè minimu. Tuttavia, avemu avutu un prublema più seriu: avemu avutu à piglià 80 mila passi (vede u codice) per ottene i valori vicinu à l'ottimali. È questu hè digià cuntradite l'idea di risparmià u tempu di calculu cù a discesa di gradiente stochasticu relative à a discesa di gradiente. Chì pò esse currettu è migliuratu? Ùn hè micca difficiule di nutà chì in i primi iterazioni avemu cunfidenza falà è, per quessa, duvemu abbandunà un grande passu in i primi iterazioni è riduce u passu mentre avanzamu. Ùn faremu micca questu in questu articulu - hè digià troppu longu. Quelli chì volenu ponu pensà per sè stessu cumu fà questu, ùn hè micca difficiule :)
, è dopu selezziunate quelli chì l'errore hè minimu. Tuttavia, avemu avutu un prublema più seriu: avemu avutu à piglià 80 mila passi (vede u codice) per ottene i valori vicinu à l'ottimali. È questu hè digià cuntradite l'idea di risparmià u tempu di calculu cù a discesa di gradiente stochasticu relative à a discesa di gradiente. Chì pò esse currettu è migliuratu? Ùn hè micca difficiule di nutà chì in i primi iterazioni avemu cunfidenza falà è, per quessa, duvemu abbandunà un grande passu in i primi iterazioni è riduce u passu mentre avanzamu. Ùn faremu micca questu in questu articulu - hè digià troppu longu. Quelli chì volenu ponu pensà per sè stessu cumu fà questu, ùn hè micca difficiule :)
Avà eseguisce una discesa di gradiente stochasticu utilizendu a biblioteca numpy (è ùn inciamu micca nantu à e petre chì avemu identificatu prima)
Codice per a Descensu Gradiente Stocasticu (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
I valori sò diventati quasi i stessi chì quandu si scende senza usu numpy. Tuttavia, questu hè logicu.
Scupritemu quantu ci anu purtatu a discendenza di gradiente stochasticu.
Codice per a determinazione di u tempu di calculu SGD (80 mila passi)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
U più in u boscu, u più scuru i nuvuli: di novu, a formula "autore scritta" mostra u megliu risultatu. Tuttu chistu suggerisce chì ci deve esse ancu modi più sottili per utilizà a biblioteca numpy, chì veramente accelerà e operazioni di calculu. In questu articulu ùn avemu micca amparà nantu à elli. Ci sarà qualcosa à pensà in u vostru tempu liberu :)
Impariscamu
Prima di riassume, mi piacerebbe risponde à una quistione chì assai prubabilmente nasce da u nostru caru lettore. Perchè, in fattu, tali "tortura" cù i discendenti, perchè avemu bisognu di marchjà sopra è falà a muntagna (a maiò parte di a muntagna) per truvà u pianu tesoru, s'ellu avemu in e nostre mani un dispusitivu cusì putente è simplice, in u forma di una suluzione analitica, chì ci teletransporta istantaneamente à u locu ghjustu?
A risposta à sta quistione si trova nantu à a superficia. Avà avemu vistu un esempiu assai simplice, in quale a risposta vera hè  dipende di un signu
dipende di un signu  . Ùn vede micca spessu in a vita, cusì imaginemu chì avemu 2, 30, 50 o più segni. Aghjunghjemu à questu millaie, o ancu decine di millaie di valori per ogni attributu. In questu casu, a suluzione analitica ùn pò micca sustene a prova è falla. À u turnu, a discesa di gradiente è e so variazioni, lentamente, ma sicuru, ci portanu più vicinu à u scopu - u minimu di a funzione. È ùn vi preoccupate micca di a velocità - prubabilmente guardemu modi chì ci permettenu di stabilisce è regulà a durata di u passu (vale à dì, a velocità).
. Ùn vede micca spessu in a vita, cusì imaginemu chì avemu 2, 30, 50 o più segni. Aghjunghjemu à questu millaie, o ancu decine di millaie di valori per ogni attributu. In questu casu, a suluzione analitica ùn pò micca sustene a prova è falla. À u turnu, a discesa di gradiente è e so variazioni, lentamente, ma sicuru, ci portanu più vicinu à u scopu - u minimu di a funzione. È ùn vi preoccupate micca di a velocità - prubabilmente guardemu modi chì ci permettenu di stabilisce è regulà a durata di u passu (vale à dì, a velocità).
È avà u veru riassuntu breve.
Prima, speru chì u materiale presentatu in l'articulu aiuterà à principià "scientists di dati" per capiscenu cumu risolve equazioni di regressione lineari simplici (è micca solu).
Siconda, avemu vistu parechje manere di risolve l'equazioni. Avà, sicondu a situazione, pudemu sceglie quellu chì hè megliu adattatu per risolve u prublema.
Terzu, avemu vistu u putere di paràmetri supplementari, vale à dì a durata di u passu di discesa gradiente. Stu paràmetru ùn pò esse trascuratatu. Comu nutatu sopra, per riduce u costu di i calculi, a durata di u passu deve esse cambiatu durante a discesa.
In quartu, in u nostru casu, e funzioni "scritte in casa" dimustranu i megliu risultati di u tempu per i calculi. Questu hè probabilmente duvuta à micca l'usu più prufessiunale di e capacità di a biblioteca numpy. Ma sia cusì, a seguente cunclusione si suggerisce. Da una banda, qualchì volta vale a pena interrogà l'opinioni stabilite, è da l'altra banda, ùn hè micca sempre vale a pena cumplicà tuttu - à u cuntrariu, qualchì volta un modu più simplice di risolve un prublema hè più efficace. E postu chì u nostru scopu era di analizà trè approcci per risolve una equazione di regressione lineale simplice, l'usu di e funzioni "auto-scritte" era abbastanza per noi.
Letteratura (o qualcosa di simile)
1. Regressione lineale
2. Metudu di u minimu quadru
3. Derivatu
4. Gradiente
5. Descente di gradiente
6. Biblioteca NumPy
Source: www.habr.com
