

Před začátkem kurzu pro vás připravil překlad dalšího užitečného materiálu.
Huffmanovo kódování je algoritmus komprese dat, který formuluje základní myšlenku komprese souborů. V tomto článku budeme hovořit o kódování s pevnou a proměnnou délkou, jedinečně dekódovatelných kódech, pravidlech pro předpony a budování Huffmanova stromu.
Víme, že každý znak je uložen jako sekvence 0 a 1 a zabírá 8 bitů. Toto se nazývá kódování s pevnou délkou, protože každý znak používá k uložení stejný pevný počet bitů.
Řekněme, že máme text. Jak můžeme snížit množství místa potřebného k uložení jednoho znaku?
Hlavní myšlenkou je kódování s proměnnou délkou. Můžeme využít toho, že některé znaky se v textu vyskytují častěji než jiné () vyvinout algoritmus, který bude reprezentovat stejnou sekvenci znaků v méně bitech. V kódování s proměnnou délkou přidělujeme znakům proměnný počet bitů podle toho, jak často se v daném textu vyskytují. Nakonec některé znaky mohou trvat jen 1 bit, zatímco jiné mohou trvat 2 bity, 3 nebo více. Problémem kódování s proměnnou délkou je pouze následné dekódování sekvence.
Jak to při znalosti posloupnosti bitů jednoznačně dekódovat?
Zvažte čáru "abacdab". Má 8 znaků a při kódování pevné délky bude k uložení potřebovat 64 bitů. Všimněte si, že frekvence symbolu "a", "b", "c" и "D" rovná se 4, 2, 1, 1 v tomto pořadí. Zkusme si to představit "abacdab" méně bitů, s využitím skutečnosti, že "na" vyskytuje častěji než "B"a "B" vyskytuje častěji než "C" и "D". Začněme kódováním "na" s jedním bitem rovným 0, "B" přiřadíme dvoubitový kód 11 a pomocí tří bitů 100 a 011 zakódujeme "C" и "D".
V důsledku toho získáme:
a
0
b
11
c
100
d
011
Takže čára "abacdab" budeme kódovat jako 00110100011011 (0|0|11|0|100|011|0|11)pomocí výše uvedených kódů. Hlavní problém však bude v dekódování. Když se snažíme dekódovat řetězec 00110100011011, dostaneme nejednoznačný výsledek, protože jej lze reprezentovat jako:
0|011|0|100|011|0|11 adacdab
0|0|11|0|100|0|11|011 aabacabd
0|011|0|100|0|11|0|11 adacabab
...
atd.
Abychom se vyhnuli této nejednoznačnosti, musíme zajistit, aby naše kódování vyhovovalo takovému konceptu jako pravidlo předpony, což zase znamená, že kódy lze dekódovat pouze jedním jedinečným způsobem. Pravidlo prefixu zajišťuje, že žádný kód není prefixem jiného. Kódem rozumíme bity používané k reprezentaci určitého znaku. V příkladu výše 0 je předpona 011, což porušuje pravidlo předpony. Pokud tedy naše kódy splňují pravidlo prefixu, můžeme je jednoznačně dekódovat (a naopak).
Vraťme se k výše uvedenému příkladu. Tentokrát budeme přiřazovat pro symboly "a", "b", "c" и "D" kódy, které splňují pravidlo prefixu.
a
0
b
10
c
110
d
111
S tímto kódováním řetězec "abacdab" bude zakódováno jako 00100100011010 (0|0|10|0|100|011|0|10). Avšak 00100100011010 již budeme schopni jednoznačně dekódovat a vrátit se k našemu původnímu řetězci "abacdab".
Huffmanovo kódování
Nyní, když jsme se zabývali kódováním s proměnnou délkou a pravidlem pro předponu, pojďme mluvit o Huffmanově kódování.
Metoda je založena na vytváření binárních stromů. V něm může být uzel buď konečný, nebo vnitřní. Zpočátku jsou všechny uzly považovány za listy (terminály), které představují samotný symbol a jeho váhu (tedy četnost výskytu). Vnitřní uzly obsahují váhu znaku a odkazují na dva podřízené uzly. Podle obecné dohody bit «0» představuje následující levou větev a «1» - napravo. v plném stromě N listy a N-1 vnitřní uzly. Při konstrukci Huffmanova stromu se doporučuje vyřadit nepoužívané symboly, aby se získaly kódy optimální délky.
K vytvoření Huffmanova stromu použijeme prioritní frontu, kde uzel s nejnižší frekvencí bude mít nejvyšší prioritu. Konstrukční kroky jsou popsány níže:
- Vytvořte listový uzel pro každou postavu a přidejte je do prioritní fronty.
- Pokud je ve frontě více než jeden list, proveďte následující:
- Odstraňte dva uzly s nejvyšší prioritou (nejnižší frekvencí) z fronty;
- Vytvořte nový vnitřní uzel, kde tyto dva uzly budou potomky a četnost výskytu bude rovna součtu četností těchto dvou uzlů.
- Přidejte nový uzel do prioritní fronty.
- Jediným zbývajícím uzlem bude kořen a tím bude stavba stromu dokončena.
Představte si, že máme nějaký text, který se skládá pouze ze znaků "abeceda" и "a"a jejich frekvence výskytu jsou 15, 7, 6, 6 a 5, v tomto pořadí. Níže jsou ilustrace, které odrážejí kroky algoritmu.
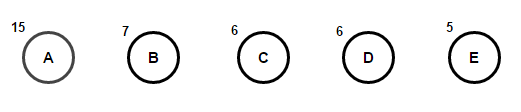
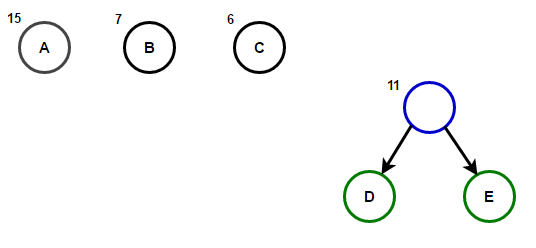
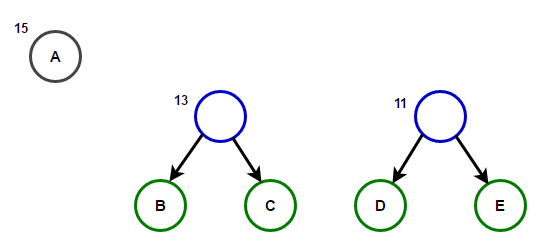
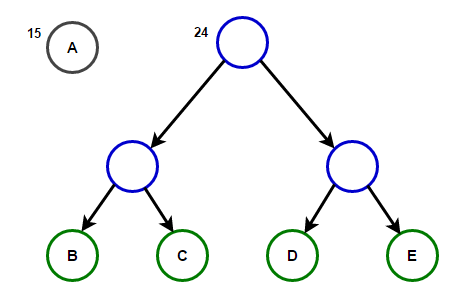
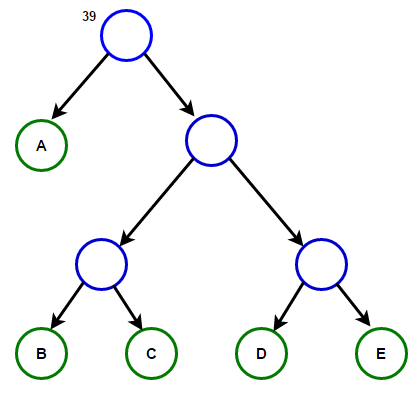
Cesta od kořene k libovolnému koncovému uzlu bude ukládat optimální prefixový kód (také známý jako Huffmanův kód) odpovídající znaku spojenému s tímto koncovým uzlem.
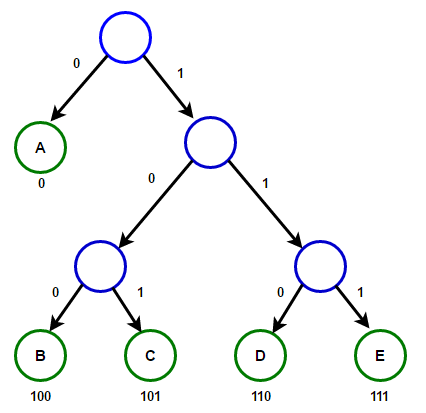
Huffmanův strom
Níže naleznete implementaci Huffmanova kompresního algoritmu v C++ a Javě:
#include <iostream>
#include <string>
#include <queue>
#include <unordered_map>
using namespace std;
// A Tree node
struct Node
{
char ch;
int freq;
Node *left, *right;
};
// Function to allocate a new tree node
Node* getNode(char ch, int freq, Node* left, Node* right)
{
Node* node = new Node();
node->ch = ch;
node->freq = freq;
node->left = left;
node->right = right;
return node;
}
// Comparison object to be used to order the heap
struct comp
{
bool operator()(Node* l, Node* r)
{
// highest priority item has lowest frequency
return l->freq > r->freq;
}
};
// traverse the Huffman Tree and store Huffman Codes
// in a map.
void encode(Node* root, string str,
unordered_map<char, string> &huffmanCode)
{
if (root == nullptr)
return;
// found a leaf node
if (!root->left && !root->right) {
huffmanCode[root->ch] = str;
}
encode(root->left, str + "0", huffmanCode);
encode(root->right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
void decode(Node* root, int &index, string str)
{
if (root == nullptr) {
return;
}
// found a leaf node
if (!root->left && !root->right)
{
cout << root->ch;
return;
}
index++;
if (str[index] =='0')
decode(root->left, index, str);
else
decode(root->right, index, str);
}
// Builds Huffman Tree and decode given input text
void buildHuffmanTree(string text)
{
// count frequency of appearance of each character
// and store it in a map
unordered_map<char, int> freq;
for (char ch: text) {
freq[ch]++;
}
// Create a priority queue to store live nodes of
// Huffman tree;
priority_queue<Node*, vector<Node*>, comp> pq;
// Create a leaf node for each character and add it
// to the priority queue.
for (auto pair: freq) {
pq.push(getNode(pair.first, pair.second, nullptr, nullptr));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node *left = pq.top(); pq.pop();
Node *right = pq.top(); pq.pop();
// Create a new internal node with these two nodes
// as children and with frequency equal to the sum
// of the two nodes' frequencies. Add the new node
// to the priority queue.
int sum = left->freq + right->freq;
pq.push(getNode(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node* root = pq.top();
// traverse the Huffman Tree and store Huffman Codes
// in a map. Also prints them
unordered_map<char, string> huffmanCode;
encode(root, "", huffmanCode);
cout << "Huffman Codes are :n" << 'n';
for (auto pair: huffmanCode) {
cout << pair.first << " " << pair.second << 'n';
}
cout << "nOriginal string was :n" << text << 'n';
// print encoded string
string str = "";
for (char ch: text) {
str += huffmanCode[ch];
}
cout << "nEncoded string is :n" << str << 'n';
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
cout << "nDecoded string is: n";
while (index < (int)str.size() - 2) {
decode(root, index, str);
}
}
// Huffman coding algorithm
int main()
{
string text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
return 0;
}import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
// A Tree node
class Node
{
char ch;
int freq;
Node left = null, right = null;
Node(char ch, int freq)
{
this.ch = ch;
this.freq = freq;
}
public Node(char ch, int freq, Node left, Node right) {
this.ch = ch;
this.freq = freq;
this.left = left;
this.right = right;
}
};
class Huffman
{
// traverse the Huffman Tree and store Huffman Codes
// in a map.
public static void encode(Node root, String str,
Map<Character, String> huffmanCode)
{
if (root == null)
return;
// found a leaf node
if (root.left == null && root.right == null) {
huffmanCode.put(root.ch, str);
}
encode(root.left, str + "0", huffmanCode);
encode(root.right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
public static int decode(Node root, int index, StringBuilder sb)
{
if (root == null)
return index;
// found a leaf node
if (root.left == null && root.right == null)
{
System.out.print(root.ch);
return index;
}
index++;
if (sb.charAt(index) == '0')
index = decode(root.left, index, sb);
else
index = decode(root.right, index, sb);
return index;
}
// Builds Huffman Tree and huffmanCode and decode given input text
public static void buildHuffmanTree(String text)
{
// count frequency of appearance of each character
// and store it in a map
Map<Character, Integer> freq = new HashMap<>();
for (int i = 0 ; i < text.length(); i++) {
if (!freq.containsKey(text.charAt(i))) {
freq.put(text.charAt(i), 0);
}
freq.put(text.charAt(i), freq.get(text.charAt(i)) + 1);
}
// Create a priority queue to store live nodes of Huffman tree
// Notice that highest priority item has lowest frequency
PriorityQueue<Node> pq = new PriorityQueue<>(
(l, r) -> l.freq - r.freq);
// Create a leaf node for each character and add it
// to the priority queue.
for (Map.Entry<Character, Integer> entry : freq.entrySet()) {
pq.add(new Node(entry.getKey(), entry.getValue()));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node left = pq.poll();
Node right = pq.poll();
// Create a new internal node with these two nodes as children
// and with frequency equal to the sum of the two nodes
// frequencies. Add the new node to the priority queue.
int sum = left.freq + right.freq;
pq.add(new Node(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node root = pq.peek();
// traverse the Huffman tree and store the Huffman codes in a map
Map<Character, String> huffmanCode = new HashMap<>();
encode(root, "", huffmanCode);
// print the Huffman codes
System.out.println("Huffman Codes are :n");
for (Map.Entry<Character, String> entry : huffmanCode.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
System.out.println("nOriginal string was :n" + text);
// print encoded string
StringBuilder sb = new StringBuilder();
for (int i = 0 ; i < text.length(); i++) {
sb.append(huffmanCode.get(text.charAt(i)));
}
System.out.println("nEncoded string is :n" + sb);
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
System.out.println("nDecoded string is: n");
while (index < sb.length() - 2) {
index = decode(root, index, sb);
}
}
public static void main(String[] args)
{
String text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
}
}Poznámka: paměť využívaná vstupním řetězcem je 47 * 8 = 376 bitů a kódovaný řetězec je pouze 194 bitů, tzn. data jsou komprimována asi o 48 %. Ve výše uvedeném programu C++ používáme třídu string k uložení zakódovaného řetězce, aby byl program čitelný.
Protože efektivní prioritní datové struktury fronty vyžadují na vložení O(log(N)) čas, ale v úplném binárním stromu s N listy přítomny 2N-1 uzly a Huffmanův strom je úplný binární strom, pak se spustí algoritmus O(Nlog(N)) čas, kde N - Postavy.
Zdroje:
Zdroj: www.habr.com
