

Na začátku byla technologie a jmenovala se BPF. Podívali jsme se na ni , Starý zákon, článek v této sérii. V roce 2013 byl díky úsilí Alexeje Starovoitova a Daniela Borkmana vyvinut a zahrnut do jádra Linux Vylepšená verze optimalizovaná pro moderní 64bitové počítače. Tato nová technologie se krátce nazývala Internal BPF, poté se přejmenovala na Extended BPF a nyní, o několik let později, jí všichni říkají jednoduše BPF.
BPF v podstatě umožňuje běh libovolného kódu zadaného uživatelem v prostoru jádra. Linux A nová architektura se ukázala být tak úspěšná, že bychom potřebovali další tucet článků k popisu všech jejích aplikací. (Jediné, co se vývojářům nepodařilo, jak vidíte v níže uvedeném grafu efektivity, bylo vytvoření slušného loga.)
Tento článek popisuje strukturu virtuálního stroje BPF, rozhraní jádra pro práci s BPF, vývojové nástroje a také stručný, velmi stručný přehled existujících schopností, tzn. vše, co budeme v budoucnu potřebovat pro hlubší studium praktických aplikací BPF.
Shrnutí článku
Nejprve se podíváme na architekturu BPF z ptačí perspektivy a nastíníme hlavní komponenty.
Již máme představu o architektuře jako celku, popíšeme strukturu virtuálního stroje BPF.
V této části se blíže podíváme na životní cyklus BPF objektů – programů a map.
Když už trochu rozumíme systému, podíváme se konečně na to, jak vytvářet a manipulovat s objekty z uživatelského prostoru pomocí speciálního systémového volání − bpf(2).
Programy samozřejmě můžete psát pomocí systémového volání. Ale je to těžké. Pro realističtější scénář vyvinuli jaderní programátoři knihovnu libbpf. Vytvoříme základní kostru aplikace BPF, kterou použijeme v následujících příkladech.
Zde se dozvíme, jak mohou programy BPF přistupovat k pomocným funkcím jádra – nástroji, který spolu s mapami zásadně rozšiřuje možnosti nového BPF oproti tomu klasickému.
V tomto bodě budeme vědět dost na to, abychom přesně pochopili, jak můžeme vytvářet programy, které využívají mapy. A pojďme dokonce rychle nahlédnout do velkého a mocného ověřovače.
Sekce nápovědy o tom, jak sestavit požadované nástroje a jádro pro experimenty.
Na konci článku ti, kteří dočetli až sem, najdou v následujících článcích motivující slova a stručný popis toho, co se bude dít. Uvedeme i řadu odkazů pro samostudium pro ty, kteří nemají chuť či schopnosti čekat na pokračování.
Úvod do architektury BPF
Než začneme uvažovat o architektuře BPF, odkážeme ještě naposledy (ach) na , který byl vyvinut jako reakce na nástup RISC strojů a vyřešil problém efektivního filtrování paketů. Architektura se ukázala být natolik úspěšná, že se zrodila na přelomu devadesátých let v Berkeley UNIX, byla portována na většinu existujících operačních systémů, přežila do šílených dvacátých let a stále nachází nové aplikace.
Nový BPF byl vyvinut jako reakce na všudypřítomnost 64bitových strojů, cloudových služeb a zvýšenou potřebu nástrojů pro vytváření SDN (Software-dusilovně nNová BPF, vyvinutá inženýry páteřních sítí jako vylepšená náhrada za klasickou BPF, našla uplatnění v obtížném úkolu trasování o pouhých šest měsíců později. Linux systémy a nyní, šest let po jejich objevení, bychom potřebovali zcela nový článek jen k tomu, abychom vyjmenovali různé typy programů.
Vtipné obrázky
Ve svém jádru je BPF sandboxový virtuální stroj, který vám umožňuje spouštět „libovolný“ kód v prostoru jádra, aniž by došlo k ohrožení bezpečnosti. Programy BPF se vytvářejí v uživatelském prostoru, načítají se do jádra a připojují se k nějakému zdroji událostí. Událostí může být například doručení paketu na síťové rozhraní, spuštění nějaké funkce jádra atp. V případě balíčku bude mít program BPF přístup k datům a metadatům balíčku (pro čtení a případně zápis, v závislosti na typu programu); v případě spuštění funkce jádra budou argumenty funkce, včetně ukazatelů na paměť jádra atd.
Pojďme se na tento proces podívat blíže. Pro začátek si řekněme první rozdíl od klasických BPF, pro které byly programy napsány v assembleru. V nové verzi byla architektura rozšířena tak, aby bylo možné programy psát ve vyšších jazycích, primárně samozřejmě v C. K tomu byl vyvinut backend pro llvm, který umožňuje generovat bytecode pro architekturu BPF.

Architektura BPF byla navržena částečně tak, aby fungovala efektivně na moderních strojích. Aby to fungovalo v praxi, je bajtový kód BPF po načtení do jádra přeložen do nativního kódu pomocí komponenty zvané JIT kompilátor (JUst In Tčas). Dále, pokud si vzpomínáte, v klasickém BPF byl program načten do jádra a připojen ke zdroji události atomicky - v kontextu jediného systémového volání. V nové architektuře se to děje ve dvou fázích – nejprve se kód nahraje do jádra pomocí systémového volání bpf(2)a později, prostřednictvím jiných mechanismů, které se liší v závislosti na typu programu, se program připojí ke zdroji události.
Zde může mít čtenář otázku: bylo to možné? Jak je zaručena bezpečnost provádění takového kódu? Bezpečnost provádění nám zaručuje fáze načítání BPF programů zvaná verifikátor (v angličtině se tato fáze nazývá verifikátor a nadále budu používat anglické slovo):

Verifier je statický analyzátor, který zajišťuje, že program nenaruší normální provoz jádra. To mimochodem neznamená, že program nemůže zasahovat do provozu systému - programy BPF v závislosti na typu mohou číst a přepisovat části paměti jádra, vracet hodnoty funkcí, trimovat, přidávat, přepisovat a dokonce přeposílat síťové pakety. Verifier zaručuje, že spuštění programu BPF nezpůsobí pád jádra a že program, který má podle pravidel přístup pro zápis, například data odchozího paketu, nebude schopen přepsat paměť jádra mimo paket. Na verifikátor se podíváme trochu podrobněji v příslušné sekci, až se seznámíme se všemi ostatními složkami BPF.
Co jsme se tedy zatím naučili? Uživatel napíše program v C, nahraje jej do jádra pomocí systémového volání bpf(2), kde je zkontrolován ověřovatelem a přeložen do nativního bajtkódu. Poté stejný nebo jiný uživatel připojí program ke zdroji události a začne se spouštět. Oddělit boot a připojení je nutné z několika důvodů. Za prvé, provoz ověřovače je poměrně drahý a opakovaným stažením stejného programu ztrácíme počítačový čas. Za druhé, přesně to, jak je program připojen, závisí na jeho typu a jedno „univerzální“ rozhraní vyvinuté před rokem nemusí být vhodné pro nové typy programů. (Ačkoli nyní, kdy se architektura stává vyspělejší, existuje myšlenka sjednotit toto rozhraní na úrovni libbpf.)
Pozorný čtenář si může všimnout, že s obrázky ještě nekončíme. Všechno výše uvedené skutečně nevysvětluje, proč BPF zásadně mění obrázek ve srovnání s klasickým BPF. Dvě novinky, které výrazně rozšiřují rozsah použitelnosti, jsou možnost využívat sdílenou paměť a pomocné funkce jádra. V BPF je sdílená paměť implementována pomocí tzv. map – sdílených datových struktur se specifickým API. Pravděpodobně dostali toto jméno, protože první typ mapy, který se objevil, byla hashovací tabulka. Pak se objevila pole, lokální (per-CPU) hashovací tabulky a lokální pole, vyhledávací stromy, mapy obsahující ukazatele na BPF programy a mnoho dalšího. Pro nás je nyní zajímavé, že programy BPF nyní mají schopnost přetrvávat stav mezi hovory a sdílet jej s jinými programy a uživatelským prostorem.
Mapy jsou přístupné z uživatelských procesů pomocí systémového volání bpf(2)a z programů BPF spuštěných v jádře pomocí pomocných funkcí. Kromě toho existují pomocníci nejen pro práci s mapami, ale také pro přístup k dalším schopnostem jádra. Například programy BPF mohou používat pomocné funkce k předávání paketů na jiná rozhraní, generování událostí perf, přístupu ke strukturám jádra a tak dále.

Stručně řečeno, BPF poskytuje možnost načíst libovolný, tj. ověřovatelem testovaný uživatelský kód do prostoru jádra. Tento kód může ukládat stav mezi voláními a vyměňovat si data s uživatelským prostorem a má také přístup k subsystémům jádra povoleným tímto typem programu.
To je již podobné schopnostem, které poskytují moduly jádra, oproti kterým má BPF určité výhody (samozřejmě lze porovnávat pouze podobné aplikace, například trasování systému - s BPF nelze napsat libovolný ovladač). Můžete si povšimnout nižší vstupní prahové hodnoty (některé nástroje, které používají BPF, nevyžadují od uživatele znalosti programování v jádře nebo programátorské dovednosti obecně), bezpečnost běhu (zvedněte ruku v komentářích pro ty, kteří při psaní nenarušili systém nebo testování modulů), atomicita – při opětovném načítání modulů dochází k prostojům a subsystém BPF zajišťuje, že nedojde k žádné události (abych byl spravedlivý, neplatí to pro všechny typy programů BPF).
Přítomnost takových schopností dělá z BPF univerzální nástroj pro rozšiřování jádra, což se v praxi potvrzuje: do BPF se přidává stále více nových typů programů, stále více velkých společností používá BPF na bojových serverech 24×7, stále více startupy staví své podnikání na řešeních, na kterých jsou založeny BPF. BPF se používá všude: při ochraně před útoky DDoS, vytváření SDN (například implementace sítí pro kubernetes), jako hlavní nástroj pro sledování systému a sběratel statistik, v systémech detekce narušení a systémech sandbox atd.
Dokončíme zde přehledovou část článku a podíváme se na virtuální stroj a ekosystém BPF podrobněji.
Odbočka: komunální služby
Abyste mohli spouštět příklady v následujících částech, možná budete potřebovat alespoň několik utilit llvm/clang s podporou bpf a bpftool. V sekci Můžete si přečíst pokyny pro sestavení utilit a také vaše jádro. Tato sekce je umístěna níže, aby nenarušila harmonii naší prezentace.
Registry virtuálních strojů BPF a instrukční systém
Architektura a příkazový systém BPF byly vyvinuty s ohledem na skutečnost, že programy budou psány v jazyce C a po nahrání do jádra přeloženy do nativního kódu. Proto byl počet registrů a sada příkazů volena s ohledem na průnik, v matematickém smyslu, schopností moderních strojů. Na programy byla navíc uvalena různá omezení, například donedávna nebylo možné psát smyčky a podprogramy a počet instrukcí byl omezen na 4096 (nyní mohou privilegované programy načíst až milion instrukcí).
BPF má jedenáct uživatelsky přístupných 64bitových registrů r0-r10 a počítadlo programů. Registrovat r10 obsahuje ukazatel na rámec a je pouze pro čtení. Programy mají za běhu přístup k 512bajtovému zásobníku a neomezenému množství sdílené paměti ve formě map.
Programy BPF mohou spouštět specifickou sadu pomocných programů jádra a v poslední době i běžné funkce. Každá volaná funkce může mít až pět argumentů předávaných v registrech r1-r5a návratová hodnota je předána do r0. Je zaručeno, že po návratu z funkce se obsah registrů r6-r9 se nezmění.
Pro efektivní překlad programu, registry r0-r11 pro všechny podporované architektury jsou jedinečně mapovány na skutečné registry s přihlédnutím k funkcím ABI aktuální architektury. Například pro x86_64 registrů r1-r5, používané k předávání parametrů funkcí, jsou zobrazeny na rdi, rsi, rdx, rcx, r8, které se používají k předávání parametrů funkcím x86_64. Například kód vlevo se překládá na kód vpravo takto:
1: (b7) r1 = 1 mov $0x1,%rdi
2: (b7) r2 = 2 mov $0x2,%rsi
3: (b7) r3 = 3 mov $0x3,%rdx
4: (b7) r4 = 4 mov $0x4,%rcx
5: (b7) r5 = 5 mov $0x5,%r8
6: (85) call pc+1 callq 0x0000000000001ee8Registr r0 používá se také k vrácení výsledku provádění programu a v registru r1 programu je předán ukazatel na kontext - v závislosti na typu programu to může být například struktura (pro XDP) nebo strukturu (pro různé síťové programy) nebo strukturu (pro různé typy sledovacích programů) atd.
Měli jsme tedy sadu registrů, pomocníky jádra, zásobník, kontextový ukazatel a sdílenou paměť ve formě map. Ne že by tohle všechno bylo na výletě nezbytně nutné, ale...
Pokračujme v popisu a povíme si o příkazovém systému pro práci s těmito objekty. Všechno () Instrukce BPF mají pevnou 64bitovou velikost. Když se podíváte na jednu instrukci na 64bitovém stroji Big Endian, uvidíte
![]()
Zde Code - toto je kódování instrukce, Dst/Src jsou kódování přijímače a zdroje, resp. Off - 16bitové podepsané odsazení a Imm je 32bitové celé číslo se znaménkem používané v některých instrukcích (podobně jako cBPF konstanta K). Kódování Code má jeden ze dvou typů:
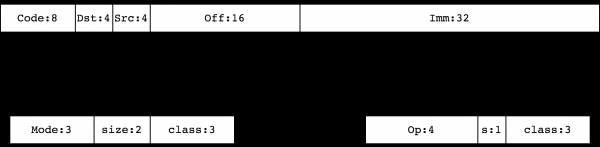
Třídy instrukcí 0, 1, 2, 3 definují příkazy pro práci s pamětí. Ony , BPF_LD, BPF_LDX, BPF_ST, BPF_STX, resp. Třídy 4, 7 (BPF_ALU, BPF_ALU64) tvoří soubor instrukcí ALU. Třídy 5, 6 (BPF_JMP, BPF_JMP32) obsahují instrukce skoku.
Další plán studia instrukčního systému BPF je následující: místo pečlivého vypisování všech instrukcí a jejich parametrů se v této části podíváme na několik příkladů a z nich bude zřejmé, jak instrukce vlastně fungují a jak ručně rozebrat jakýkoli binární soubor pro BPF. Pro konsolidaci materiálu dále v článku se s jednotlivými pokyny setkáme i v částech o Verifieru, JIT kompilátoru, překladu klasického BPF, ale i při studiu map, volání funkcí atp.
Když mluvíme o jednotlivých instrukcích, budeme odkazovat na základní soubory и , které definují číselné kódy instrukcí BPF. Při studiu architektury na vlastní pěst a/nebo analýze binárních souborů můžete najít sémantiku v následujících zdrojích seřazených podle složitosti: , , a samozřejmě i ve zdrojových kódech Linux — ověřovač, JIT, interpret BPF.
Příklad: rozebírání BPF v hlavě
Podívejme se na příklad, ve kterém sestavujeme program readelf-example.c a podívejte se na výslednou dvojhvězdu. Prozradíme původní obsah readelf-example.c níže, poté, co obnovíme jeho logiku z binárních kódů:
$ clang -target bpf -c readelf-example.c -o readelf-example.o -O2
$ llvm-readelf -x .text readelf-example.o
Hex dump of section '.text':
0x00000000 b7000000 01000000 15010100 00000000 ................
0x00000010 b7000000 02000000 95000000 00000000 ................První sloupec na výstupu readelf je odsazení a náš program se tedy skládá ze čtyř příkazů:
Code Dst Src Off Imm
b7 0 0 0000 01000000
15 0 1 0100 00000000
b7 0 0 0000 02000000
95 0 0 0000 00000000Kódy příkazů jsou stejné b7, 15, b7 и 95. Připomeňme, že nejméně významné tři bity jsou třída instrukce. V našem případě je čtvrtý bit všech instrukcí prázdný, takže třídy instrukcí jsou 7, 5, 7, 5. Třída 7 je BPF_ALU64a 5 je BPF_JMP. Pro obě třídy je formát instrukce stejný (viz výše) a náš program můžeme přepsat takto (současně přepíšeme zbývající sloupce do lidské podoby):
Op S Class Dst Src Off Imm
b 0 ALU64 0 0 0 1
1 0 JMP 0 1 1 0
b 0 ALU64 0 0 0 2
9 0 JMP 0 0 0 0Operace b třída ALU64 - Je . Přiřadí hodnotu cílovému registru. Pokud je bit nastaven s (source), pak se hodnota převezme ze zdrojového registru, a pokud jako v našem případě není nastavena, pak se hodnota převezme z pole Imm. Takže v prvním a třetím návodu provedeme operaci r0 = Imm. Dále provoz JMP třídy 1 je (skok, pokud se rovná). V našem případě od bit S je nula, porovnává hodnotu zdrojového registru s polem Imm. Pokud se hodnoty shodují, dojde k přechodu na PC + OffKde PCjako obvykle obsahuje adresu další instrukce. Konečně, JMP Class 9 Operation je . Tato instrukce ukončí program a vrátí se do jádra r0. Přidejme do naší tabulky nový sloupec:
Op S Class Dst Src Off Imm Disassm
MOV 0 ALU64 0 0 0 1 r0 = 1
JEQ 0 JMP 0 1 1 0 if (r1 == 0) goto pc+1
MOV 0 ALU64 0 0 0 2 r0 = 2
EXIT 0 JMP 0 0 0 0 exitMůžeme to přepsat do pohodlnějšího tvaru:
r0 = 1
if (r1 == 0) goto END
r0 = 2
END:
exitPokud si pamatujeme, co je v registru r1 programu je předán ukazatel na kontext z jádra a do registru r0 hodnota je vrácena jádru, pak můžeme vidět, že pokud je ukazatel na kontext nula, vrátíme 1 a jinak - 2. Zkontrolujeme, že máme pravdu, když se podíváme na zdroj:
$ cat readelf-example.c
int foo(void *ctx)
{
return ctx ? 2 : 1;
}Ano, je to nesmyslný program, ale převádí se do pouhých čtyř jednoduchých pokynů.
Příklad výjimky: 16bajtová instrukce
Již dříve jsme zmínili, že některé instrukce zabírají více než 64 bitů. Týká se to například návodu lddw (Kód = 0x18 = | | ) — načte dvojslovo z polí do registru Imm, Jde o to, že Imm má velikost 32 a dvojité slovo má 64 bitů, takže načtení 64bitové okamžité hodnoty do registru v jedné 64bitové instrukci nebude fungovat. K tomu slouží dvě sousední instrukce k uložení druhé části 64bitové hodnoty do pole Imm. Příklad:
$ cat x64.c
long foo(void *ctx)
{
return 0x11223344aabbccdd;
}
$ clang -target bpf -c x64.c -o x64.o -O2
$ llvm-readelf -x .text x64.o
Hex dump of section '.text':
0x00000000 18000000 ddccbbaa 00000000 44332211 ............D3".
0x00000010 95000000 00000000 ........V binárním programu jsou pouze dvě instrukce:
Binary Disassm
18000000 ddccbbaa 00000000 44332211 r0 = Imm[0]|Imm[1]
95000000 00000000 exitS instrukcemi se ještě setkáme lddw, když mluvíme o přesunech a práci s mapami.
Příklad: demontáž BPF pomocí standardních nástrojů
Naučili jsme se tedy číst binární kódy BPF a jsme připraveni v případě potřeby analyzovat jakoukoli instrukci. Je však třeba říci, že v praxi je pohodlnější a rychlejší rozebírat programy pomocí standardních nástrojů, například:
$ llvm-objdump -d x64.o
Disassembly of section .text:
0000000000000000 <foo>:
0: 18 00 00 00 dd cc bb aa 00 00 00 00 44 33 22 11 r0 = 1234605617868164317 ll
2: 95 00 00 00 00 00 00 00 exitŽivotní cyklus objektů BPF, souborový systém bpffs
(Některé podrobnosti popsané v této podsekci jsem se poprvé dozvěděl od Alexej Starovoitov v .)
BPF objekty - programy a mapy - jsou vytvářeny z uživatelského prostoru pomocí příkazů BPF_PROG_LOAD и BPF_MAP_CREATE systémové volání bpf(2), o tom, jak přesně k tomu dojde, si povíme v další části. Tím se vytvoří datové struktury jádra a pro každou z nich refcount (počet referencí) se nastaví na jedna a uživateli se vrátí deskriptor souboru ukazující na objekt. Po zavření rukojeti refcount objekt se zmenší o jedničku a když dosáhne nuly, objekt se zničí.
Pokud program používá mapy, pak refcount tyto mapy se po načtení programu zvětší o jedničku, tzn. jejich deskriptory souborů lze zavřít z uživatelského procesu a přesto refcount se nestane nulou:
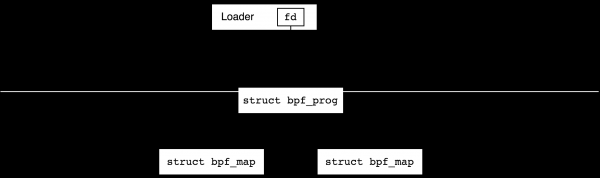
Po úspěšném načtení programu jej obvykle připojíme k nějakému generátoru událostí. Můžeme jej například umístit na síťové rozhraní pro zpracování příchozích paketů nebo jej k některým připojit tracepoint v jádru. V tomto okamžiku se také počítadlo referencí zvýší o jednu a budeme moci zavřít deskriptor souboru v programu loader.
Co se stane, když nyní bootloader vypneme? Záleží na typu generátoru událostí (háku). Všechny síťové háky budou existovat po dokončení zavaděče, jedná se o takzvané globální háky. A například trasovací programy budou uvolněny po ukončení procesu, který je vytvořil (a proto se nazývají místní, od „lokálního k procesu“). Technicky mají místní háky vždy odpovídající deskriptor souboru v uživatelském prostoru, a proto se zavřou, když je proces uzavřen, ale globální háky nikoli. Na následujícím obrázku se pomocí červených křížků snažím ukázat, jak ukončení programu loader ovlivňuje životnost objektů v případě lokálních a globálních háčků.
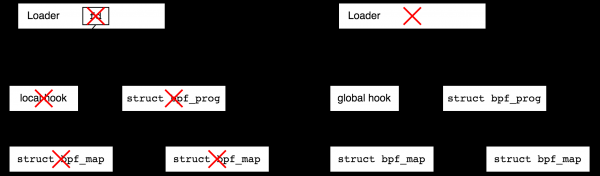
Proč se rozlišuje mezi lokálními a globálními háčky? Spouštění některých typů síťových programů má smysl bez uživatelského prostoru, představte si například DDoS ochranu – bootloader napíše pravidla a připojí program BPF k síťovému rozhraní, načež se bootloader může jít zabít. Na druhou stranu si představte ladící trasovací program, který jste napsali na koleně za deset minut – po jeho dokončení byste chtěli, aby v systému nezůstaly žádné smetí a místní háčky to zajistí.
Na druhou stranu si představte, že se chcete připojit ke sledovacímu bodu v jádře a sbírat statistiky po mnoho let. V tomto případě byste chtěli dokončit uživatelskou část a čas od času se vrátit ke statistikám. Souborový systém bpf tuto možnost poskytuje. Jedná se o systém pseudosouborů pouze v paměti, který umožňuje vytvářet soubory odkazující na objekty BPF, a tím zvyšovat refcount objektů. Poté může nakladač opustit a objekty, které vytvořil, zůstanou živé.
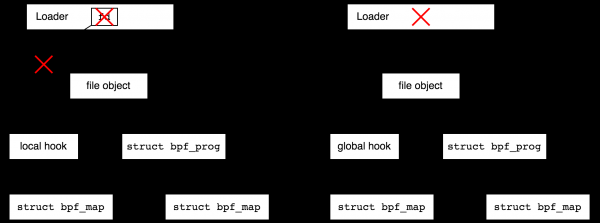
Vytváření souborů v bpffs, které odkazují na objekty BPF, se nazývá „připnutí“ (jako v následující frázi: „proces může připnout program nebo mapu BPF“). Vytváření souborových objektů pro BPF objekty má smysl nejen pro prodloužení životnosti lokálních objektů, ale také pro použitelnost globálních objektů – vrátíme-li se k příkladu s globálním DDoS ochranným programem, chceme mít možnost se přijít podívat na statistiky čas od času.
Souborový systém BPF je obvykle připojen /sys/fs/bpf, ale lze jej také namontovat lokálně, například takto:
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointNázvy systému souborů se vytvářejí pomocí příkazu BPF_OBJ_PIN Systémové volání BPF. Pro ilustraci si vezmeme program, zkompilujeme ho, nahrajeme a připneme bpffs. Náš program nedělá nic užitečného, pouze předkládáme kód, abyste si mohli příklad reprodukovat:
$ cat test.c
__attribute__((section("xdp"), used))
int test(void *ctx)
{
return 0;
}
char _license[] __attribute__((section("license"), used)) = "GPL";Pojďme tento program zkompilovat a vytvořit lokální kopii souborového systému bpffs:
$ clang -target bpf -c test.c -o test.o
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointNyní si stáhněte náš program pomocí nástroje bpftool a podívejte se na doprovodná systémová volání bpf(2) (z výstupu trace byly odstraněny některé irelevantní řádky):
$ sudo strace -e bpf bpftool prog load ./test.o bpf-mountpoint/test
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="test", ...}, 120) = 3
bpf(BPF_OBJ_PIN, {pathname="bpf-mountpoint/test", bpf_fd=3}, 120) = 0Zde jsme nahráli program pomocí BPF_PROG_LOAD, obdržel deskriptor souboru z jádra 3 a pomocí příkazu BPF_OBJ_PIN připnul tento deskriptor souboru jako soubor "bpf-mountpoint/test". Poté program bootloader bpftool dokončil práci, ale náš program zůstal v jádře, i když jsme jej nepřipojili k žádnému síťovému rozhraní:
$ sudo bpftool prog | tail -3
783: xdp name test tag 5c8ba0cf164cb46c gpl
loaded_at 2020-05-05T13:27:08+0000 uid 0
xlated 24B jited 41B memlock 4096BObjekt souboru můžeme normálně smazat unlink(2) a poté bude odpovídající program smazán:
$ sudo rm ./bpf-mountpoint/test
$ sudo bpftool prog show id 783
Error: get by id (783): No such file or directoryMazání objektů
Když už mluvíme o mazání objektů, je nutné upřesnit, že poté, co jsme odpojili program od háku (generátoru událostí), ani jedna nová událost nespustí jeho spuštění, ale všechny aktuální instance programu budou dokončeny v normálním pořadí. .
Některé typy programů BPF umožňují výměnu programu za chodu, tzn. poskytují sekvenční atomičnost replace = detach old program, attach new program. V tomto případě všechny aktivní instance staré verze programu dokončí svou práci a z nového programu se vytvoří nové obslužné rutiny událostí, přičemž „atomicita“ zde znamená, že nezmeškáte ani jednu událost.
Připojování programů ke zdrojům událostí
V tomto článku nebudeme samostatně popisovat připojení programů ke zdrojům událostí, protože má smysl to studovat v kontextu konkrétního typu programu. Cm. níže, ve kterém ukážeme, jak jsou programy jako XDP propojeny.
Manipulace s objekty pomocí systémového volání bpf
programy BPF
Všechny objekty BPF jsou vytvářeny a spravovány z uživatelského prostoru pomocí systémového volání bpf, který má následující prototyp:
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);Tady je tým cmd je jednou z hodnot typu , attr — ukazatel na parametry pro konkrétní program a size — velikost objektu podle ukazatele, tzn. obvykle toto sizeof(*attr). V jádře 5.8 systémové volání bpf podporuje 34 různých příkazů a union bpf_attr zabírá 200 řádků. Ale neměli bychom se toho zastrašit, protože s příkazy a parametry se seznámíme v průběhu několika článků.
Začněme týmem BPF_PROG_LOAD, který vytváří BPF programy - vezme sadu BPF instrukcí a nahraje ji do jádra. V okamžiku načtení se spustí ověřovač a následně se uživateli vrátí kompilátor JIT a po úspěšném spuštění deskriptor souboru programu. Co se s ním stane dál, jsme viděli v předchozí části .
Nyní napíšeme vlastní program, který načte jednoduchý program BPF, ale nejprve se musíme rozhodnout, jaký druh programu chceme načíst - budeme muset vybrat a v rámci tohoto typu napsat program, který projde ověřovacím testem. Abychom však proces nekomplikovali, zde je hotové řešení: vezmeme program jako BPF_PROG_TYPE_XDP, který vrátí hodnotu XDP_PASS (přeskočit všechny balíčky). V assembleru BPF to vypadá velmi jednoduše:
r0 = 2
exitPoté, co jsme se rozhodli že nahrajeme, můžeme vám říct, jak to uděláme:
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
static inline __u64 ptr_to_u64(const void *ptr)
{
return (__u64) (unsigned long) ptr;
}
int main(void)
{
struct bpf_insn insns[] = {
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_0,
.imm = XDP_PASS
},
{
.code = BPF_JMP | BPF_EXIT
},
};
union bpf_attr attr = {
.prog_type = BPF_PROG_TYPE_XDP,
.insns = ptr_to_u64(insns),
.insn_cnt = sizeof(insns)/sizeof(insns[0]),
.license = ptr_to_u64("GPL"),
};
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
for ( ;; )
pause();
}Zajímavé události v programu začínají definicí pole insns - náš program BPF ve strojovém kódu. V tomto případě je každá instrukce programu BPF zabalena do struktury . První prvek insns vyhovuje pokynům r0 = 2, druhý - exit.
Ústraní. Jádro definuje pohodlnější makra pro psaní strojových kódů a používání hlavičkového souboru jádra tools/include/linux/filter.h mohli bychom psát
struct bpf_insn insns[] = {
BPF_MOV64_IMM(BPF_REG_0, XDP_PASS),
BPF_EXIT_INSN()
};Jelikož je ale psaní BPF programů v nativním kódu nutné pouze pro psaní testů v jádře a článků o BPF, absence těchto maker život vývojářům opravdu nekomplikuje.
Po definování programu BPF přejdeme k jeho nahrání do jádra. Naše minimalistická sada parametrů attr obsahuje typ programu, sadu a počet instrukcí, požadovanou licenci a název "woo", který používáme k nalezení našeho programu v systému po stažení. Program, jak bylo slíbeno, se nahraje do systému pomocí systémového volání bpf.
Na konci programu skončíme v nekonečné smyčce, která simuluje užitečné zatížení. Bez něj bude program zabit jádrem, když se zavře deskriptor souboru, který nám systémové volání vrátilo bpf, a v systému to neuvidíme.
No, jsme připraveni na testování. Pojďme sestavit a spustit program pod stracepro kontrolu, zda vše funguje jak má:
$ clang -g -O2 simple-prog.c -o simple-prog
$ sudo strace ./simple-prog
execve("./simple-prog", ["./simple-prog"], 0x7ffc7b553480 /* 13 vars */) = 0
...
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0x7ffe03c4ed50, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_V
ERSION(0, 0, 0), prog_flags=0, prog_name="woo", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS}, 72) = 3
pause(Vše je v pořádku, bpf(2) vrátil nám rukojeť 3 a šli jsme do nekonečné smyčky pause(). Zkusme v systému najít náš program. K tomu přejdeme na jiný terminál a použijeme nástroj bpftool:
# bpftool prog | grep -A3 woo
390: xdp name woo tag 3b185187f1855c4c gpl
loaded_at 2020-08-31T24:66:44+0000 uid 0
xlated 16B jited 40B memlock 4096B
pids simple-prog(10381)Vidíme, že v systému je načtený program woo jehož globální ID je 390 a právě probíhá simple-prog existuje otevřený deskriptor souboru ukazující na program (a if simple-prog pak dokončí práci woo zmizí). Podle očekávání program woo bere 16 bajtů - dvě instrukce - binárních kódů v architektuře BPF, ale v nativní podobě (x86_64) je to již 40 bajtů. Podívejme se na náš program v původní podobě:
# bpftool prog dump xlated id 390
0: (b7) r0 = 2
1: (95) exitžádné překvapení. Nyní se podívejme na kód generovaný kompilátorem JIT:
# bpftool prog dump jited id 390
bpf_prog_3b185187f1855c4c_woo:
0: nopl 0x0(%rax,%rax,1)
5: push %rbp
6: mov %rsp,%rbp
9: sub $0x0,%rsp
10: push %rbx
11: push %r13
13: push %r14
15: push %r15
17: pushq $0x0
19: mov $0x2,%eax
1e: pop %rbx
1f: pop %r15
21: pop %r14
23: pop %r13
25: pop %rbx
26: leaveq
27: retqnení příliš efektivní pro exit(2), ale spravedlivě je náš program příliš jednoduchý a pro netriviální programy je samozřejmě potřeba prolog a epilog přidaný kompilátorem JIT.
Mapy
Programy BPF mohou využívat strukturované paměťové oblasti, které jsou přístupné jak jiným programům BPF, tak programům v uživatelském prostoru. Tyto objekty se nazývají mapy a v této části si ukážeme, jak s nimi manipulovat pomocí systémového volání bpf.
Řekněme si hned, že možnosti map se neomezují pouze na přístup ke sdílené paměti. Existují účelové mapy obsahující např. ukazatele na programy BPF nebo ukazatele na síťová rozhraní, mapy pro práci s událostmi perf atp. Nebudeme se zde o nich bavit, abychom čtenáře nepletli. Kromě toho ignorujeme problémy se synchronizací, protože to není pro naše příklady důležité. Kompletní seznam dostupných typů map naleznete v , a v této části si vezmeme jako příklad historicky první typ, hashovací tabulku BPF_MAP_TYPE_HASH.
Řekli byste, že pokud vytvoříte hashovací tabulku v, řekněme, C++ unordered_map<int,long> woo, což v ruštině znamená „Potřebuji stůl woo neomezená velikost, jejichž klíče jsou typu inta hodnoty jsou typem long" Abychom vytvořili hashovací tabulku BPF, musíme udělat v podstatě totéž, kromě toho, že musíme určit maximální velikost tabulky a místo určení typů klíčů a hodnot musíme zadat jejich velikosti v bajtech. . Chcete-li vytvořit mapy, použijte příkaz BPF_MAP_CREATE systémové volání bpf. Podívejme se na víceméně minimální program, který vytváří mapu. Po předchozím programu, který načítá programy BPF, by se vám tento měl zdát jednoduchý:
$ cat simple-map.c
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
int main(void)
{
union bpf_attr attr = {
.map_type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 4,
};
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
for ( ;; )
pause();
}Zde definujeme sadu parametrů attr, ve kterém říkáme „Potřebuji hashovací tabulku s klíči a hodnotami velikosti sizeof(int), do kterého mohu dát maximálně čtyři prvky.“ Při vytváření BPF map můžete zadat další parametry, např. stejně jako v příkladu s programem jsme zadali název objektu jako "woo".
Pojďme zkompilovat a spustit program:
$ clang -g -O2 simple-map.c -o simple-map
$ sudo strace ./simple-map
execve("./simple-map", ["./simple-map"], 0x7ffd40a27070 /* 14 vars */) = 0
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=4, max_entries=4, map_name="woo", ...}, 72) = 3
pause(Zde je systémové volání bpf(2) nám vrátilo číslo deskriptorové mapy 3 a poté program podle očekávání čeká na další pokyny v systémovém volání pause(2).
Nyní odešleme náš program na pozadí nebo otevřeme jiný terminál a podíváme se na náš objekt pomocí utility bpftool (naši mapu můžeme odlišit od ostatních podle názvu):
$ sudo bpftool map
...
114: hash name woo flags 0x0
key 4B value 4B max_entries 4 memlock 4096B
...Číslo 114 je globální ID našeho objektu. Jakýkoli program v systému může použít toto ID k otevření existující mapy pomocí příkazu BPF_MAP_GET_FD_BY_ID systémové volání bpf.
Nyní si můžeme hrát s naší hashovací tabulkou. Podívejme se na jeho obsah:
$ sudo bpftool map dump id 114
Found 0 elementsPrázdný. Dejme tomu hodnotu hash[1] = 1:
$ sudo bpftool map update id 114 key 1 0 0 0 value 1 0 0 0Podívejme se znovu na tabulku:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
Found 1 elementHurá! Podařilo se nám přidat jeden prvek. Všimněte si, že k tomu musíme pracovat na úrovni bajtů, protože bptftool neví, jaký typ jsou hodnoty v hash tabulce. (Tyto znalosti na ni lze přenést pomocí BTF, ale o tom nyní.)
Jak přesně bpftool čte a přidává prvky? Pojďme se podívat pod pokličku:
$ sudo strace -e bpf bpftool map dump id 114
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=0x55856ab65280}, 120) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0x55856ab65280, value=0x55856ab652a0}, 120) = 0
key: 01 00 00 00 value: 01 00 00 00
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0x55856ab65280, next_key=0x55856ab65280}, 120) = -1 ENOENTNejprve jsme pomocí příkazu otevřeli mapu podle jejího globálního ID BPF_MAP_GET_FD_BY_ID и bpf(2) nám vrátil deskriptor 3. Dále pomocí příkazu BPF_MAP_GET_NEXT_KEY průchodem jsme našli první klíč v tabulce NULL jako ukazatel na "předchozí" klíč. Pokud máme klíč, můžeme to udělat BPF_MAP_LOOKUP_ELEMkterý vrací hodnotu ukazateli value. Dalším krokem je pokusit se najít další prvek předáním ukazatele na aktuální klíč, ale naše tabulka obsahuje pouze jeden prvek a příkaz BPF_MAP_GET_NEXT_KEY se vrací ENOENT.
Dobře, změňme hodnotu klíčem 1, řekněme, že naše obchodní logika vyžaduje registraci hash[1] = 2:
$ sudo strace -e bpf bpftool map update id 114 key 1 0 0 0 value 2 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x55dcd72be260, value=0x55dcd72be280, flags=BPF_ANY}, 120) = 0Jak se dalo očekávat, je to velmi jednoduché: příkaz BPF_MAP_GET_FD_BY_ID otevře naši mapu podle ID a příkazu BPF_MAP_UPDATE_ELEM přepíše prvek.
Takže po vytvoření hash tabulky z jednoho programu můžeme číst a zapisovat její obsah z jiného. Všimněte si, že pokud jsme to byli schopni udělat z příkazového řádku, pak to může udělat jakýkoli jiný program v systému. Kromě výše popsaných příkazů pro práci s mapami z uživatelského prostoru, :
BPF_MAP_LOOKUP_ELEM: najít hodnotu pomocí klíčeBPF_MAP_UPDATE_ELEM: aktualizovat/vytvořit hodnotuBPF_MAP_DELETE_ELEM: vyjměte klíčBPF_MAP_GET_NEXT_KEY: najít další (nebo první) klíčBPF_MAP_GET_NEXT_ID: umožňuje procházet všechny existující mapy, tak to fungujebpftool mapBPF_MAP_GET_FD_BY_ID: otevřít existující mapu podle jejího globálního IDBPF_MAP_LOOKUP_AND_DELETE_ELEM: atomicky aktualizuje hodnotu objektu a vrací starouBPF_MAP_FREEZE: učinit mapu neměnnou z uživatelského prostoru (tuto operaci nelze vrátit zpět)BPF_MAP_LOOKUP_BATCH,BPF_MAP_LOOKUP_AND_DELETE_BATCH,BPF_MAP_UPDATE_BATCH,BPF_MAP_DELETE_BATCH: hromadné operace. Například,BPF_MAP_LOOKUP_AND_DELETE_BATCH- toto je jediný spolehlivý způsob, jak číst a resetovat všechny hodnoty z mapy
Ne všechny tyto příkazy fungují pro všechny typy map, ale obecně práce s jinými typy map z uživatelského prostoru vypadá úplně stejně jako práce s hashovacími tabulkami.
Pro pořádek ukončíme experimenty s hashovacími tabulkami. Pamatujete si, že jsme vytvořili tabulku, která může obsahovat až čtyři klíče? Přidejme ještě několik prvků:
$ sudo bpftool map update id 114 key 2 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 3 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 4 0 0 0 value 1 0 0 0Zatím je vše dobré:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
key: 02 00 00 00 value: 01 00 00 00
key: 04 00 00 00 value: 01 00 00 00
key: 03 00 00 00 value: 01 00 00 00
Found 4 elementsZkusme přidat ještě jeden:
$ sudo bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
Error: update failed: Argument list too longPodle očekávání se nám to nepovedlo. Podívejme se na chybu podrobněji:
$ sudo strace -e bpf bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, info_len=80, info=0x7ffe6c626da0}}, 120) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x56049ded5260, value=0x56049ded5280, flags=BPF_ANY}, 120) = -1 E2BIG (Argument list too long)
Error: update failed: Argument list too long
+++ exited with 255 +++Všechno je v pořádku: podle očekávání tým BPF_MAP_UPDATE_ELEM pokusí se vytvořit nový, pátý klíč, ale zhroutí se E2BIG.
Můžeme tedy vytvářet a načítat programy BPF, stejně jako vytvářet a spravovat mapy z uživatelského prostoru. Nyní je logické podívat se na to, jak můžeme použít mapy ze samotných programů BPF. Mohli bychom o tom mluvit jazykem těžko čitelných programů v kódech strojových maker, ale ve skutečnosti nastal čas ukázat, jak se programy BPF skutečně píší a udržují – pomocí libbpf.
(Pro čtenáře, kteří nejsou spokojeni s tím, že chybí nízkoúrovňový příklad: podrobně rozebereme programy, které využívají mapy a pomocné funkce vytvořené pomocí libbpf a řeknou vám, co se děje na úrovni výuky. Pro čtenáře, kteří jsou nespokojení moc, dodali jsme na příslušném místě v článku.)
Psaní BPF programů pomocí libbpf
Psaní programů BPF pomocí strojových kódů může být zajímavé jen napoprvé a pak se dostaví sytost. V tuto chvíli musíte obrátit svou pozornost llvm, který má backend pro generování kódu pro architekturu BPF a také knihovnu libbpf, který umožňuje psát uživatelskou stránku aplikací BPF a načítat kód programů BPF generovaných pomocí llvm/clang.
Ve skutečnosti, jak uvidíme v tomto a následujících článcích, libbpf dělá docela dost práce bez něj (nebo podobných nástrojů - iproute2, libbcc, libbpf-goatd.) nelze žít. Jedna ze zabijáckých vlastností projektu libbpf je BPF CO-RE (Compile Once, Run Everywhere) – projekt, který umožňuje psát programy BPF, které jsou přenosné z jednoho jádra do druhého, se schopností běžet na různých API (například když se struktura jádra změní od verze na verzi). Abyste mohli pracovat s CO-RE, musí být vaše jádro zkompilováno s podporou BTF (jak to udělat, popisujeme v sekci . Zda je vaše jádro sestaveno s BTF nebo ne, můžete zkontrolovat velmi jednoduše – přítomností následujícího souboru:
$ ls -lh /sys/kernel/btf/vmlinux
-r--r--r-- 1 root root 2.6M Jul 29 15:30 /sys/kernel/btf/vmlinuxTento soubor uchovává informace o všech typech dat používaných v jádře a používá se ve všech našich příkladech použití libbpf. O CO-RE budeme hovořit podrobně v příštím článku, ale v tomto - stačí si vytvořit jádro pomocí CONFIG_DEBUG_INFO_BTF.
knihovna libbpf bydlí přímo v adresáři tools/lib/bpf kernel a jeho vývoj probíhá prostřednictvím mailing listu bpf@vger.kernel.org. Pro potřeby aplikací žijících mimo jádro je však udržováno samostatné úložiště ve kterém je knihovna jádra zrcadlena pro přístup ke čtení víceméně tak, jak je.
V této části se podíváme na to, jak můžete vytvořit projekt, který používá libbpf, pojďme napsat několik (víceméně nesmyslných) testovacích programů a podrobně rozebrat, jak to celé funguje. To nám umožní v následujících částech snadněji vysvětlit, jak přesně programy BPF interagují s mapami, pomocníky jádra, BTF atd.
Typicky projekty využívající libbpf přidejte úložiště GitHub jako submodul git, uděláme totéž:
$ mkdir /tmp/libbpf-example
$ cd /tmp/libbpf-example/
$ git init-db
Initialized empty Git repository in /tmp/libbpf-example/.git/
$ git submodule add https://github.com/libbpf/libbpf.git
Cloning into '/tmp/libbpf-example/libbpf'...
remote: Enumerating objects: 200, done.
remote: Counting objects: 100% (200/200), done.
remote: Compressing objects: 100% (103/103), done.
remote: Total 3354 (delta 101), reused 118 (delta 79), pack-reused 3154
Receiving objects: 100% (3354/3354), 2.05 MiB | 10.22 MiB/s, done.
Resolving deltas: 100% (2176/2176), done.Chystat se libbpf velmi jednoduché:
$ cd libbpf/src
$ mkdir build
$ OBJDIR=build DESTDIR=root make -s install
$ find root
root
root/usr
root/usr/include
root/usr/include/bpf
root/usr/include/bpf/bpf_tracing.h
root/usr/include/bpf/xsk.h
root/usr/include/bpf/libbpf_common.h
root/usr/include/bpf/bpf_endian.h
root/usr/include/bpf/bpf_helpers.h
root/usr/include/bpf/btf.h
root/usr/include/bpf/bpf_helper_defs.h
root/usr/include/bpf/bpf.h
root/usr/include/bpf/libbpf_util.h
root/usr/include/bpf/libbpf.h
root/usr/include/bpf/bpf_core_read.h
root/usr/lib64
root/usr/lib64/libbpf.so.0.1.0
root/usr/lib64/libbpf.so.0
root/usr/lib64/libbpf.a
root/usr/lib64/libbpf.so
root/usr/lib64/pkgconfig
root/usr/lib64/pkgconfig/libbpf.pcNáš další plán v této sekci je následující: napíšeme program typu BPF BPF_PROG_TYPE_XDP, stejně jako v předchozím příkladu, ale v C jej zkompilujeme pomocí clanga napište pomocný program, který jej nahraje do jádra. V následujících částech rozšíříme možnosti jak programu BPF, tak programu asistenta.
Příklad: vytvoření plnohodnotné aplikace pomocí libbpf
Pro začátek použijeme soubor /sys/kernel/btf/vmlinux, který byl zmíněn výše, a vytvořte jeho ekvivalent ve formě hlavičkového souboru:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.hTento soubor bude ukládat všechny datové struktury dostupné v našem jádře, například takto je v jádře definována hlavička IPv4:
$ grep -A 12 'struct iphdr {' vmlinux.h
struct iphdr {
__u8 ihl: 4;
__u8 version: 4;
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
};Nyní napíšeme náš BPF program v C:
$ cat xdp-simple.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Přestože se náš program ukázal jako velmi jednoduchý, stále je třeba věnovat pozornost mnoha detailům. Za prvé, první soubor záhlaví, který zahrneme, je vmlinux.h, který jsme právě vygenerovali pomocí bpftool btf dump - nyní nepotřebujeme instalovat balíček kernel-headers, abychom zjistili, jak vypadají struktury jádra. Následující hlavičkový soubor k nám přichází z knihovny libbpf. Nyní jej potřebujeme pouze k definování makra SEC, který odešle znak do příslušné části souboru objektu ELF. Náš program je obsažen v sekci xdp/simple, kde před lomítkem definujeme typ programu BPF - to je konvence používaná v libbpf, na základě názvu sekce nahradí správný typ při spuštění bpf(2). Samotný program BPF je C - velmi jednoduchý a skládá se z jednoho řádku return XDP_PASS. Na závěr samostatná sekce "license" obsahuje název licence.
Náš program můžeme zkompilovat pomocí llvm/clang, verze >= 10.0.0 nebo ještě lépe vyšší (viz část ):
$ clang --version
clang version 11.0.0 (https://github.com/llvm/llvm-project.git afc287e0abec710398465ee1f86237513f2b5091)
...
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.oMezi zajímavé funkce: uvádíme cílovou architekturu -target bpf a cestu k hlavičkám libbpf, který jsme nedávno nainstalovali. Také nezapomeňte na -O2, bez této možnosti vás možná v budoucnu čeká překvapení. Podívejme se na náš kód, podařilo se nám napsat program, který jsme chtěli?
$ llvm-objdump --section=xdp/simple --no-show-raw-insn -D xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: r0 = 2
1: exitAno, povedlo se! Nyní máme binární soubor s programem a chceme vytvořit aplikaci, která jej načte do jádra. Za tímto účelem knihovna libbpf nám nabízí dvě možnosti – použít API nižší úrovně nebo API vyšší úrovně. My půjdeme druhou cestou, jelikož se chceme naučit psát, načítat a propojovat BPF programy s minimální námahou pro jejich následné studium.
Nejprve musíme vygenerovat „kostru“ našeho programu z jeho binárního souboru pomocí stejného nástroje bpftool — švýcarský nůž ze světa BPF (což lze brát doslova, protože Daniel Borkman, jeden z tvůrců a správců BPF, je Švýcar):
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.hV souboru xdp-simple.skel.h obsahuje binární kód našeho programu a funkce pro správu - načítání, připojování, mazání našeho objektu. V našem jednoduchém případě to vypadá přehnaně, ale funguje to i v případě, kdy objektový soubor obsahuje mnoho BPF programů a map a k načtení tohoto obřího ELFu nám stačí vygenerovat kostru a zavolat jednu nebo dvě funkce z vlastní aplikace, kterou píšou Pojďme teď dál.
Přísně vzato, náš program načítání je triviální:
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
pause();
xdp_simple_bpf__destroy(obj);
}Zde struct xdp_simple_bpf definované v souboru xdp-simple.skel.h a popisuje náš objektový soubor:
struct xdp_simple_bpf {
struct bpf_object_skeleton *skeleton;
struct bpf_object *obj;
struct {
struct bpf_program *simple;
} progs;
struct {
struct bpf_link *simple;
} links;
};Zde můžeme vidět stopy nízkoúrovňového API: struktura struct bpf_program *simple и struct bpf_link *simple. První struktura konkrétně popisuje náš program, napsaný v sekci xdp/simplea druhý popisuje, jak se program připojuje ke zdroji události.
Funkce xdp_simple_bpf__open_and_load, otevře objekt ELF, analyzuje jej, vytvoří všechny struktury a podstruktury (kromě programu ELF obsahuje i další sekce - data, data pouze pro čtení, ladicí informace, licenci atd.) a poté jej pomocí systému načte do jádra volání bpf, což můžeme zkontrolovat kompilací a spuštěním programu:
$ clang -O2 -I ./libbpf/src/root/usr/include/ xdp-simple.c -o xdp-simple ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_BTF_LOAD, 0x7ffdb8fd9670, 120) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0xdfd580, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 8, 0), prog_flags=0, prog_name="simple", prog_ifindex=0, expected_attach_type=0x25 /* BPF_??? */, ...}, 120) = 4Podívejme se nyní na náš program pomocí bpftool. Pojďme najít její ID:
# bpftool p | grep -A4 simple
463: xdp name simple tag 3b185187f1855c4c gpl
loaded_at 2020-08-01T01:59:49+0000 uid 0
xlated 16B jited 40B memlock 4096B
btf_id 185
pids xdp-simple(16498)a dump (používáme zkrácenou formu příkazu bpftool prog dump xlated):
# bpftool p d x id 463
int simple(void *ctx):
; return XDP_PASS;
0: (b7) r0 = 2
1: (95) exitNěco nového! Program vytiskl části našeho zdrojového souboru C. To provedla knihovna libbpf, který našel sekci ladění v binárním kódu, zkompiloval ji do objektu BTF a nahrál do jádra pomocí BPF_BTF_LOADa poté určil výsledný deskriptor souboru při načítání programu pomocí příkazu BPG_PROG_LOAD.
Pomocníci jádra
Programy BPF mohou spouštět „externí“ funkce – pomocníky jádra. Tyto pomocné funkce umožňují programům BPF přistupovat ke strukturám jádra, spravovat mapy a také komunikovat se „skutečným světem“ – vytvářet události výkonu, ovládat hardware (například přesměrování paketů) atd.
Příklad: bpf_get_smp_processor_id
V rámci paradigmatu „učení příkladem“ uvažujme jednu z pomocných funkcí, bpf_get_smp_processor_id(), v souboru kernel/bpf/helpers.c. Vrací číslo procesoru, na kterém běží program BPF, který jej volal. Nás ale ani tak nezajímá jeho sémantika, jako spíše to, že jeho implementace trvá jednu linii:
BPF_CALL_0(bpf_get_smp_processor_id)
{
return smp_processor_id();
}Definice pomocných funkcí BPF jsou podobné definicím systémových volání. LinuxZde je například definována funkce, která nemá žádné argumenty. (Funkce, která například přijímá tři argumenty, je definována pomocí makra BPF_CALL_3. Maximální počet argumentů je pět.) Toto je však pouze první část definice. Druhou částí je definování typové struktury struct bpf_func_proto, který obsahuje popis pomocné funkce, které ověřovatel rozumí:
const struct bpf_func_proto bpf_get_smp_processor_id_proto = {
.func = bpf_get_smp_processor_id,
.gpl_only = false,
.ret_type = RET_INTEGER,
};Registrace pomocných funkcí
Aby programy BPF konkrétního typu mohly tuto funkci používat, musí ji zaregistrovat, například pro typ BPF_PROG_TYPE_XDP funkce je definována v jádře xdp_func_proto, který z ID pomocné funkce určí, zda XDP tuto funkci podporuje či nikoli. Naše funkce je :
static const struct bpf_func_proto *
xdp_func_proto(enum bpf_func_id func_id, const struct bpf_prog *prog)
{
switch (func_id) {
...
case BPF_FUNC_get_smp_processor_id:
return &bpf_get_smp_processor_id_proto;
...
}
}V souboru jsou „definovány“ nové typy programů BPF pomocí makra BPF_PROG_TYPE. Definováno v uvozovkách, protože jde o logickou definici, a v pojmech jazyka C se definice celé sady betonových konstrukcí vyskytuje na jiných místech. Zejména ve spisu kernel/bpf/verifier.c všechny definice ze souboru bpf_types.h se používají k vytvoření řady struktur bpf_verifier_ops[]:
static const struct bpf_verifier_ops *const bpf_verifier_ops[] = {
#define BPF_PROG_TYPE(_id, _name, prog_ctx_type, kern_ctx_type)
[_id] = & _name ## _verifier_ops,
#include <linux/bpf_types.h>
#undef BPF_PROG_TYPE
};To znamená, že pro každý typ programu BPF je definován ukazatel na datovou strukturu daného typu struct bpf_verifier_ops, která je inicializována hodnotou _name ## _verifier_ops, tj., xdp_verifier_ops pro xdp. Struktura xdp_verifier_ops v souboru net/core/filter.c takto:
const struct bpf_verifier_ops xdp_verifier_ops = {
.get_func_proto = xdp_func_proto,
.is_valid_access = xdp_is_valid_access,
.convert_ctx_access = xdp_convert_ctx_access,
.gen_prologue = bpf_noop_prologue,
};Zde vidíme naši známou funkci xdp_func_proto, který spustí ověřovač pokaždé, když narazí na výzvu nějaký druh funkce uvnitř programu BPF, viz .
Podívejme se, jak hypotetický program BPF využívá funkci bpf_get_smp_processor_id. Za tímto účelem přepíšeme program z naší předchozí části takto:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
if (bpf_get_smp_processor_id() != 0)
return XDP_DROP;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Symbol bpf_get_smp_processor_id в <bpf/bpf_helper_defs.h> knihovna libbpf как
static u32 (*bpf_get_smp_processor_id)(void) = (void *) 8;to znamená, bpf_get_smp_processor_id je ukazatel funkce, jehož hodnota je 8, kde 8 je hodnota BPF_FUNC_get_smp_processor_id typ enum bpf_fun_id, který je pro nás definován v souboru vmlinux.h (soubor bpf_helper_defs.h v jádře je generován skriptem, takže „magická“ čísla jsou v pořádku). Tato funkce nebere žádné argumenty a vrací hodnotu typu __u32. Když to spustíme v našem programu, clang vygeneruje pokyn BPF_CALL "správný druh" Pojďme sestavit program a podívat se na sekci xdp/simple:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ llvm-objdump -D --section=xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: bf 01 00 00 00 00 00 00 r1 = r0
2: 67 01 00 00 20 00 00 00 r1 <<= 32
3: 77 01 00 00 20 00 00 00 r1 >>= 32
4: b7 00 00 00 02 00 00 00 r0 = 2
5: 15 01 01 00 00 00 00 00 if r1 == 0 goto +1 <LBB0_2>
6: b7 00 00 00 01 00 00 00 r0 = 1
0000000000000038 <LBB0_2>:
7: 95 00 00 00 00 00 00 00 exitV prvním řádku vidíme instrukce call, parametr IMM což se rovná 8 a SRC_REG - nula. Podle dohody ABI používané ověřovatelem se jedná o volání pomocné funkce číslo osm. Po spuštění je logika jednoduchá. Návratová hodnota z registru r0 zkopírován do r1 a na řádcích 2,3 je převeden na typ u32 — horních 32 bitů se vymaže. Na řádcích 4,5,6,7 vrátíme 2 (XDP_PASS) nebo 1 (XDP_DROP) podle toho, zda pomocná funkce z řádku 0 vrátila nulovou nebo nenulovou hodnotu.
Pojďme se otestovat: načtěte program a podívejte se na výstup bpftool prog dump xlated:
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simple &
[2] 10914
$ sudo bpftool p | grep simple
523: xdp name simple tag 44c38a10c657e1b0 gpl
pids xdp-simple(10915)
$ sudo bpftool p d x id 523
int simple(void *ctx):
; if (bpf_get_smp_processor_id() != 0)
0: (85) call bpf_get_smp_processor_id#114128
1: (bf) r1 = r0
2: (67) r1 <<= 32
3: (77) r1 >>= 32
4: (b7) r0 = 2
; }
5: (15) if r1 == 0x0 goto pc+1
6: (b7) r0 = 1
7: (95) exitOk, ověřovatel našel správného pomocníka jádra.
Příklad: předání argumentů a konečně spuštění programu!
Všechny pomocné funkce na úrovni běhu mají prototyp
u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5)Parametry pomocným funkcím se předávají v registrech r1-r5a hodnota se vrátí do registru r0. Neexistují žádné funkce, které vyžadují více než pět argumentů, a neočekává se, že by jejich podpora byla v budoucnu přidána.
Pojďme se podívat na nového pomocníka jádra a na to, jak BPF předává parametry. Pojďme přepsat xdp-simple.bpf.c následovně (zbytek řádků se nezměnil):
SEC("xdp/simple")
int simple(void *ctx)
{
bpf_printk("running on CPU%un", bpf_get_smp_processor_id());
return XDP_PASS;
}Náš program vypíše číslo CPU, na kterém běží. Pojďme to zkompilovat a podívat se na kód:
$ llvm-objdump -D --section=xdp/simple --no-show-raw-insn xdp-simple.bpf.o
0000000000000000 <simple>:
0: r1 = 10
1: *(u16 *)(r10 - 8) = r1
2: r1 = 8441246879787806319 ll
4: *(u64 *)(r10 - 16) = r1
5: r1 = 2334956330918245746 ll
7: *(u64 *)(r10 - 24) = r1
8: call 8
9: r1 = r10
10: r1 += -24
11: r2 = 18
12: r3 = r0
13: call 6
14: r0 = 2
15: exitNa řádky 0-7 zapíšeme řetězec running on CPU%un, a pak na lince 8 spustíme ten známý bpf_get_smp_processor_id. Na řádcích 9-12 připravíme pomocné argumenty bpf_printk - registry r1, r2, r3. Proč jsou tři a ne dva? Protože bpf_printk - kolem skutečného pomocníka bpf_trace_printk, který potřebuje předat velikost formátovacího řetězce.
Nyní přidáme pár řádků xdp-simple.caby se náš program připojil k rozhraní lo a pořádně to začalo!
$ cat xdp-simple.c
#include <linux/if_link.h>
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
__u32 flags = XDP_FLAGS_SKB_MODE;
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
bpf_set_link_xdp_fd(1, -1, flags);
bpf_set_link_xdp_fd(1, bpf_program__fd(obj->progs.simple), flags);
cleanup:
xdp_simple_bpf__destroy(obj);
}Zde použijeme funkci bpf_set_link_xdp_fd, který připojuje programy BPF typu XDP k síťovým rozhraním. Napevno jsme zakódovali číslo rozhraní lo, což je vždy 1. Funkci spustíme dvakrát, abychom nejprve odpojili starý program, pokud byl připojen. Všimněte si, že teď nepotřebujeme žádnou výzvu pause nebo nekonečná smyčka: náš zavaděč se ukončí, ale program BPF nebude ukončen, protože je připojen ke zdroji události. Po úspěšném stažení a připojení se program spustí pro každý příchozí síťový paket lo.
Pojďme si stáhnout program a podívat se na rozhraní lo:
$ sudo ./xdp-simple
$ sudo bpftool p | grep simple
669: xdp name simple tag 4fca62e77ccb43d6 gpl
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 669Program, který jsme stáhli, má ID 669 a na rozhraní vidíme stejné ID lo. Pošleme vám několik balíčků 127.0.0.1 (žádost + odpověď):
$ ping -c1 localhosta nyní se podíváme na obsah ladícího virtuálního souboru /sys/kernel/debug/tracing/trace_pipe, ve kterém bpf_printk píše své zprávy:
# cat /sys/kernel/debug/tracing/trace_pipe
ping-13937 [000] d.s1 442015.377014: bpf_trace_printk: running on CPU0
ping-13937 [000] d.s1 442015.377027: bpf_trace_printk: running on CPU0Byly spatřeny dva balíčky lo a zpracováno na CPU0 - náš první plnohodnotný nesmyslný BPF program fungoval!
Stojí za zmínku bpf_printk Ne nadarmo se zapisuje do ladicího souboru: není to nejúspěšnější pomocník pro použití v produkci, ale naším cílem bylo ukázat něco jednoduchého.
Přístup k mapám z programů BPF
Příklad: použití mapy z programu BPF
V předchozích částech jsme se naučili vytvářet a používat mapy z uživatelského prostoru a nyní se podíváme na část jádra. Začněme jako obvykle příkladem. Pojďme přepsat náš program xdp-simple.bpf.c takto:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 8);
__type(key, u32);
__type(value, u64);
} woo SEC(".maps");
SEC("xdp/simple")
int simple(void *ctx)
{
u32 key = bpf_get_smp_processor_id();
u32 *val;
val = bpf_map_lookup_elem(&woo, &key);
if (!val)
return XDP_ABORTED;
*val += 1;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Na začátku programu jsme přidali definici mapy woo: Toto je 8prvkové pole, které ukládá hodnoty jako u64 (v C bychom definovali takové pole jako u64 woo[8]). V programu "xdp/simple" do proměnné dostaneme aktuální číslo procesoru key a poté pomocí funkce pomocníka bpf_map_lookup_element dostaneme ukazatel na odpovídající záznam v poli, který zvýšíme o jednu. Přeloženo do ruštiny: počítáme statistiky, které CPU zpracovávaly příchozí pakety. Zkusme spustit program:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simpleZkontrolujeme, že je napojená lo a poslat nějaké balíčky:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 108
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; doneNyní se podívejme na obsah pole:
$ sudo bpftool map dump name woo
[
{ "key": 0, "value": 0 },
{ "key": 1, "value": 400 },
{ "key": 2, "value": 0 },
{ "key": 3, "value": 0 },
{ "key": 4, "value": 0 },
{ "key": 5, "value": 0 },
{ "key": 6, "value": 0 },
{ "key": 7, "value": 46400 }
]Téměř všechny procesy byly zpracovávány na CPU7. To pro nás není důležité, hlavní je, že program funguje a rozumíme tomu, jak přistupovat k mapám z programů BPF - pomocí .
Mystický index
Takže můžeme přistupovat k mapě z programu BPF pomocí volání jako
val = bpf_map_lookup_elem(&woo, &key);kde pomocná funkce vypadá
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)ale míjíme ukazatel &woo do nejmenované struktury struct { ... }...
Pokud se podíváme na assembler programu, vidíme, že hodnota &woo není ve skutečnosti definováno (řádek 4):
llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
...a je obsažen v relokacích:
$ llvm-readelf -r xdp-simple.bpf.o | head -4
Relocation section '.relxdp/simple' at offset 0xe18 contains 1 entries:
Offset Info Type Symbol's Value Symbol's Name
0000000000000020 0000002700000001 R_BPF_64_64 0000000000000000 wooPokud se ale podíváme na již načtený program, vidíme ukazatel na správnou mapu (řádek 4):
$ sudo bpftool prog dump x name simple
int simple(void *ctx):
0: (85) call bpf_get_smp_processor_id#114128
1: (63) *(u32 *)(r10 -4) = r0
2: (bf) r2 = r10
3: (07) r2 += -4
4: (18) r1 = map[id:64]
...Můžeme tedy dojít k závěru, že v době spuštění našeho nakládacího programu byl odkaz na &woo byla nahrazena něčím s knihovnou libbpf. Nejprve se podíváme na výstup strace:
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, key_size=4, value_size=8, max_entries=8, map_name="woo", ...}, 120) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="simple", ...}, 120) = 5To vidíme libbpf vytvořil mapu woo a poté si stáhli náš program simple. Podívejme se blíže na to, jak načítáme program:
- volání
xdp_simple_bpf__open_and_loadze souboruxdp-simple.skel.h - Který způsobuje
xdp_simple_bpf__loadze souboruxdp-simple.skel.h - Který způsobuje
bpf_object__load_skeletonze souborulibbpf/src/libbpf.c - Který způsobuje
bpf_object__load_xattrzlibbpf/src/libbpf.c
Poslední funkce mimo jiné zavolá bpf_object__create_maps, který vytváří nebo otevírá existující mapy a mění je na deskriptory souborů. (Tady vidíme BPF_MAP_CREATE ve výstupu strace.) Dále se zavolá funkce bpf_object__relocate a je to ona, kdo nás zajímá, protože si pamatujeme, co jsme viděli woo v tabulce přemístění. Když to prozkoumáme, nakonec se ocitneme ve funkci bpf_program__relocate, který :
case RELO_LD64:
insn[0].src_reg = BPF_PSEUDO_MAP_FD;
insn[0].imm = obj->maps[relo->map_idx].fd;
break;Takže se řídíme našimi pokyny
18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 lla nahraďte v něm zdrojový registr BPF_PSEUDO_MAP_FD, a první IMM do deskriptoru souboru naší mapy a pokud se rovná např. 0xdeadbeef, pak jako výsledek obdržíme pokyn
18 11 00 00 ef eb ad de 00 00 00 00 00 00 00 00 r1 = 0 llTakto jsou mapové informace přenášeny do konkrétního načteného programu BPF. V tomto případě lze mapu vytvořit pomocí BPF_MAP_CREATEa otevřen pomocí ID pomocí BPF_MAP_GET_FD_BY_ID.
Celkem, při použití libbpf algoritmus je následující:
- při kompilaci se v relokační tabulce vytvoří záznamy pro odkazy na mapy
libbpfotevře knihu objektů ELF, najde všechny použité mapy a vytvoří pro ně deskriptory souborů- deskriptory souborů jsou načteny do jádra jako součást instrukce
LD64
Jak si dokážete představit, je toho víc a budeme se muset podívat do jádra. Naštěstí tušíme – význam jsme si zapsali BPF_PSEUDO_MAP_FD do zdrojového registru a můžeme jej pohřbít, což nás zavede ke svatyni všech svatých - kernel/bpf/verifier.c, kde funkce s rozlišujícím názvem nahrazuje deskriptor souboru adresou struktury typu struct bpf_map:
static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) {
...
f = fdget(insn[0].imm);
map = __bpf_map_get(f);
if (insn->src_reg == BPF_PSEUDO_MAP_FD) {
addr = (unsigned long)map;
}
insn[0].imm = (u32)addr;
insn[1].imm = addr >> 32;(úplný kód naleznete ). Můžeme tedy náš algoritmus rozšířit:
- při načítání programu ověřovatel zkontroluje správné použití mapy a zapíše adresu odpovídající struktury
struct bpf_map
Při stahování binárky ELF pomocí libbpf Děje se toho mnohem víc, ale to si probereme v dalších článcích.
Načítání programů a map bez libbpf
Jak jsme slíbili, zde je příklad pro čtenáře, kteří chtějí vědět, jak vytvořit a načíst program, který používá mapy, bez pomoci libbpf. To může být užitečné, když pracujete v prostředí, pro které nemůžete vytvářet závislosti, šetříte každý bit nebo píšete program jako , který generuje BPF binární kód za běhu.
Abychom usnadnili dodržování logiky, přepíšeme pro tyto účely náš příklad xdp-simple. Kompletní a mírně rozšířený kód programu diskutovaného v tomto příkladu lze nalézt v tomto .
Logika naší aplikace je následující:
- vytvořit typovou mapu
BPF_MAP_TYPE_ARRAYpomocí příkazuBPF_MAP_CREATE, - vytvořit program, který používá tuto mapu,
- připojte program k rozhraní
lo,
což se překládá do lidského jako
int main(void)
{
int map_fd, prog_fd;
map_fd = map_create();
if (map_fd < 0)
err(1, "bpf: BPF_MAP_CREATE");
prog_fd = prog_load(map_fd);
if (prog_fd < 0)
err(1, "bpf: BPF_PROG_LOAD");
xdp_attach(1, prog_fd);
}Zde map_create vytvoří mapu stejným způsobem, jako jsme to udělali v prvním příkladu o systémovém volání bpf - „kernele, prosím, udělejte mi novou mapu ve formě pole 8 prvků jako __u64 a dejte mi zpět deskriptor souboru":
static int map_create()
{
union bpf_attr attr;
memset(&attr, 0, sizeof(attr));
attr.map_type = BPF_MAP_TYPE_ARRAY,
attr.key_size = sizeof(__u32),
attr.value_size = sizeof(__u64),
attr.max_entries = 8,
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
return syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
}Program lze také snadno načíst:
static int prog_load(int map_fd)
{
union bpf_attr attr;
struct bpf_insn insns[] = {
...
};
memset(&attr, 0, sizeof(attr));
attr.prog_type = BPF_PROG_TYPE_XDP;
attr.insns = ptr_to_u64(insns);
attr.insn_cnt = sizeof(insns)/sizeof(insns[0]);
attr.license = ptr_to_u64("GPL");
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
}Záludná část prog_load je definice našeho programu BPF jako pole struktur struct bpf_insn insns[]. Ale protože používáme program, který máme v C, můžeme trochu podvádět:
$ llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
7: b7 01 00 00 00 00 00 00 r1 = 0
8: 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2>
9: 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0)
10: 07 01 00 00 01 00 00 00 r1 += 1
11: 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1
12: b7 01 00 00 02 00 00 00 r1 = 2
0000000000000068 <LBB0_2>:
13: bf 10 00 00 00 00 00 00 r0 = r1
14: 95 00 00 00 00 00 00 00 exitCelkem potřebujeme napsat 14 instrukcí ve formě struktur jako struct bpf_insn (Rada: vezměte skládku shora, znovu si přečtěte sekci s pokyny, otevřete и a pokusit se určit struct bpf_insn insns[] sám):
struct bpf_insn insns[] = {
/* 85 00 00 00 08 00 00 00 call 8 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 8,
},
/* 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0 */
{
.code = BPF_MEM | BPF_STX,
.off = -4,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_10,
},
/* bf a2 00 00 00 00 00 00 r2 = r10 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_10,
.dst_reg = BPF_REG_2,
},
/* 07 02 00 00 fc ff ff ff r2 += -4 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_2,
.imm = -4,
},
/* 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll */
{
.code = BPF_LD | BPF_DW | BPF_IMM,
.src_reg = BPF_PSEUDO_MAP_FD,
.dst_reg = BPF_REG_1,
.imm = map_fd,
},
{ }, /* placeholder */
/* 85 00 00 00 01 00 00 00 call 1 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 1,
},
/* b7 01 00 00 00 00 00 00 r1 = 0 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 0,
},
/* 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2> */
{
.code = BPF_JMP | BPF_JEQ | BPF_K,
.off = 4,
.src_reg = BPF_REG_0,
.imm = 0,
},
/* 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0) */
{
.code = BPF_MEM | BPF_LDX,
.off = 0,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_1,
},
/* 07 01 00 00 01 00 00 00 r1 += 1 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 1,
},
/* 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1 */
{
.code = BPF_MEM | BPF_STX,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* b7 01 00 00 02 00 00 00 r1 = 2 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 2,
},
/* <LBB0_2>: bf 10 00 00 00 00 00 00 r0 = r1 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* 95 00 00 00 00 00 00 00 exit */
{
.code = BPF_JMP | BPF_EXIT
},
};Cvičení pro ty, kteří toto sami nenapsali – najděte map_fd.
V našem programu zbývá ještě jedna nezveřejněná část - xdp_attach. Bohužel programy jako XDP nelze připojit pomocí systémového volání bpfLidé, kteří vytvořili BPF a XDP, pocházeli z online komunity. Linux, což znamená, že použili ten, který jim byl nejznámější (ale ne pro normální people) rozhraní pro interakci s jádrem: , viz také . Nejjednodušší způsob realizace xdp_attach kopíruje kód z libbpf, totiž ze spisu , což jsme udělali a trochu to zkrátili:
Vítejte ve světě netlink zásuvek
Otevřete typ zásuvky síťového připojení NETLINK_ROUTE:
int netlink_open(__u32 *nl_pid)
{
struct sockaddr_nl sa;
socklen_t addrlen;
int one = 1, ret;
int sock;
memset(&sa, 0, sizeof(sa));
sa.nl_family = AF_NETLINK;
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);
if (sock < 0)
err(1, "socket");
if (setsockopt(sock, SOL_NETLINK, NETLINK_EXT_ACK, &one, sizeof(one)) < 0)
warnx("netlink error reporting not supported");
if (bind(sock, (struct sockaddr *)&sa, sizeof(sa)) < 0)
err(1, "bind");
addrlen = sizeof(sa);
if (getsockname(sock, (struct sockaddr *)&sa, &addrlen) < 0)
err(1, "getsockname");
*nl_pid = sa.nl_pid;
return sock;
}Z této zásuvky čteme:
static int bpf_netlink_recv(int sock, __u32 nl_pid, int seq)
{
bool multipart = true;
struct nlmsgerr *errm;
struct nlmsghdr *nh;
char buf[4096];
int len, ret;
while (multipart) {
multipart = false;
len = recv(sock, buf, sizeof(buf), 0);
if (len < 0)
err(1, "recv");
if (len == 0)
break;
for (nh = (struct nlmsghdr *)buf; NLMSG_OK(nh, len);
nh = NLMSG_NEXT(nh, len)) {
if (nh->nlmsg_pid != nl_pid)
errx(1, "wrong pid");
if (nh->nlmsg_seq != seq)
errx(1, "INVSEQ");
if (nh->nlmsg_flags & NLM_F_MULTI)
multipart = true;
switch (nh->nlmsg_type) {
case NLMSG_ERROR:
errm = (struct nlmsgerr *)NLMSG_DATA(nh);
if (!errm->error)
continue;
ret = errm->error;
// libbpf_nla_dump_errormsg(nh); too many code to copy...
goto done;
case NLMSG_DONE:
return 0;
default:
break;
}
}
}
ret = 0;
done:
return ret;
}Nakonec je zde naše funkce, která otevře soket a odešle do něj speciální zprávu obsahující deskriptor souboru:
static int xdp_attach(int ifindex, int prog_fd)
{
int sock, seq = 0, ret;
struct nlattr *nla, *nla_xdp;
struct {
struct nlmsghdr nh;
struct ifinfomsg ifinfo;
char attrbuf[64];
} req;
__u32 nl_pid = 0;
sock = netlink_open(&nl_pid);
if (sock < 0)
return sock;
memset(&req, 0, sizeof(req));
req.nh.nlmsg_len = NLMSG_LENGTH(sizeof(struct ifinfomsg));
req.nh.nlmsg_flags = NLM_F_REQUEST | NLM_F_ACK;
req.nh.nlmsg_type = RTM_SETLINK;
req.nh.nlmsg_pid = 0;
req.nh.nlmsg_seq = ++seq;
req.ifinfo.ifi_family = AF_UNSPEC;
req.ifinfo.ifi_index = ifindex;
/* started nested attribute for XDP */
nla = (struct nlattr *)(((char *)&req)
+ NLMSG_ALIGN(req.nh.nlmsg_len));
nla->nla_type = NLA_F_NESTED | IFLA_XDP;
nla->nla_len = NLA_HDRLEN;
/* add XDP fd */
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FD;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(int);
memcpy((char *)nla_xdp + NLA_HDRLEN, &prog_fd, sizeof(prog_fd));
nla->nla_len += nla_xdp->nla_len;
/* if user passed in any flags, add those too */
__u32 flags = XDP_FLAGS_SKB_MODE;
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FLAGS;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(flags);
memcpy((char *)nla_xdp + NLA_HDRLEN, &flags, sizeof(flags));
nla->nla_len += nla_xdp->nla_len;
req.nh.nlmsg_len += NLA_ALIGN(nla->nla_len);
if (send(sock, &req, req.nh.nlmsg_len, 0) < 0)
err(1, "send");
ret = bpf_netlink_recv(sock, nl_pid, seq);
cleanup:
close(sock);
return ret;
}Vše je tedy připraveno k testování:
$ cc nolibbpf.c -o nolibbpf
$ sudo strace -e bpf ./nolibbpf
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, map_name="woo", ...}, 72) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=15, prog_name="woo", ...}, 72) = 4
+++ exited with 0 +++Podívejme se, zda se náš program připojil k lo:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 160Pošleme pingy a podíváme se na mapu:
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; done
$ sudo bpftool m dump name woo
key: 00 00 00 00 value: 90 01 00 00 00 00 00 00
key: 01 00 00 00 value: 00 00 00 00 00 00 00 00
key: 02 00 00 00 value: 00 00 00 00 00 00 00 00
key: 03 00 00 00 value: 00 00 00 00 00 00 00 00
key: 04 00 00 00 value: 00 00 00 00 00 00 00 00
key: 05 00 00 00 value: 00 00 00 00 00 00 00 00
key: 06 00 00 00 value: 40 b5 00 00 00 00 00 00
key: 07 00 00 00 value: 00 00 00 00 00 00 00 00
Found 8 elementsHurá, vše funguje. Všimněte si mimochodem, že naše mapa je opět zobrazena ve formě bajtů. Je to dáno tím, že na rozdíl libbpf nenačetli jsme informace o typu (BTF). Ale o tom si povíme více příště.
Vývojové nástroje
V této části se podíváme na minimální sadu nástrojů pro vývojáře BPF.
Obecně řečeno, k vývoji programů BPF nepotřebujete nic speciálního – BPF běží na jakémkoli slušném distribučním jádře a programy jsou sestavovány pomocí clang, které lze dodat z balení. Nicméně vzhledem k tomu, že BPF je ve vývoji, jádro a nástroje se neustále mění, pokud nechcete od roku 2019 psát programy BPF pomocí staromódních metod, pak budete muset kompilovat
llvm/clangpahole- jeho jádro
bpftool
(Pro informaci: tato část a všechny příklady v článku byly spuštěny na Debian 10.)
llvm/clang
BPF je přátelský s LLVM, a přestože v poslední době lze programy pro BPF kompilovat pomocí gcc, veškerý současný vývoj se provádí pro LLVM. Proto nejprve sestavíme aktuální verzi clang od git:
$ sudo apt install ninja-build
$ git clone --depth 1 https://github.com/llvm/llvm-project.git
$ mkdir -p llvm-project/llvm/build/install
$ cd llvm-project/llvm/build
$ cmake .. -G "Ninja" -DLLVM_TARGETS_TO_BUILD="BPF;X86"
-DLLVM_ENABLE_PROJECTS="clang"
-DBUILD_SHARED_LIBS=OFF
-DCMAKE_BUILD_TYPE=Release
-DLLVM_BUILD_RUNTIME=OFF
$ time ninja
... много времени спустя
$Nyní můžeme zkontrolovat, zda se vše spojilo správně:
$ ./bin/llc --version
LLVM (http://llvm.org/):
LLVM version 11.0.0git
Optimized build.
Default target: x86_64-unknown-linux-gnu
Host CPU: znver1
Registered Targets:
bpf - BPF (host endian)
bpfeb - BPF (big endian)
bpfel - BPF (little endian)
x86 - 32-bit X86: Pentium-Pro and above
x86-64 - 64-bit X86: EM64T and AMD64(Montážní návod clang převzato mnou z .)
Nebudeme instalovat programy, které jsme právě vytvořili, ale místo toho je jen přidáme PATH, Například:
export PATH="`pwd`/bin:$PATH"(Toto lze přidat .bashrc nebo do samostatného souboru. Osobně k tomu přidávám takové věci ~/bin/activate-llvm.sh a když je potřeba, tak to udělám . activate-llvm.sh.)
Pahole a BTF
Užitečnost pahole používá se při sestavování jádra k vytváření ladicích informací ve formátu BTF. O detailech technologie BTF se v tomto článku nebudeme rozepisovat, kromě toho, že je pohodlná a chceme ji používat. Takže pokud se chystáte sestavit své jádro, nejprve sestavte pahole (bez pahole nebudete moci sestavit jádro s volbou CONFIG_DEBUG_INFO_BTF:
$ git clone https://git.kernel.org/pub/scm/devel/pahole/pahole.git
$ cd pahole/
$ sudo apt install cmake
$ mkdir build
$ cd build/
$ cmake -D__LIB=lib ..
$ make
$ sudo make install
$ which pahole
/usr/local/bin/paholeJádra pro experimentování s BPF
Při zkoumání možností BPF si chci sestavit vlastní jádro. Obecně řečeno to není nutné, protože budete moci kompilovat a načítat programy BPF na distribučním jádře, nicméně vlastní jádro vám umožní používat nejnovější funkce BPF, které se ve vaší distribuci objeví v nejlepším případě za měsíce. , nebo jako v případě některých ladicích nástrojů nebudou v dohledné době vůbec baleny. Díky svému vlastnímu jádru je také důležité experimentovat s kódem.
K sestavení jádra potřebujete za prvé samotné jádro a za druhé konfigurační soubor jádra. K experimentování s BPF můžeme použít obvyklé jádro nebo jedno z vývojářských jader. Historicky probíhal vývoj BPF v rámci síťové komunity. Linux a proto všechny změny dříve či později procházejí přes Davida Millera, správce sítě LinuxV závislosti na jejich povaze – opravy nebo nové funkce – se změny v síti dostávají do jednoho ze dvou jader: nebo . Změny pro BPF jsou mezi sebou distribuovány stejným způsobem и , které jsou pak sdruženy do net a net-next, v daném pořadí. Další podrobnosti viz и . Vyberte si tedy jádro podle svého vkusu a potřeb stability systému, na kterém testujete (*-next jádra jsou nejnestabilnější z uvedených).
Je nad rámec tohoto článku mluvit o tom, jak spravovat konfigurační soubory jádra - předpokládá se, že buď již víte, jak to udělat, nebo na vlastní pěst. Následující pokyny by vám však měly víceméně stačit k tomu, abyste získali fungující systém s podporou BPF.
Stáhněte si jedno z výše uvedených jader:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git
$ cd bpf-nextSestavte minimální funkční konfiguraci jádra:
$ cp /boot/config-`uname -r` .config
$ make localmodconfigPovolit možnosti BPF v souboru .config dle vlastního výběru (s největší pravděpodobností CONFIG_BPF bude již povoleno, protože jej systemd používá). Zde je seznam možností z jádra použitého pro tento článek:
CONFIG_CGROUP_BPF=y
CONFIG_BPF=y
CONFIG_BPF_LSM=y
CONFIG_BPF_SYSCALL=y
CONFIG_ARCH_WANT_DEFAULT_BPF_JIT=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT_DEFAULT_ON=y
CONFIG_IPV6_SEG6_BPF=y
# CONFIG_NETFILTER_XT_MATCH_BPF is not set
# CONFIG_BPFILTER is not set
CONFIG_NET_CLS_BPF=y
CONFIG_NET_ACT_BPF=y
CONFIG_BPF_JIT=y
CONFIG_BPF_STREAM_PARSER=y
CONFIG_LWTUNNEL_BPF=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_BPF_KPROBE_OVERRIDE=y
CONFIG_DEBUG_INFO_BTF=yPoté můžeme snadno sestavit a nainstalovat moduly a jádro (mimochodem, jádro můžete sestavit pomocí nově sestaveného clangpřidáváním CC=clang):
$ make -s -j $(getconf _NPROCESSORS_ONLN)
$ sudo make modules_install
$ sudo make installa restartujte s novým jádrem (používám k tomu kexec z balíčku kexec-tools):
v=5.8.0-rc6+ # если вы пересобираете текущее ядро, то можно делать v=`uname -r`
sudo kexec -l -t bzImage /boot/vmlinuz-$v --initrd=/boot/initrd.img-$v --reuse-cmdline &&
sudo kexec -ebpftool
Nejčastěji používanou utilitou v článku bude utilita bpftool, dodávaný jako součást jádra LinuxJe napsán a spravován vývojáři BPF pro vývojáře BPF a lze jej použít ke správě všech typů objektů BPF – načítání programů, vytváření a úpravě map, prozkoumávání ekosystému BPF a dalším činnostem. Dokumentaci ve formě zdrojového kódu pro manuálové stránky naleznete na nebo již zkompilovaný, .
V době psaní tohoto článku bpftool dodává se pouze připravené pro RHEL, Fedoru a Ubuntu (viz například , která vypráví nedokončený příběh balení bpftool в Debian). Pokud jste si ale již jádro sestavili, tak sestavte bpftool snadné jako koláč:
$ cd ${linux}/tools/bpf/bpftool
# ... пропишите пути к последнему clang, как рассказано выше
$ make -s
Auto-detecting system features:
... libbfd: [ on ]
... disassembler-four-args: [ on ]
... zlib: [ on ]
... libcap: [ on ]
... clang-bpf-co-re: [ on ]
Auto-detecting system features:
... libelf: [ on ]
... zlib: [ on ]
... bpf: [ on ]
$(tady ${linux} - toto je adresář vašeho jádra.) Po provedení těchto příkazů bpftool budou shromážděny v adresáři ${linux}/tools/bpf/bpftool a lze jej přidat do cesty (především k uživateli root) nebo zkopírujte do /usr/local/sbin.
sbírat bpftool nejlepší je použít to druhé clang, sestavené výše popsaným způsobem a zkontrolujte, zda je sestaveno správně - například pomocí příkazu
$ sudo bpftool feature probe kernel
Scanning system configuration...
bpf() syscall for unprivileged users is enabled
JIT compiler is enabled
JIT compiler hardening is disabled
JIT compiler kallsyms exports are enabled for root
...který ukáže, které funkce BPF jsou ve vašem jádře povoleny.
Mimochodem, předchozí příkaz lze spustit jako
# bpftool f p kTo se provádí analogicky s nástroji z balíčku iproute2, kde můžeme např. říci ip a s eth0 místo ip addr show dev eth0.
Závěr
BPF vám umožňuje nazout blechu, abyste efektivně změřili a za běhu změnili funkčnost jádra. Systém se ukázal jako velmi úspěšný, v nejlepších tradicích UNIXu: jednoduchý mechanismus, který vám umožňuje (re)programovat jádro, umožnil experimentovat velkému množství lidí a organizací. A přestože experimenty, stejně jako samotný vývoj infrastruktury BPF, nejsou zdaleka dokončeny, systém již má stabilní ABI, které vám umožní vybudovat spolehlivou a hlavně efektivní obchodní logiku.
Rád bych poznamenal, že podle mého názoru se technologie stala tak populární, protože na jedné straně může hrát (architekturu stroje lze pochopit víceméně za jeden večer), a na druhé straně řešit problémy, které se nedaly (krásně) vyřešit před jeho objevením. Tyto dvě složky dohromady nutí lidi experimentovat a snít, což vede ke vzniku stále více inovativních řešení.
Tento článek, i když není nijak zvlášť krátký, je pouze úvodem do světa BPF a nepopisuje „pokročilé“ funkce a důležité části architektury. Plán do budoucna je asi takový: v příštím článku bude přehled typů programů BPF (v jádře 5.8 je podporováno 30 typů programů), pak se konečně podíváme na to, jak psát skutečné aplikace BPF pomocí programů pro sledování jádra jako příklad, pak je čas na podrobnější kurz architektury BPF, po kterém budou následovat příklady síťových a bezpečnostních aplikací BPF.
Předchozí články v této sérii
Odkazy
— dokumentace o BPF od cilium, přesněji od Daniela Borkmana, jednoho z tvůrců a správců BPF. Toto je jeden z prvních vážných popisů, který se od ostatních liší tím, že Daniel přesně ví, o čem píše a nejsou tam žádné chyby. Tento dokument popisuje zejména práci s programy BPF typu XDP a TC pomocí známé utility
ipz balíčkuiproute2.— původní soubor s dokumentací pro klasický a následně rozšířený BPF. Dobré čtení, pokud se chcete ponořit do assembleru a technických architektonických detailů.
. Aktualizuje se zřídka, ale trefně, jak tam píše Alexej Starovoitov (autor eBPF) a Andrii Nakryiko - (správce)
libbpf).. Zábavné twitterové vlákno od Quentina Monneta s příklady a tajemstvím používání bpftool.
. Obří (a stále udržovaný) seznam odkazů na dokumentaci BPF od Quentina Monneta.
Zdroj: www.habr.com
