

Vzhledem k tomu, že adresy IPv4 se vyčerpávají, mnoho telekomunikačních operátorů se potýká s potřebou poskytnout svým klientům přístup k síti pomocí překladu adres. V tomto článku vám řeknu, jak můžete získat výkon Carrier Grade NAT na komoditních serverech.
Trocha historie
Téma vyčerpání adresního prostoru IPv4 již není nové. V určitém okamžiku se v RIPE objevily čekací listiny, pak se objevily burzy, na kterých se obchodovalo s bloky adres a uzavíraly obchody na jejich pronájem. Postupně začali telekomunikační operátoři poskytovat služby přístupu k internetu pomocí překladu adres a portů. Některým se nepodařilo získat dostatek adres na vydání „bílé“ adresy každému předplatiteli, zatímco jiní začali šetřit peníze tím, že odmítali nákup adres na sekundárním trhu. Výrobci síťových zařízení tuto myšlenku podpořili, protože tato funkce obvykle vyžaduje další rozšiřující moduly nebo licence. Například v řadě MX routerů Juniper (kromě nejnovějších MX104 a MX204) můžete provádět NAPT na samostatné servisní kartě MS-MIC, Cisco ASR1k vyžaduje licenci CGN, Cisco ASR9k vyžaduje samostatný modul A9K-ISM-100 a licenci A9K-CGN -LIC k němu. Obecně platí, že potěšení stojí spoustu peněz.
IPTables
Implementace NAT nevyžaduje specializované výpočetní prostředky; lze ji zvládnout univerzálními procesory, jako jsou ty, které se nacházejí v jakémkoli domácím routeru. V měřítku telekomunikačního operátora lze tento úkol splnit pomocí běžných serverů s operačním systémem FreeBSD (ipfw/pf) nebo GNU/...Linux (iptables). Nebudeme se zabývat FreeBSD, protože jsem tento operační systém přestal používat už dávno, takže zůstaňme u GNU/Linux.
Povolit překlad adres není vůbec obtížné. Nejprve musíte zaregistrovat pravidlo v iptables v tabulce nat:
iptables -t nat -A POSTROUTING -s 100.64.0.0/10 -j SNAT --to <pool_start_addr>-<pool_end_addr> --persistent
Operační systém načte modul nf_conntrack, který bude sledovat všechna aktivní připojení a provádět potřebné konverze. Je zde několik jemností. Za prvé, protože mluvíme o NAT v měřítku telekomunikačního operátora, je nutné upravit časové limity, protože s výchozími hodnotami velikost překladové tabulky rychle naroste do katastrofálních hodnot. Níže je uveden příklad nastavení, které jsem použil na svých serverech:
net.ipv4.ip_forward = 1
net.ipv4.ip_local_port_range = 8192 65535
net.netfilter.nf_conntrack_generic_timeout = 300
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 600
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 45
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 60
net.netfilter.nf_conntrack_icmpv6_timeout = 30
net.netfilter.nf_conntrack_icmp_timeout = 30
net.netfilter.nf_conntrack_events_retry_timeout = 15
net.netfilter.nf_conntrack_checksum=0
A za druhé, protože výchozí velikost překladové tabulky není navržena tak, aby fungovala v podmínkách telekomunikačního operátora, je třeba ji zvětšit:
net.netfilter.nf_conntrack_max = 3145728
Je také nutné zvýšit počet bucketů pro hashovací tabulku ukládající všechna vysílání (toto je možnost v modulu nf_conntrack):
options nf_conntrack hashsize=1572864
Po těchto jednoduchých manipulacích je získán plně funkční návrh, který dokáže vysílat velké množství klientských adres do skupiny externích adres. Výkon tohoto řešení však zanechává mnoho prostoru pro zlepšení. V mých prvních pokusech o použití GNU/Linux Pro NAT (cca 2013) se mi podařilo dosáhnout výkonu kolem 7 Gbit/s při 0.8 Mpps na jednom serveru (Xeon E5-1650v2). Od té doby síťový stack jádra GNU/Linux Byla provedena řada optimalizací a výkon jednoho serveru na stejném hardwaru se zvýšil na téměř 18–19 Gbit/s při 1.8–1.9 Mpps (to byly maximální hodnoty), ale poptávka po provozu zpracovávaném jedním serverem rostla mnohem rychleji. Nakonec byla vyvinuta schémata vyvažování zátěže pro různé servery, ale to vše zvýšilo složitost nastavení, údržby a udržování kvality poskytovaných služeb.
Tabulky NFT
V současné době je módním trendem v softwarových „shifting bags“ používání DPDK a XDP. Na toto téma bylo napsáno mnoho článků, zaznělo mnoho různých projevů a objevují se komerční produkty (například SKAT od VasExperts). Ale vzhledem k omezeným programovacím prostředkům telekomunikačních operátorů je poměrně problematické vytvořit jakýkoli „produkt“ založený na těchto rámcích vlastními silami. Provozování takového řešení bude v budoucnu mnohem obtížnější, zejména bude nutné vyvinout diagnostické nástroje. Například standardní tcpdump s DPDK nebude fungovat jen tak a „neuvidí“ pakety odeslané zpět do drátů pomocí XDP. Uprostřed všech těch řečí o nových technologiích pro předávání paketů do uživatelského prostoru zůstali bez povšimnutí и Pablo Neira Ayuso, správce iptables, o vývoji vykládání toku v nftables. Pojďme se na tento mechanismus podívat blíže.
Hlavní myšlenkou je, že pokud router předával pakety z jedné relace v obou směrech toku (TCP relace přešla do stavu ESTABLISHED), pak není potřeba procházet následující pakety této relace všemi pravidly firewallu, protože všechny tyto kontroly budou stále ukončeny přenosem paketu dále do směrování. A vlastně nemusíme vybírat trasu – už víme, na jaké rozhraní a na který hostitel musíme v rámci této relace posílat pakety. Zbývá pouze uložit tyto informace a použít je pro směrování v rané fázi zpracování paketů. Při provádění NAT je nutné dodatečně ukládat informace o změnách adres a portů přeložených modulem nf_conntrack. Ano, samozřejmě, v tomto případě přestávají fungovat různí policisté a další informační a statistická pravidla v iptables, ale v rámci úkolu samostatného stálého NATu nebo třeba hranice to není tak důležité, protože služby jsou distribuovány napříč zařízeními.
Konfigurace
K použití této funkce potřebujeme:
- Použijte čerstvé jádro. Navzdory tomu, že se samotná funkčnost objevila v jádře 4.16, byla poměrně dlouho velmi „raw“ a pravidelně vyvolávala jadernou paniku. Vše se stabilizovalo kolem prosince 2019, kdy byla vydána jádra LTS 4.19.90 a 5.4.5.
- Přepište pravidla iptables ve formátu nftables pomocí poměrně nedávné verze nftables. Funguje přesně ve verzi 0.9.0
Pokud je s prvním bodem vše v principu jasné, jde hlavně o to nezapomenout zařadit modul do konfigurace při montáži (CONFIG_NFT_FLOW_OFFLOAD=m), pak druhý bod vyžaduje vysvětlení. Pravidla nftables jsou popsána úplně jinak než v iptables. odhaluje téměř všechny body, existují i speciální pravidla od iptables po nftables. Uvedu proto pouze příklad nastavení NAT a flow offload. Malá legenda například: , - jedná se o síťová rozhraní, kterými prochází provoz, ve skutečnosti jich může být více než dvě. , — počáteční a koncová adresa rozsahu „bílých“ adres.
Konfigurace NAT je velmi jednoduchá:
#! /usr/sbin/nft -f
table nat {
chain postrouting {
type nat hook postrouting priority 100;
oif <o_if> snat to <pool_addr_start>-<pool_addr_end> persistent
}
}
S flow offload je to trochu složitější, ale celkem pochopitelné:
#! /usr/sbin/nft -f
table inet filter {
flowtable fastnat {
hook ingress priority 0
devices = { <i_if>, <o_if> }
}
chain forward {
type filter hook forward priority 0; policy accept;
ip protocol { tcp , udp } flow offload @fastnat;
}
}
To je ve skutečnosti celé nastavení. Nyní bude veškerý provoz TCP/UDP spadat do tabulky fastnat a bude zpracován mnohem rychleji.
výsledky
Aby bylo jasné, o kolik rychlejší to je, přikládám snímek obrazovky zátěže na dvou reálných serverech, se stejným hardwarem (Xeon E5-1650v2), nakonfigurovaným identicky a s použitím stejného jádra. Linux, ale provádění NAT v iptables (NAT4) a v nftables (NAT5).
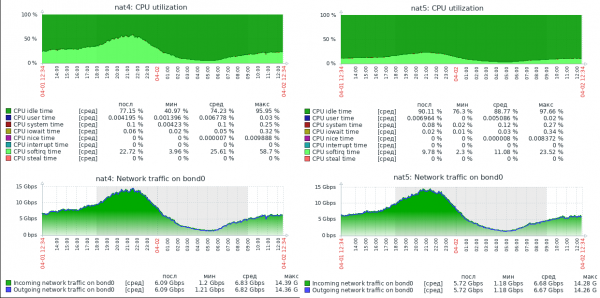
Na snímku obrazovky není žádný graf paketů za sekundu, ale v profilu zatížení těchto serverů je průměrná velikost paketu kolem 800 bajtů, takže hodnoty dosahují až 1.5 Mpps. Jak vidíte, server s nftables má obrovskou výkonnostní rezervu. V současné době tento server zpracovává až 30 Gbit/s rychlostí 3 Mpps a je zjevně schopen splnit omezení fyzické sítě 40 Gb/s, přičemž má volné prostředky CPU.
Doufám, že tento materiál bude užitečný pro síťové inženýry, kteří se snaží zlepšit výkon svých serverů.
Zdroj: www.habr.com
