

Přepis zprávy z roku 2015 od Alexey Lesovského „Deep dive into PostgreSQL internal statistics“
Prohlášení od autora zprávy: Podotýkám, že tato zpráva je datována listopadem 2015 - uplynuly více než 4 roky a uplynulo mnoho času. Verze 9.4 popisovaná v této zprávě již není podporována. Za poslední 4 roky bylo vydáno 5 nových verzí, ve kterých se objevilo mnoho inovací, vylepšení a změn týkajících se statistik a některé materiály jsou zastaralé a nerelevantní. Jak jsem recenzoval, snažil jsem se tato místa označit, abych vás čtenáře neuvedl v omyl. Tato místa jsem nepřepisoval, je jich hodně a ve výsledku vyjde úplně jiná zpráva.
PostgreSQL DBMS je obrovský mechanismus a tento mechanismus se skládá z mnoha subsystémů, jejichž koordinovaná práce přímo ovlivňuje výkon DBMS. Během provozu se shromažďují statistiky a informace o provozu komponent, což umožňuje vyhodnocovat efektivitu PostgreSQL a přijímat opatření ke zlepšení výkonu. Těchto informací je však hodně a jsou uvedeny spíše zjednodušenou formou. Zpracování těchto informací a jejich interpretace je někdy zcela netriviální úkol a „zoo“ nástrojů a utilit může snadno zmást i pokročilého DBA.


Dobré odpoledne Jmenuji se Alexey. Jak řekl Ilya, budu mluvit o statistikách PostgreSQL.

Statistiky aktivity PostgreSQL. PostgreSQL má dvě statistiky. Statistiky činnosti, o kterých bude řeč. A statistiky plánovače o distribuci dat. Budu mluvit konkrétně o statistikách aktivity PostgreSQL, které nám umožňují posuzovat výkon a nějak jej zlepšovat.
Řeknu vám, jak efektivně využít statistiky k řešení různých problémů, které máte nebo můžete mít.

Co ve zprávě nebude? Ve zprávě se nebudu dotýkat statistik plánovače, protože. toto je samostatné téma pro samostatnou zprávu o tom, jak jsou data uložena v databázi a jak plánovač dotazů získává představu o kvalitativních a kvantitativních charakteristikách těchto dat.
A nebudou žádné recenze nástrojů, nebudu porovnávat jeden produkt s druhým. Žádná reklama nebude. Nechme toho.

Chci vám ukázat, že používání statistik je užitečné. Je to nutné. Použijte to nebojácně. Vše, co potřebujeme, je prosté SQL a základní znalost SQL.
A povíme si, jakou statistiku zvolit pro řešení problémů.

Pokud se podíváme na PostgreSQL a spustíme v operačním systému příkaz pro zobrazení procesů, uvidíme „černou skříňku“. Uvidíme nějaké procesy, které něco dělají a podle názvu si můžeme zhruba představit, co tam dělají, co dělají. Ale ve skutečnosti je to černá skříňka, nemůžeme se podívat dovnitř.
Můžeme se podívat na zatížení CPU top, můžeme vidět využití paměti některými systémovými utilitami, ale nebudeme se moci podívat do PostgreSQL. K tomu potřebujeme další nástroje.
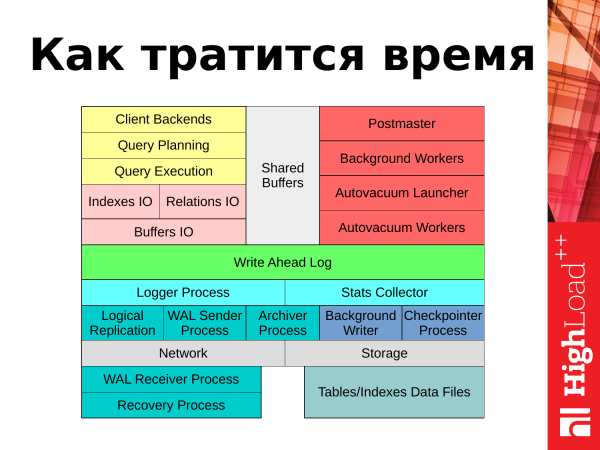
A pokračujme dále, řeknu vám, kde trávíte čas. Pokud budeme PostgreSQL reprezentovat ve formě takového schématu, pak bude možné odpovědět, kde se tráví čas. Jsou to dvě věci: je to zpracování požadavků klientů z aplikací a úlohy na pozadí, které PostgreSQL provádí, aby jej udržely v chodu.
Pokud se začneme dívat do levého horního rohu, můžeme vidět, jak jsou zpracovávány požadavky klientů. Požadavek přichází z aplikace a otevře se klientská relace pro další práci. Požadavek je předán plánovači. Plánovač sestaví plán dotazů. Odešle jej dále k provedení. S tabulkami a indexy jsou spojena nějaká bloková I/O data. Potřebná data se načtou z disků do paměti ve speciální oblasti zvané „sdílené vyrovnávací paměti“. Výsledky dotazu, pokud se jedná o aktualizace, smazání, jsou zaznamenány v transakčním protokolu ve WAL. Některé statistické informace se dostanou do protokolu nebo sběrače statistik. A výsledek požadavku je vrácen klientovi. Poté může klient vše zopakovat s novým požadavkem.
Co máme s úlohami na pozadí a procesy na pozadí? Máme několik procesů, které udržují databázi v chodu a běží normálně. Tyto procesy budou také zahrnuty ve zprávě: jedná se o autovakuum, kontrolní ukazatel, procesy související s replikací, zapisovač na pozadí. Při hlášení se dotknu každého z nich.

Jaké jsou problémy se statistikou?
- Spousta informací. PostgreSQL 9.4 poskytuje 109 metrik pro prohlížení statistických dat. Pokud však databáze ukládá mnoho tabulek, schémat, databází, pak bude nutné všechny tyto metriky vynásobit odpovídajícím počtem tabulek, databází. To znamená, že informací je ještě více. A je velmi snadné se v něm utopit.
- Dalším problémem je, že statistiky jsou reprezentovány počítadly. Pokud se podíváme na tyto statistiky, uvidíme neustále přibývající čítače. A pokud od vynulování statistik uplynulo hodně času, uvidíme miliardy hodnot. A nic nám neříkají.
- Neexistuje žádná historie. Pokud máte nějaké selhání, něco spadlo před 15-30 minutami, nebudete moci použít statistiky a podívat se, co se stalo před 15-30 minutami. To je problém.
- Chybějící nástroj zabudovaný do PostgreSQL je problém. Vývojáři jádra neposkytují žádný nástroj. Nic takového nemají. Jen dávají statistiky v databázi. Použijte to, požádejte o to, co chcete, a pak to udělejte.
- Protože v PostgreSQL není zabudován žádný nástroj, způsobuje to další problém. Spousta nástrojů třetích stran. Každá firma, která má více či méně přímé ruce, se snaží napsat svůj vlastní program. A díky tomu má komunita spoustu nástrojů, které můžete použít pro práci se statistikami. A v některých nástrojích jsou některé funkce, v jiných nástrojích nejsou žádné jiné funkce nebo jsou tam nějaké nové funkce. A nastává situace, že je potřeba použít dva nebo tři nebo čtyři nástroje, které se navzájem překrývají a mají různé funkce. To je velmi nepříjemné.

Co z toho vyplývá? Je důležité umět brát statistiky přímo, abyste nebyli závislí na programech, nebo tyto programy sami nějak vylepšovat: přidejte některé funkce, abyste získali svůj prospěch.
A potřebujete základní znalosti SQL. Chcete-li získat nějaká data ze statistik, musíte provést SQL dotazy, tj. musíte vědět, jak se provádí výběr, spojení.

Statistiky nám říkají několik věcí. Lze je rozdělit do kategorií.
- První kategorií jsou události probíhající v databázi. To je, když v databázi nastane nějaká událost: dotaz, přístup k tabulce, autovakuování, potvrzení, to jsou všechno události. Čítače odpovídající těmto událostem se zvýší. A můžeme tyto události sledovat.
- Druhou kategorií jsou vlastnosti objektů jako jsou tabulky, databáze. Mají vlastnosti. Toto je velikost tabulek. Můžeme sledovat růst tabulek, růst indexů. Můžeme vidět změny v dynamice.
- A třetí kategorií je čas strávený na akci. Žádost je událost. Má svou vlastní specifickou míru trvání. Tady to začalo, tady to skončilo. Můžeme to sledovat. Buď čas čtení bloku z disku nebo zápisu. Tyto věci jsou také sledovány.

Zdroje statistik jsou uvedeny takto:
- Ve sdílené paměti (sdílené vyrovnávací paměti) je segment pro umístění statických dat, jsou zde i takové čítače, které se neustále inkrementují, když nastanou určité události, nebo vzniknou nějaké momenty v provozu databáze.
- Všechny tyto čítače nejsou dostupné pro uživatele a nejsou dostupné ani pro správce. To jsou věci nízké úrovně. Pro přístup k nim PostgreSQL poskytuje rozhraní ve formě funkcí SQL. Pomocí těchto funkcí můžeme provádět výběry a získat nějakou metriku (nebo sadu metrik).
- Ne vždy je však vhodné tyto funkce používat, takže funkce jsou základem pro pohledy (VIEWs). Jedná se o virtuální tabulky, které poskytují statistiky o konkrétním subsystému nebo o nějaké sadě událostí v databázi.
- Tyto vestavěné pohledy (VIEWs) jsou hlavním uživatelským rozhraním pro práci se statistikami. Jsou k dispozici standardně bez dalších nastavení, můžete je okamžitě používat, sledovat, brát si odtamtud informace. A jsou tam i příspěvky. Příspěvky jsou oficiální. Můžete nainstalovat balíček postgresql-contrib (například postgresql94-contrib), načíst potřebný modul v konfiguraci, zadat mu parametry, restartovat PostgreSQL a můžete jej používat. (Poznámka. V závislosti na distribuci je v posledních verzích contrib balíček součástí hlavního balíčku).
- A existují neoficiální příspěvky. Nejsou dodávány se standardní distribucí PostgreSQL. Musí být buď zkompilovány, nebo nainstalovány jako knihovna. Možnosti se mohou velmi lišit v závislosti na tom, s čím přišel vývojář tohoto neoficiálního příspěvku.

Tento snímek ukazuje všechna tato zobrazení (VIEWS) a některé z těch funkcí, které jsou dostupné v PostgreSQL 9.4. Jak vidíme, je jich hodně. A je docela snadné se zmást, pokud to zažíváte poprvé.
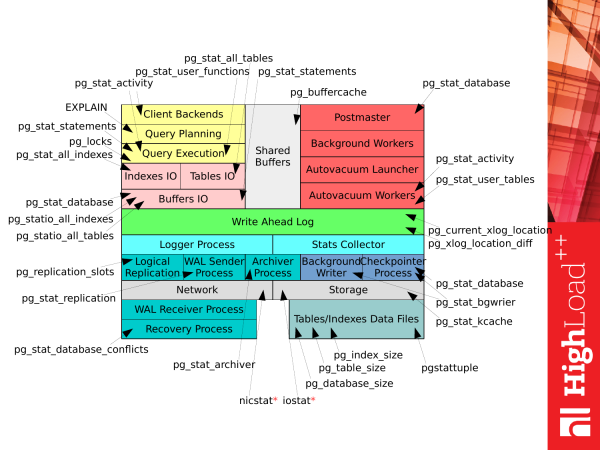
Pokud však vezmeme předchozí obrázek Как тратится время на PostgreSQL a kompatibilní s tímto seznamem, dostaneme tento obrázek. Každý pohled (VIEWs), nebo každou funkci, můžeme použít pro ten či onen účel k získání příslušných statistik, když máme spuštěný PostgreSQL. A již můžeme získat nějaké informace o fungování subsystému.
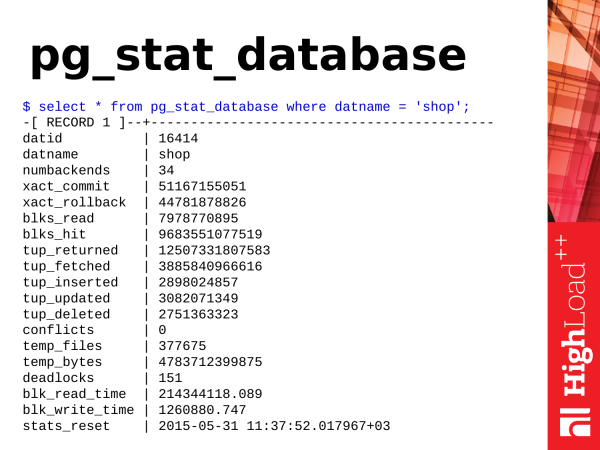
První věc, na kterou se podíváme, je pg_stat_database. Jak vidíme, jedná se o reprezentaci. Obsahuje spoustu informací. Nejrozmanitější informace. A poskytuje velmi užitečné znalosti o tom, co se v databázi děje.
Co si odtud můžeme vzít? Začněme těmi nejjednoduššími věcmi.

select
sum(blks_hit)*100/sum(blks_hit+blks_read) as hit_ratio
from pg_stat_database;První věc, na kterou se můžeme podívat, je procento zásahu do mezipaměti. Procento zásahů do mezipaměti je užitečná metrika. Umožňuje vám odhadnout, kolik dat je odebráno ze sdílené mezipaměti vyrovnávacích pamětí a kolik je načteno z disku.
Je jasné, že čím více mezipaměti máme, tím lépe. Tuto metriku hodnotíme v procentech. A pokud máme například procento těchto zásahů do mezipaměti větší než 90 %, pak je to dobré. Pokud klesne pod 90 %, pak nemáme dostatek paměti, abychom udrželi horkou hlavu dat v paměti. A aby bylo možné tato data využít, je PostgreSQL nucen přistupovat na disk a to je pomalejší, než kdyby se data načítala z paměti. A musíte myslet na zvýšení paměti: buď zvýšit sdílené vyrovnávací paměti, nebo zvýšit železnou paměť (RAM).
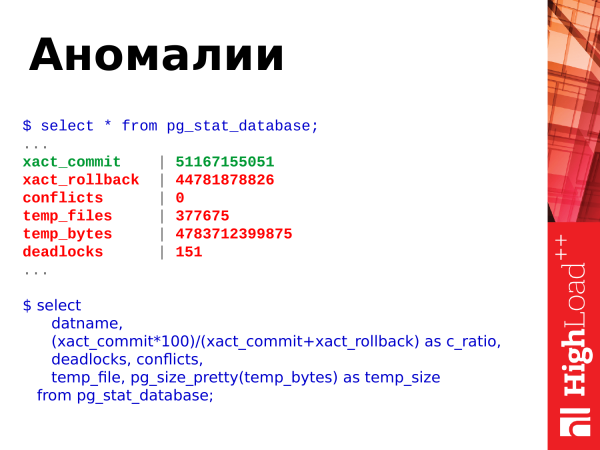
select
datname,
(xact_commit*100)/(xact_commit+xact_rollback) as c_ratio,
deadlocks, conflicts,
temp_file, pg_size_pretty(temp_bytes) as temp_size
from pg_stat_database;Co si z tohoto představení ještě vzít? Můžete vidět anomálie vyskytující se v databázi. Co je zde zobrazeno? Existují commity, rollbacky, vytváření dočasných souborů, jejich velikost, uváznutí a konflikty.
Tuto žádost můžeme využít. Tento SQL je docela jednoduchý. A tato data můžeme vidět sami.
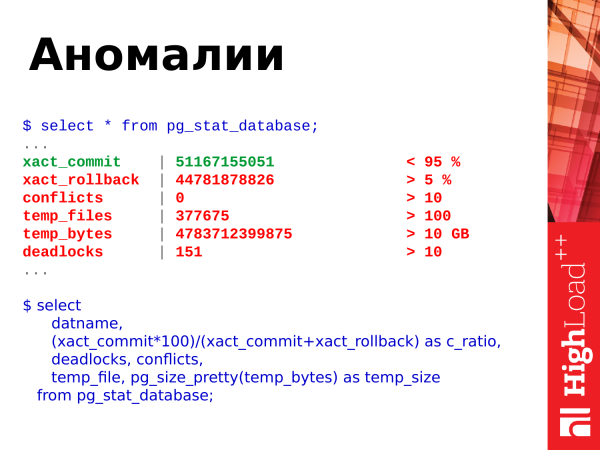
A zde jsou prahové hodnoty. Podíváme se na poměr commitů a rollbacků. Commits je úspěšné potvrzení transakce. Rollbacks je vrácení zpět, tj. transakce provedla nějakou práci, zatížila databázi, něco zvážila a pak došlo k selhání a výsledky transakce jsou zahozeny. tj. neustále se zvyšující počet rollbacků je špatný. A měli byste se jim nějak vyhnout a upravit kód tak, aby se to nestalo.
Konflikty souvisí s replikací. A těm je třeba se také vyhnout. Pokud máte nějaké dotazy, které se provádějí na replice a vznikají konflikty, musíte tyto konflikty analyzovat a zjistit, co se stane. Podrobnosti najdete v logech. A vyřešit konflikty tak, aby požadavky aplikací fungovaly bez chyb.
Zablokování je také špatná situace. Když požadavky soutěží o zdroje, jeden požadavek přistoupil k jednomu zdroji a vzal zámek, druhý požadavek přistoupil k druhému zdroji a také vzal zámek, a pak oba požadavky vzájemně přistoupily ke zdrojům a zablokovaly čekání, až soused uvolní zámek. To je také problematická situace. Je třeba je řešit na úrovni přepisování aplikací a serializace přístupu ke zdrojům. A pokud vidíte, že vaše zablokování neustále narůstá, musíte se podívat na podrobnosti v protokolech, analyzovat vzniklé situace a zjistit, v čem je problém.
Špatné jsou také dočasné soubory (temp_files). Když požadavek uživatele nemá dostatek paměti pro uložení provozních dočasných dat, vytvoří se soubor na disku. A všechny operace, které mohl provádět v dočasné vyrovnávací paměti v paměti, začnou provádět již na disku. Je to pomalé. Tím se prodlouží doba provádění dotazu. A klient, který odeslal požadavek na PostgreSQL, obdrží odpověď o něco později. Pokud jsou všechny tyto operace prováděny v paměti, Postgres bude reagovat mnohem rychleji a klient bude čekat méně.
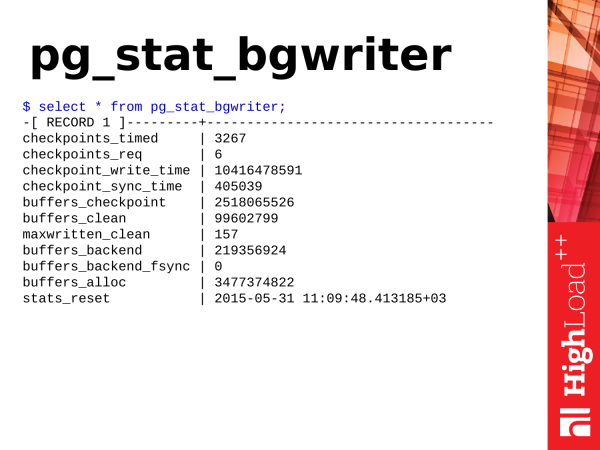
pg_stat_bgwriter - Tento pohled popisuje provoz dvou podsystémů PostgreSQL na pozadí: checkpointer и background writer.

Pro začátek si rozeberme kontrolní body, tzv. checkpoints. Co jsou kontrolní body? Kontrolní bod je pozice v transakčním protokolu indikující, že všechny změny dat provedené v protokolu jsou úspěšně synchronizovány s daty na disku. Proces může být v závislosti na zátěži a nastavení zdlouhavý a většinou sestává ze synchronizace nečistých stránek ve sdílených bufferech s datovými soubory na disku. K čemu to je? Pokud by PostgreSQL neustále přistupoval k disku a bral odtud data a zapisoval data při každém přístupu, bylo by to pomalé. PostgreSQL má tedy paměťový segment, jehož velikost závisí na parametrech v konfiguraci. Postgres alokuje operační data v této paměti pro další zpracování nebo dotazování. V případě požadavků na změnu údajů dochází k jejich změně. A dostáváme dvě verze dat. Jeden je v paměti, druhý na disku. A pravidelně musíte tato data synchronizovat. Potřebujeme, aby se to, co se změnilo v paměti, synchronizovalo na disk. To vyžaduje kontrolní bod.
Checkpoint prochází sdílenými buffery, označí nečisté stránky, že jsou potřebné pro kontrolní bod. Poté spustí druhý průchod sdílenými vyrovnávacími pamětmi. A stránky, které jsou označené jako kontrolní bod, už synchronizuje. Data jsou tedy synchronizována již s diskem.
Existují dva typy kontrolních bodů. Jeden kontrolní bod se provede při vypršení časového limitu. Tento kontrolní bod je užitečný a dobrý - checkpoint_timed. A na požádání jsou kontrolní body - checkpoint required. K takovému kontrolnímu bodu dochází, když máme velmi rozsáhlý datový záznam. Zaznamenali jsme spoustu transakčních protokolů. A PostgreSQL věří, že to vše potřebuje co nejrychleji synchronizovat, udělat kontrolní bod a jít dál.
A kdybyste se podívali do statistik pg_stat_bgwriter a uvidíte, co máte checkpoint_req je mnohem větší než checkpoint_timed, pak je to špatné. Proč špatné? To znamená, že PostgreSQL je pod neustálým stresem, když potřebuje zapisovat data na disk. Kontrolní bod podle časového limitu je méně stresující a provádí se podle interního plánu a jakoby se prodlužuje v čase. PostgreSQL má schopnost pozastavit práci a nezatěžovat diskový subsystém. To je užitečné pro PostgreSQL. A požadavky, které jsou prováděny během kontrolního bodu, nebudou zatěžovat skutečnost, že je diskový subsystém zaneprázdněn.
A existují tři parametry pro úpravu kontrolního bodu:
сheckpoint_segments.сheckpoint_timeout.сheckpoint_competion_target.
Umožňují ovládat činnost kontrolních bodů. Ale nebudu se u nich zdržovat. Jejich vliv je samostatný problém.
Poznámka: Verze 9.4 zvažovaná ve zprávě již není relevantní. V moderních verzích PostgreSQL je parametr checkpoint_segments nahrazeny parametry min_wal_size и max_wal_size.

Dalším podsystémem je zapisovač na pozadí − background writer. Co dělá? Běží neustále v nekonečné smyčce. Skenuje stránky do sdílených vyrovnávacích pamětí a vyprázdní špinavé stránky, které najde, na disk. Tímto způsobem pomáhá kontrolnímu ukazateli dělat méně práce během kontroly.
K čemu je ještě potřeba? Zajišťuje potřebu čistých stránek ve sdílených vyrovnávacích pamětech, pokud jsou náhle vyžadovány (ve velkém množství a okamžitě) pro uložení dat. Předpokládejme, že nastala situace, kdy požadavek vyžadoval čisté stránky a ty jsou již ve sdílených bufferech. Postgres backend prostě si je vezme a použije, sám nic uklízet nemusí. Pokud ale najednou žádné takové stránky nejsou, backend se pozastaví a začne hledat stránky, aby je vyprázdnil na disk a vzal si je pro své potřeby – což negativně ovlivní dobu aktuálně prováděného požadavku. Pokud vidíte, že máte parametr maxwritten_clean velký, to znamená, že zapisovač na pozadí nedělá svou práci a musíte zvýšit parametry bgwriter_lru_maxpagesaby mohl udělat více práce v jednom cyklu, vyčistit více stránek.
A dalším velmi užitečným ukazatelem je buffers_backend_fsync. Backendy nedělají fsync, protože je pomalý. Předávají fsync kontrolním ukazatelem zásobníku IO. Kontrolní ukazatel má svou vlastní frontu, periodicky zpracovává fsync a synchronizuje stránky v paměti se soubory na disku. Pokud je fronta kontrolních bodů velká a plná, pak je backend nucen provést fsync sám a to zpomaluje backend, tj. klient obdrží odpověď později, než by mohl. Pokud vidíte, že máte tuto hodnotu větší než nula, pak je to již problém a je třeba věnovat pozornost nastavení zapisovače na pozadí a také hodnotit výkon diskového subsystému.
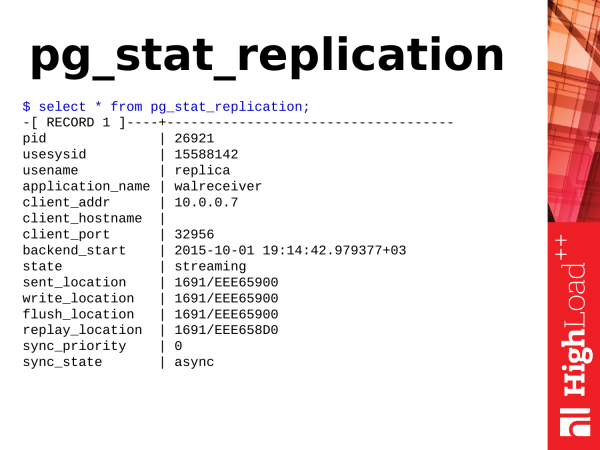
Poznámka: _Následující text popisuje statistické pohledy spojené s replikací. Většina názvů zobrazení a funkcí byla v Postgres 10 přejmenována. Podstatou přejmenování bylo nahradit xlog na wal и location na lsn v názvech funkcí/zobrazení atd. Konkrétní příklad, funkce pg_xlog_location_diff() byl přejmenován na pg_wal_lsn_diff()._
I tady toho máme hodně. Potřebujeme ale pouze položky související s umístěním.
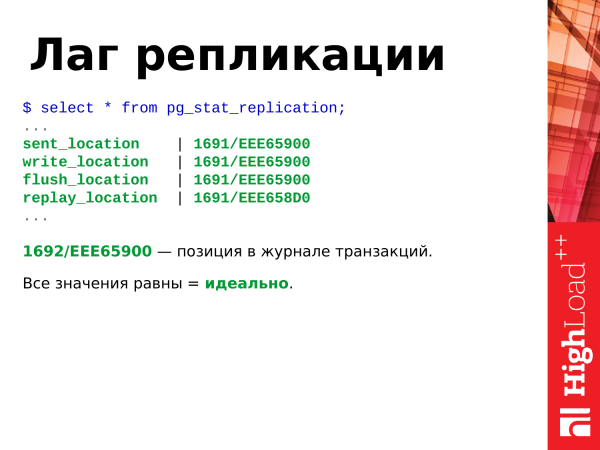
Pokud vidíme, že všechny hodnoty jsou stejné, pak je to ideální a replika nezaostává za předlohou.
Tato hexadecimální pozice je zde pozicí v transakčním protokolu. Neustále se zvyšuje, pokud je v databázi nějaká aktivita: vkládání, mazání atd.
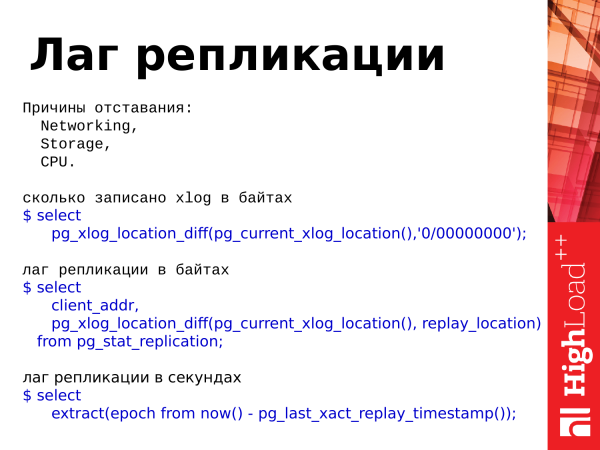
сколько записано xlog в байтах
$ select
pg_xlog_location_diff(pg_current_xlog_location(),'0/00000000');
лаг репликации в байтах
$ select
client_addr,
pg_xlog_location_diff(pg_current_xlog_location(), replay_location)
from pg_stat_replication;
лаг репликации в секундах
$ select
extract(epoch from now() - pg_last_xact_replay_timestamp());Pokud jsou tyto věci odlišné, pak je zde určitá prodleva. Lag je zpoždění repliky od hlavního serveru, tj. data se mezi servery liší.
Zpoždění má tři důvody:
- Je to diskový subsystém, který nezvládá synchronizační zápisy souborů.
- Jedná se o možné chyby sítě nebo přetížení sítě, kdy se data nestihnou dostat do repliky a ta je nemůže reprodukovat.
- A procesor. Procesor je velmi vzácný případ. A to jsem viděl dvakrát nebo třikrát, ale i to se může stát.
A zde jsou tři dotazy, které nám umožňují používat statistiky. Můžeme odhadnout, kolik je zaznamenáno v našem transakčním protokolu. Existuje taková funkce pg_xlog_location_diff a můžeme odhadnout zpoždění replikace v bajtech a sekundách. K tomu používáme také hodnotu z tohoto pohledu (VIEWs).
Poznámka: _Namísto pg_xlog_locationfunkce diff(), můžete použít operátor odečítání a odečíst jedno místo od druhého. Komfortní.
Se zpožděním, které je v sekundách, je jeden okamžik. Pokud na masteru není žádná aktivita, transakce tam byla asi před 15 minutami a není žádná aktivita, a když se podíváme na toto zpoždění na replice, uvidíme zpoždění 15 minut. To stojí za zapamatování. A může to vést k strnulosti, když jste sledovali toto zpoždění.
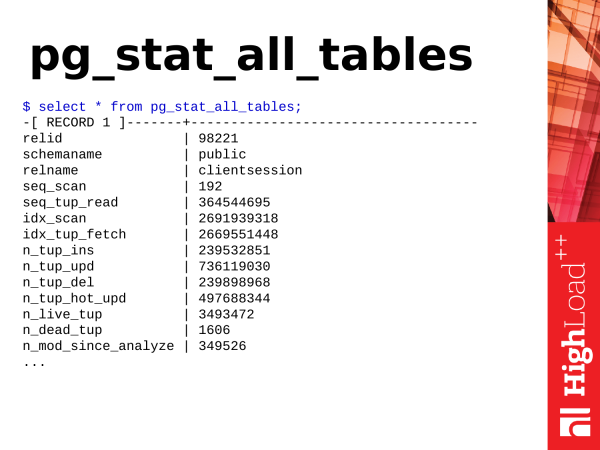
pg_stat_all_tables je další užitečný pohled. Zobrazuje statistiky v tabulkách. Když máme tabulky v databázi, je s tím nějaká aktivita, nějaké akce, můžeme tyto informace získat z tohoto pohledu.

select
relname,
pg_size_pretty(pg_relation_size(relname::regclass)) as size,
seq_scan, seq_tup_read,
seq_scan / seq_tup_read as seq_tup_avg
from pg_stat_user_tables
where seq_tup_read > 0 order by 3,4 desc limit 5;První věc, na kterou se můžeme podívat, je sekvenční skenování tabulek. Samotné číslo po těchto pasážích nemusí být nutně špatné a nenaznačuje, že už musíme něco udělat.
Existuje však druhá metrika - seq_tup_read. Toto je počet řádků vrácených ze sekvenčního skenování. Pokud průměrný počet překročí 1 000, 10 000, 50 000, 100 000, pak je to již indikátor, že možná budete muset někde vytvořit index, aby přístupy byly podle indexu, nebo je možné optimalizovat dotazy, které používají takové sekvenční skenování tak, aby to se nestane.
Jednoduchý příklad – řekněme požadavek s velkým OFFSET a LIMIT stojí za to. Například je naskenováno 100 000 řádků v tabulce a poté je odebráno 50 000 požadovaných řádků a předchozí naskenované řádky jsou zahozeny. To je také špatný případ. A takové požadavky je potřeba optimalizovat. A tady je takový jednoduchý SQL dotaz, na kterém to vidíte a vyhodnocujete přijatá čísla.

select
relname,
pg_size_pretty(pg_total_relation_size(relname::regclass)) as
full_size,
pg_size_pretty(pg_relation_size(relname::regclass)) as
table_size,
pg_size_pretty(pg_total_relation_size(relname::regclass) -
pg_relation_size(relname::regclass)) as index_size
from pg_stat_user_tables
order by pg_total_relation_size(relname::regclass) desc limit 10;Velikosti tabulek lze také získat pomocí této tabulky a pomocí doplňkových funkcí pg_total_relation_size(), pg_relation_size().
Obecně existují metapříkazy dt и di, který můžete použít v PSQL a také zobrazit velikosti tabulek a indexů.
Využití funkcí nám ale pomáhá podívat se na velikosti tabulek, i s přihlédnutím k indexům, nebo bez zohlednění indexů, a udělat už nějaké odhady na základě růstu databáze, tedy jak roste s námi, s jakou intenzitu, a již vyvodit nějaké závěry o optimalizaci velikosti.
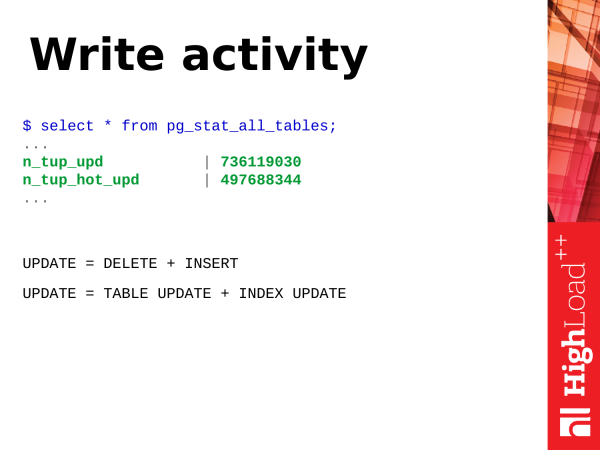
Napište aktivitu. co je to záznam? Podívejme se na operaci UPDATE – operace aktualizace řádků v tabulce. Ve skutečnosti jsou aktualizace dvě operace (nebo dokonce více). Toto je vložení nové verze řádku a označení staré verze řádku jako zastaralé. Později přijde autovakuum a vyčistí tyto zastaralé verze linek, označí toto místo jako dostupné pro opětovné použití.
Aktualizace také není jen o aktualizaci tabulky. Stále se jedná o aktualizaci indexu. Pokud máte v tabulce mnoho indexů, pak s aktualizací budou muset být aktualizovány také všechny indexy, kterých se účastní pole aktualizovaná v dotazu. Tyto indexy budou mít také zastaralé verze řádků, které bude třeba vyčistit.

select
s.relname,
pg_size_pretty(pg_relation_size(relid)),
coalesce(n_tup_ins,0) + 2 * coalesce(n_tup_upd,0) -
coalesce(n_tup_hot_upd,0) + coalesce(n_tup_del,0) AS total_writes,
(coalesce(n_tup_hot_upd,0)::float * 100 / (case when n_tup_upd > 0
then n_tup_upd else 1 end)::float)::numeric(10,2) AS hot_rate,
(select v[1] FROM regexp_matches(reloptions::text,E'fillfactor=(\d+)') as
r(v) limit 1) AS fillfactor
from pg_stat_all_tables s
join pg_class c ON c.oid=relid
order by total_writes desc limit 50;A vzhledem ke svému designu je UPDATE těžká operace. Ale lze je usnadnit. Jíst hot updates. Objevily se v PostgreSQL verze 8.3. a co je tohle? Toto je odlehčená aktualizace, která nezpůsobuje opětovné sestavení indexů. To znamená, že jsme aktualizovali záznam, ale aktualizoval se pouze záznam na stránce (který patří do tabulky) a indexy stále ukazují na stejný záznam na stránce. Je tam trochu taková zajímavá logika práce, když přijde vakuum, tak to má tyto řetězy hot přestaví a vše pokračuje v práci bez aktualizace indexů a vše se děje s menším plýtváním zdroji.
A když máte n_tup_hot_upd velký, je moc dobrý. To znamená, že převažují odlehčené aktualizace a to je pro nás levnější z hlediska zdrojů a vše je v pořádku.

ALTER TABLE table_name SET (fillfactor = 70);Jak zvýšit hlasitost hot updateov? Můžeme použít fillfactor. Určuje velikost rezervovaného volného místa při vyplňování stránky v tabulce pomocí INSERTů. Když přílohy jdou na stůl, zcela vyplní stránku, nenechávají v ní prázdné místo. Poté se zvýrazní nová stránka. Údaje se znovu vyplní. A toto je výchozí chování, fillfactor = 100 %.
Fillfactor můžeme nastavit na 70 %. To znamená, že s inserty byla přidělena nová stránka, ale bylo vyplněno pouze 70 % stránky. A v záloze nám zbývá 30 %. Když potřebujete provést aktualizaci, s největší pravděpodobností se to stane na stejné stránce a nová verze řádku se vejde na stejnou stránku. A hot_update bude hotový. To usnadňuje psaní na tabulky.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Fronta automatického vakuování. Autovacuum je takový subsystém, pro který je v PostgreSQL velmi málo statistik. V tabulkách v pg_stat_activity vidíme pouze kolik vakuů máme v tuto chvíli. Je však velmi obtížné pochopit, kolik stolů ve frontě má na cestách.
Poznámka: _Od Postgres 10 se situace se sledováním vakuového vakua hodně zlepšila - objevil se pohled pg_stat_progressvakuum, což značně zjednodušuje problematiku monitorování autovakua.
Můžeme použít tento zjednodušený dotaz. A vidíme, kdy by mělo být vakuum vytvořeno. Ale jak a kdy by mělo vakuum začít? Toto jsou staré verze strun, o kterých jsem mluvil dříve. Došlo k aktualizaci, byla vložena nová verze řádku. Objevila se zastaralá verze řetězce. Stůl pg_stat_user_tables existuje takový parametr n_dead_tup. Ukazuje počet "mrtvých" řádků. A jakmile počet mrtvých řad překročí určitou hranici, na stůl přijde autovakuum.
A jak se tato hranice počítá? Jedná se o velmi konkrétní procento z celkového počtu řádků v tabulce. Existuje parametr autovacuum_vacuum_scale_factor. Definuje procento. Řekněme 10 % + je zde další základní práh 50 řádků. A co se stane? Když máme více mrtvých řádků než "10% + 50" všech řádků v tabulce, dáme tabulku do autovakua.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Je tu však jeden háček. Základní prahové hodnoty pro parametry av_base_thresh и av_scale_factor lze přiřadit individuálně. A proto prahová hodnota nebude globální, ale individuální pro tabulku. Proto pro výpočet musíte použít triky a triky. A pokud vás to zajímá, můžete se podívat na zkušenosti našich kolegů z Avita (odkaz na snímku je neplatný a byl v textu aktualizován).
Psali pro který bere v úvahu tyto věci. Na dvou prostěradlech je nánožník. Ale myslí správně a celkem efektivně nám umožňuje posoudit, kde potřebujeme hodně vakua u stolů, kde je málo.
co s tím můžeme dělat? Pokud máme dlouhou frontu a autovakuum to nezvládne, můžeme zvýšit počet vysavačů, nebo jednoduše vakuum udělat agresivnějšímaby se spustil dříve, zpracuje tabulku na malé kousky. A tím se fronta zmenší. - Hlavní je zde sledovat zatížení disků, protože. Vakuová věc není zdarma, i když s příchodem zařízení SSD / NVMe se problém stal méně patrným.
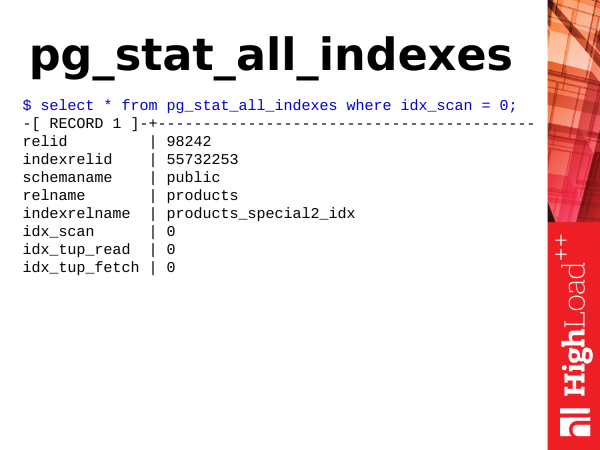
pg_stat_all_indexes je statistika indexů. Není velká. A můžeme z něj získat informace o použití indexů. A můžeme například určit, které indexy máme navíc.
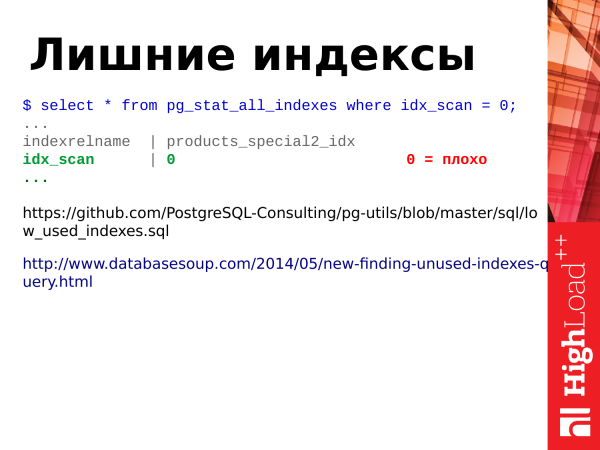
Jak jsem již řekl, update není jen aktualizace tabulek, ale také aktualizace indexů. Pokud tedy máme v tabulce mnoho indexů, je třeba při aktualizaci řádků v tabulce aktualizovat také indexy indexovaných polí a pokud máme nepoužívané indexy, pro které neexistují žádné skenování indexů, pak s námi visí jako zátěž. A je potřeba se jich zbavit. K tomu potřebujeme pole idx_scan. Jen se podíváme na počet skenování indexu. Pokud mají indexy nulové skenování po relativně dlouhou dobu ukládání statistik (alespoň 2-3 týdny), pak se s největší pravděpodobností jedná o špatné indexy, musíme se jich zbavit.
Poznámka: Při hledání nepoužívaných indexů v případě klastrů streamingové replikace je třeba zkontrolovat všechny uzly klastru, protože statistiky nejsou globální, a pokud se index nepoužívá na hlavním serveru, lze jej použít na replikách (pokud existuje zatížení).
Dva odkazy:
Toto jsou pokročilejší příklady dotazů, jak vyhledat nepoužívané indexy.
Druhý odkaz je docela zajímavý dotaz. Je v tom velmi netriviální logika. Doporučuji k recenzi.
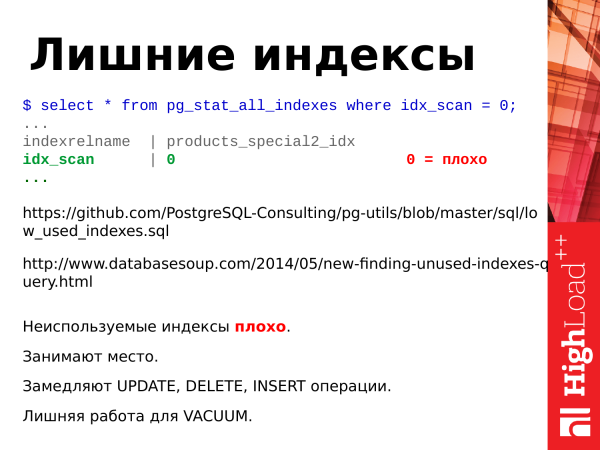
Co dalšího by se mělo shrnout do indexů?
Nepoužívané indexy jsou špatné.
Zabírají místo.
Zpomalte operace aktualizace.
Práce navíc pro vakuum.
Pokud odstraníme nepoužívané indexy, pak databázi jen vylepšíme.
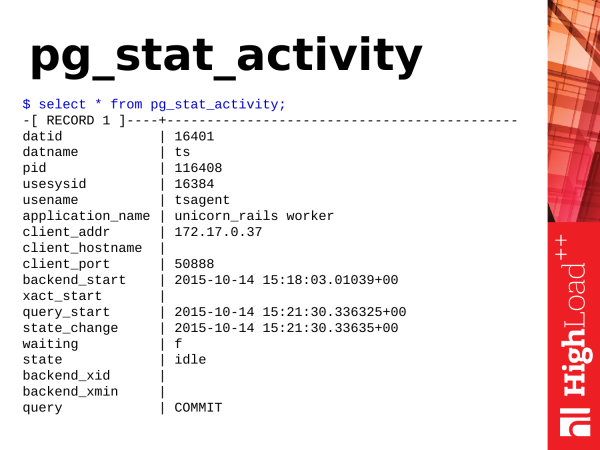
Další pohled je pg_stat_activity. Toto je analogie utility ps, pouze v PostgreSQL. Li ps'Ohm, pak se díváš na procesy v operačním systému pg_stat_activity vám ukáže aktivitu uvnitř PostgreSQL.
Co si odtud můžeme vzít?

select
count(*)*100/(select current_setting('max_connections')::int)
from pg_stat_activity;Můžeme vidět celkovou aktivitu, která se děje v databázi. Můžeme provést nové nasazení. Všechno tam bouchlo, nová spojení se nepřijímají, chyby se sypou do aplikace.

select
client_addr, usename, datname, count(*)
from pg_stat_activity group by 1,2,3 order by 4 desc;Můžeme spustit dotaz jako tento a podívat se na celkové procento připojení vzhledem k maximálnímu limitu připojení a zjistit, kdo máme nejvíce připojení. A v tomto daném případě tohoto uživatele vidíme cron_role otevřelo 508 spojení. A něco se mu stalo. Musíš se s tím poprat a uvidíš. A je dost možné, že se jedná o nějaký anomální počet spojení.
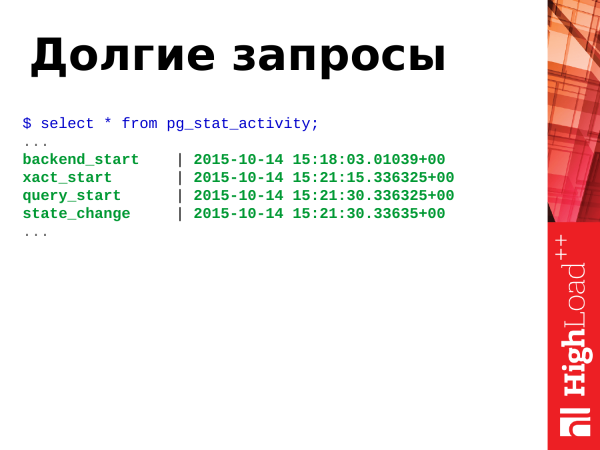
Pokud máme zatížení OLTP, dotazy by měly být rychlé, velmi rychlé a neměly by existovat dlouhé dotazy. Pokud však existují dlouhé požadavky, pak se z krátkodobého hlediska není čeho obávat, ale z dlouhodobého hlediska dlouhé dotazy poškozují databázi, zvyšují efekt nadýmání tabulek při fragmentaci tabulek. Je třeba se zbavit nadýmání i dlouhých dotazů.

select
client_addr, usename, datname,
clock_timestamp() - xact_start as xact_age,
clock_timestamp() - query_start as query_age,
query
from pg_stat_activity order by xact_start, query_start;Upozornění: s takovým požadavkem můžeme definovat dlouhé požadavky a transakce. Používáme funkci clock_timestamp() k určení pracovní doby. Dlouhé požadavky, které jsme našli, můžeme si je zapamatovat, provést je explain, podívat se na plány a nějak optimalizovat. Natáčíme aktuální dlouhé požadavky a žijeme dál.
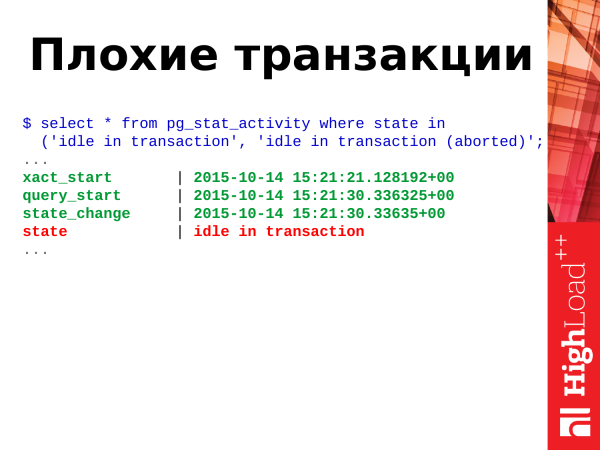
select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';Špatné transakce jsou nečinné v transakci a nečinné v transakcích (přerušených) transakcích.
Co to znamená? Transakce mají více stavů. A jeden z těchto stavů může zabrat kdykoliv. Existuje pole pro definování stavů state v tomto pohledu. A používáme to k určení stavu.

select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';A jak jsem řekl výše, tyto dva státy nečinnost v transakci a nečinnost v transakci (přerušená) jsou špatné. co to je? To je, když aplikace otevřela transakci, provedla nějaké akce a pokračovala ve svém podnikání. Transakce zůstává otevřená. Zasekne se, nic se v něm neděje, naváže spojení, uzamkne změněné řádky a potenciálně dokonce zvýší nadýmání ostatních tabulek, kvůli architektuře transakčního enginu Postrges. A takové transakce by se také měly střílet, protože jsou v každém případě obecně škodlivé.
Pokud vidíte, že jich máte v databázi více než 5-10-20, tak se musíte znepokojit a začít s nimi něco dělat.
Zde také používáme pro výpočet času clock_timestamp(). Natáčíme transakce, optimalizujeme aplikaci.
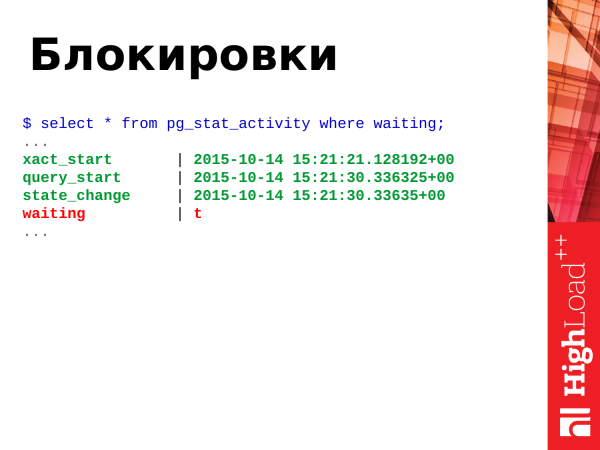
Jak jsem řekl výše, zámky jsou, když dvě nebo více transakcí soutěží o jeden nebo skupinu zdrojů. K tomu máme pole waiting s booleovskou hodnotou true nebo false.
Pravda - to znamená, že proces čeká, je třeba něco udělat. Když proces čeká, pak čeká i klient, který proces inicioval. Klient v prohlížeči sedí a také čeká.
Poznámka: _Počínaje Postgres 9.6, pole waiting odstraněny a nahrazeny dvěma více informativními poli wait_event_type и wait_event._
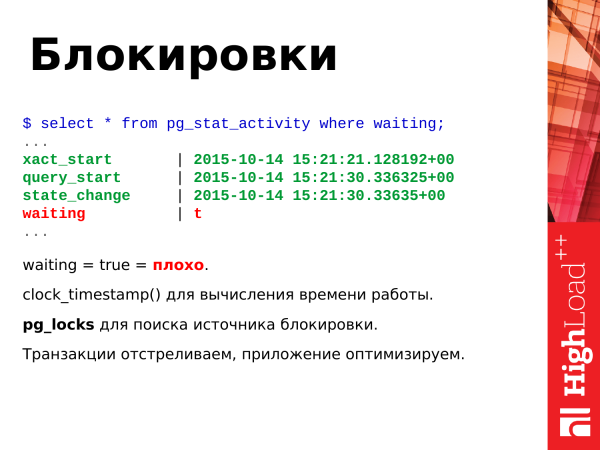
Co dělat? Pokud po dlouhou dobu vidíte pravdu, měli byste se takových požadavků zbavit. Takové transakce jen natáčíme. Píšeme vývojářům, co je potřeba nějak optimalizovat, aby nedocházelo k závodům o zdroje. A pak vývojáři optimalizují aplikaci tak, aby k tomu nedocházelo.
A extrémní, ale zároveň potenciálně ne fatální případ je výskyt patových situací. Dvě transakce aktualizovaly dva zdroje, pak k nim znovu přistupují, již k opačným zdrojům. PostgreSQL v tomto případě vezme a odstřelí samotnou transakci, aby ta druhá mohla pokračovat v práci. Tohle je slepá ulička a ona sama sobě nerozumí. PostgreSQL je proto nucen přijmout extrémní opatření.

A zde jsou dva dotazy, které umožňují sledovat zámky. Používáme pohled pg_locks, který umožňuje sledovat těžké zámky.
A prvním odkazem je samotný text požadavku. Je to pěkně dlouhé.
A druhý odkaz je článek o zámcích. Je užitečné číst, je to velmi zajímavé.
Co tedy vidíme? Vidíme dvě žádosti. Transakce s ALTER TABLE je blokovací transakce. Začalo to, ale neskončilo a aplikace, která tuto transakci zaúčtovala, někde dělá jiné věci. A druhý požadavek je aktualizace. Čeká na dokončení alterační tabulky, než bude pokračovat ve své práci.
Takto zjistíme, kdo koho zavřel, kdo koho drží, a můžeme se tím dále zabývat.
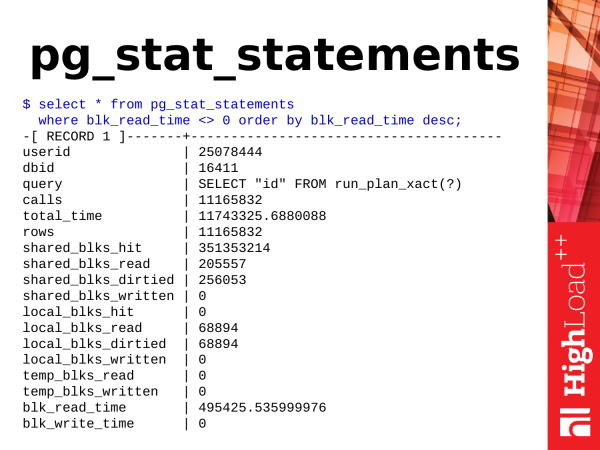
Další modul je pg_stat_statements. Jak jsem řekl, je to modul. Pro jeho použití je potřeba načíst jeho knihovnu v konfiguraci, restartovat PostgreSQL, nainstalovat modul (jedním příkazem) a pak budeme mít nový pohled.

Cреднее время запроса в милисекундах
$ select (sum(total_time) / sum(calls))::numeric(6,3)
from pg_stat_statements;
Самые активно пишущие (в shared_buffers) запросы
$ select query, shared_blks_dirtied
from pg_stat_statements
where shared_blks_dirtied > 0 order by 2 desc;Co si odtud můžeme vzít? Pokud mluvíme o jednoduchých věcech, můžeme vzít průměrnou dobu provádění dotazu. Čas roste, což znamená, že PostgreSQL reaguje pomalu a je potřeba něco udělat.
V databázi můžeme vidět nejaktivnější zápisové transakce, které mění data ve sdílených bufferech. Podívejte se, kdo tam aktualizuje nebo maže data.
A můžeme se jen podívat na různé statistiky pro tyto dotazy.

My pg_stat_statements slouží k vytváření přehledů. Statistiky resetujeme jednou denně. Pojďme to nashromáždit. Před dalším resetováním statistik vytvoříme přehled. Zde je odkaz na zprávu. Můžete to sledovat.

Co to děláme? Vypočítáváme celkové statistiky pro všechny požadavky. Poté pro každý dotaz spočítáme jeho individuální příspěvek k této celkové statistice.
A co můžeme vidět? Můžeme vidět celkovou dobu provádění všech požadavků určitého typu na pozadí všech ostatních požadavků. Můžeme se podívat na využití CPU a I/O ve vztahu k celkovému obrazu. A již k optimalizaci těchto požadavků. Na základě tohoto přehledu vytváříme hlavní dotazy a již dostáváme podněty k zamyšlení nad tím, co optimalizovat.

Co máme v zákulisí? Stále existuje několik příspěvků, které jsem nezvážil, protože čas je omezený.
K dispozici je pgstattuple je také doplňkový modul ze standardního balíčku contribs. Umožňuje vám hodnotit bloat tabulky, tzv. fragmentace tabulky. A pokud je fragmentace velká, musíte ji odstranit, použijte různé nástroje. A funkce pgstattuple funguje dlouho. A čím více tabulek, tím déle to bude fungovat.

Další příspěvek je pg_buffercache. Umožňuje vám kontrolovat sdílené buffery: jak intenzivně a pro jaké tabulky jsou stránky bufferů využívány. A to vám jen umožňuje nahlížet do sdílených vyrovnávacích pamětí a vyhodnocovat, co se tam děje.
Další modul je pgfincore. Umožňuje provádět operace s tabulkami na nízké úrovni prostřednictvím systémového volání mincore(), tj. umožňuje načíst tabulku do sdílených vyrovnávacích pamětí nebo ji uvolnit. A umožňuje mimo jiné prohlížet cache stránek operačního systému, tedy jak moc tabulka zabírá v cache stránek, ve sdílených bufferech a jednoduše umožňuje vyhodnotit zátěž tabulky.
Další modul je pg_stat_kcache. Používá také systémové volání getrusage(). A provede jej před a po provedení požadavku. A v získaných statistikách nám umožňuje odhadnout, kolik náš požadavek vynaložil na diskové I/O, tedy operace se souborovým systémem a dívá se na využití procesoru. Modul je však mladý (khe-khe) a pro svou práci vyžaduje PostgreSQL 9.4 a pg_stat_statements, o kterých jsem se zmínil dříve.

Užitečná je možnost používat statistiky. Nepotřebujete software třetích stran. Můžete se dívat, vidět, něco dělat, hrát.
Použití statistik je snadné, je to obyčejné SQL. Shromáždili jste žádost, sestavili ji, odeslali, podívali se na ni.
Statistiky pomáhají odpovídat na otázky. Máte-li otázky, obraťte se na statistiky – podívejte se, vyvozujte závěry, analyzujte výsledky.
A experimentujte. Spousta požadavků, spousta dat. Vždy můžete optimalizovat některý existující dotaz. Můžete si vytvořit vlastní verzi požadavku, která vám bude vyhovovat lépe než originál a použít ji.

reference
Platné odkazy, které byly v článku nalezeny, na základě kterých byly ve zprávě.
Autor napsat více
(anglicky)
Sběratel statistik
Funkce správy systému
Moduly Contrib
SQL utility a příklady SQL kódu
Děkuji vám všem za pozornost!
Zdroj: www.habr.com
