

Ahoj všichni! Máme skvělou zprávu, OTUS v červnu opět spouští kurz , v souvislosti s níž s vámi tradičně sdílíme užitečný materiál.

Pokud jste na celou tuhle věc s mikroslužbami narazili bez jakéhokoli kontextu, bylo by vám odpuštěno, že si myslíte, že je to trochu zvláštní. Rozdělení aplikace na fragmenty propojené sítí nutně znamená přidání komplexních režimů odolnosti proti chybám do výsledného distribuovaného systému.
Ačkoli tento přístup zahrnuje rozdělení do mnoha nezávislých služeb, konečným cílem je mnohem více než jen provozování těchto služeb na různých počítačích. Hovoříme zde o interakci s vnějším světem, který je ve své podstatě také distribuován. Ne v technickém smyslu, ale spíše ve smyslu ekosystému, který se skládá z mnoha lidí, týmů, programů a každá z těchto částí nějak potřebuje dělat svou práci.
Společnosti jsou například souborem distribuovaných systémů, které společně přispívají k dosažení nějakého cíle. Tuto skutečnost jsme po desetiletí ignorovali a snažili jsme se dosáhnout sjednocení pomocí FTP souborů nebo pomocí podnikových integračních nástrojů a zároveň se soustředili na naše vlastní izolované cíle. S příchodem služeb se ale vše změnilo. Služby nám pomohly podívat se za horizont a vidět svět vzájemně propojených programů, které spolupracují. Pro úspěšné fungování je však nutné rozpoznat a navrhnout dva zásadně odlišné světy: vnější svět, kde žijeme v ekosystému mnoha dalších služeb, a náš osobní, vnitřní svět, kde vládneme sami.
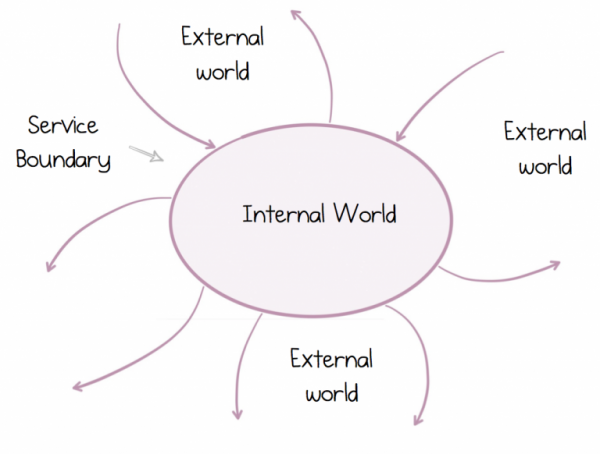
Tento distribuovaný svět je jiný než ten, ve kterém jsme vyrostli a na který jsme zvyklí. Principy výstavby tradiční monolitické architektury neobstojí v kritice. Správné uvedení těchto systémů tedy znamená více než jen vytvoření skvělého diagramu tabule nebo skvělého důkazu konceptu. Jde o to, zajistit, aby takový systém úspěšně fungoval po dlouhou dobu. Naštěstí služby existují už docela dlouho, i když vypadají jinak. jsou stále aktuální, dokonce ostřílení Dockerem, Kubernetesem a lehce ošuntělými hipsterskými vousy.
Dnes se tedy podíváme na to, jak se změnila pravidla, proč musíme přehodnotit způsob, jakým přistupujeme ke službám a datům, která si navzájem předávají, a proč k tomu budeme potřebovat úplně jiné nástroje.
Zapouzdření nebude vždy vaším přítelem
Mikroslužby mohou fungovat nezávisle na sobě. Právě tato vlastnost jim dává největší hodnotu. Stejná vlastnost umožňuje službám škálovat a růst. Ani ne tak ve smyslu škálování na kvadriliony uživatelů nebo petabajtů dat (i když i tam mohou pomoci), ale ve smyslu škálování z hlediska lidí, protože týmy a organizace neustále rostou.
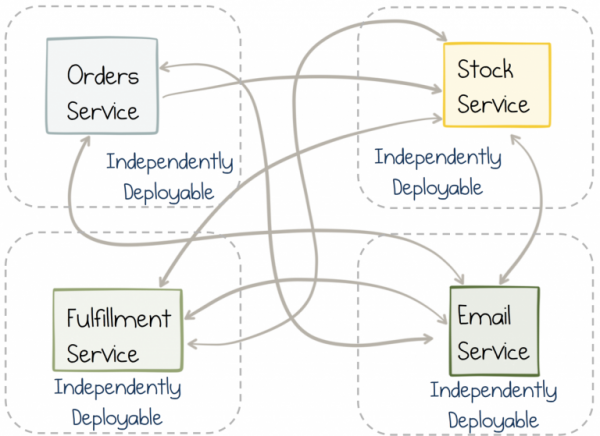
Nezávislost je však dvousečná zbraň. To znamená, že samotná služba může běžet snadno a přirozeně. Ale pokud je funkce implementována v rámci služby, která vyžaduje použití jiné služby, pak nakonec musíme provést změny v obou službách téměř současně. V monolitu je to snadné, stačí provést změnu a odeslat ji k vydání, ale v případě synchronizace nezávislých služeb bude více problémů. Koordinace mezi týmy a cykly uvolňování ničí agilitu.
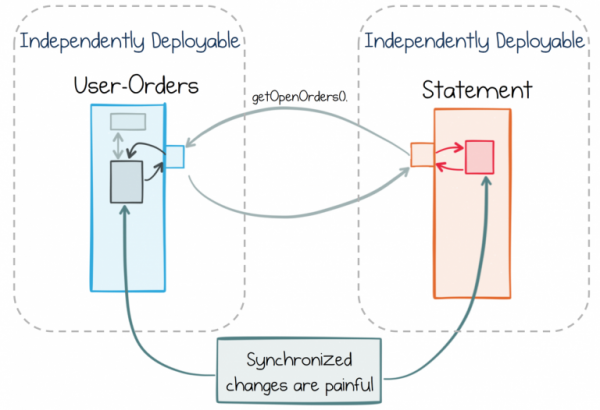
V rámci standardního přístupu se jednoduše snaží vyhnout nepříjemným end-to-end změnám a jasně rozdělují funkčnost mezi služby. Dobrým příkladem zde může být služba jednotného přihlášení. Má jasně definovanou roli, která ji odlišuje od ostatních služeb. Toto jasné oddělení znamená, že ve světě rychle se měnících požadavků na služby kolem něj se služba jednotného přihlašování pravděpodobně nezmění. Existuje v přísně omezeném kontextu.
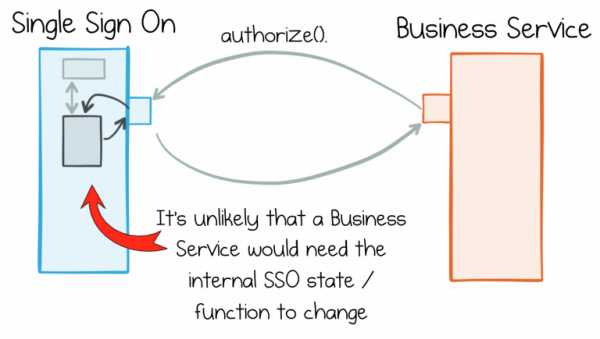
Problém je v tom, že v reálném světě obchodní služby nemohou udržovat stále stejné čisté oddělení rolí. Stejné obchodní služby například ve větší míře pracují s daty pocházejícími z jiných podobných služeb. Pokud jste zapojeni do online maloobchodu, pak se zpracování toku objednávek, katalogu produktů nebo informací o uživatelích stane požadavkem pro mnoho vašich služeb. Každá ze služeb bude ke svému provozu potřebovat přístup k těmto datům.
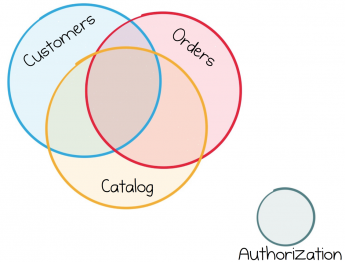
Většina podnikových služeb sdílí stejný datový tok, takže jejich práce je vždy propojena.
Tím se dostáváme k důležitému bodu, o kterém stojí za to mluvit. Zatímco služby fungují dobře pro komponenty infrastruktury, které fungují převážně izolovaně, většina obchodních služeb je nakonec mnohem těsněji propojena.
Datová dichotomie
Přístupy orientované na služby již mohou existovat, ale stále jim chybí přehled o tom, jak mezi službami sdílet velké množství dat.
Hlavním problémem je, že data a služby jsou neoddělitelné. Na jedné straně nás zapouzdření vybízí ke skrytí dat, aby bylo možné služby od sebe oddělit a usnadnit jejich růst a další změny. Na druhou stranu musíme být schopni volně dělit a dobývat sdílená data, stejně jako jakákoli jiná data. Jde o to, aby bylo možné okamžitě začít pracovat, tak volně jako v jakémkoli jiném informačním systému.
Informační systémy však nemají se zapouzdřením mnoho společného. Ve skutečnosti je to úplně naopak. Databáze dělají vše, co mohou, aby poskytly přístup k datům, která ukládají. Přicházejí s výkonným deklarativním rozhraním, které vám umožňuje upravovat data podle potřeby. Tato funkce je důležitá ve fázi předběžného výzkumu, ale ne pro řízení rostoucí složitosti neustále se vyvíjející služby.
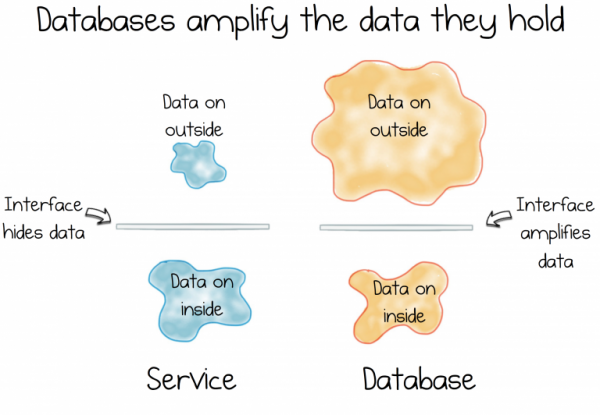
A zde nastává dilema. Rozpor. Dichotomie. Informační systémy jsou totiž o poskytování dat a služby o skrývání.
Tyto dvě síly jsou základní. Jsou základem velké části naší práce a neustále bojují o dokonalost v systémech, které budujeme.
Jak systémy služeb rostou a vyvíjejí se, vidíme důsledky datové dichotomie v mnoha ohledech. Buď se rozhraní služby rozroste a bude poskytovat stále větší rozsah funkcí a začne vypadat jako velmi luxusní domácí databáze, nebo budeme frustrovaní a implementujeme nějaký způsob, jak hromadně získávat nebo přesouvat celé sady dat ze služby do služby.
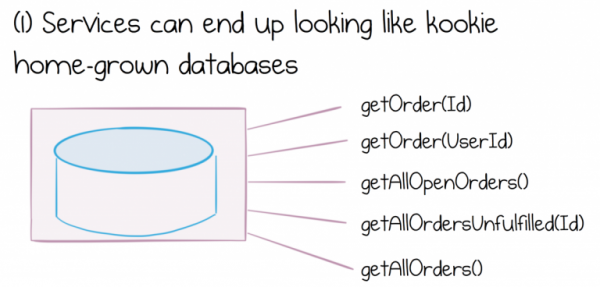
Na druhé straně vytvoření něčeho, co vypadá jako luxusní domácí databáze, povede k celé řadě problémů. Nebudeme zabíhat do podrobností o tom, proč je to nebezpečné sdílená databázeřekněme, že představuje značné nákladné inženýrské a provozní náklady pro společnost, která se jej snaží využít.
Horší je, že objemy dat zvětšují problémy s hranicemi služeb. Čím více sdílených dat se nachází ve službě, tím složitější bude rozhraní a tím obtížnější bude kombinovat datové sady pocházející z různých služeb.
Alternativní přístup extrakce a přesun celých datových sad má také své problémy. Běžný přístup k této otázce vypadá tak, že jednoduše načtete a uložíte celou datovou sadu a poté ji uložíte lokálně v každé náročné službě.
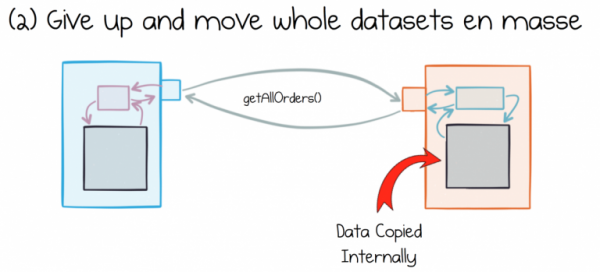
Problém je v tom, že různé služby interpretují data, která spotřebovávají, různě. Tato data jsou vždy po ruce. Jsou upravovány a zpracovávány lokálně. Poměrně rychle přestanou mít cokoli společného s daty ve zdroji.
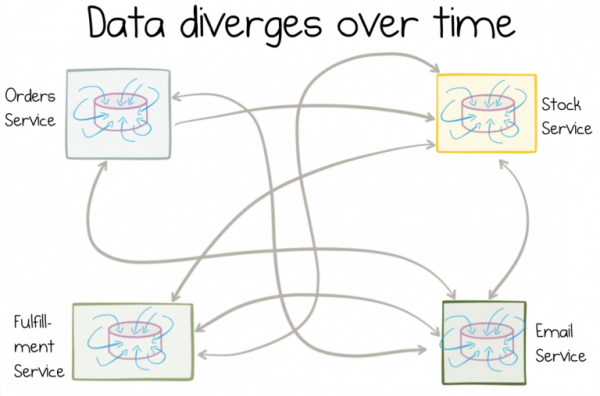
Čím proměnlivější jsou kopie, tím více se budou data v průběhu času lišit.
Aby toho nebylo málo, taková data je obtížné zpětně opravit ( Tady to může skutečně přijít k záchraně). Ve skutečnosti některé z neřešitelných technologických problémů, kterým podniky čelí, vyplývají z nesourodých dat, která se množí od aplikace k aplikaci.
Abychom našli řešení tohoto problému, musíme o sdílených datech přemýšlet jinak. Musí se stát prvotřídními objekty v architekturách, které stavíme. nazývá taková data „externí“, a to je velmi důležitá vlastnost. Potřebujeme zapouzdření, abychom neodhalili vnitřní fungování služby, ale musíme službám usnadnit přístup ke sdíleným datům, aby mohly správně vykonávat svou práci.
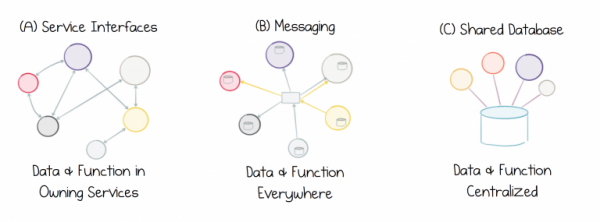
Problém je v tom, že ani jeden přístup dnes není relevantní, protože ani rozhraní služeb, ani zasílání zpráv, ani sdílená databáze nenabízejí dobré řešení pro práci s externími daty. Servisní rozhraní se špatně hodí pro výměnu dat v jakémkoli měřítku. Zprávy přesouvají data, ale neukládají jejich historii, takže se data časem poškodí. Sdílené databáze se příliš zaměřují na jeden bod, což brzdí pokrok. Nevyhnutelně uvízneme v cyklu selhání dat:
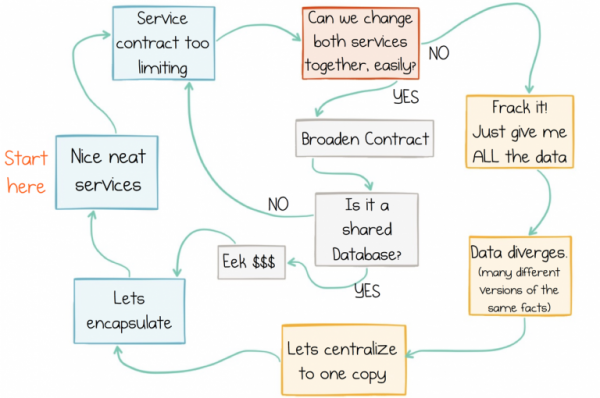
Cyklus selhání dat
Streams: decentralizovaný přístup k datům a službám
V ideálním případě musíme změnit způsob, jakým služby pracují se sdílenými daty. V tomto bodě se oba přístupy potýkají s výše zmíněnou dichotomií, protože neexistuje žádný magický prach, který by na něj mohl být posypán, aby zmizel. Můžeme však problém znovu promyslet a dosáhnout kompromisu.
Tento kompromis zahrnuje určitý stupeň centralizace. Můžeme použít mechanismus distribuovaného protokolu, protože poskytuje spolehlivé, škálovatelné proudy. Nyní chceme, aby se služby mohly připojit a fungovat na těchto sdílených vláknech, ale chceme se vyhnout komplexním centralizovaným Božím službám, které toto zpracování provádějí. Proto je nejlepší možností zabudovat zpracování toku do každé spotřebitelské služby. Služby tak budou moci kombinovat datové sady z různých zdrojů a pracovat s nimi tak, jak potřebují.
Jedním ze způsobů, jak tohoto přístupu dosáhnout, je použití streamovací platformy. Možností je mnoho, ale dnes se podíváme na Kafku, protože využití jeho Stateful Stream Processing nám umožňuje efektivně řešit prezentovaný problém.
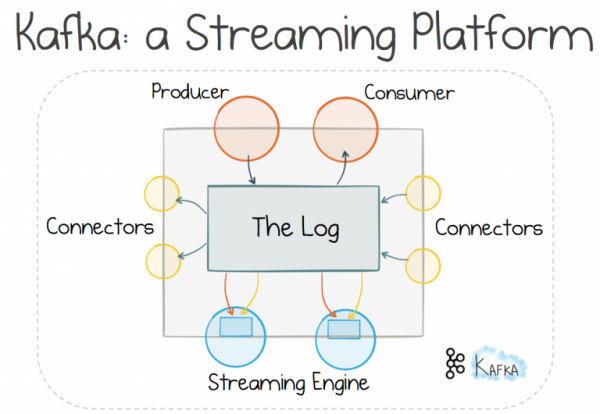
Použití mechanismu distribuovaného protokolování nám umožňuje jít po vyšlapané cestě a používat k práci zasílání zpráv . Má se za to, že tento přístup poskytuje lepší škálování a rozdělování než mechanismus požadavek-odpověď, protože poskytuje řízení toku příjemci spíše než odesílateli. Za všechno v tomto životě však musíte platit a zde potřebujete makléře. Ale u velkých systémů se kompromis vyplatí (což nemusí platit pro vaši průměrnou webovou aplikaci).
Pokud je za distribuované protokolování zodpovědný spíše broker než za tradiční systém zasílání zpráv, můžete využít další funkce. Přenos se může lineárně škálovat téměř stejně dobře jako distribuovaný souborový systém. Data mohou být uložena v logech poměrně dlouhou dobu, takže získáme nejen výměnu zpráv, ale také ukládání informací. Škálovatelné úložiště bez obav z proměnlivého sdíleného stavu.
Poté můžete použít stavové zpracování toku k přidání deklarativních databázových nástrojů ke spotřebovaným službám. To je velmi důležitá myšlenka. Zatímco data jsou uložena ve sdílených tocích, ke kterým mají přístup všechny služby, agregace a zpracování, které služba provádí, je soukromé. Ocitají se izolovaní v přísně omezeném kontextu.
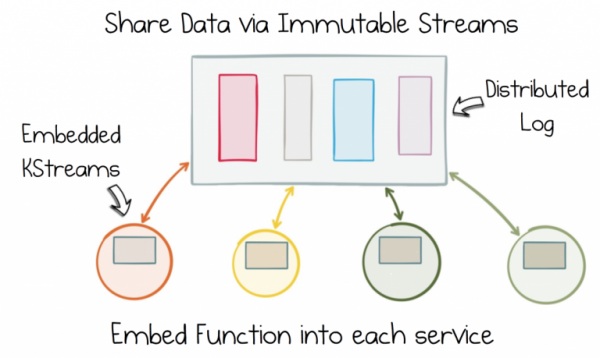
Eliminujte datovou dichotomii oddělením toku neměnných stavů. Pak přidejte tuto funkci do každé služby pomocí Stateful Stream Processing.
Pokud tedy vaše služba potřebuje pracovat s objednávkami, produktovým katalogem, skladem, bude mít plný přístup: pouze vy rozhodnete, jaká data zkombinujete, kde je zpracujete a jak se budou v čase měnit. I přes to, že jsou data sdílená, práce s nimi je zcela decentralizovaná. Vyrábí se v rámci každé služby, ve světě, kde vše probíhá podle vašich pravidel.
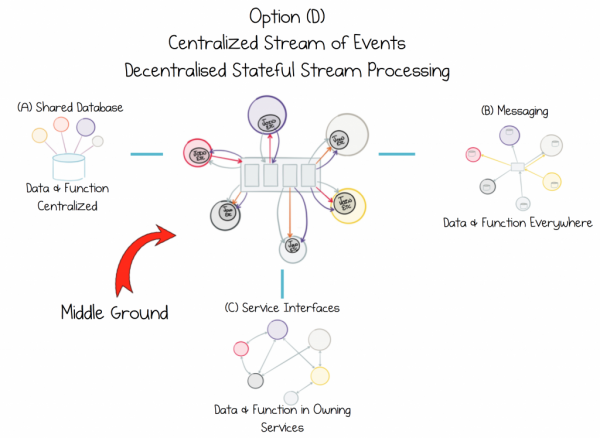
Sdílejte data, aniž byste narušili jejich integritu. Zapouzdřte funkci, nikoli zdroj, do každé služby, která to potřebuje.
Stává se, že je potřeba hromadně přesouvat data. Někdy služba vyžaduje místní historickou datovou sadu ve vybraném databázovém stroji. Trik je v tom, že můžete zaručit, že v případě potřeby bude možné kopii obnovit ze zdroje přístupem k mechanismu distribuovaného protokolování. Konektory v Kafkovi to dělají skvěle.
Dnes diskutovaný přístup má tedy několik výhod:
- Data se používají ve formě společných toků, které mohou být uloženy v protokolech po dlouhou dobu, a mechanismus pro práci s běžnými daty je pevně zapojen v každém jednotlivém kontextu, což umožňuje službám pracovat snadno a rychle. Tímto způsobem lze vyvážit dichotomii dat.
- Data pocházející z různých služeb lze snadno kombinovat do sad. To zjednodušuje interakci se sdílenými daty a eliminuje potřebu udržovat lokální datové sady v databázi.
- Stateful Stream Processing pouze ukládá data do mezipaměti a zdrojem pravdy zůstávají obecné protokoly, takže problém poškození dat v průběhu času není tak akutní.
- Služby jsou ve své podstatě založeny na datech, což znamená, že i přes neustále rostoucí objemy dat mohou služby stále rychle reagovat na obchodní události.
- Problémy se škálovatelností dopadají na zprostředkovatele, nikoli na služby. To výrazně snižuje složitost služeb psaní, protože není třeba přemýšlet o škálovatelnosti.
- Přidání nových služeb nevyžaduje změnu starých, takže připojení nových služeb je jednodušší.
Jak vidíte, je to víc než jen ODPOČINEK. Dostali jsme sadu nástrojů, která umožňuje pracovat se sdílenými daty decentralizovaně.
Ne všechny aspekty byly v dnešním článku popsány. Stále musíme vymyslet, jak vyvážit paradigma žádost-odpověď a paradigma řízené událostmi. Ale tím se budeme zabývat příště. Jsou témata, která potřebujete lépe poznat, například proč je Stateful Stream Processing tak dobrý. O tom si povíme ve třetím článku. A existují další silné konstrukty, které můžeme využít, pokud se k nim uchýlíme, např. . Jedná se o změnu hry pro distribuované obchodní systémy, protože poskytuje transakční záruky ve škálovatelné podobě. O tom bude řeč ve čtvrtém článku. Nakonec si budeme muset projít detaily implementace těchto principů.
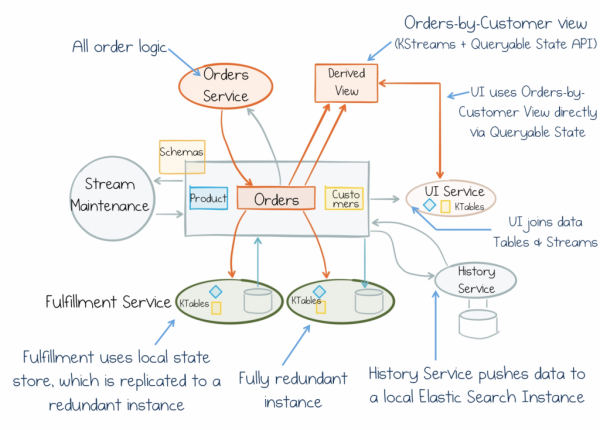
Ale zatím si pamatujte jen toto: datová dichotomie je síla, které čelíme při budování obchodních služeb. A toto si musíme pamatovat. Trik je v tom postavit vše na hlavu a začít se sdílenými daty zacházet jako s prvotřídními objekty. Stateful Stream Processing pro to poskytuje jedinečný kompromis. Vyhýbá se centralizovaným „Božím komponentům“, které brzdí pokrok. Navíc zajišťuje agilitu, škálovatelnost a odolnost kanálů pro streamování dat a přidává je do každé služby. Můžeme se proto zaměřit na obecný proud vědomí, ke kterému se může připojit jakákoli služba a pracovat se svými daty. Díky tomu jsou služby škálovatelnější, zaměnitelné a autonomní. Budou tedy nejen dobře vypadat na tabulích a testech hypotéz, ale budou také fungovat a vyvíjet se desítky let.
Zdroj: www.habr.com
