

Vážená komunito, tento článek se zaměří na efektivní ukládání a načítání stovek milionů malých souborů. V této fázi je navrženo konečné řešení pro souborové systémy kompatibilní s POSIX s plnou podporou zámků, včetně clusterových zámků, a zdánlivě dokonce bez berliček.
Tak jsem si pro tento účel napsal svůj vlastní server.
V průběhu realizace tohoto úkolu se nám podařilo vyřešit hlavní problém a zároveň dosáhnout úspory místa na disku a RAM, které náš clusterový souborový systém nemilosrdně spotřebovával. Ve skutečnosti je takový počet souborů škodlivý pro jakýkoli seskupený souborový systém.
Myšlenka je tato:
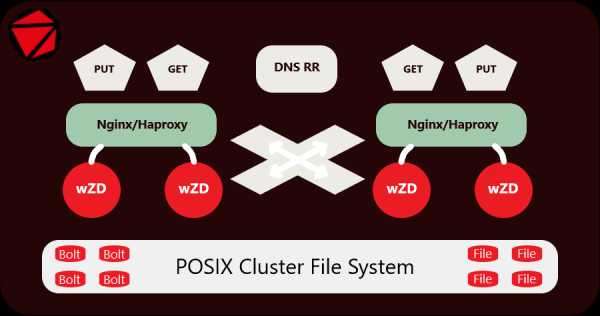
Jednoduše řečeno, malé soubory se nahrávají přes server, ukládají se přímo do archivu a také se z něj čtou a velké soubory jsou umístěny vedle sebe. Schéma: 1 složka = 1 archiv, celkem máme několik milionů archivů s malými soubory a ne několik set milionů souborů. A to vše je implementováno plně, bez jakýchkoli skriptů nebo vkládání souborů do archivů tar/zip.
Pokusím se to zkrátit, předem se omlouvám, pokud je příspěvek dlouhý.
Všechno to začalo tím, že jsem na světě nenašel vhodný server, který by dokázal ukládat data přijatá přes HTTP protokol přímo do archivů, bez nevýhod, které mají klasické archivy a objektové úložiště. A důvodem pro hledání byl Origin cluster 10 serverů, který se rozrostl do velkého měřítka, ve kterém se již nashromáždilo 250,000,000 XNUMX XNUMX malých souborů a růstový trend se nezastavil.
Pro ty, kteří neradi čtou články, je snazší malá dokumentace:
и .
A zároveň docker, nyní existuje možnost pouze s nginx uvnitř pro případ:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdDalší:
Pokud je souborů hodně, jsou potřeba značné zdroje a nejhorší na tom je, že některé z nich jsou plýtvány. Například při použití klastrovaného souborového systému (v tomto případě MooseFS) soubor bez ohledu na jeho skutečnou velikost vždy zabírá minimálně 64 KB. To znamená, že pro soubory o velikosti 3, 10 nebo 30 KB je na disku vyžadováno 64 KB. Pokud je souborů čtvrt miliardy, ztratíme 2 až 10 terabajtů. Nové soubory nebude možné vytvářet donekonečna, protože MooseFS má omezení: ne více než 1 miliarda s jednou replikou každého souboru.
S rostoucím počtem souborů je pro metadata potřeba hodně paměti RAM. K opotřebení SSD disků přispívají také časté velké skládky metadat.
server wZD. Dáme věci do pořádku na discích.
Server je napsán v Go. V první řadě jsem potřeboval snížit počet souborů. Jak to udělat? Kvůli archivaci, ale v tomto případě bez komprese, protože moje soubory jsou pouze komprimované obrázky. Na pomoc přišel BoltDB, který ještě musel být odstraněn ze svých nedostatků, to se odráží v dokumentaci.
Celkem místo čtvrt miliardy souborů v mém případě zbylo jen 10 milionů archivů Bolt. Pokud bych měl možnost změnit aktuální adresářovou strukturu souborů, bylo by možné ji zmenšit na přibližně 1 milion souborů.
Všechny malé soubory jsou zabaleny do archivů Bolt, které automaticky obdrží názvy adresářů, ve kterých se nacházejí, a všechny velké soubory zůstávají vedle archivů, nemá smysl je balit, je to přizpůsobitelné. Malé jsou archivovány, velké jsou ponechány beze změny. Server pracuje transparentně s oběma.
Architektura a vlastnosti serveru wZD.

Server pracuje pod kontrolou operačních systémů Linux, BSD, Solaris a OSX. Testoval jsem pouze architekturu AMD64 pod Linux, ale mělo by to fungovat i pro ARM64, PPC64 a MIPS64.
Hlavní rysy:
- Vícevláknové zpracování;
- Multiserver poskytující odolnost proti chybám a vyvažování zátěže;
- Maximální transparentnost pro uživatele nebo vývojáře;
- Podporované metody HTTP: GET, HEAD, PUT a DELETE;
- Řízení chování při čtení a zápisu prostřednictvím klientských hlaviček;
- Podpora flexibilních virtuálních hostitelů;
- Podpora integrity dat CRC při zápisu/čtení;
- Polodynamické vyrovnávací paměti pro minimální spotřebu paměti a optimální vyladění výkonu sítě;
- Odložené zhuštění dat;
- Kromě toho je nabízen vícevláknový archivátor wZA pro migraci souborů bez zastavení služby.
Skutečná zkušenost:
Server a archivátor jsem vyvíjel a testoval na živých datech poměrně dlouho, nyní úspěšně funguje na clusteru, který obsahuje 250,000,000 15,000,000 10 malých souborů (obrázků) umístěných v 2 2 XNUMX adresářích na samostatných SATA discích. Cluster XNUMX serverů je server Origin nainstalovaný za sítí CDN. K jeho obsluze se používají XNUMX servery Nginx + XNUMX servery wZD.
Pro ty, kteří se rozhodnou používat tento server, by bylo moudré před použitím naplánovat strukturu adresářů, pokud je to možné. Dovolte mi, abych si hned zarezervoval, že server není určen k tomu, aby vše nacpal do 1 Bolt archivu.
Testování výkonu:
Čím menší je velikost zazipovaného souboru, tím rychleji se na něm provádějí operace GET a PUT. Porovnejme celkovou dobu zápisu HTTP klienta do běžných souborů a archivů Bolt a také čtení. Porovnávána je práce se soubory o velikosti 32 KB, 256 KB, 1024 KB, 4096 KB a 32768 KB.
Při práci s archivy Bolt se kontroluje integrita dat každého souboru (používá se CRC), před záznamem i po záznamu dochází k průběžnému čtení a přepočítávání, to samozřejmě přináší zpoždění, ale hlavní je bezpečnost dat.
Provedl jsem výkonnostní testy na SSD discích, protože testy na SATA discích neukazují jasný rozdíl.
Grafy založené na výsledcích testování:
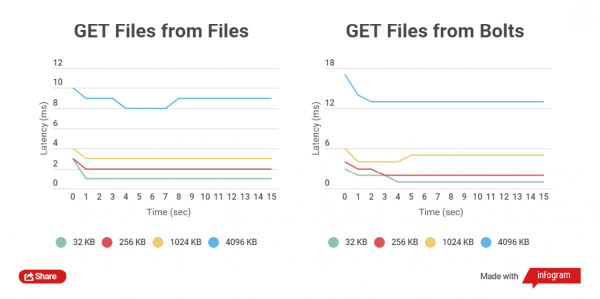
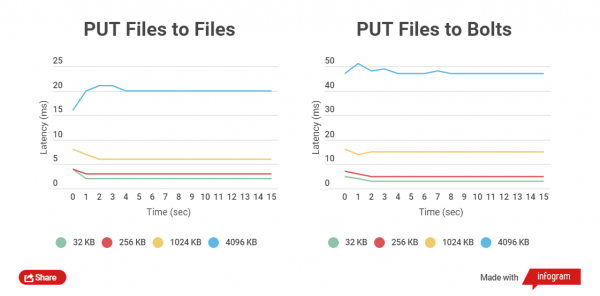
Jak vidíte, u malých souborů je rozdíl v dobách čtení a zápisu mezi archivovanými a nearchivovanými soubory malý.
Zcela jiný obrázek získáme při testování čtení a zápisu souborů o velikosti 32 MB:
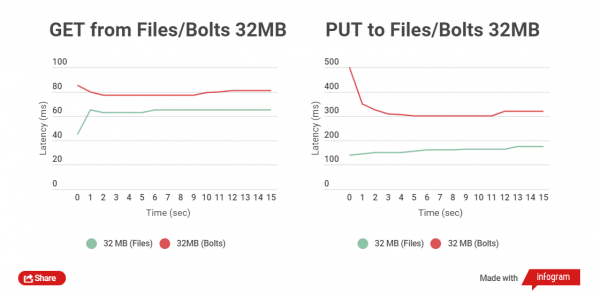
Časový rozdíl mezi čtením souborů je 5-25 ms. S nahráváním je to horší, rozdíl je asi 150 ms. V tomto případě však není nutné nahrávat velké soubory, prostě to nemá smysl, mohou žít odděleně od archivů.
*Technicky můžete tento server použít pro úlohy vyžadující NoSQL.
Základní metody práce se serverem wZD:
Načítání běžného souboru:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgNahrání souboru do archivu Bolt (pokud není překročen serverový parametr fmaxsize, který určuje maximální velikost souboru, která může být zahrnuta do archivu; pokud je překročena, soubor se nahraje jako obvykle vedle archivu):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgStahování souboru (pokud jsou na disku a v archivu soubory se stejnými názvy, pak při stahování má ve výchozím nastavení prioritu nearchivovaný soubor):
curl -o test.jpg http://localhost/test/test.jpgStažení souboru z archivu Bolt (vynucené):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgPopisy dalších metod jsou v dokumentaci.
Server zatím podporuje pouze protokol HTTP, s HTTPS zatím nepracuje. Metoda POST také není podporována (dosud nebylo rozhodnuto, zda je potřeba nebo ne).
Kdo se hrabe ve zdrojovém kódu, najde tam karamel, ne každému se to líbí, ale já jsem hlavní kód nesvázal s funkcemi webového frameworku, kromě obsluhy přerušení, takže ho v budoucnu mohu rychle přepsat pro téměř jakýkoli motor.
Úkoly:
- Vývoj vlastního replikátoru a distributora + geo pro možnost použití ve velkých systémech bez clusterových souborových systémů (Vše pro dospělé)
- Možnost kompletní zpětné obnovy metadat v případě jejich úplné ztráty (při použití distributora)
- Nativní protokol pro schopnost používat trvalá síťová připojení a ovladače pro různé programovací jazyky
- Pokročilé možnosti využití komponenty NoSQL
- Komprese různých typů (gzip, zstd, snappy) pro soubory nebo hodnoty v archivech Bolt a pro běžné soubory
- Šifrování různých typů pro soubory nebo hodnoty uvnitř archivů Bolt a pro běžné soubory
- Zpožděný převod videa na straně serveru, včetně GPU
Mám vše, doufám, že se tento server bude někomu hodit, licence BSD-3, dvojitá autorská práva, protože kdyby nebyla žádná společnost, kde pracuji, server by nevznikl. Jsem jediný vývojář. Byl bych vděčný za jakékoli chyby a požadavky na funkce, které najdete.
Zdroj: www.habr.com
