


Tým nabízí inženýr Rahul Bhatia z Clairvoyant o tom, jaké formáty souborů existují ve velkých datech, jaké jsou nejčastější vlastnosti formátů Hadoop a který formát je lepší použít.
Proč jsou potřeba různé formáty souborů?
Hlavním omezením výkonu aplikací s podporou HDFS, jako jsou MapReduce a Spark, je čas, který zabere vyhledávání, čtení a zápis dat. Tyto problémy jsou umocněny obtížemi při správě velkých souborů dat, pokud máme vyvíjející se schéma spíše než pevné, nebo pokud existují určitá omezení úložiště.
Zpracování velkých dat zvyšuje zátěž úložného subsystému – Hadoop ukládá data redundantně, aby dosáhl odolnosti proti chybám. Kromě disků se zatěžuje procesor, síť, vstupně/výstupní systém a tak dále. S rostoucím objemem dat rostou i náklady na jejich zpracování a uložení.
Různé formáty souborů v vynalezen k řešení právě těchto problémů. Výběr vhodného formátu souboru může poskytnout některé významné výhody:
- Rychlejší doba čtení.
- Rychlejší doba nahrávání.
- Sdílené soubory.
- Podpora pro vývoj schémat.
- Rozšířená podpora komprese.
Některé formáty souborů jsou určeny pro obecné použití, jiné pro specifičtější použití a některé jsou navrženy tak, aby splňovaly specifické datové charakteristiky. Výběr je tedy opravdu velký.
Formát souboru Avro
pro serializace dat Avro je široce používán - it na bázi řetězce, tedy formát ukládání dat řetězce v Hadoop. Ukládá schéma ve formátu JSON, což usnadňuje čtení a interpretaci jakýmkoli programem. Samotná data jsou v binárním formátu, kompaktní a efektivní.
Serializační systém Avro je jazykově neutrální. Soubory lze zpracovávat v různých jazycích, aktuálně C, C++, C#, Java, Python a Ruby.
Klíčovým rysem Avro je jeho robustní podpora pro datová schémata, která se v čase mění, tedy vyvíjejí. Avro rozumí změnám schématu – mazání, přidávání nebo změně polí.
Avro podporuje různé datové struktury. Můžete například vytvořit záznam, který obsahuje pole, výčtový typ a podzáznam.
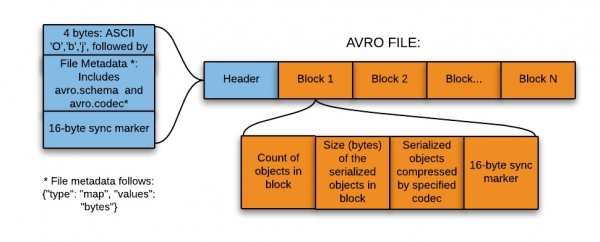
Tento formát je ideální pro zápis do přistávací (přechodové) zóny datového jezera (, neboli datové jezero - kolekce instancí pro ukládání různých typů dat vedle zdrojů dat přímo).
Tento formát je tedy nejvhodnější pro zápis do přistávací zóny datového jezera z následujících důvodů:
- Data z této zóny jsou obvykle čtena celá pro další zpracování následnými systémy – a řádkový formát je v tomto případě efektivnější.
- Následné systémy mohou snadno načítat tabulky schémat ze souborů – není třeba ukládat schémata samostatně v externím metaúložišti.
- Jakákoli změna původního schématu se snadno zpracuje (vývoj schématu).
Formát souboru parket
Parquet je souborový formát s otevřeným zdrojovým kódem pro Hadoop, který se ukládá vnořené datové struktury v plochém sloupcovém formátu.
Ve srovnání s tradičním řádkovým přístupem je Parquet efektivnější z hlediska skladování a výkonu.
To je užitečné zejména pro dotazy, které čtou konkrétní sloupce z široké tabulky (s mnoha sloupci). Díky formátu souboru se čtou pouze potřebné sloupce, takže I/O jsou omezeny na minimum.
Malá odbočka a vysvětlení: Abychom lépe porozuměli formátu souboru Parquet v Hadoopu, podívejme se, co je sloupcový - tedy sloupcový - formát. Tento formát ukládá podobné hodnoty pro každý sloupec společně.
, záznam obsahuje pole ID, Name a Department. V tomto případě budou všechny hodnoty sloupce ID uloženy společně, stejně jako hodnoty sloupce Name a tak dále. Tabulka bude vypadat nějak takto:
ID
Jméno
oddělení
1
emp1
d1
2
emp2
d2
3
emp3
d3
Ve formátu řetězce budou data uložena následovně:
1
emp1
d1
2
emp2
d2
3
emp3
d3
Ve sloupcovém formátu souboru budou stejná data uložena takto:
1
2
3
emp1
emp2
emp3
d1
d2
d3
Sloupcový formát je efektivnější, když potřebujete dotazovat více sloupců z tabulky. Přečte pouze požadované sloupce, protože spolu sousedí. Tímto způsobem jsou I/O operace omezeny na minimum.
Potřebujete například pouze sloupec NAME. V Každý záznam v datové sadě je třeba načíst, analyzovat podle pole a poté extrahovat data NAME. Formát sloupce umožňuje přejít přímo na sloupec Název, protože všechny hodnoty pro tento sloupec jsou uloženy společně. Nemusíte skenovat celý záznam.
Sloupcový formát tedy zlepšuje výkon dotazů, protože vyžaduje kratší dobu vyhledávání k získání požadovaných sloupců a snižuje počet I/O operací, protože se čtou pouze požadované sloupce.
Jedna z jedinečných funkcí je, že v tomto formátu může ukládat data s vnořenými strukturami. To znamená, že v souboru Parquet lze jednotlivě číst i vnořená pole, aniž by bylo nutné číst všechna pole ve vnořené struktuře. Parquet používá k ukládání vnořených struktur algoritmus drcení a sestavování.
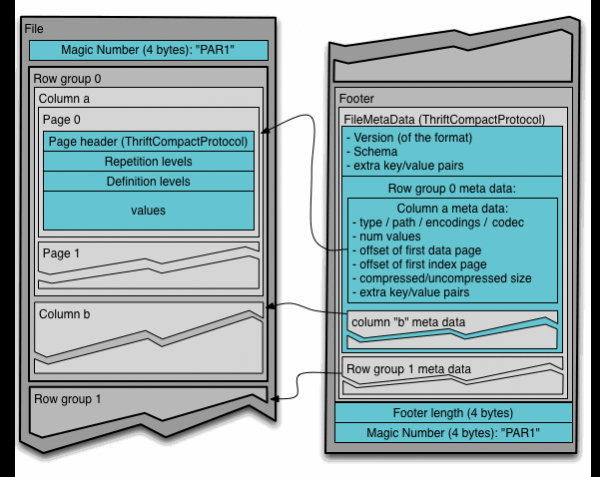
Chcete-li porozumět formátu souboru Parquet v Hadoop, musíte znát následující termíny:
- Skupina řetězců (skupina řádků): logické horizontální rozdělení dat do řádků. Skupina řádků se skládá z fragmentu každého sloupce v sadě dat.
- Fragment sloupce (column chunk): Fragment konkrétního sloupce. Tyto fragmenty sloupců žijí ve specifické skupině řádků a je zaručeno, že budou v souboru souvislé.
- Page (stránka): Fragmenty sloupců jsou rozděleny na stránky psané za sebou. Stránky mají společný název, takže nepotřebné můžete při čtení přeskakovat.
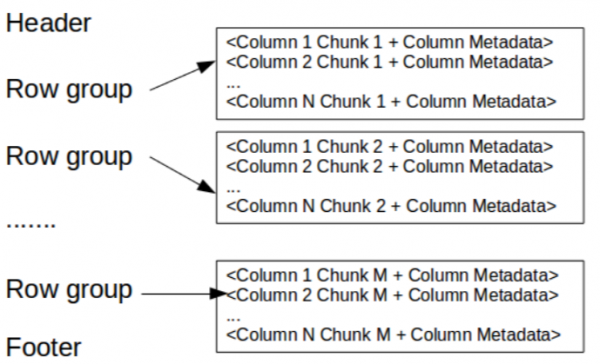
Zde název obsahuje pouze magické číslo PAR1 (4 bajty), který identifikuje soubor jako soubor Parquet.
Zápatí říká následující:
- Soubor metadat, která obsahují počáteční souřadnice metadat každého sloupce. Při čtení musíte nejprve přečíst metadata souboru, abyste našli všechny fragmenty sloupců, které vás zajímají. Části sloupce by se pak měly odečítat postupně. Další metadata zahrnují verzi formátu, schéma a jakékoli další páry klíč–hodnota.
- Délka metadat (4 bajty).
- magické číslo PAR1 (4 byty).
Formát souboru ORC
Optimalizovaný formát souboru řádků a sloupců (Optimalizovaný sloupec řádku, ) nabízí velmi efektivní způsob ukládání dat a byl navržen tak, aby překonal omezení jiných formátů. Ukládá data v dokonale kompaktní podobě, což vám umožňuje přeskočit zbytečné detaily – bez nutnosti vytváření velkých, složitých nebo ručně udržovaných indexů.
Výhody formátu ORC:
- Výstupem každé úlohy je jeden soubor, což snižuje zatížení NameNode (název uzlu).
- Podpora pro datové typy Hive, včetně DateTime, desítkové a komplexní datové typy (struct, list, map a union).
- Současné čtení stejného souboru různými procesy RecordReaderu.
- Schopnost rozdělit soubory bez skenování značek.
- Odhad maximální možné alokace paměti haldy pro procesy čtení/zápisu na základě informací v zápatí souboru.
- Metadata jsou uložena v binárním serializačním formátu Protocol Buffers, který umožňuje přidávat a odebírat pole.
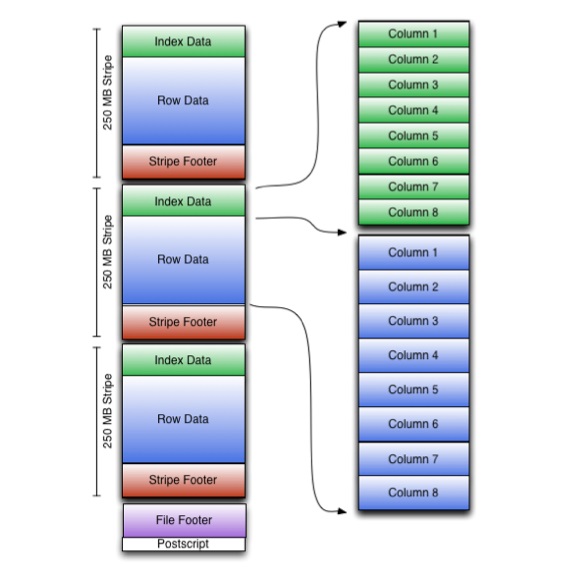
ORC ukládá kolekce řetězců do jednoho souboru a v rámci kolekce jsou data řetězců uložena ve sloupcovém formátu.
Soubor ORC ukládá skupiny řádků nazývaných pruhy a podpůrné informace v zápatí souboru. Postscript na konci souboru obsahuje parametry komprese a velikost komprimovaného zápatí.
Výchozí velikost pruhu je 250 MB. Díky takto velkým pruhům se čtení z HDFS provádí efektivněji: ve velkých souvislých blocích.
Zápatí souboru zaznamenává seznam pruhů v souboru, počet řádků na pruh a datový typ každého sloupce. Je tam zapsána i výsledná hodnota count, min, max a sum pro každý sloupec.
Zápatí stripu obsahuje adresář umístění streamů.
Data řádků se používají při skenování tabulek.
Data indexu zahrnují minimální a maximální hodnoty pro každý sloupec a pozici řádků v každém sloupci. Indexy ORC se používají pouze pro výběr pruhů a skupin řádků, nikoli pro odpovídání na dotazy.
Porovnání různých formátů souborů
Avro ve srovnání s parketami
- Avro je formát pro ukládání řádků, zatímco Parquet ukládá data ve sloupcích.
- Parquet se lépe hodí pro analytické dotazy, což znamená, že operace čtení a dotazování na data jsou mnohem efektivnější než zápisy.
- Operace zápisu v Avro se provádějí efektivněji než v Parquet.
- Avro se evolucí obvodů zabývá vyzrálěji. Parquet podporuje pouze přidávání schémat, zatímco Avro podporuje multifunkční evoluci, tedy přidávání nebo změnu sloupců.
- Parquet je ideální pro dotazování na podmnožinu sloupců ve vícesloupcové tabulce. Avro je vhodné pro ETL operace, kde se dotazujeme na všechny sloupce.
ORC vs parkety
- Parket lépe ukládá vnořená data.
- ORC je vhodnější pro predikátové pushdown.
- ORC podporuje vlastnosti ACID.
- ORC komprimuje data lépe.
Co si k tématu ještě přečíst:
- .
- .
- .
Zdroj: www.habr.com
