

V tomto článku vám představuji své úvahy o historii a perspektivách rozvoje internetu, centralizovaných a decentralizovaných sítí a v důsledku toho o možné architektuře decentralizované sítě příští generace.
S internetem je něco špatně
S internetem jsem se poprvé seznámil v roce 2000. Samozřejmě to není zdaleka úplný začátek - Síť existovala již před tím, ale tuto dobu lze označit za první rozkvět internetu. World Wide Web je důmyslným vynálezem Tima Bernerse-Leeho, web 1.0 ve své klasické kanonické podobě. Mnoho webů a stránek se navzájem propojuje hypertextovými odkazy. Architektura je na první pohled jednoduchá, jako všechny důmyslné věci: decentralizované a bezplatné. Chci – cestuji na stránky jiných lidí pomocí hypertextových odkazů; Chci si vytvořit vlastní web, na kterém budu zveřejňovat to, co mě zajímá – například své články, fotografie, programy, hypertextové odkazy na stránky, které jsou pro mě zajímavé. A ostatní mi posílají odkazy.
Zdá se vám to jako idylický obrázek? Ale vy už víte, jak to všechno skončilo.
Existuje příliš mnoho stránek a hledání informací se stalo velmi netriviálním úkolem. Hypertextové odkazy předepsané autory jednoduše nemohly strukturovat toto obrovské množství informací. Nejprve to byly ručně vyplněné adresáře a poté obří vyhledávače, které začaly používat důmyslné heuristické algoritmy hodnocení. Webové stránky byly vytvořeny a opuštěny, informace byly duplikovány a zkresleny. Internet se rychle komercializoval a vzdaloval se ideální akademické síti. Značkovací jazyk se rychle stal formátovacím jazykem. Objevila se reklama, ošklivé otravné bannery a technologie pro propagaci a klamání vyhledávačů - SEO. Síť se rychle zanášela informačním odpadem. Hypertextové odkazy přestaly být nástrojem logické komunikace a staly se nástrojem propagace. Webové stránky se uzavřely do sebe, změnily se z otevřených „stránek“ na zapečetěné „aplikace“ a staly se jediným prostředkem generování příjmů.
Už tehdy jsem měl určitou myšlenku, že „tady je něco špatně“. Spousta různých webů, od primitivních domovských stránek s vykulenýma očima až po „megaportály“ přeplněné blikajícími bannery. I když jsou stránky na stejné téma, vůbec spolu nesouvisí, každá má svůj design, svou strukturu, otravné bannery, špatně fungující vyhledávání, problémy se stahováním (ano, chtěl jsem mít informace offline). Už tehdy se internet začínal měnit v jakousi televizi, kde se k užitečnému obsahu přibíjela nejrůznější pozlátka.
Decentralizace se stala noční můrou.
Co chceš?
Je to paradoxní, ale ani tehdy, když jsem ještě nevěděl o webu 2.0 nebo p2p, jsem jako uživatel decentralizaci nepotřeboval! Když si vzpomenu na své nezamlžené myšlenky o té době, docházím k závěru, že jsem potřeboval... jednotná databáze! Takový dotaz, pro který by vrátil všechny výsledky, a ne ty, které jsou nejvhodnější pro algoritmus hodnocení. Takový, ve kterém by všechny tyto výsledky byly navrženy jednotně a stylizovány mým vlastním jednotným designem, a ne okem valícími se vlastními návrhy mnoha Vasya Pupkins. Takový, který by se dal uložit offline a nebát se, že zítra web zmizí a informace budou navždy ztraceny. Takový, do kterého jsem mohl zadat své informace, jako jsou komentáře a štítky. Takový, ve kterém jsem mohl vyhledávat, třídit a filtrovat pomocí svých vlastních osobních algoritmů.
Web 2.0 a sociální sítě
Mezitím do arény vstoupil koncept Web 2.0. V roce 2005 formuloval Tim O'Reilly jako „techniku pro navrhování systémů, které se tím, že zohledňují síťové interakce, stávají tím lepšími, čím více lidí je používá“ – a znamená aktivní zapojení uživatelů do kolektivní tvorby a úpravy webového obsahu. Bez nadsázky byly vrcholem a triumfem tohoto konceptu sociální sítě. Obří platformy, které propojují miliardy uživatelů a ukládají stovky petabajtů dat.
Co jsme získali na sociálních sítích?
- sjednocení rozhraní; ukázalo se, že uživatelé nepotřebují všechny příležitosti k vytvoření různých poutavých návrhů; všechny stránky všech uživatelů mají stejný design a to vyhovuje všem a je to dokonce pohodlné; Jen obsah je jiný.
- sjednocení funkčnosti; veškerá rozmanitost skriptů se ukázala jako zbytečná. „Feed“, přátelé, alba... za dobu existence sociálních sítí se jejich funkčnost víceméně ustálila a je nepravděpodobné, že by se změnila: vždyť funkčnost je dána typy činností lidí a lidé se prakticky nemění .
- jediná databáze; ukázalo se, že je mnohem pohodlnější pracovat s takovou databází než s mnoha různorodými weby; vyhledávání je mnohem jednodušší. Namísto neustálého skenování různých volně souvisejících stránek, ukládání do mezipaměti, hodnocení pomocí složitých heuristických algoritmů – relativně jednoduchý jednotný dotaz do jediné databáze se známou strukturou.
- rozhraní zpětné vazby - lajky a opětovné příspěvky; na běžném webu nemohl stejný Google získat zpětnou vazbu od uživatelů po kliknutí na odkaz ve výsledcích vyhledávání. Na sociálních sítích se toto spojení ukázalo jako jednoduché a přirozené.
co jsme ztratili? Ztratili jsme decentralizaci, což znamená svobodu. Předpokládá se, že naše data nám nyní nepatří. Pokud jsme dříve mohli umístit domovskou stránku i na svůj vlastní počítač, nyní dáváme všechna svá data internetovým gigantům.
Navíc, jak se internet rozvíjel, začaly se o něj zajímat vlády a korporace, což vyvolalo problémy politické cenzury a omezení autorských práv. Naše stránky na sociálních sítích mohou být zakázány a smazány, pokud obsah neodpovídá jakýmkoli pravidlům sociální sítě; za nedbalý příspěvek - vyvodit správní a dokonce i trestní odpovědnost.
A teď znovu přemýšlíme: neměli bychom vrátit decentralizaci? Ale v jiné podobě, bez nedostatků prvního pokusu?
Peer-to-peer sítě
První p2p sítě se objevily dávno před webem 2.0 a vyvíjely se souběžně s vývojem webu. Hlavní klasickou aplikací p2p je sdílení souborů; první sítě byly vyvinuty pro výměnu hudby. První sítě (jako Napster) byly v podstatě centralizované, a proto byly držiteli autorských práv rychle odstaveny. Následovníci šli cestou decentralizace. V roce 2000 se objevily protokoly ED2K (první klient eDokney) a Gnutella, v roce 2001 protokol FastTrack (klient KaZaA). Postupně se zvyšoval stupeň decentralizace, zlepšovaly se technologie. Systémy „fronty stahování“ byly nahrazeny torrenty a objevil se koncept distribuovaných hashovacích tabulek (DHT). Jak státy utahují šrouby, anonymita účastníků je stále více žádaná. Síť Freenet se vyvíjí od roku 2000, I2003P od roku 2 a v roce 2006 byl spuštěn projekt RetroShare. Můžeme zmínit četné p2p sítě, dříve existující i již zaniklé a v současnosti fungující: WASTE, MUTE, TurtleF2F, RShare, PerfectDark, ARES, Gnutella2, GNUNet, IPFS, ZeroNet, Tribbler a mnoho dalších. Mnoho z nich. Jsou rozdílní. Velmi odlišné - jak účelově, tak designově... Pravděpodobně mnoho z vás všechny tyto názvy ani nezná. A to není vše.
P2p sítě však mají mnoho nevýhod. Kromě technických nedostatků, které jsou vlastní každému konkrétnímu protokolu a klientské implementaci, si můžeme například všimnout docela obecné nevýhody – složitosti vyhledávání (tedy všeho, s čím se Web 1.0 setkal, ovšem v ještě složitější verzi). Není zde žádný Google s jeho všudypřítomným a okamžitým vyhledáváním. A pokud pro sítě pro sdílení souborů můžete stále používat vyhledávání podle názvu souboru nebo meta informací, pak najít něco, řekněme, v cibulových nebo i2p překryvných sítích je velmi obtížné, ne-li nemožné.
Obecně, pokud nakreslíme analogie s klasickým internetem, pak většina decentralizovaných sítí uvízla někde na úrovni FTP. Představte si internet, ve kterém není nic jiného než FTP: žádné moderní stránky, žádný web2.0, žádný Youtube... To je přibližně stav decentralizovaných sítí. A i přes jednotlivé pokusy něco změnit, změn je zatím málo.
Obsah
Pojďme k dalšímu důležitému dílku této skládačky – obsahu. Obsah je hlavním problémem jakéhokoli internetového zdroje, a zejména decentralizovaného. Odkud to získat? Samozřejmě se můžete spolehnout na hrstku nadšenců (jak je tomu u stávajících p2p sítí), ale pak bude vývoj sítě poměrně dlouhý a obsahu tam bude málo.
Práce s běžným internetem znamená vyhledávání a studium obsahu. Někdy - ukládání (pokud je obsah zajímavý a užitečný, pak mnozí, zejména ti, kteří přišli na internet v dobách vytáčení - včetně mě - jej prozíravě ukládají offline, aby se neztratili; protože internet je věc mimo naši kontrolu, dnes je tam web zítra tam není , dnes je na YouTube video - zítra bude smazáno atd.
A u torrentů (které vnímáme spíše jen jako způsob doručování než jako p2p síť) je úspora obecně implikována. A to je mimochodem jeden z problémů s torrenty: jednou stažený soubor je obtížné přesunout tam, kde je to pohodlnější (zpravidla musíte distribuci ručně regenerovat) a absolutně jej nelze přejmenovat ( můžete to pevně propojit, ale jen velmi málo lidí o tom ví).
Obecně platí, že mnoho lidí ukládá obsah tak či onak. Jaký je jeho budoucí osud? Uložené soubory obvykle končí někde na disku, ve složce jako Stažené soubory, na obecné hromadě a leží tam spolu s mnoha tisíci dalšími soubory. To je špatné – a špatné pro samotného uživatele. Pokud má internet vyhledávače, pak místní počítač uživatele nic podobného nemá. Je dobré, když je uživatel úhledný a zvyklý třídit „příchozí“ stažené soubory. Ale ne všichni jsou takoví...
Ve skutečnosti je nyní mnoho těch, kteří nic nešetří, ale spoléhají výhradně na online. Ale v sítích p2p se předpokládá, že obsah je uložen lokálně na zařízení uživatele a distribuován dalším účastníkům. Lze najít řešení, které umožní oběma kategoriím uživatelů zapojit se do decentralizované sítě beze změny jejich návyků a navíc jim usnadní život?
Myšlenka je docela jednoduchá: co kdybychom vytvořili prostředek pro ukládání obsahu z běžného internetu, pohodlný a transparentní pro uživatele, a chytré ukládání - se sémantickými metainformacemi, a ne na společné hromadě, ale ve specifické struktuře s možnost dalšího strukturování a zároveň distribuci uloženého obsahu do decentralizované sítě?
Začněme ukládáním
Nebudeme uvažovat o utilitárním využití internetu pro prohlížení předpovědí počasí nebo letových řádů. Nás zajímají spíše soběstačné a víceméně neměnné předměty - články (od tweetů/příspěvků ze sociálních sítí až po velké články, jako zde na Habré), knihy, obrázky, programy, audio a video nahrávky. Odkud informace většinou pocházejí? Obvykle toto
- sociální sítě (různé zprávy, drobné poznámky – „tweety“, obrázky, zvuk a video)
- články o tematických zdrojích (např. Habr); Dobrých zdrojů není mnoho, většinou jsou tyto zdroje také postaveny na principu sociálních sítí
- zpravodajské weby
Zpravidla existují standardní funkce: „like“, „repost“, „sdílení na sociálních sítích“ atd.
Pojďme si některé představit plugin prohlížeče, který speciálně uloží vše, co se nám líbilo, přeposlalo, uložilo do „oblíbených“ (nebo kliklo na speciální tlačítko pluginu zobrazené v nabídce prohlížeče - v případě, že stránka nemá funkci Líbí se/repost/záložka). Hlavní myšlenkou je, že se vám to prostě líbí – jako už milionkrát předtím, a systém uloží článek, obrázek nebo video do speciálního offline úložiště a tento článek nebo obrázek bude dostupný – a vám k offline prohlížení prostřednictvím decentralizované klientské rozhraní a v nejvíce decentralizované síti! Podle mého názoru je to velmi pohodlné. Nejsou zde žádné zbytečné akce a řešíme mnoho problémů najednou:
- Zachování cenného obsahu, který se může ztratit nebo smazat
- rychlé naplnění decentralizované sítě
- agregace obsahu z různých zdrojů (můžete být registrováni v desítkách internetových zdrojů a všechny lajky/reposty budou proudit do jediné lokální databáze)
- strukturování obsahu, který vás zajímá vaše pravidla
Je zřejmé, že plugin prohlížeče musí být nakonfigurován pro strukturu každého webu (to je docela reálné - již existují pluginy pro ukládání obsahu z Youtube, Twitteru, VK atd.). Není tolik stránek, pro které má smysl dělat osobní pluginy. Zpravidla se jedná o běžné sociální sítě (je jich sotva více než desítka) a řadu kvalitních tematických stránek jako Habr (také je jich pár). S otevřeným zdrojovým kódem a specifikacemi by vývoj nového pluginu na základě šablony neměl zabrat mnoho času. U jiných webů lze použít univerzální tlačítko pro uložení, které by celou stránku uložilo v mhtml – třeba po prvním vymazání stránky od reklamy.
Nyní o strukturování
„Chytrým“ ukládáním myslím alespoň úsporu s metainformacemi: zdroj obsahu (URL), sada dříve nastavených lajků, tagů, komentářů, jejich identifikátorů atd. Při běžném ukládání se totiž tato informace ztrácí... Zdroj lze chápat nejen jako přímou URL, ale také jako sémantickou složku: například skupinu na sociální síti nebo uživatele, který provedl repost. Plugin může být dostatečně chytrý, aby tyto informace použil k automatickému strukturování a označování. Mělo by být také zřejmé, že uživatel sám může k uloženému obsahu vždy přidat nějaké metainformace, k čemuž by měly být poskytnuty nejpohodlnější nástroje rozhraní (mám spoustu nápadů, jak to udělat).
Tím je vyřešen problém strukturování a organizace lokálních souborů uživatele. Jedná se o hotový benefit, který lze využít i bez jakéhokoliv p2p. Prostě nějaká offline databáze, která ví, co, kde a v jakém kontextu jsme uložili, a umožňuje nám provádět malé studie. Najděte například uživatele externí sociální sítě, kterým se nejvíce líbily stejné příspěvky jako vy. Kolik sociálních sítí to výslovně umožňuje?
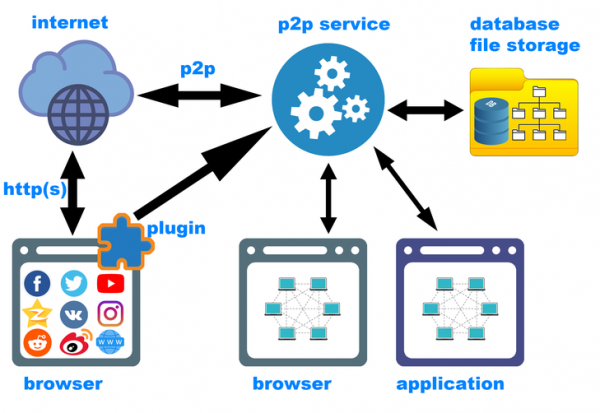
Již zde je třeba zmínit, že jeden plugin prohlížeče rozhodně nestačí. Druhou nejdůležitější součástí systému je decentralizovaná síťová služba, která běží na pozadí a obsluhuje jak samotnou p2p síť (požadavky ze sítě a požadavky od klienta), tak i ukládání nového obsahu pomocí pluginu. Služba ve spolupráci s pluginem umístí obsah na správné místo, vypočítá hashe (a případně určí, že takový obsah již byl dříve uložen) a přidá potřebné metainformace do lokální databáze.
Zajímavé je, že systém by byl užitečný již v této podobě, bez jakéhokoli p2p. Mnoho lidí používá web clippery, které přidávají zajímavý obsah z webu například do Evernote. Navrhovaná architektura je rozšířenou verzí takového clipperu.
A nakonec výměna p2p
Nejlepší na tom je, že informace a metainformace (jak zachycené z webu, tak vaše vlastní) lze vyměňovat. Koncept sociální sítě se dokonale přenáší do p2p architektury. Dá se říci, že sociální síť a p2p jako by byly stvořeny jeden pro druhého. Jakákoli decentralizovaná síť by měla být ideálně postavena jako sociální, jen tak bude efektivně fungovat. „Přátelé“, „Skupiny“ - to jsou stejní vrstevníci, se kterými by měla existovat stabilní spojení, a ty jsou převzaty z přirozeného zdroje - společných zájmů uživatelů.
Principy ukládání a distribuce obsahu v decentralizované síti jsou zcela totožné s principy ukládání (zachycování) obsahu z běžného internetu. Pokud používáte nějaký obsah ze sítě (a tedy jste si jej uložili), může kdokoli použít vaše zdroje (disk a kanál) potřebné k příjmu tohoto konkrétního obsahu.
Huskies — nejjednodušší nástroj pro ukládání a sdílení. Pokud se mi to líbilo – ať už na externím internetu nebo uvnitř decentralizované sítě – znamená to, že se mi obsah líbí, a pokud ano, pak jsem připraven ho ponechat lokálně a distribuovat dalším účastníkům v decentralizované síti.
- Obsah se „neztratí“; nyní je uložen lokálně, mohu se k němu kdykoli vrátit později, aniž bych se musel obávat, že jej někdo smaže nebo zablokuje
- Mohu jej (okamžitě nebo později) kategorizovat, označovat, komentovat, spojovat s jiným obsahem a obecně s ním dělat něco smysluplného – říkejme tomu „generování metainformací“.
- Tyto metainformace mohu sdílet s ostatními členy sítě
- Mohu synchronizovat své metainformace s metainformacemi ostatních členů
Pravděpodobně se také zdá logické vzdát se nesympatií: pokud se mi obsah nelíbí, pak je zcela logické, že nechci plýtvat místem na disku pro ukládání a svým internetovým kanálem pro distribuci tohoto obsahu. Nelíbí se proto do decentralizace příliš organicky nezapadají (i když někdy ano ).
Někdy si musíte nechat to, co se vám „nelíbí“. Existuje takové slovo jako "musí" :)
«Záložky“ (nebo „Oblíbené“) – nevyjadřuji afinitu k obsahu, ale ukládám jej do své místní databáze záložek. Slovo „oblíbené“ není svým významem úplně vhodné (k tomu existují lajky a jejich následná kategorizace), ale „záložky“ jsou docela vhodné. Obsah v „záložkách“ je také distribuován – pokud jej „potřebujete“ (to znamená, že jej „používáte“ tak či onak), je logické, že ho může „potřebovat“ někdo jiný. Proč k tomu nevyužít své zdroje?
Funkce "друзья". Jsou to vrstevníci, lidé s podobnými zájmy, a tedy ti, kteří mají s největší pravděpodobností zajímavý obsah. V decentralizované síti to primárně znamená přihlášení k odběru novinek od přátel a přístup k jejich katalogům (albům) obsahu, který si uložili.
Podobné jako funkce "skupiny“- nějaký druh společných kanálů nebo fór nebo něco, k čemu se můžete také přihlásit – a to znamená přijmout všechny materiály skupiny a distribuovat je. Možná by „skupiny“ jako velká fóra měly být hierarchické – to umožní lepší strukturování obsahu skupiny a také omezení toku informací a nepřijímání/distribuování toho, co pro vás není příliš zajímavé.
Všechen zbytek
Je třeba poznamenat, že decentralizovaná architektura je vždy složitější než centralizovaná. V centralizovaných zdrojích je přísný diktát kódu serveru. V decentralizovaných je potřeba vyjednávat mezi mnoha rovnocennými účastníky. To se samozřejmě neobejde bez kryptografie, blockchainů a dalších výdobytků vyvinutých především na kryptoměnách.
Předpokládám, že může být vyžadováno nějaké kryptografické hodnocení vzájemné důvěry, které si navzájem vytvářejí účastníci sítě. Architektura by měla umožňovat efektivní boj s botnety, které existující v určitém cloudu mohou například vzájemně zvyšovat vlastní hodnocení. Opravdu chci, aby se korporace a botnetové farmy se vší jejich technologickou převahou nechopily kontroly nad takovou decentralizovanou sítí; tak, aby jeho hlavním zdrojem byli živí lidé schopní produkovat a strukturovat obsah, který je zajímavý a užitečný pro ostatní žijící lidi.
Také chci, aby taková síť posunula civilizaci k pokroku. Mám na toto téma spoustu nápadů, které však nezapadají do rozsahu tohoto článku. Řeknu pouze, že určitým způsobem vědecký, technický, lékařský atd. obsah by měl mít přednost před zábavou, a to bude vyžadovat určitou míru moderování. Samotné moderování decentralizované sítě je netriviální úkol, ale lze jej vyřešit (slovo „moderování“ je zde však zcela nesprávné a vůbec neodráží podstatu procesu – ani navenek, ani uvnitř... a Ani mě nenapadlo, jak by se tento proces dal nazvat).
Asi je zbytečné zmiňovat nutnost zajištění anonymity – jak vestavěnými prostředky (jako v i2p nebo Retroshare), tak i průchodem veškerého provozu přes TOR, popř. VPN.
A nakonec softwarová architektura (schematicky znázorněná na obrázku připojeném k článku). Jak již bylo zmíněno, první komponentou systému je plugin prohlížeče, který zachycuje obsah s metadaty. Druhou nejdůležitější komponentou je p2p služba běžící na pozadí („backend“). Provoz sítě by samozřejmě neměl záviset na tom, zda je spuštěn prohlížeč. Třetí komponentou je klientský software – frontend. Může se jednat buď o lokální webovou službu (v takovém případě může uživatel interagovat s decentralizovanou sítí, aniž by opustil svůj oblíbený prohlížeč), nebo o samostatnou aplikaci s grafickým rozhraním pro konkrétní operační systém (Windows, Linux, MacOS, Android, iOS atd.). Líbí se mi myšlenka, že všechny varianty frontendu existují současně. To bude také vyžadovat důslednější architekturu backendu.
Existuje mnoho dalších aspektů, které nejsou zahrnuty v tomto článku. Připojení k distribuci stávajících úložišť souborů (tj. když už máte pár terabajtů čerpaných dat a necháte klienta je naskenovat, získat hashe, porovnat je s tím, co je uvnitř sítě a připojit se k distribuci, a zároveň čas získat metainformace o vlastních souborech – běžná jména, popisy, hodnocení, recenze atd.), připojení externích zdrojů metainformací (např. databáze Libgen), volitelné využití místa na disku pro ukládání zašifrovaného obsahu jiných lidí (jako ve Freenetu ), integrační architektura se stávajícími decentralizovanými sítěmi (toto je zcela temný les), myšlenka mediálního hashování (použití speciálních percepčních hashů pro mediální obsah - obrázky, zvuk a video, které vám umožní porovnávat mediální soubory stejný význam, lišící se velikostí, rozlišením atd.) a mnoho dalšího.
Krátké shrnutí článku
1. V decentralizovaných sítích neexistuje Google s jeho vyhledáváním a hodnocením – ale existuje Komunita skutečných lidí. Sociální síť s mechanismy zpětné vazby (lajky, reposty...) a sociálním grafem (přátelé, komunity...) je ideálním modelem aplikační vrstvy pro decentralizovanou síť.
2. Hlavní myšlenkou, kterou přináším tímto článkem, je automatické ukládání zajímavého obsahu z běžného internetu při nastavení like/repost; to může být užitečné bez p2p, stačí udržovat osobní archiv zajímavých informací
3. Tento obsah může také automaticky zaplnit decentralizovanou síť
4. Princip automatického ukládání zajímavého obsahu funguje i u lajků/repostů v nejvíce decentralizované síti
Zdroj: www.habr.com
