

Ahoj všichni! Jmenuji se Sasha, jsem CTO & Co-Founder v LoyaltyLab. Před dvěma lety jsme s kamarády jako všichni chudí studenti zašli večer na pivo do nejbližšího obchodu u domu. Velmi nás naštvalo, že obchodník s vědomím, že přijdeme na pivo, nenabídl slevu na chipsy nebo krekry, ačkoliv je to tak logické! Nechápali jsme, proč k této situaci dochází, a rozhodli jsme se vytvořit vlastní společnost. No a jako bonus si každý pátek vypište slevy na ty samé žetony.

A vše dospělo do bodu, kdy mluvím s materiálem o technické stránce produktu . Rádi se o naši práci podělíme s komunitou, a proto zveřejňuji svou zprávu ve formě článku.
úvod
Jako každý na začátku cesty jsme začali přehledem, jak se doporučovací systémy vyrábějí. A architektura následujícího typu se ukázala jako nejoblíbenější:

Skládá se ze dvou částí:
- Vzorkování kandidátů pro doporučení pomocí jednoduchého a rychlého modelu, obvykle na spolupráci.
- Seřazení kandidátů podle složitějšího a pomalejšího modelu obsahu, který zohledňuje všechny možné vlastnosti v datech.
Zde a níže budu používat následující termíny:
- kandidát / kandidát na doporučení - dvojice uživatel-produkt, která se může potenciálně dostat do doporučení ve výrobě.
- kandidátská metoda extrakce/extraktor/kandidátní metoda extrakce — proces nebo metoda pro extrakci „kandidátů na doporučení“ z dostupných údajů.
V prvním kroku se obvykle používají různé varianty kolaborativního filtrování. Nejpopulárnější - . Překvapivě většina článků o doporučovacích systémech odhaluje různá vylepšení kolaborativních modelů pouze v první fázi, ale nikdo nemluví o jiných metodách vzorkování. U nás přístup používání pouze kolaborativních modelů a různých optimalizací s nimi nefungoval s kvalitou, kterou jsme očekávali, a tak jsme se pustili do výzkumu konkrétně na tuto část. A na konci článku ukážu, jak moc jsme byli schopni zlepšit ALS, což byla naše základní linie.
Než přejdu k popisu našeho přístupu, je důležité poznamenat, že s doporučeními v reálném čase, kdy je pro nás důležité vzít v úvahu data, která se stala před 30 minutami, opravdu není mnoho přístupů, které mohou fungovat ve správný čas. Ale v našem případě musíme sbírat doporučení ne více než jednou denně a ve většině případů - jednou týdně, což nám dává příležitost používat složité modely a znásobit kvalitu.
Vezměme si za základ, jaké metriky ukazuje pouze ALS při extrakci kandidátů. Klíčové metriky, které sledujeme, jsou:
- Preciznost - podíl správně vybraných kandidátů z vybraných.
- Připomenout – podíl kandidátů, kteří se stali, z těch, kteří se skutečně nacházeli v cílovém intervalu.
- F1-score - F-skóre vypočtené z předchozích dvou bodů.
Podíváme se také na metriky finálního modelu po tréninku zesílení gradientu s dalšími funkcemi obsahu. Existují také 3 hlavní metriky:
- precision@5 — průměrné procento zásahů z 5 nejlepších podle pravděpodobnosti pro každého zákazníka.
- response-rate@5 — přeměna kupujících z návštěvy prodejny na nákup alespoň jedné osobní nabídky (jedna nabídka obsahuje 5 produktů).
- průměr roc-auc na uživatele – střední pro každého kupujícího.
Je důležité si uvědomit, že všechny tyto metriky jsou měřeny na , to znamená, že školení probíhá v prvních k týdnech a jako testovací data se bere k + 1 týdnů. Sezónní vzestupy/propady tak měly minimální vliv na interpretaci kvality modelů. Dále na všech grafech bude osa souřadnic označovat číslo týdne při křížové validaci a osa pořadnice bude označovat hodnotu zadané metriky. Všechny grafy jsou založeny na transakčních datech jednoho klienta, takže srovnání mezi nimi je správné.
Než začneme popisovat náš přístup, podívejme se nejprve na základní linii, kterou je model natrénovaný ALS.
Metriky pro extrakci kandidátů:
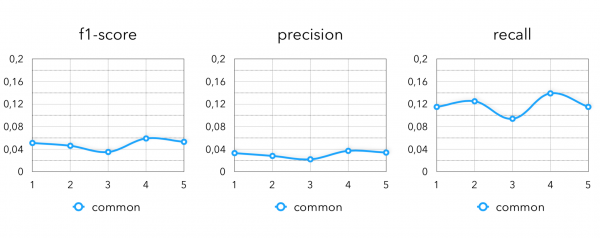
Konečné metriky:
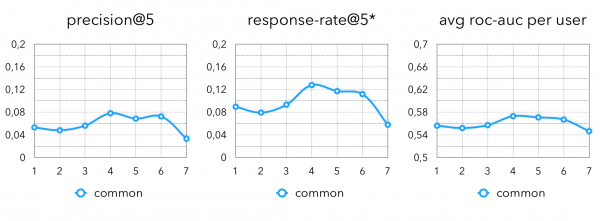
Všechny implementace algoritmů beru jako nějakou obchodní hypotézu. Jakékoli kolaborativní modely lze tedy velmi zhruba považovat za hypotézu, že „lidé mají tendenci kupovat to, co kupují lidé jako oni“. Jak jsem řekl, neomezili jsme se na takovou sémantiku a zde jsou některé hypotézy, které stále fungují na datech v offline maloobchodě:
- Co jste si předtím koupili.
- Podobné jako jsem si koupil předtím.
- Období dávno minulých nákupů.
- Populární podle kategorie/značky.
- Střídejte nákupy různého zboží týden od týdne (řetězce Markov).
- Podobné produkty jako kupující, podle vlastností vytvořených různými modely (Word2Vec, DSSM atd.).
Co jsi koupil předtím
Nejviditelnější heuristika, která velmi dobře funguje v maloobchodě s potravinami. Zde bereme veškeré zboží, které držitel věrnostní karty nakoupil za posledních K dnů (obvykle 1-3 týdny), případně K dnů před rokem. Pokud použijeme pouze tuto metodu, získáme následující metriky:
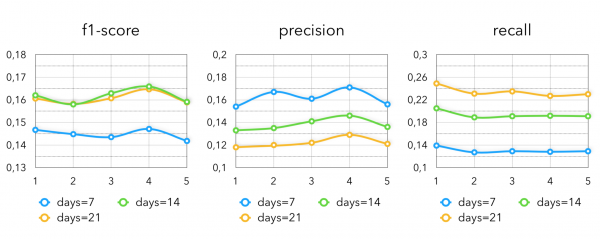
Zde je zcela zřejmé, že čím více bereme období, tím máme více zapamatovatelnosti a méně přesnosti a naopak. Lepší výsledky v průměru pro klienty dávají „poslední 2 týdny“.
Podobné jako jsem si koupil předtím
Není divu, že pro maloobchod s potravinami dobře funguje „to, co bylo nakoupeno dříve“, ale extrahovat kandidáty pouze z toho, co si uživatel již koupil, není příliš cool, protože je nepravděpodobné, že by bylo možné překvapit kupujícího nějakým novým produktem. Proto navrhujeme tuto heuristiku mírně zlepšit pomocí stejných modelů spolupráce. Z vektorů, které jsme obdrželi během školení ALS, můžete získat podobné produkty, jaké si uživatel již zakoupil. Tato myšlenka je velmi podobná „podobným videím“ ve službách pro sledování videoobsahu, ale protože nevíme, co uživatel v konkrétní chvíli jí/kupuje, můžeme hledat pouze něco podobného, co si již koupil, zvláště když už víme, jak dobře to funguje. Při použití této metody na uživatelské transakce za poslední 2 týdny získáme následující metriky:
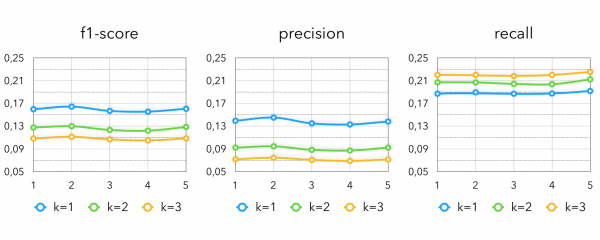
Zde k - počet podobných produktů, které jsou načteny pro každý produkt zakoupený kupujícím za posledních 14 dní.
Tento přístup se nám osvědčil zvláště u klienta, který byl kritický, aby vůbec nedoporučoval to, co již bylo v historii nákupů uživatele.
Dlouho uplynulé období nákupu
Jak jsme již zjistili, vzhledem k vysoké frekvenci nákupu zboží pro naše specifika dobře funguje první přístup. Ale co zboží jako prací prášek/šampon/atd. Tedy s produkty, které pravděpodobně nebudou potřeba každý týden nebo dva a které předchozí metody nedokážou extrahovat. Z toho vyplývá následující myšlenka - navrhuje se vypočítat dobu nákupu každého produktu v průměru pro kupující, kteří si produkt zakoupili více k jednou. A pak vytěžit to, co s největší pravděpodobností kupujícímu již došlo. Přiměřenost vypočítaných lhůt pro zboží lze zkontrolovat očima:
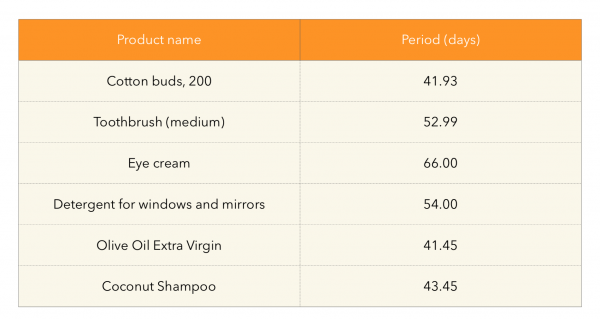
A pak uvidíme, jestli konec produktového období spadne do časového intervalu, kdy budou doporučení ve výrobě a ochutnáme, co spadne. Přístup lze znázornit takto:
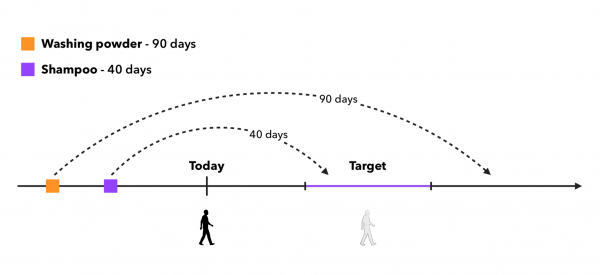
Zde máme 2 hlavní případy, které lze zvážit:
- Zda vzorky produktů pro zákazníky, kteří si produkt zakoupili méně než Kkrát.
- Zda se má produkt odebírat, pokud konec jeho období spadá před začátek cílového intervalu.
Následující graf ukazuje, jakých výsledků taková metoda dosahuje s různými hyperparametry:
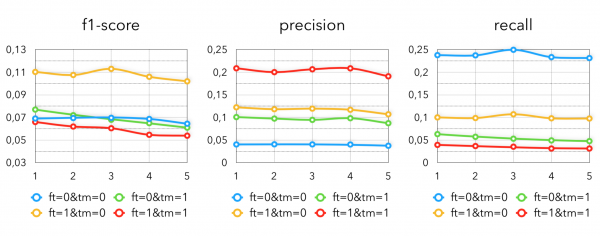
ft - Vezměte pouze kupující, kteří koupili produkt alespoň K (zde K = 5) krát
tm — Vezměte pouze kandidáty, kteří spadají do cílového intervalu
Není divu, schopný (0, 0) největší odvolání a nejmenší přesnost, protože za této podmínky je extrahováno nejvíce kandidátů. Nejlepších výsledků však dosáhneme, když neodebíráme vzorky produktů zákazníkům, kteří zakoupili konkrétní produkt méně než k časy a extrahovat mimo jiné zboží, jehož konec období spadá před cílový interval.
Oblíbené podle kategorie
Další poměrně zřejmou myšlenkou je ochutnat oblíbené produkty napříč různými kategoriemi nebo značkami. Zde kalkulujeme pro každého zákazníka top-k „oblíbené“ kategorie/značky a extrahovat „populární“ z této kategorie/značky. V našem případě budeme definovat „oblíbený“ a „oblíbený“ podle počtu nákupů produktu. Další výhodou tohoto přístupu je jeho použitelnost v případě studeného startu. Tedy pro zákazníky, kteří buď nakupovali velmi málo, nebo nebyli v prodejně delší dobu, nebo obecně mají pouze vystavenou věrnostní kartu. Pro ně je snazší a nejlepší vhodit zboží z oblíbeného u kupujících s existující historií. Metriky jsou následující:
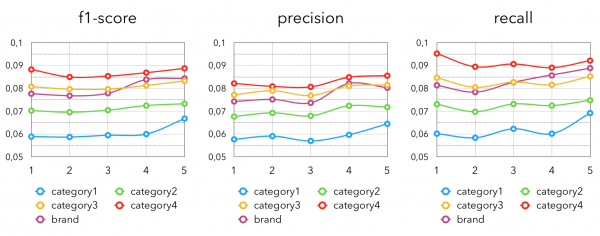
Číslo za slovem „kategorie“ zde znamená úroveň vnoření kategorie.
Obecně také není divu, že užší kategorie dosahují lepších výsledků, protože získávají přesnější „oblíbené“ produkty pro kupující.
Střídejte nákupy různého zboží z týdne na týden
Zajímavým přístupem, který jsem v článcích o doporučovacích systémech neviděl, je celkem jednoduchá a přitom fungující statistická metoda Markovových řetězců. Zde trváme 2 různé týdny, poté pro každého zákazníka sestavujeme páry produktů [koupeno v týdnu i]-[koupeno v týdnu j], kde j > i, a odtud vypočítáme pro každý produkt pravděpodobnost přechodu na jiný produkt příští týden. Tedy za každý pár zboží produktový-produktj spočítejte jejich počet v nalezených dvojicích a vydělte počtem dvojic, kde produkti byl v prvním týdnu. Chcete-li získat kandidáty, vezmeme poslední kontrolu kupujícího a dostaneme top-k nejpravděpodobnější další produkty z přechodové matice, které jsme dostali. Proces vytváření přechodové matice vypadá takto:
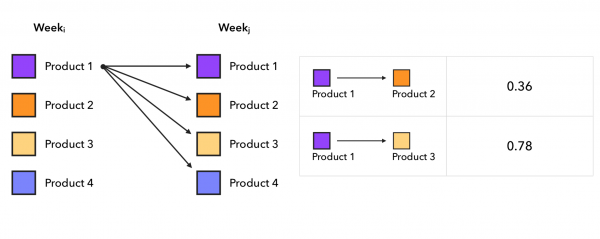
Z reálných příkladů v matici pravděpodobností přechodu vidíme následující zajímavé jevy:
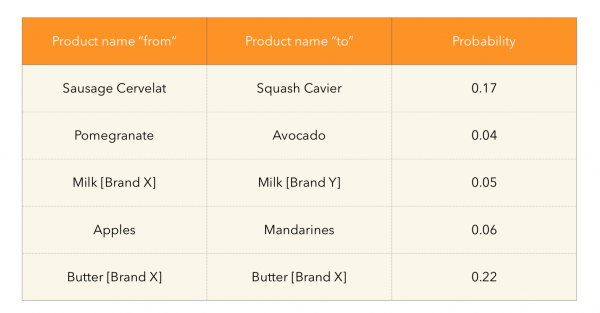
Zde si můžete všimnout zajímavých závislostí, které se odhalují ve spotřebitelském chování: například milovníci citrusů nebo značka mléka, od které s největší pravděpodobností přecházejí na jinou. Není také divu, že zde končí i položky s vysokými opakovanými nákupy, jako je máslo.
Metriky v metodě s Markovovými řetězci jsou následující:
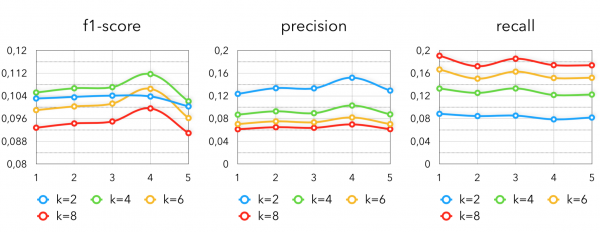
k - počet produktů, které jsou získány pro každou položku zakoupenou od poslední transakce kupujícího.
Jak vidíme, konfigurace s k=4 ukazuje nejlepší výsledek. Nárůst ve 4. týdnu lze vysvětlit sezónním chováním kolem svátků.
Podobné produkty jako kupující, podle vlastností vytvořených různými modely
Dostáváme se tedy k nejtěžší a nejzajímavější části – hledání nejbližších sousedů ve vektorech kupců a produktů sestavených podle různých modelů. V naší práci používáme 3 takové modely:
- ALS
- Word2Vec (Item2Vec pro takové úkoly)
- DSSM
ALS jsme už řešili, o tom, jak se učí, si můžete přečíst . V případě Word2Vec používáme známou implementaci modelu z gensim. Analogicky s texty definujeme nabídku jako nákupní doklad. Při konstrukci vektoru produktu se tedy model naučí předpovídat jeho „kontext“ pro produkt v účtence (zbytek zboží v účtence). V datech elektronického obchodu je lepší použít relaci kupujícího místo účtenky, kluci z . A DSSM je zajímavější na rozebrání. Původně to napsali kluci z Microsoftu jako vyhledávací model, . Architektura modelu vypadá takto:
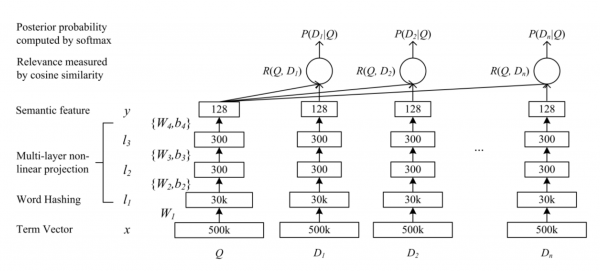
Zde Q - dotaz, vyhledávací dotaz uživatele, D[i] - dokument, webová stránka. Vstup modelu přijímá znaky požadavku a stránek. Za každou vstupní vrstvou následuje řada plně propojených vrstev (vícevrstvý perceptron). Dále se model naučí minimalizovat kosinus mezi vektory získanými v posledních vrstvách modelu.
Úlohy doporučení používají přesně stejnou architekturu, ale místo požadavku je uživatel a místo stránek jsou produkty. A v našem případě je tato architektura transformována do následujícího:
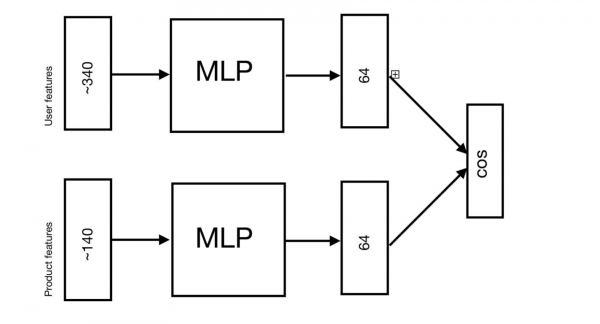
Nyní pro kontrolu výsledků zbývá pokrýt poslední bod – pokud v případě ALS a DSSM máme explicitně definované uživatelské vektory, tak v případě Word2Vec máme pouze produktové vektory. Zde, abychom vytvořili uživatelský vektor, jsme identifikovali 3 hlavní přístupy:
- Stačí přidat vektory a pro kosinusovou vzdálenost se ukáže, že jsme pouze zprůměrovali produkty v historii nakupování.
- Součet vektorů s určitou časovou vahou.
- Vážení zboží s koeficientem TF-IDF.
V případě lineárního vážení vektoru kupujícího vycházíme z hypotézy, že produkt, který uživatel včera koupil, má větší vliv na jeho chování než produkt, který si koupil před půl rokem. Zvažujeme tedy předchozí týden kupujícího s koeficientem 1 a co se stalo dále s koeficienty ½, ⅓ atd.:
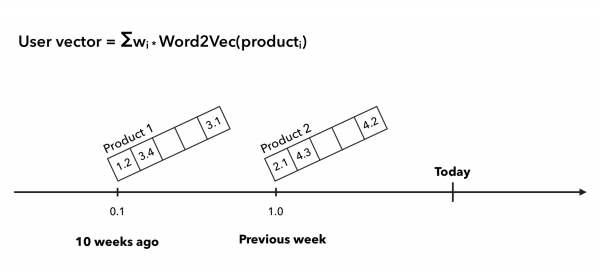
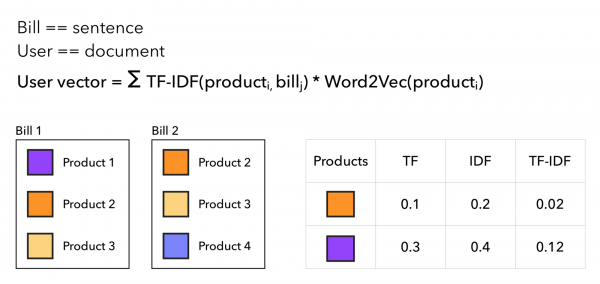
U koeficientů TF-IDF děláme úplně to samé jako u TF-IDF u textů, jen kupujícího považujeme za doklad a šek za nabídku, respektive slovo je produkt. Uživatelský vektor se tedy posune spíše k vzácnému zboží a zboží, které je časté a kupujícímu známé, to příliš nezmění. Přístup lze znázornit takto:
Nyní se podíváme na metriky. Takto vypadají výsledky ALS:
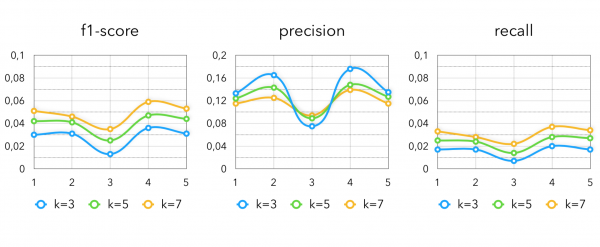
Metriky od Item2Vec s různými variantami konstrukce vektoru kupujícího:
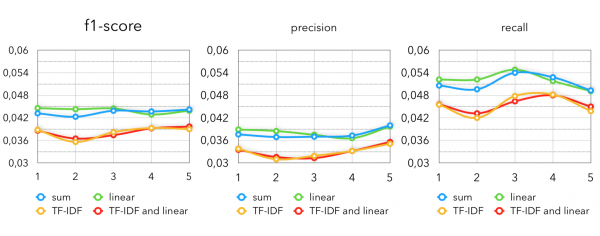
V tomto případě je použit přesně stejný model jako v naší základní linii. Jediný rozdíl je, které k použijeme. Abyste mohli používat pouze kolaborativní modely, musíte pro každého zákazníka vzít asi 50-70 nejbližších produktů.
A metriky DSSM:
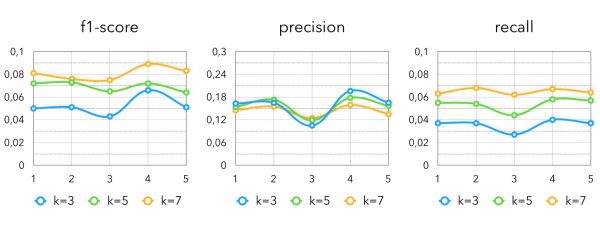
Jak zkombinovat všechny metody?
Skvělé, říkáte si, ale co dělat s tak velkou sadou nástrojů pro extrakci kandidátů? Jak zvolit optimální konfiguraci pro vaše data? Zde máme několik problémů:
- V každé metodě je nutné nějak omezit prostor pro vyhledávání hyperparametrů. Je samozřejmě všude diskrétní, ale počet možných bodů je velmi velký.
- Jak vybrat nejlepší konfiguraci pro vaši metriku pomocí malého omezeného vzorku konkrétních metod se specifickými hyperparametry?
Na první otázku jsme zatím nenašli jednoznačně správnou odpověď, takže vycházíme z následujícího: pro každou metodu je zapsán omezovač vyhledávacího prostoru hyperparametrů v závislosti na nějaké statistice dat, která máme k dispozici. Když tedy známe průměrnou dobu mezi nákupy od lidí, můžeme hádat, s jakým obdobím použít metodu „co již bylo nakoupeno“ a „období dávno minulého nákupu“.
A poté, co jsme prošli adekvátním počtem variant různých metod, poznamenáme následující: každá implementace extrahuje určitý počet kandidátů a má určitou hodnotu metriky (recall), která je pro nás klíčová. Chceme celkem získat určitý počet kandidátů v závislosti na našem přípustném výpočetním výkonu s nejvyšší možnou metrikou. Zde se problém pěkně zhroutí do problému batohu.
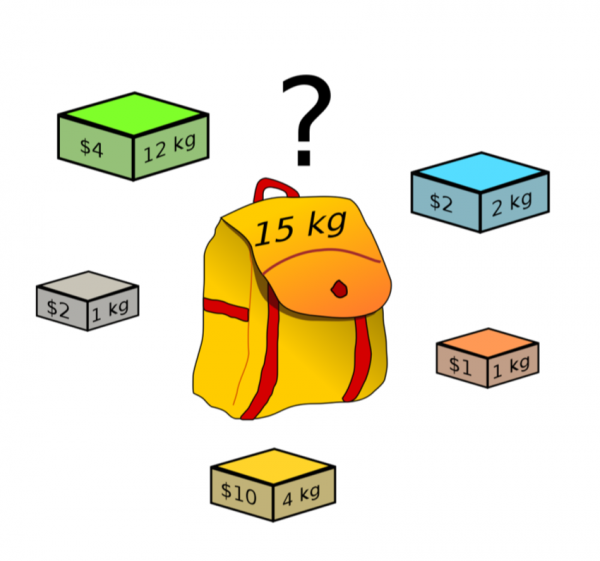
Zde je počet kandidátů hmotnost ingotu a odvolání metody je jeho hodnota. Při implementaci algoritmu je však třeba vzít v úvahu další 2 body:
- Metody se mohou u kandidátů, které vytáhnou, překrývat.
- V některých případech bude správné vzít jednu metodu dvakrát s různými parametry a kandidáti na výstupu první nebudou podmnožinou druhé.
Vezmeme-li například implementaci metody „co již bylo nakoupeno“ s různými intervaly extrakce, pak se jejich sady kandidátů vnoří do sebe. Současně různé parametry v „periodických nákupech“ na výstupu nedávají úplný průnik. Proto rozdělujeme vzorkovací metody s různými parametry do bloků tak, že z každého bloku chceme vzít maximálně jeden extrakční přístup se specifickými hyperparametry. Chcete-li to provést, musíte trochu trikovat při implementaci problému s batohem, ale asymptotika a výsledek se tím nezmění.
Taková chytrá kombinace nám umožňuje získat následující metriky ve srovnání s jednoduše kolaborativními modely:
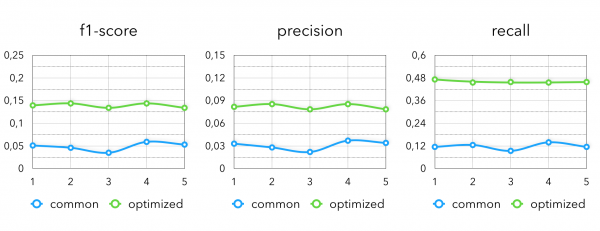
Na konečných metrikách vidíme následující obrázek:
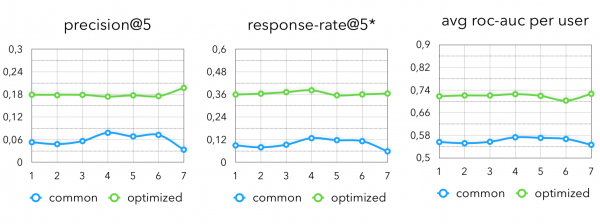
Zde však můžete vidět, že existuje jeden nepokrytý bod pro doporučení, která jsou užitečná pro podnikání. Teď jsme se jen naučili, jak v pohodě předvídat, co si uživatel koupí třeba příští týden. Ale jen tak dát slevu na to, že stejně nakoupí, není moc cool. Ale je skvělé maximalizovat očekávání například od následujících metrik:
- Marže/obrat na základě osobních doporučení.
- Průměrná kontrola kupujících.
- frekvence návštěv.
Získané pravděpodobnosti tedy vynásobíme různými koeficienty a přeřadíme je tak, aby nahoře byly produkty, které ovlivňují metriky výše. Zde neexistuje žádné hotové řešení, který přístup je lepší použít. I s takovými koeficienty experimentujeme přímo ve výrobě. Zde je ale několik zajímavých triků, které nám nejčastěji poskytují nejlepší výsledky:
- Vynásobte cenou/marží položky.
- Vynásobte průměrnou kontrolou, ve které se produkt vyskytuje. Vyjde tedy zboží, se kterým většinou berou něco jiného.
- Vynásobte průměrnou frekvencí návštěv kupujících tohoto produktu na základě hypotézy, že tento produkt u něj vyvolává častější návraty.
Po experimentování s koeficienty jsme ve výrobě získali následující metriky:
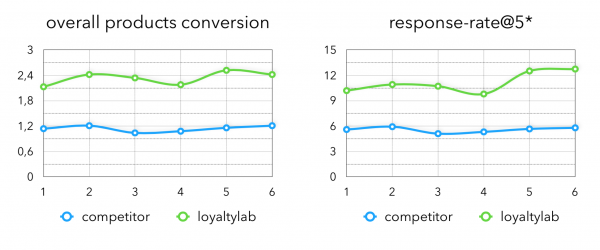
Zde celkovou konverzi produktu - podíl nakoupených produktů ze všech produktů v námi vygenerovaných doporučeních.
Pozorný čtenář si všimne výrazného rozdílu mezi offline a online metrikami. Toto chování je vysvětleno skutečností, že ne všechny dynamické filtry pro produkty, které lze doporučit, lze vzít v úvahu při trénování modelu. Je to pro nás normální příběh, kdy se podaří odfiltrovat polovinu vytěžených kandidátů, taková specifičnost je v našem oboru typická.
Pokud jde o výnosy, je získán následující příběh, je zřejmé, že po spuštění doporučení výnosy testovací skupiny silně rostou, nyní je průměrný nárůst výnosů s našimi doporučeními 3-4%:
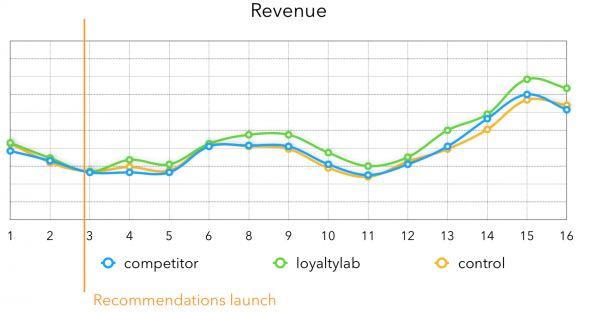
Na závěr chci říci, že pokud potřebujete doporučení, která nejsou v reálném čase, pak se v experimentech s extrakcí kandidátů na doporučení zjistí velmi velký nárůst kvality. Velké množství času na jejich generování umožňuje zkombinovat mnoho dobrých metod, které celkově přinesou podniku skvělé výsledky.
Rád si v komentářích popovídám s každým, koho materiál zaujme. Otázky mi můžete pokládat osobně . Také sdílím své myšlenky na AI/startupy v mém - vítejte 🙂
Zdroj: www.habr.com
