

Vysoký výkon je jedním z klíčových požadavků při práci s velkými daty. V oddělení načítání dat ve Sberbank pumpujeme téměř všechny transakce do našeho datového cloudu založeného na Hadoopu, a proto se zabýváme opravdu velkými toky informací. Samozřejmě stále hledáme způsoby, jak zlepšit výkon, a nyní vám chceme prozradit, jak se nám podařilo záplatovat RegionServer HBase a HDFS klienta, díky čemuž jsme dokázali výrazně zvýšit rychlost operací čtení.
Než však přejdeme k podstatě vylepšení, stojí za to mluvit o omezeních, která v zásadě nelze obejít, pokud sedíte na HDD.
Proč jsou HDD a rychlé čtení s náhodným přístupem nekompatibilní
Jak víte, HBase a mnoho dalších databází ukládá data v blocích o velikosti několika desítek kilobajtů. Ve výchozím nastavení je to asi 64 kB. Nyní si představme, že potřebujeme získat pouze 100 bajtů a požádáme HBase, aby nám tato data poskytla pomocí určitého klíče. Protože velikost bloku v HFiles je 64 KB, požadavek bude 640krát větší (pouze minuta!), než je nutné.
Dále, protože požadavek projde HDFS a jeho mechanismem mezipaměti metadat ShortCircuitCache (což umožňuje přímý přístup k souborům), to vede k přečtení již 1 MB z disku. To však lze upravit pomocí parametru dfs.client.read.shortcircuit.buffer.size a v mnoha případech má smysl tuto hodnotu snížit, například na 126 KB.
Řekněme, že to uděláme, ale navíc, když začneme číst data přes java api, jako jsou funkce jako FileChannel.read, a požádáme operační systém, aby přečetl zadané množství dat, přečte „pro jistotu“ 2krát více , tj. 256 kB v našem případě. Je to proto, že java nemá snadný způsob, jak nastavit příznak FADV_RANDOM, aby se tomuto chování zabránilo.
Výsledkem je, že pro získání našich 100 bajtů se pod kapotou přečte 2600krát více. Zdálo by se, že řešení je nasnadě, zmenšíme velikost bloku na kilobajt, nastavíme zmíněný příznak a získáme velké zrychlení osvěty. Problém je ale v tom, že dvojnásobným zmenšením velikosti bloku snížíme také dvojnásobně počet přečtených bajtů za jednotku času.
Určitý zisk z nastavení příznaku FADV_RANDOM lze získat, ale pouze s vysokým multivláknem a s velikostí bloku 128 KB, ale to je maximálně pár desítek procent:

Testy byly provedeny na 100 souborech, každý o velikosti 1 GB a umístěných na 10 HDD.
Pojďme si spočítat, s čím můžeme při této rychlosti v zásadě počítat:
Dejme tomu, že čteme z 10 disků rychlostí 280 MB/sec, tzn. 3 miliony krát 100 bajtů. Ale jak si pamatujeme, dat, která potřebujeme, je 2600krát méně než to, co se čte. Vydělíme tedy 3 miliony 2600 a dostaneme 1100 záznamů za sekundu.
Deprimující, že? To je příroda Náhodný přístup přístup k datům na HDD - bez ohledu na velikost bloku. Toto je fyzický limit náhodného přístupu a žádná databáze nemůže za takových podmínek vymáčknout více.
Jak potom databáze dosahují mnohem vyšších rychlostí? Abychom na tuto otázku odpověděli, podívejme se, co se děje na následujícím obrázku:
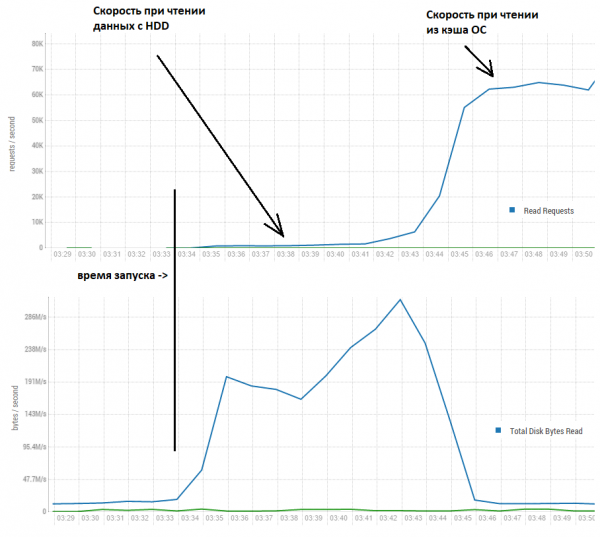
Zde vidíme, že prvních pár minut je rychlost opravdu kolem tisíce záznamů za vteřinu. Ovšem dále díky tomu, že se čte mnohem více, než bylo požadováno, data končí v buffu/cache operačního systému (linuxu) a rychlost stoupá na slušnějších 60 tisíc za vteřinu
Dále se tedy budeme zabývat zrychlením přístupu pouze k datům, která jsou v mezipaměti OS nebo se nacházejí v úložištích SSD/NVMe se srovnatelnou rychlostí přístupu.
V našem případě provedeme testy na 4 serverech, z nichž každý je zpoplatněn následovně:
CPU: Xeon E5-2680 v4 @ 2.40 GHz 64 vláken.
Paměť: 730 GB.
Java verze: 1.8.0_111
A zde je klíčovým bodem množství dat v tabulkách, které je potřeba načíst. Faktem je, že pokud čtete data z tabulky, která je celá umístěna v mezipaměti HBase, nedojde ani ke čtení z buffu/mezipaměti operačního systému. Protože HBase ve výchozím nastavení přiděluje 40 % paměti struktuře zvané BlockCache. V podstatě se jedná o ConcurrentHashMap, kde klíč je název souboru + offset bloku a hodnota jsou skutečná data v tomto offsetu.
Při čtení pouze z této struktury tedy my , jako milion požadavků za sekundu. Představme si ale, že nemůžeme alokovat stovky gigabajtů paměti jen pro potřeby databáze, protože na těchto serverech běží spousta dalších užitečných věcí.
Například v našem případě je objem BlockCache na jednom RS cca 12 GB. Na jednom uzlu jsme přistáli dvě RS, tzn. 96 GB je alokováno pro BlockCache na všech uzlech. A dat je mnohonásobně více, např. budiž 4 tabulky, každá po 130 regionech, ve kterých jsou soubory o velikosti 800 MB, komprimované FAST_DIFF, tzn. celkem 410 GB (jedná se o čistá data, tedy bez zohlednění replikačního faktoru).
BlockCache je tedy jen asi 23 % z celkového objemu dat a to je mnohem blíže reálným podmínkám toho, čemu se říká BigData. A tady začíná legrace – protože samozřejmě platí, že čím méně zásahů do mezipaměti, tím horší výkon. Když se totiž minete, budete muset udělat hodně práce - tzn. přejděte dolů na volání funkcí systému. Tomu se však nelze vyhnout, pojďme se tedy podívat na úplně jiný aspekt – co se stane s daty uvnitř mezipaměti?
Zjednodušme situaci a předpokládejme, že máme cache, do které se vejde pouze 1 objekt. Zde je příklad toho, co se stane, když se pokusíme pracovat s objemem dat 3krát větším, než je mezipaměť, budeme muset:
1. Umístěte blok 1 do mezipaměti
2. Odstraňte blok 1 z mezipaměti
3. Umístěte blok 2 do mezipaměti
4. Odstraňte blok 2 z mezipaměti
5. Umístěte blok 3 do mezipaměti
5 akcí dokončeno! Tuto situaci však nelze nazvat normální, ve skutečnosti nutíme HBase k hromadě zcela zbytečné práce. Neustále čte data z mezipaměti OS, umísťuje je do BlockCache, aby je téměř okamžitě vyhodila, protože dorazila nová část dat. Animace na začátku příspěvku ukazuje podstatu problému - Garbage Collector jde mimo měřítko, atmosféra se zahřívá, malá Greta ve vzdáleném a horkém Švédsku se rozčiluje. A my IT lidé opravdu nemáme rádi, když jsou děti smutné, takže začínáme přemýšlet, co s tím můžeme dělat.
Co když do mezipaměti nevložíte všechny bloky, ale jen určité procento z nich, aby mezipaměť nepřetekla? Začněme jednoduchým přidáním několika řádků kódu na začátek funkce pro vkládání dat do BlockCache:
public void cacheBlock(BlockCacheKey cacheKey, Cacheable buf, boolean inMemory) {
if (cacheDataBlockPercent != 100 && buf.getBlockType().isData()) {
if (cacheKey.getOffset() % 100 >= cacheDataBlockPercent) {
return;
}
}
...
Jde zde o následující: offset je pozice bloku v souboru a jeho poslední číslice jsou náhodně a rovnoměrně rozloženy od 00 do 99. Přeskočíme proto pouze ty, které spadají do rozsahu, který potřebujeme.
Nastavte například cacheDataBlockPercent = 20 a uvidíte, co se stane:
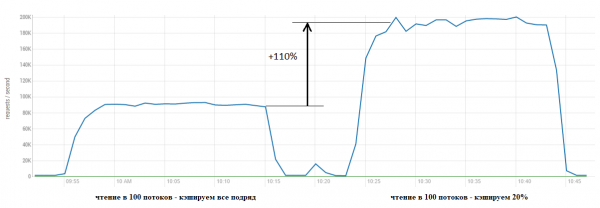
Výsledek je zřejmý. Z níže uvedených grafů je zřejmé, proč k takovému zrychlení došlo – ušetříme spoustu zdrojů GC, aniž bychom museli provádět sisyfovskou práci s umístěním dat do mezipaměti, jen abychom je okamžitě vyhodili do kanálu marťanských psů:
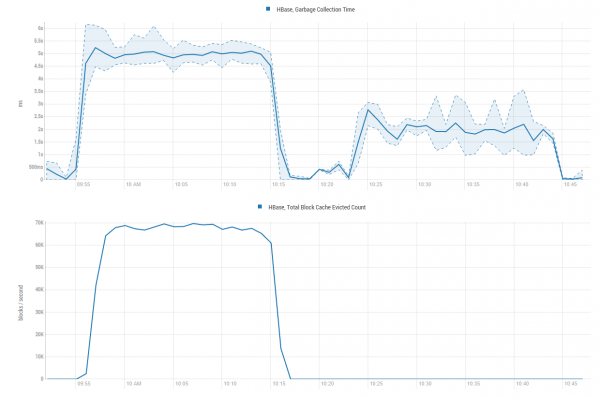
Současně se zvyšuje využití CPU, ale je mnohem menší než produktivita:
Za zmínku také stojí, že bloky uložené v BlockCache se liší. Většina, asi 95 %, jsou data samotná. A zbytek jsou metadata, jako jsou Bloomovy filtry nebo LEAF_INDEX a . Tato data nestačí, ale jsou velmi užitečná, protože před přímým přístupem k datům se HBase obrátí na meta, aby pochopila, zda je nutné zde dále hledat a pokud ano, kde přesně se blok zájmu nachází.
Proto v kódu vidíme kontrolní podmínku buf.getBlockType().isData() a díky této meta ho v keši v každém případě necháme.
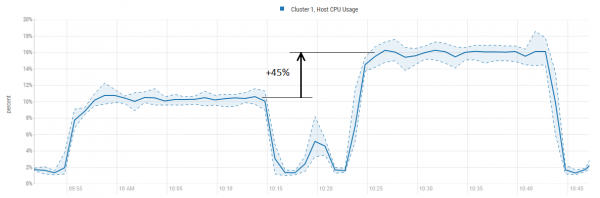
Nyní zvýšíme zátěž a lehce zpřísníme funkci jedním tahem. V prvním testu jsme udělali procento cutoff = 20 a BlockCache byla mírně nevyužitá. Nyní ji nastavíme na 23 % a přidáme 100 vláken každých 5 minut, abychom viděli, v jakém bodě nastane saturace:
Zde vidíme, že původní verze téměř okamžitě narazí na strop s rychlostí asi 100 tisíc požadavků za sekundu. Kdežto patch dává zrychlení až 300tis. Zároveň je jasné, že další zrychlení už není tak „zadarmo“, zvyšuje se i vytížení CPU.
To však není příliš elegantní řešení, jelikož předem nevíme, jaké procento bloků je potřeba cachovat, záleží na profilu zatížení. Proto byl implementován mechanismus pro automatickou úpravu tohoto parametru v závislosti na aktivitě operací čtení.
K ovládání byly přidány tři možnosti:
hbase.lru.cache.heavy.eviction.count.limit — nastavuje, kolikrát má proces vyřazení dat z mezipaměti proběhnout, než začneme používat optimalizaci (tj. přeskakování bloků). Ve výchozím nastavení se rovná MAX_INT = 2147483647 a ve skutečnosti znamená, že funkce s touto hodnotou nikdy nezačne pracovat. Protože proces vystěhování začíná každých 5 - 10 sekund (záleží na zátěži) a 2147483647 * 10 / 60 / 60 / 24 / 365 = 680 let. Tento parametr však můžeme nastavit na 0 a funkci zprovoznit ihned po spuštění.
V tomto parametru je však také užitečné zatížení. Pokud je naše zatížení takové, že krátkodobé čtení (řekněme ve dne) a dlouhodobé čtení (v noci) se neustále prolínají, pak můžeme zajistit, aby byla funkce zapnuta pouze tehdy, když probíhají operace dlouhého čtení.
Například víme, že krátkodobá měření obvykle trvají asi 1 minutu. Není potřeba začít vyhazovat bloky, cache nestihne zastarat a pak můžeme tento parametr nastavit na rovný např. 10. To povede k tomu, že optimalizace začne fungovat až při dlouho- začalo období aktivního čtení, tzn. za 100 sekund. Pokud tedy provedeme krátkodobé čtení, všechny bloky půjdou do mezipaměti a budou dostupné (kromě těch, které budou vyřazeny standardním algoritmem). A když děláme dlouhodobé čtení, funkce je zapnutá a měli bychom mnohem vyšší výkon.
hbase.lru.cache.heavy.eviction.mb.size.limit — nastavuje, kolik megabajtů bychom chtěli umístit do mezipaměti (a samozřejmě vyřadit) za 10 sekund. Funkce se pokusí dosáhnout této hodnoty a udržet ji. Jde o toto: pokud strčíme gigabajty do mezipaměti, budeme muset gigabajty vyklidit, a to, jak jsme viděli výše, je velmi drahé. Nepokoušejte se jej však nastavit příliš malý, protože to způsobí předčasné ukončení režimu přeskakování bloku. Pro výkonné servery (cca 20-40 fyzických jader) je optimální nastavit cca 300-400 MB. Pro střední třídu (~10 jader) 200-300 MB. U slabých systémů (2-5 jader) může být 50-100 MB normální (netestováno na nich).
Podívejme se, jak to funguje: řekněme, že nastavíme hbase.lru.cache.heavy.eviction.mb.size.limit = 500, dojde k nějakému zatížení (čtení) a pak každých ~10 sekund spočítáme, kolik bajtů bylo vystěhován pomocí vzorce:
Režie = součet volných bajtů (MB) * 100 / limit (MB) - 100;
Pokud bylo ve skutečnosti vystěhováno 2000 XNUMX MB, pak se režie rovná:
2000 * 100 / 500 - 100 = 300 %
Algoritmy se snaží udržet maximálně několik desítek procent, takže funkce sníží procento bloků uložených v mezipaměti, a tím implementuje mechanismus automatického ladění.
Pokud však zatížení klesne, řekněme, že se odstraní pouze 200 MB a Overhead se stane záporným (tzv. přestřelení):
200 * 100 / 500 - 100 = -60 %
Naopak, tato funkce zvýší procento bloků uložených v mezipaměti, dokud nebude Overhead pozitivní.
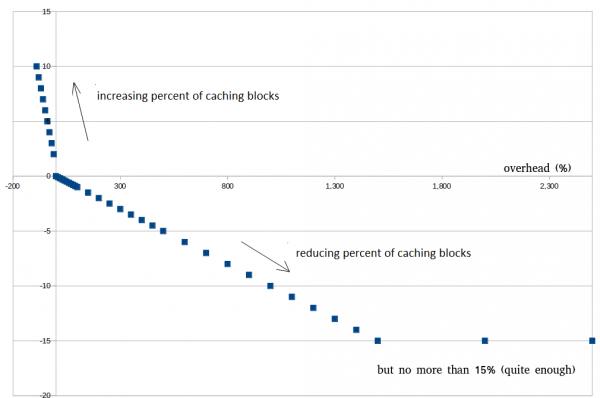
Níže je uveden příklad, jak to vypadá na skutečných datech. Není třeba se snažit dosáhnout 0 %, to je nemožné. Je velmi dobré, když je to asi 30 - 100%, což pomáhá vyhnout se předčasnému odchodu z režimu optimalizace při krátkodobých rázech.
hbase.lru.cache.heavy.eviction.režijní.koeficient — nastavuje, jak rychle chceme získat výsledek. Pokud s jistotou víme, že naše čtení je většinou dlouhé a nechce se nám čekat, můžeme tento poměr zvýšit a získat vysoký výkon rychleji.
Například tento koeficient nastavíme = 0.01. To znamená, že Režie (viz výše) se tímto číslem vynásobí výsledným výsledkem a sníží se procento bloků uložených v mezipaměti. Předpokládejme, že režie = 300 % a koeficient = 0.01, pak se procento bloků v mezipaměti sníží o 3 %.
Podobná logika „Backpressure“ je implementována také pro záporné hodnoty Overhead (přestřelení). Vzhledem k tomu, že krátkodobé výkyvy v objemu čtení a vystěhování jsou vždy možné, tento mechanismus vám umožňuje vyhnout se předčasnému odchodu z režimu optimalizace. Backpressure má obrácenou logiku: čím silnější je přestřelení, tím více bloků je ukládáno do mezipaměti.
Implementační kód
LruBlockCache cache = this.cache.get();
if (cache == null) {
break;
}
freedSumMb += cache.evict()/1024/1024;
/*
* Sometimes we are reading more data than can fit into BlockCache
* and it is the cause a high rate of evictions.
* This in turn leads to heavy Garbage Collector works.
* So a lot of blocks put into BlockCache but never read,
* but spending a lot of CPU resources.
* Here we will analyze how many bytes were freed and decide
* decide whether the time has come to reduce amount of caching blocks.
* It help avoid put too many blocks into BlockCache
* when evict() works very active and save CPU for other jobs.
* More delails: https://issues.apache.org/jira/browse/HBASE-23887
*/
// First of all we have to control how much time
// has passed since previuos evict() was launched
// This is should be almost the same time (+/- 10s)
// because we get comparable volumes of freed bytes each time.
// 10s because this is default period to run evict() (see above this.wait)
long stopTime = System.currentTimeMillis();
if ((stopTime - startTime) > 1000 * 10 - 1) {
// Here we have to calc what situation we have got.
// We have the limit "hbase.lru.cache.heavy.eviction.bytes.size.limit"
// and can calculte overhead on it.
// We will use this information to decide,
// how to change percent of caching blocks.
freedDataOverheadPercent =
(int) (freedSumMb * 100 / cache.heavyEvictionMbSizeLimit) - 100;
if (freedSumMb > cache.heavyEvictionMbSizeLimit) {
// Now we are in the situation when we are above the limit
// But maybe we are going to ignore it because it will end quite soon
heavyEvictionCount++;
if (heavyEvictionCount > cache.heavyEvictionCountLimit) {
// It is going for a long time and we have to reduce of caching
// blocks now. So we calculate here how many blocks we want to skip.
// It depends on:
// 1. Overhead - if overhead is big we could more aggressive
// reducing amount of caching blocks.
// 2. How fast we want to get the result. If we know that our
// heavy reading for a long time, we don't want to wait and can
// increase the coefficient and get good performance quite soon.
// But if we don't sure we can do it slowly and it could prevent
// premature exit from this mode. So, when the coefficient is
// higher we can get better performance when heavy reading is stable.
// But when reading is changing we can adjust to it and set
// the coefficient to lower value.
int change =
(int) (freedDataOverheadPercent * cache.heavyEvictionOverheadCoefficient);
// But practice shows that 15% of reducing is quite enough.
// We are not greedy (it could lead to premature exit).
change = Math.min(15, change);
change = Math.max(0, change); // I think it will never happen but check for sure
// So this is the key point, here we are reducing % of caching blocks
cache.cacheDataBlockPercent -= change;
// If we go down too deep we have to stop here, 1% any way should be.
cache.cacheDataBlockPercent = Math.max(1, cache.cacheDataBlockPercent);
}
} else {
// Well, we have got overshooting.
// Mayby it is just short-term fluctuation and we can stay in this mode.
// It help avoid permature exit during short-term fluctuation.
// If overshooting less than 90%, we will try to increase the percent of
// caching blocks and hope it is enough.
if (freedSumMb >= cache.heavyEvictionMbSizeLimit * 0.1) {
// Simple logic: more overshooting - more caching blocks (backpressure)
int change = (int) (-freedDataOverheadPercent * 0.1 + 1);
cache.cacheDataBlockPercent += change;
// But it can't be more then 100%, so check it.
cache.cacheDataBlockPercent = Math.min(100, cache.cacheDataBlockPercent);
} else {
// Looks like heavy reading is over.
// Just exit form this mode.
heavyEvictionCount = 0;
cache.cacheDataBlockPercent = 100;
}
}
LOG.info("BlockCache evicted (MB): {}, overhead (%): {}, " +
"heavy eviction counter: {}, " +
"current caching DataBlock (%): {}",
freedSumMb, freedDataOverheadPercent,
heavyEvictionCount, cache.cacheDataBlockPercent);
freedSumMb = 0;
startTime = stopTime;
}
Podívejme se nyní na to vše na reálném příkladu. Máme následující testovací skript:
- Začněme skenovat (25 vláken, dávka = 100)
- Po 5 minutách přidejte multi-gety (25 vláken, dávka = 100)
- Po 5 minutách vypněte multi-get (zůstane pouze skenování)
Provedeme dva běhy, nejprve hbase.lru.cache.heavy.eviction.count.limit = 10000 (což ve skutečnosti funkci deaktivuje) a poté nastavíme limit = 0 (povolí ji).
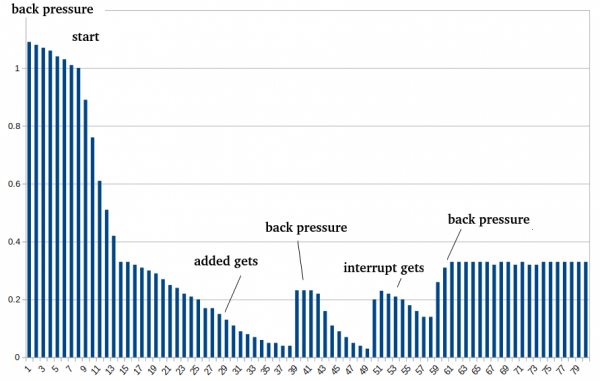
V níže uvedených protokolech vidíme, jak je funkce zapnutá a resetuje přestřelení na 14-71%. Čas od času se zátěž sníží, čímž se zapne Backpressure a HBase opět ukládá do mezipaměti další bloky.
Log RegionServer
vyřazeno (MB): 0, poměr 0.0, režie (%): -100, velké počítadlo vystěhování: 0, aktuální mezipaměť DataBlock (%): 100
vyřazeno (MB): 0, poměr 0.0, režie (%): -100, velké počítadlo vystěhování: 0, aktuální mezipaměť DataBlock (%): 100
vyřazeno (MB): 2170, poměr 1.09, režie (%): 985, velké počítadlo vystěhování: 1, aktuální mezipaměť DataBlock (%): 91 < start
vyřazeno (MB): 3763, poměr 1.08, režie (%): 1781, velké počítadlo vystěhování: 2, aktuální ukládání dat do mezipaměti DataBlock (%): 76
vyřazeno (MB): 3306, poměr 1.07, režie (%): 1553, velké počítadlo vystěhování: 3, aktuální ukládání dat do mezipaměti DataBlock (%): 61
vyřazeno (MB): 2508, poměr 1.06, režie (%): 1154, velké počítadlo vystěhování: 4, aktuální ukládání dat do mezipaměti DataBlock (%): 50
vyřazeno (MB): 1824, poměr 1.04, režie (%): 812, velké počítadlo vystěhování: 5, aktuální ukládání dat do mezipaměti DataBlock (%): 42
vyřazeno (MB): 1482, poměr 1.03, režie (%): 641, velké počítadlo vystěhování: 6, aktuální ukládání dat do mezipaměti DataBlock (%): 36
vyřazeno (MB): 1140, poměr 1.01, režie (%): 470, velké počítadlo vystěhování: 7, aktuální ukládání dat do mezipaměti DataBlock (%): 32
vyřazeno (MB): 913, poměr 1.0, režie (%): 356, velké počítadlo vystěhování: 8, aktuální ukládání dat do mezipaměti DataBlock (%): 29
vyřazeno (MB): 912, poměr 0.89, režie (%): 356, velké počítadlo vystěhování: 9, aktuální ukládání dat do mezipaměti DataBlock (%): 26
vyřazeno (MB): 684, poměr 0.76, režie (%): 242, velké počítadlo vystěhování: 10, aktuální ukládání dat do mezipaměti DataBlock (%): 24
vyřazeno (MB): 684, poměr 0.61, režie (%): 242, velké počítadlo vystěhování: 11, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 456, poměr 0.51, režie (%): 128, velké počítadlo vystěhování: 12, aktuální ukládání dat do mezipaměti DataBlock (%): 21
vyřazeno (MB): 456, poměr 0.42, režie (%): 128, velké počítadlo vystěhování: 13, aktuální ukládání dat do mezipaměti DataBlock (%): 20
vyřazeno (MB): 456, poměr 0.33, režie (%): 128, velké počítadlo vystěhování: 14, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 15, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 342, poměr 0.32, režie (%): 71, velké počítadlo vystěhování: 16, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 342, poměr 0.31, režie (%): 71, velké počítadlo vystěhování: 17, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.3, režie (%): 14, velké počítadlo vystěhování: 18, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.29, režie (%): 14, velké počítadlo vystěhování: 19, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.27, režie (%): 14, velké počítadlo vystěhování: 20, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.25, režie (%): 14, velké počítadlo vystěhování: 21, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.24, režie (%): 14, velké počítadlo vystěhování: 22, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.22, režie (%): 14, velké počítadlo vystěhování: 23, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.21, režie (%): 14, velké počítadlo vystěhování: 24, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.2, režie (%): 14, velké počítadlo vystěhování: 25, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 228, poměr 0.17, režie (%): 14, velké počítadlo vystěhování: 26, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vystěhováno (MB): 456, poměr 0.17, režie (%): 128, velké počítadlo vystěhování: 27, aktuální ukládání do mezipaměti DataBlock (%): 18 < přidáno dostane (ale tabulka stejná)
vyřazeno (MB): 456, poměr 0.15, režie (%): 128, velké počítadlo vystěhování: 28, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 342, poměr 0.13, režie (%): 71, velké počítadlo vystěhování: 29, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 342, poměr 0.11, režie (%): 71, velké počítadlo vystěhování: 30, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 342, poměr 0.09, režie (%): 71, velké počítadlo vystěhování: 31, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 228, poměr 0.08, režie (%): 14, velké počítadlo vystěhování: 32, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 228, poměr 0.07, režie (%): 14, velké počítadlo vystěhování: 33, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 228, poměr 0.06, režie (%): 14, velké počítadlo vystěhování: 34, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 228, poměr 0.05, režie (%): 14, velké počítadlo vystěhování: 35, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 228, poměr 0.05, režie (%): 14, velké počítadlo vystěhování: 36, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 228, poměr 0.04, režie (%): 14, velké počítadlo vystěhování: 37, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 109, poměr 0.04, režie (%): -46, počítadlo těžkého vystěhování: 37, aktuální cachování DataBlock (%): 22 < zpětný tlak
vyřazeno (MB): 798, poměr 0.24, režie (%): 299, velké počítadlo vystěhování: 38, aktuální ukládání dat do mezipaměti DataBlock (%): 20
vyřazeno (MB): 798, poměr 0.29, režie (%): 299, velké počítadlo vystěhování: 39, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 570, poměr 0.27, režie (%): 185, velké počítadlo vystěhování: 40, aktuální ukládání dat do mezipaměti DataBlock (%): 17
vyřazeno (MB): 456, poměr 0.22, režie (%): 128, velké počítadlo vystěhování: 41, aktuální ukládání dat do mezipaměti DataBlock (%): 16
vyřazeno (MB): 342, poměr 0.16, režie (%): 71, velké počítadlo vystěhování: 42, aktuální ukládání dat do mezipaměti DataBlock (%): 16
vyřazeno (MB): 342, poměr 0.11, režie (%): 71, velké počítadlo vystěhování: 43, aktuální ukládání dat do mezipaměti DataBlock (%): 16
vyřazeno (MB): 228, poměr 0.09, režie (%): 14, velké počítadlo vystěhování: 44, aktuální ukládání dat do mezipaměti DataBlock (%): 16
vyřazeno (MB): 228, poměr 0.07, režie (%): 14, velké počítadlo vystěhování: 45, aktuální ukládání dat do mezipaměti DataBlock (%): 16
vyřazeno (MB): 228, poměr 0.05, režie (%): 14, velké počítadlo vystěhování: 46, aktuální ukládání dat do mezipaměti DataBlock (%): 16
vyřazeno (MB): 222, poměr 0.04, režie (%): 11, velké počítadlo vystěhování: 47, aktuální ukládání dat do mezipaměti DataBlock (%): 16
vyřazeno (MB): 104, poměr 0.03, režie (%): -48, počítadlo těžkého vystěhování: 47, aktuální ukládání do mezipaměti DataBlock (%): 21 < přerušení dostane
vyřazeno (MB): 684, poměr 0.2, režie (%): 242, velké počítadlo vystěhování: 48, aktuální ukládání dat do mezipaměti DataBlock (%): 19
vyřazeno (MB): 570, poměr 0.23, režie (%): 185, velké počítadlo vystěhování: 49, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 342, poměr 0.22, režie (%): 71, velké počítadlo vystěhování: 50, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 228, poměr 0.21, režie (%): 14, velké počítadlo vystěhování: 51, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 228, poměr 0.2, režie (%): 14, velké počítadlo vystěhování: 52, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 228, poměr 0.18, režie (%): 14, velké počítadlo vystěhování: 53, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 228, poměr 0.16, režie (%): 14, velké počítadlo vystěhování: 54, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 228, poměr 0.14, režie (%): 14, velké počítadlo vystěhování: 55, aktuální ukládání dat do mezipaměti DataBlock (%): 18
vyřazeno (MB): 112, poměr 0.14, režie (%): -44, počítadlo těžkého vystěhování: 55, aktuální cachování DataBlock (%): 23 < zpětný tlak
vyřazeno (MB): 456, poměr 0.26, režie (%): 128, velké počítadlo vystěhování: 56, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.31, režie (%): 71, velké počítadlo vystěhování: 57, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 58, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 59, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 60, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 61, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 62, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 63, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.32, režie (%): 71, velké počítadlo vystěhování: 64, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 65, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 66, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.32, režie (%): 71, velké počítadlo vystěhování: 67, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 68, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.32, režie (%): 71, velké počítadlo vystěhování: 69, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.32, režie (%): 71, velké počítadlo vystěhování: 70, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 71, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 72, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 73, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 74, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 75, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 342, poměr 0.33, režie (%): 71, velké počítadlo vystěhování: 76, aktuální ukládání dat do mezipaměti DataBlock (%): 22
vyřazeno (MB): 21, poměr 0.33, režie (%): -90, velké počítadlo vystěhování: 76, aktuální mezipaměť DataBlock (%): 32
vyřazeno (MB): 0, poměr 0.0, režie (%): -100, velké počítadlo vystěhování: 0, aktuální mezipaměť DataBlock (%): 100
vyřazeno (MB): 0, poměr 0.0, režie (%): -100, velké počítadlo vystěhování: 0, aktuální mezipaměť DataBlock (%): 100
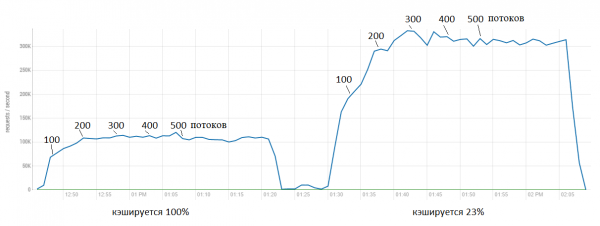
Skenování bylo potřeba k tomu, aby ukázal stejný proces ve formě grafu vztahu mezi dvěma sekcemi mezipaměti – single (kde jsou zde uloženy bloky, které nebyly nikdy předtím požadovány) a multi (zde jsou uložena data „vyžádaná“ alespoň jednou):
A nakonec, jak vypadá fungování parametrů ve formě grafu. Pro srovnání, cache byla na začátku úplně vypnutá, poté byla spuštěna HBase s cachováním a odložením začátku optimalizačních prací o 5 minut (30 cyklů vyklizení).
Úplný kód naleznete v žádosti o stažení na githubu.
300 tisíc přečtení za sekundu však není vše, čeho lze na tomto hardwaru za těchto podmínek dosáhnout. Faktem je, že když potřebujete přistupovat k datům přes HDFS, používá se mechanismus ShortCircuitCache (dále jen SSC), který vám umožňuje přistupovat přímo k datům a vyhnout se síťovým interakcím.
Profilování ukázalo, že ačkoli tento mechanismus přináší velký zisk, v určitém okamžiku se také stává úzkým hrdlem, protože téměř všechny těžké operace se odehrávají uvnitř zámku, což vede k zablokování po většinu času.

Když jsme si to uvědomili, uvědomili jsme si, že problém lze obejít vytvořením řady nezávislých SSC:
private final ShortCircuitCache[] shortCircuitCache;
...
shortCircuitCache = new ShortCircuitCache[this.clientShortCircuitNum];
for (int i = 0; i < this.clientShortCircuitNum; i++)
this.shortCircuitCache[i] = new ShortCircuitCache(…);
A pak s nimi pracujte, kromě křižovatek také na poslední číslici posunutí:
public ShortCircuitCache getShortCircuitCache(long idx) {
return shortCircuitCache[(int) (idx % clientShortCircuitNum)];
}
Nyní můžete začít testovat. K tomu budeme číst soubory z HDFS pomocí jednoduché vícevláknové aplikace. Nastavte parametry:
conf.set("dfs.client.read.shortcircuit", "true");
conf.set("dfs.client.read.shortcircuit.buffer.size", "65536"); // по дефолту = 1 МБ и это сильно замедляет чтение, поэтому лучше привести в соответствие к реальным нуждам
conf.set("dfs.client.short.circuit.num", num); // от 1 до 10
A stačí si přečíst soubory:
FSDataInputStream in = fileSystem.open(path);
for (int i = 0; i < count; i++) {
position += 65536;
if (position > 900000000)
position = 0L;
int res = in.read(position, byteBuffer, 0, 65536);
}
Tento kód se spouští v samostatných vláknech a zvýšíme počet současně čtených souborů (z 10 na 200 - vodorovná osa) a počet mezipamětí (z 1 na 10 - grafika). Svislá osa ukazuje zrychlení, které je výsledkem zvýšení SSC vzhledem k případu, kdy existuje pouze jedna mezipaměť.
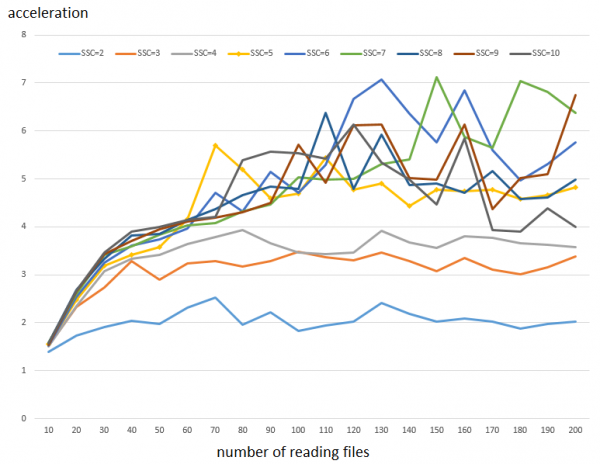
Jak číst graf: Doba provedení pro 100 tisíc čtení v 64 KB blocích s jednou cache vyžaduje 78 sekund. Zatímco s 5 cache to trvá 16 sekund. Tito. dochází ke zrychlení ~5krát. Jak je z grafu patrné, efekt není při malém počtu paralelních čtení příliš patrný, znatelnou roli začíná hrát při více než 50 čteních vláken.Je také patrné, že zvýšení počtu SSC z 6 a výše poskytuje výrazně menší nárůst výkonu.
Poznámka 1: Protože výsledky testu jsou značně kolísavé (viz níže), byly provedeny 3 běhy a výsledné hodnoty byly zprůměrovány.
Poznámka 2: Zisk výkonu z konfigurace náhodného přístupu je stejný, i když samotný přístup je o něco pomalejší.
Je však nutné upřesnit, že na rozdíl od případu HBase není toto zrychlení vždy zadarmo. Zde „odemykáme“ schopnost CPU pracovat více, místo abychom viseli na zámcích.
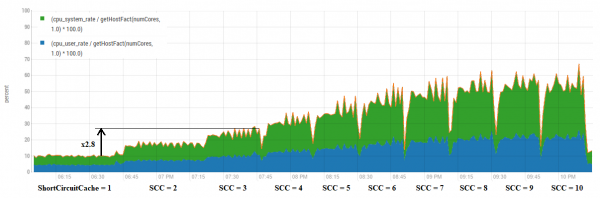
Zde můžete pozorovat, že obecně zvýšení počtu mezipamětí přibližně úměrně zvýší využití CPU. Výherních kombinací je však o něco více.
Podívejme se blíže například na nastavení SSC = 3. Nárůst výkonu na dosahu je zhruba 3.3násobný. Níže jsou uvedeny výsledky ze všech tří samostatných běhů.
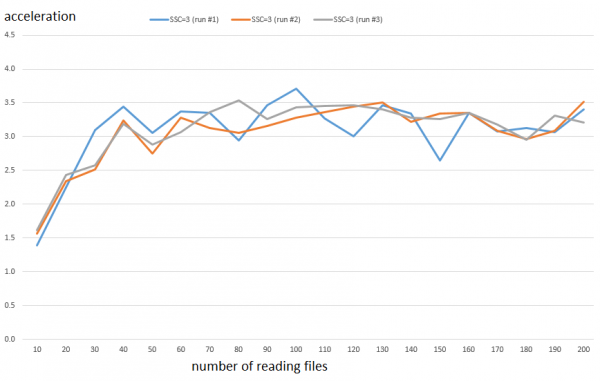
Zatímco spotřeba CPU se zvyšuje asi 2.8krát. Rozdíl není příliš velký, ale malá Greta už je spokojená a může mít čas chodit do školy a chodit na lekce.
To bude mít pozitivní efekt pro jakýkoli nástroj, který využívá hromadný přístup k HDFS (například Spark atd.), za předpokladu, že kód aplikace je lehký (tj. zástrčka je na straně klienta HDFS) a je k dispozici volné napájení CPU. . Pro kontrolu si pojďme vyzkoušet, jaký efekt bude mít kombinované použití optimalizace BlockCache a ladění SSC pro čtení z HBase.
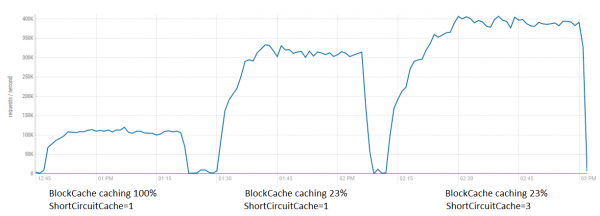
Je vidět, že za takových podmínek není efekt tak velký jako u zpřesněných testů (čtení bez jakéhokoli zpracování), ale vymáčknout zde 80K navíc jde celkem dobře. Obě optimalizace dohromady poskytují až 4x zrychlení.
Pro tuto optimalizaci bylo také provedeno PR , který byl sloučen a tato funkce bude dostupná v budoucích verzích.
A nakonec bylo zajímavé porovnat výkon čtení podobné širokosloupcové databáze Cassandra a HBase.
Za tímto účelem jsme spustili instance standardního nástroje zátěžového testování YCSB ze dvou hostitelů (celkem 800 vláken). Na straně serveru - 4 instance RegionServer a Cassandra na 4 hostitelích (ne na těch, kde běží klienti, aby se zabránilo jejich vlivu). Údaje pocházely z tabulek velikosti:
HBase – 300 GB na HDFS (100 GB čistých dat)
Cassandra – 250 GB (replikační faktor = 3)
Tito. objem byl přibližně stejný (v HBase o něco více).
Parametry HBase:
dfs.client.short.circuit.num = 5 (optimalizace klienta HDFS)
hbase.lru.cache.heavy.eviction.count.limit = 30 - to znamená, že náplast začne fungovat po 30 vystěhování (~5 minut)
hbase.lru.cache.heavy.eviction.mb.size.limit = 300 — cílový objem ukládání do mezipaměti a vystěhování
Protokoly YCSB byly analyzovány a zkompilovány do grafů aplikace Excel:
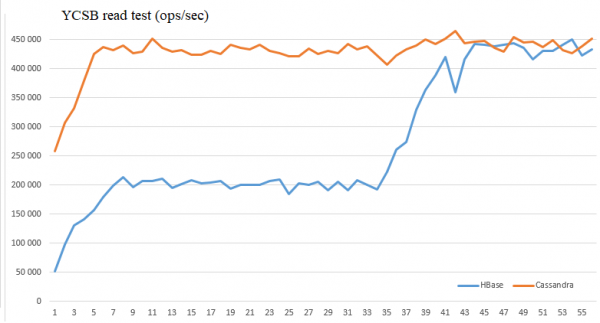
Jak vidíte, tyto optimalizace umožňují porovnat výkon těchto databází za těchto podmínek a dosáhnout 450 tisíc čtení za sekundu.
Doufáme, že tyto informace mohou být pro někoho užitečné během vzrušujícího boje o produktivitu.
Zdroj: www.habr.com
