

V roce 2016 jsme v Bufferu a nyní asi 60 uzlů (na AWS) a 1500 kontejnerů pracuje na našem clusteru k8s spravovaném . K mikroslužbám jsme však přešli metodou pokus-omyl a i po několika letech práce s k8 se stále potýkáme s novými problémy. V tomto příspěvku budeme mluvit o omezení procesoru: proč jsme si mysleli, že jsou to dobré praktiky a proč nakonec nebyly tak dobré.
Omezení procesoru a omezení
Stejně jako mnoho dalších uživatelů Kubernetes, . Bez takového nastavení mohou kontejnery v uzlu zabírat veškerý výkon procesoru, což zase způsobuje důležité procesy Kubernetes (např. kubelet) přestane reagovat na požadavky. Nastavení limitů CPU je tedy dobrý způsob, jak chránit vaše uzly.
Limity procesoru nastavují kontejner na maximální čas CPU, který může používat po určitou dobu (výchozí hodnota je 100 ms), a kontejner tento limit nikdy nepřekročí. V Kubernetes pro škrcení kontejneru a zabránit jeho překročení limitu, použije se speciální nástroj , ale tyto umělé limity CPU nakonec zhorší výkon a zvýší dobu odezvy vašich kontejnerů.
Co se může stát, pokud nenastavíme limity procesoru?
Bohužel jsme tomuto problému museli čelit sami. Každý uzel má proces zodpovědný za správu kontejnerů kubeleta přestal reagovat na žádosti. Uzel, když k tomu dojde, přejde do stavu NotReadya kontejnery z něj budou přesměrovány někam jinam a vytvoří stejné problémy na nových uzlech. Není to přinejmenším ideální scénář.
Projevování problému škrcení a odezvy
Klíčovou metrikou pro sledování kontejnerů je trottling, ukazuje, kolikrát byl váš kontejner přiškrcen. Se zájmem jsme zaznamenali přítomnost throttlingu v některých kontejnerech, bez ohledu na to, zda byla zátěž procesoru extrémní nebo ne. Jako příklad se podívejme na jedno z našich hlavních API:
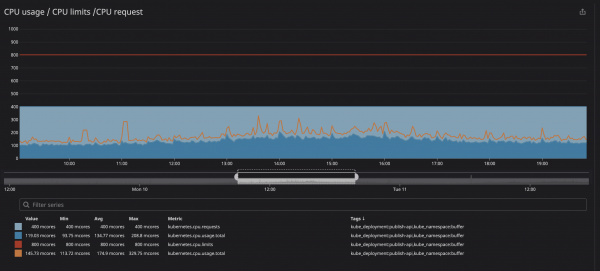
Jak můžete vidět níže, nastavili jsme limit na 800m (0.8 nebo 80 % jádra) a špičkové hodnoty při nejlepším dosahu 200m (20 % jádra). Zdálo by se, že před omezením služby máme stále dostatek výkonu procesoru, ale...
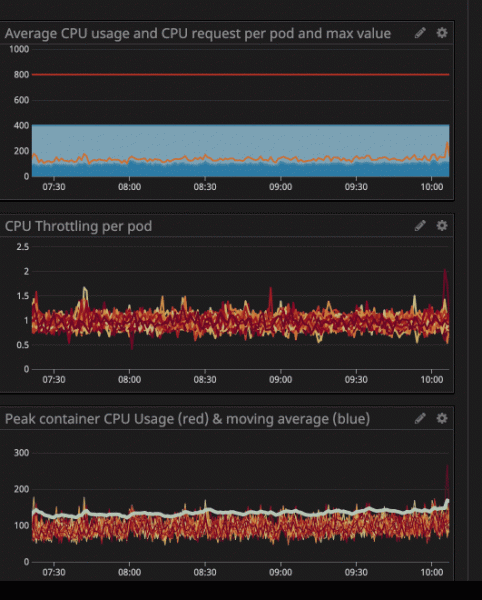
Možná jste si všimli, že i když je zatížení procesoru pod stanovenými limity – výrazně pod – stále dochází k throttlingu.
Tváří v tvář tomu jsme brzy objevili několik zdrojů (, , ) o poklesu výkonu a doby odezvy služeb v důsledku omezování.
Proč vidíme omezování při nízké zátěži procesoru? Zkrácená verze zní: „v jádru Linux Existuje chyba, která způsobuje zbytečné omezení kontejnerů se zadanými limity CPU." Pokud vás zajímá podstata problému, můžete se podívat na prezentaci ( и opce) od Davea Chiluka.
Odstranění omezení CPU (s extrémní opatrností)
Po dlouhých diskuzích jsme se rozhodli odstranit omezení procesoru ze všech služeb, které přímo či nepřímo ovlivňovaly kritické funkce pro naše uživatele.
Rozhodnutí nebylo jednoduché, protože si velmi ceníme stability našeho clusteru. V minulosti jsme již experimentovali s nestabilitou našeho clusteru a služby pak spotřebovaly příliš mnoho prostředků a zpomalily práci celého jejich uzlu. Nyní bylo všechno poněkud jiné: měli jsme jasnou představu o tom, co od našich klastrů očekáváme, a také dobrou strategii pro implementaci plánovaných změn.

Obchodní korespondence o naléhavém problému.
Jak chránit své uzly, když jsou omezení zrušena?
Izolace „neomezených“ služeb:
V minulosti jsme již viděli, jak se některé uzly dostaly do stavu notReady, především kvůli službám, které spotřebovaly příliš mnoho zdrojů.
Rozhodli jsme se umístit takové služby do samostatných („označených“) uzlů, aby nenarušovaly „související“ služby. V důsledku toho jsme označením některých uzlů a přidáním parametru tolerance k „nesouvisejícím“ službám dosáhli větší kontroly nad clusterem a bylo pro nás snazší identifikovat problémy s uzly. Chcete-li provést podobné procesy sami, můžete se s nimi seznámit .
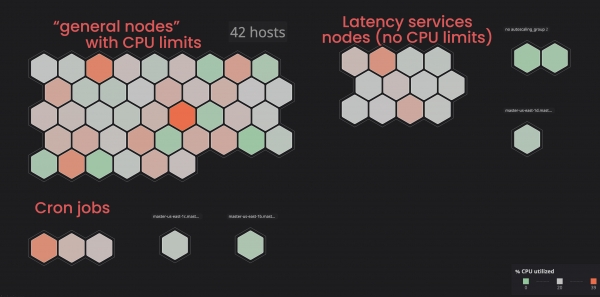
Přiřazení správného požadavku na procesor a paměť:
Největší strach jsme měli z toho, že proces spotřebuje příliš mnoho zdrojů a uzel přestane reagovat na požadavky. Vzhledem k tomu, že nyní (díky Datadogu) můžeme jasně sledovat všechny služby na našem clusteru, analyzoval jsem několik měsíců provozu těch, které jsme plánovali označit jako „nesouvisející“. Jednoduše nastavím maximální využití CPU s rezervou 20% a tím alokuji místo v uzlu pro případ, že by se k8s pokusila uzlu přiřadit další služby.
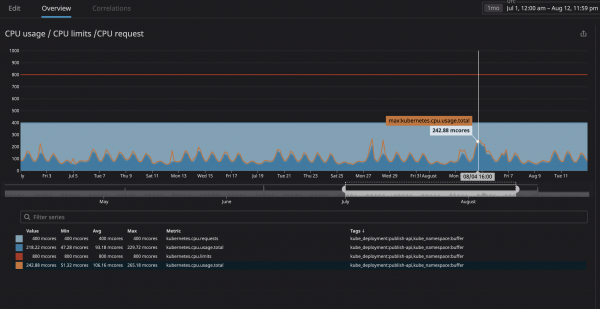
Jak můžete vidět na grafu, dosáhlo maximálního zatížení procesoru 242m CPU jádra (0.242 procesorových jader). Pro požadavek procesoru stačí vzít číslo o něco větší, než je tato hodnota. Upozorňujeme, že vzhledem k tomu, že služby jsou zaměřeny na uživatele, hodnoty špičkového zatížení se shodují s provozem.
Udělejte totéž s využitím paměti a dotazy a voila - vše je připraveno! Pro větší bezpečnost můžete přidat horizontální automatické škálování pod. Pokaždé, když je zatížení zdrojů vysoké, automatické škálování tedy vytvoří nové pody a kubernetes je distribuuje do uzlů s volným místem. V případě, že v samotném clusteru nezbývá místo, můžete si nastavit upozornění nebo nakonfigurovat přidávání nových uzlů prostřednictvím jejich automatického škálování.
Z mínusů stojí za zmínku, že jsme prohráli v „", tj. počet kontejnerů běžících na jednom uzlu. Můžeme mít také spoustu „relaxací“ při nízké hustotě provozu a je zde také šance, že dosáhnete vysokého zatížení procesoru, ale s tím druhým by měly pomoci automatické škálování uzlů.
výsledky
S potěšením zveřejňuji tyto vynikající výsledky z experimentů z posledních několika týdnů; již jsme zaznamenali výrazná zlepšení odezvy ve všech upravených službách:
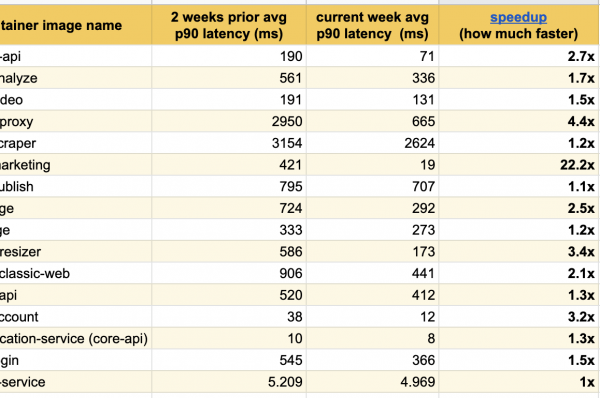
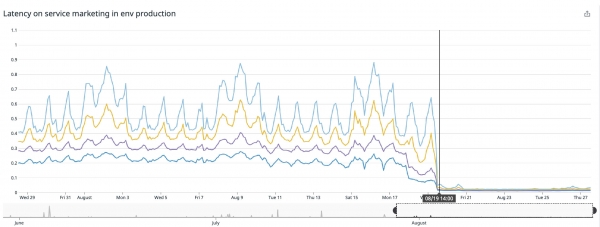
Nejlepších výsledků jsme dosáhli na naší domovské stránce (), tam se služba zrychlila dvacet dvakrát!
Je chyba jádra opravena? Linux?
Ano, distribuce verze 4.19 a vyšší.
Nicméně při čtení na druhého září 2020 stále narážíme na zmínky o některých Linux-projekty s podobnou chybou. Myslím, že v některých distribucích Linux Tato chyba stále přetrvává a v současné době se pracuje na její opravě.
Pokud je vaše distribuční verze starší než 4.19, doporučuji upgradovat na nejnovější verzi, ale i tak byste se měli pokusit odstranit omezení CPU a zjistit, zda omezení přetrvává. Níže je uveden částečný seznam služeb správy Kubernetes a Linux distribuce:
- Debian: oprava je integrována do nejnovější verze distribuce, a vypadá docela svěže (). Některé předchozí verze mohou být také opraveny.
- Ubuntu: oprava integrovaná do nejnovější verze
- EKS má ještě opravu . Pokud je vaše verze nižší než tato, měli byste aktualizovat AMI.
- kopy: у
kops 1.18+hlavní obrázek hostitele bude Ubuntu 20.04. dubna. Pokud máte starší verzi Kopsu, pravděpodobně budete muset počkat na opravu. My na ni momentálně čekáme. - GKE (Google Cloud): Oprava integrovaná , jsou však problémy s škrcení .
Co dělat, pokud oprava vyřešila problém s škrcení?
Nejsem si jistý, zda je problém zcela vyřešen. Až se dostaneme k verzi jádra s opravou, otestuji cluster a aktualizuji příspěvek. Pokud již někdo aktualizoval, rád si přečtu vaše výsledky.
Závěr
- Pokud pracujete s kontejnery Dockeru v rámci Linux (ať už se jedná o Kubernetes, Mesos, Swarm nebo cokoli jiného), vaše kontejnery mohou ztratit výkon kvůli omezení;
- Zkuste aktualizovat na nejnovější verzi vaší distribuce v naději, že chyba již byla opravena;
- Problém vyřeší odstranění limitů procesoru, ale jedná se o nebezpečnou techniku, která by se měla používat s extrémní opatrností (je lepší nejprve aktualizovat jádro a porovnat výsledky);
- Pokud jste odstranili limity procesoru, pečlivě sledujte využití procesoru a paměti a ujistěte se, že zdroje procesoru překračují vaši spotřebu;
- Bezpečnou možností by bylo automatické škálování podů pro vytváření nových podů v případě vysoké hardwarové zátěže, takže je kubernetes přiřadí volným uzlům.
Doufám, že vám tento příspěvek pomůže zlepšit výkon vašich kontejnerových systémů.
PS autor si dopisuje se čtenáři a komentátory (v angličtině).
Zdroj: www.habr.com
