

Poznámka. přel.Tento článek, jehož autorem je Galo Navarro, hlavní softwarový inženýr evropské společnosti Adevinta, je fascinujícím a poučným „zkoumáním“ oblasti provozu infrastruktury. Jeho původní název byl v překladu mírně upraven z důvodu, který autor vysvětluje na začátku.
Poznámka od autoraVypadá to, že tato publikace Tento článek se setkal s mnohem větší pozorností, než se očekávalo. Stále dostávám rozzlobené komentáře ohledně zavádějícího názvu a někteří čtenáři jsou naštvaní. Chápu důvody, proč se to stalo, takže i s rizikem, že vám celý příběh prozradím, chci vysvětlit, o čem tento článek je. Když týmy migrují na Kubernetes, pozoruji jednu kuriózní věc: pokaždé, když se objeví problém (například zvýšená latence po migraci), první věc, kterou viní, je Kubernetes, ale ukáže se, že orchestrátor ve skutečnosti na vině není. Tento článek je o jednom takovém případu. Jeho název odráží zvolání jednoho z našich vývojářů (později uvidíte, že Kubernetes s tím neměl nic společného). O Kubernetes v něm nenajdete žádná překvapivá odhalení, ale můžete se spolehnout na pár dobrých lekcí o komplexních systémech.
Před pár týdny můj tým migroval jednu mikroslužbu na základní platformu, která zahrnovala CI/CD, produkční prostředí založené na Kubernetes, metriky a další užitečné funkce. Jednalo se o pilotní projekt: plánovali jsme na něm stavět a v nadcházejících měsících migrovat přibližně 150 dalších služeb. Všechny tyto služby pohánějí některá z největších španělských online tržišť (Infojobs, Fotocasa a další).
Poté, co jsme aplikaci nasadili do Kubernetes a přesměrovali na ni část provozu, nás čekalo znepokojivé překvapení. Latence (latence) Počet požadavků v Kubernetes byl 10krát vyšší než v EC2. Nakonec bylo nutné buď najít řešení tohoto problému, nebo migraci mikroslužeb (a potenciálně i celý projekt) opustit.
Proč je latence v Kubernetes mnohem vyšší než v EC2?
Abychom našli úzké hrdlo, shromažďovali jsme metriky podél celé cesty požadavku. Naše architektura je jednoduchá: API brána (Zuul) proxyuje požadavky na instance mikroslužeb v EC2 nebo Kubernetes. V Kubernetes používáme NGINX Ingress Controller a backendy jsou regulární objekty typu s JVM aplikací na platformě Spring.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Problém zřejmě souvisel s latencí v počáteční fázi zpracování na backendu (problémovou oblast jsem v grafu označil jako „xx“). V EC2 trvala odezva aplikace přibližně 20 ms. V Kubernetes se latence zvýšila na 100–200 ms.
Rychle jsme vyloučili pravděpodobné podezřelé související se změnou běhového prostředí. Verze JVM zůstala stejná. Problémy s kontejnerizací také nesouvisely: aplikace již úspěšně běžela v kontejnerech v EC2. Načtení? Ale pozorovali jsme vysoké latence i při jednom požadavku za sekundu. Pauzy při uvolňování paměti byly také zanedbatelné.
Jeden z našich administrátorů Kubernetes se zeptal, zda má aplikace nějaké externí závislosti, protože dotazy DNS způsobovaly podobné problémy v minulosti.
Hypotéza 1: Překlad DNS jmen
Pro každý požadavek naše aplikace provede jedno až tři volání instance AWS Elasticsearch v doméně, jako je elastic.spain.adevinta.comUvnitř kontejnerů, které máme , abychom mohli zkontrolovat, zda vyhledávání domény opravdu trvá dlouho.
DNS dotazy z kontejneru:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecPodobné požadavky z jedné z instancí EC2, na kterých je aplikace spuštěna:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecVzhledem k tomu, že vyhledávání trvá přibližně 30 ms, bylo jasné, že DNS rozlišení při přístupu k Elasticsearch skutečně přispívá ke zvýšené latenci.
To však bylo zvláštní ze dvou důvodů:
- Již nyní máme spoustu aplikací Kubernetes, které interagují se zdroji AWS bez výrazné latence. Ať už je příčina jakákoli, je specifická pro tento konkrétní případ.
- Víme, že JVM implementuje ukládání DNS do mezipaměti. V našich obrázcích je hodnota TTL pevně zakódována v
$JAVA_HOME/jre/lib/security/java.securitya nastavte na 10 sekund:networkaddress.cache.ttl = 10Jinými slovy, JVM by měl ukládat všechny DNS dotazy do mezipaměti po dobu 10 sekund.
Abychom potvrdili první hypotézu, rozhodli jsme se dočasně zakázat vyhledávání DNS a zjistit, zda se problém vyřeší. Nejprve jsme zvážili překonfigurování aplikace tak, aby komunikovala s Elasticsearchem přímo prostřednictvím jeho IP adresy, nikoli prostřednictvím jeho doménového jména. To by vyžadovalo změnu kódu a nové nasazení, takže jsme doménu jednoduše namapovali na jeho IP adresu v /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comKontejner nyní obdržel svou IP adresu téměř okamžitě. To vedlo k určitému zlepšení, ale byli jsme jen nepatrně blíže k očekávané úrovni latence. Přestože překlad DNS trval dlouho, skutečná příčina nám stále unikala.
Diagnostika sítě
Rozhodli jsme se analyzovat provoz z kontejneru pomocí tcpdumpsledovat, co se přesně děje v síti:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Pak jsme odeslali několik požadavků a stáhli si jejich záznam (kubectl cp my-service:/capture.pcap capture.pcap) pro další analýzu v .
Na dotazech DNS nebylo nic podezřelého (kromě jednoho drobného detailu, o kterém budu hovořit později). Nicméně se vyskytly určité zvláštnosti v tom, jak naše služba jednotlivé požadavky zpracovávala. Níže je snímek obrazovky, který ukazuje, jak je požadavek přijat ještě před zahájením odpovědi:
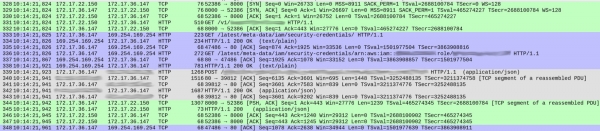
Čísla paketů jsou zobrazena v prvním sloupci. Pro přehlednost jsem různé TCP streamy barevně zvýraznil.
Zelený proud dat začínající paketem 328 ukazuje, jak klient (172.17.22.150) navázal TCP spojení s kontejnerem (172.17.36.147). Po počátečním handshake (328-330) paket 331 přinesl HTTP GET /v1/.. — příchozí požadavek na naši službu. Celý proces trval 1 ms.
Šedý stream (počínaje paketem 339) ukazuje, že naše služba odeslala HTTP požadavek instanci Elasticsearch (neexistuje žádný TCP handshake, protože používá existující připojení). To trvalo 18 ms.
Zatím je vše v pořádku a časy přibližně odpovídají očekávaným zpožděním (20-30 ms měřeno od klienta).
Modrá sekce však trvá 86 ms. Co se tam děje? S paketem 333 naše služba odeslala HTTP GET požadavek na /latest/meta-data/iam/security-credentialsa bezprostředně po něm, přes stejné TCP spojení, další GET požadavek na /latest/meta-data/iam/security-credentials/arn:...
Zjistili jsme, že to bylo konzistentní u každého požadavku v celém trasování. Překlad DNS byl v našich kontejnerech skutečně o něco pomalejší (vysvětlení tohoto jevu je docela zajímavé, ale nechám si ho na samostatný článek). Ukázalo se, že velké latence byly způsobeny voláním služby AWS Instance Metadata pro každý požadavek.
Hypotéza 2: Nadměrné volání do AWS
Oba koncové body patří Naše mikroslužba tuto službu používá při práci s Elasticsearch. Obě volání jsou součástí základního autorizačního procesu. Koncový bod, ke kterému se přistupuje během počátečního požadavku, vydává roli IAM přidruženou k instanci.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleDruhý požadavek kontaktuje druhý koncový bod a žádá o dočasná oprávnění pro tuto instanci:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Klient je může používat po krátkou dobu a musí pravidelně dostávat nové certifikáty (dokud nevyprší jejich platnost). Expiration). Model je jednoduchý: AWS z bezpečnostních důvodů často rotuje dočasné klíče, ale zákazníci si je mohou na několik minut uložit do mezipaměti, aby kompenzovali snížení výkonu spojené se získáváním nových certifikátů.
AWS Java SDK by měla převzít odpovědnost za organizaci tohoto procesu, ale z nějakého důvodu se tak neděje.
Po prohledání problémů na GitHubu jsme narazili na problém. Pomohla nám určit směr, kterým se dále ubírat.
Sada AWS SDK obnovuje certifikáty, když nastane jedna z následujících podmínek:
- Jejich datum spotřeby (
Expiration) se dostane doEXPIRATION_THRESHOLD, pevně zakódováno na 15 minut. - Od posledního pokusu o obnovení certifikátů uplynulo více času než
REFRESH_THRESHOLD, napevno zakódováno po dobu 60 minut.
Abychom zjistili skutečná data vypršení platnosti certifikátů, které jsme dostávali, spustili jsme výše uvedené příkazy cURL z kontejneru i z instance EC2. Certifikát přijatý z kontejneru měl mnohem kratší datum vypršení platnosti: přesně 15 minut.
Nyní bylo vše jasné: při prvním požadavku naše služba přijímala dočasné certifikáty. Protože jejich datum expirace bylo omezeno na 15 minut, AWS SDK je při následných požadavcích obnovovala. A to se dělo s každým dalším požadavkem.
Proč se zkrátila doba platnosti certifikátů?
Služba AWS Instance Metadata je navržena pro práci s instancemi EC2, nikoli s Kubernetes. Na druhou stranu jsme nechtěli měnit rozhraní aplikace. K tomu jsme použili — nástroj, který pomocí agentů na každém uzlu Kubernetes umožňuje uživatelům (technikům nasazujícím aplikace do clusteru) přiřazovat role IAM kontejnerům v podech, jako by se jednalo o instance EC2. KIAM zachycuje volání služby AWS Instance Metadata a zpracovává je ze své mezipaměti, poté co je předtím obdržel od AWS. Z pohledu aplikace se nic nemění.
KIAM poskytuje podům krátkodobé certifikáty. To dává smysl vzhledem k tomu, že průměrná životnost podu je kratší než u instance EC2. Ve výchozím nastavení certifikáty vyprší. .
Kombinace těchto dvou výchozích nastavení nakonec vytváří problém. Každý certifikát poskytnutý aplikaci vyprší po 15 minutách. Sada AWS Java SDK vynucuje obnovení jakéhokoli certifikátu, kterému zbývá méně než 15 minut do vypršení platnosti.
V důsledku toho je dočasný certifikát nucen obnovovat s každým požadavkem, což s sebou nese několik volání AWS API a výrazně zvyšuje latenci. Toto jsme zjistili v AWS Java SDK. , který zmiňuje podobný problém.
Řešení se ukázalo být jednoduché. Jednoduše jsme překonfigurovali KIAM tak, aby vyžadoval certifikáty s delší dobou platnosti. Jakmile se tak stalo, požadavky začaly probíhat bez služby AWS Metadata a latence klesla na úrovně ještě nižší než v EC2.
Závěry
Na základě našich zkušeností s migracemi nejsou jedním z nejčastějších zdrojů problémů chyby v Kubernetes ani v jiných prvcích platformy. Ani nesouvisí s žádnými zásadními nedostatky v mikroslužbách, které migrujeme. Problémy často vznikají jednoduše proto, že dáváme dohromady různé prvky.
Mícháme složité systémy, které spolu nikdy předtím neinteragovaly, a očekáváme, že vytvoří jeden, větší systém. Bohužel, čím více prvků, tím větší je potenciál pro chyby a vyšší entropie.
V našem případě nebyla vysoká latence důsledkem chyb nebo špatných rozhodnutí v Kubernetes, KIAM, AWS Java SDK nebo naší mikroslužbě. Byla výsledkem dvou nezávislých výchozích nastavení: jednoho v KIAM a jednoho v AWS Java SDK. Samostatně dávají smysl obě nastavení: aktivní politika obnovy certifikátů v AWS Java SDK a krátká doba vypršení platnosti certifikátu v KAIM. Ale v kombinaci se výsledky stávají nepředvídatelnými. Dvě nezávislá a logická řešení nemusí nutně dávat smysl, když jsou zkombinována.
PS od překladatele
Více se o architektuře utility KIAM pro integraci AWS IAM s Kubernetes dozvíte v od jeho tvůrců.
A na našem blogu si můžete také přečíst:
- «";
- «";
- «";
- «".
Zdroj: www.habr.com
