


S databází Apache Cassandra a potřebou provozovat ji v rámci infrastruktury založené na Kubernetes se setkáváme pravidelně. V tomto materiálu se podělíme o naši vizi nezbytných kroků, kritérií a stávajících řešení (včetně přehledu operátorů) pro migraci Cassandry na K8.
"Kdo může vládnout ženě, může také vládnout státu"
Kdo je Cassandra? Jedná se o distribuovaný úložný systém navržený pro správu velkých objemů dat při zajištění vysoké dostupnosti bez jediného bodu selhání. Projekt sotva potřebuje dlouhý úvod, proto uvedu pouze hlavní rysy Cassandry, které budou relevantní v kontextu konkrétního článku:
- Cassandra je napsána v Javě.
- Topologie Cassandra zahrnuje několik úrovní:
- Uzel – jedna nasazená instance Cassandra;
- Rack je skupina instancí Cassandra, spojených nějakou charakteristikou, umístěných ve stejném datovém centru;
- Datacenter – kolekce všech skupin instancí Cassandra umístěných v jednom datovém centru;
- Cluster je soubor všech datových center.
- Cassandra používá k identifikaci uzlu IP adresu.
- Pro urychlení operací zápisu a čtení ukládá Cassandra některá data do paměti RAM.
Nyní - ke skutečnému potenciálnímu přechodu na Kubernetes.
Kontrolní seznam pro převod
Když už mluvíme o migraci Cassandry na Kubernetes, doufáme, že s přesunem bude jeho správa pohodlnější. Co k tomu bude potřeba, co s tím pomůže?
1. Ukládání dat
Jak již bylo upřesněno, Cassanda ukládá část dat do RAM – in Zapamatovatelný. Existuje ale ještě jedna část dat, která se ukládá na disk – ve formuláři SSTable. K těmto datům je přidána entita Zapsat protokol — záznamy o všech transakcích, které se také ukládají na disk.
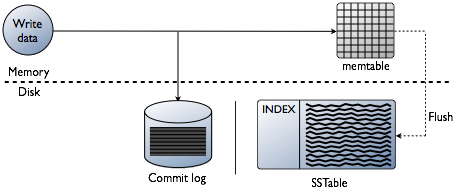
Napište transakční diagram v Cassandře
V Kubernetes můžeme k ukládání dat použít PersistentVolume. Díky osvědčeným mechanismům je práce s daty v Kubernetes rok od roku snazší.
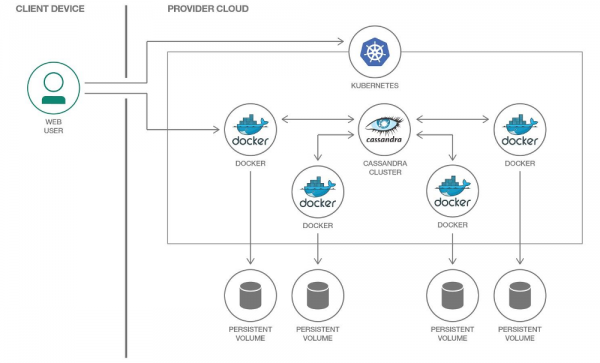
Každému modulu s Cassandrou přidělíme jeho vlastní PersistentVolume
Je důležité poznamenat, že Cassandra sama o sobě zahrnuje replikaci dat a nabízí pro to vestavěné mechanismy. Pokud tedy budujete cluster Cassandra z velkého počtu uzlů, není potřeba pro ukládání dat používat distribuované systémy jako Ceph nebo GlusterFS. V tomto případě by bylo logické ukládat data na hostitelský disk pomocí nebo montáž hostPath.
Další otázkou je, zda chcete pro každou větev funkcí vytvořit samostatné prostředí pro vývojáře. V tomto případě by správný přístup byl zvýšit jeden uzel Cassandra a uložit data do distribuovaného úložiště, tj. zmiňovaný Ceph a GlusterFS budou vaše možnosti. Pak bude mít vývojář jistotu, že o testovací data nepřijde ani v případě ztráty jednoho z uzlů clusteru Kuberntes.
2. Sledování
Prakticky nespornou volbou pro implementaci monitorování v Kubernetes je Prometheus (podrobně jsme o tom hovořili v ). Jak je na tom Cassandra s exportéry metrik pro Prometheus? A co je ještě důležitější, s odpovídajícími řídicími panely pro Grafana?
Příklad vzhledu grafů v Grafaně pro Cassandru
Existují pouze dva vývozci: и .
První jsme si vybrali, protože:
- JMX Exporter roste a vyvíjí se, zatímco Cassandra Exporter nebyla schopna získat dostatečnou podporu komunity. Cassandra Exporter stále nepodporuje většinu verzí Cassandry.
- Můžete jej spustit jako javaagent přidáním příznaku
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - Jeden pro něj existuje , který není kompatibilní s Cassandra Exporter.
3. Výběr primitiv Kubernetes
Podle výše uvedené struktury clusteru Cassandra se pokusme převést vše, co je tam popsáno, do terminologie Kubernetes:
- Cassandra Node → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → fond ze StatefulSets
- Cluster Cassandra → ???
Ukazuje se, že chybí nějaká další entita pro správu celého clusteru Cassandra najednou. Ale pokud něco neexistuje, můžeme to vytvořit! Kubernetes má pro tento účel mechanismus pro definování vlastních zdrojů - .
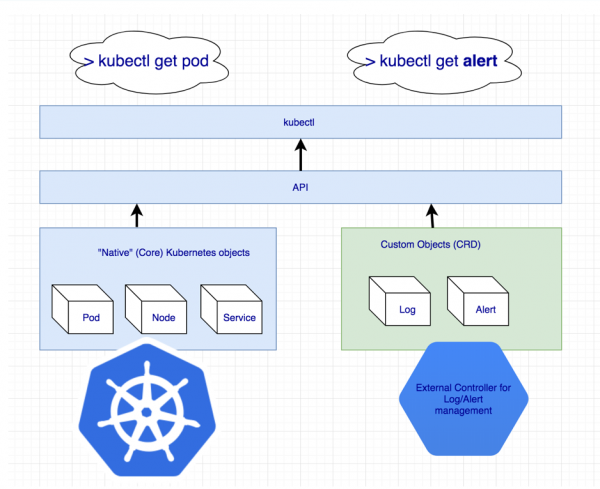
Deklarování dalších zdrojů pro protokoly a výstrahy
Vlastní zdroj sám o sobě ale nic neznamená: koneckonců vyžaduje kontrolor. Možná budete muset vyhledat pomoc ...
4. Identifikace lusků
V odstavci výše jsme se dohodli, že jeden uzel Cassandra se bude rovnat jednomu podu v Kubernetes. Ale IP adresy modulů budou pokaždé jiné. A identifikace uzlu v Cassandře je založena na IP adrese... Ukazuje se, že po každém odebrání podu Cassandra cluster přidá nový uzel.
Existuje cesta ven, a nejen jedna:
- Můžeme vést záznamy podle identifikátorů hostitele (UUID, které jedinečně identifikují instance Cassandry) nebo podle IP adres a vše uložit do nějakých struktur/tabulek. Metoda má dvě hlavní nevýhody:
- Riziko, že dojde ke konfliktu, pokud dva uzly spadnou najednou. Po vzestupu budou uzly Cassandra současně požadovat IP adresu z tabulky a soutěžit o stejný zdroj.
- Pokud uzel Cassandra ztratil svá data, nebudeme jej již schopni identifikovat.
- Druhé řešení vypadá jako malý hack, ale přesto: můžeme vytvořit službu s ClusterIP pro každý uzel Cassandra. Problémy s touto implementací:
- Pokud je v clusteru Cassandra mnoho uzlů, budeme muset vytvořit mnoho služeb.
- Funkce ClusterIP je implementována prostřednictvím iptables. To se může stát problémem, pokud má cluster Cassandra mnoho (1000... nebo dokonce 100?) uzlů. Ačkoli může tento problém vyřešit.
- Třetím řešením je použití sítě uzlů pro uzly Cassandra namísto vyhrazené sítě podů povolením nastavení
hostNetwork: true. Tato metoda ukládá určitá omezení:- K výměně jednotek. Je nutné, aby nový uzel měl stejnou IP adresu jako předchozí (v cloudech jako AWS, GCP je to téměř nemožné);
- Pomocí sítě uzlů clusteru začínáme soutěžit o síťové zdroje. Proto umístění více než jednoho modulu s Cassandrou na jeden uzel clusteru bude problematické.
5. Zálohy
Chceme uložit plnou verzi dat jednoho uzlu Cassandra podle plánu. Kubernetes poskytuje pohodlnou funkci pomocí , ale tady nám do kol vkládá paprsky sama Cassandra.
Dovolte mi připomenout, že Cassandra ukládá některá data do paměti. Chcete-li provést úplnou zálohu, potřebujete data z paměti (Pamětihodnosti) přesunout na disk (SSTtables). V tomto okamžiku uzel Cassandra přestane přijímat připojení a zcela se vypne z clusteru.
Poté je záloha odstraněna (momentka) a schéma se uloží (klíčový prostor). A pak se ukáže, že jen záloha nám nic nedá: potřebujeme uložit identifikátory dat, za které byl uzel Cassandra zodpovědný – to jsou speciální tokeny.
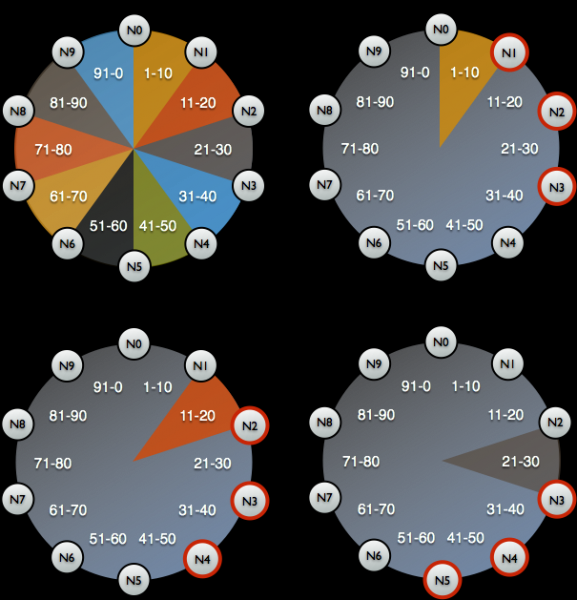
Distribuce tokenů k identifikaci dat, za která jsou uzly Cassandra zodpovědné
Ukázkový skript pro převzetí zálohy Cassandra od Googlu v Kubernetes naleznete na . Jediný bod, který skript nebere v úvahu, je resetování dat do uzlu před pořízením snímku. To znamená, že záloha se neprovádí pro aktuální stav, ale pro stav o něco dříve. Ale pomáhá to nevyřadit uzel z provozu, což se zdá velmi logické.
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Příklad bash skriptu pro vytvoření zálohy z jednoho uzlu Cassandra
Hotová řešení pro Cassandru v Kubernetes
Co se v současnosti používá k nasazení Cassandry v Kubernetes a která z nich nejlépe vyhovuje daným požadavkům?
1. Řešení založená na grafech StatefulSet nebo Helm
Použití základních funkcí StatefulSets ke spuštění clusteru Cassandra je dobrá volba. Pomocí šablony Helm chart a Go můžete uživateli poskytnout flexibilní rozhraní pro nasazení Cassandry.
To obvykle funguje dobře... dokud se nestane něco neočekávaného, jako je selhání uzlu. Standardní nástroje Kubernetes prostě nemohou zohlednit všechny výše popsané funkce. Tento přístup je navíc velmi omezený v tom, jak moc může být rozšířen pro složitější použití: výměna uzlů, zálohování, obnova, monitorování atd.
Zástupci:
- ;
- .
Oba grafy jsou stejně dobré, ale podléhají výše popsaným problémům.
2. Řešení založená na Kubernetes Operator
Takové možnosti jsou zajímavější, protože poskytují dostatek příležitostí pro správu clusteru. Pro návrh operátora Cassandra, stejně jako jakékoli jiné databáze, dobrý vzor vypadá jako Sidecar <-> Controller <-> CRD:
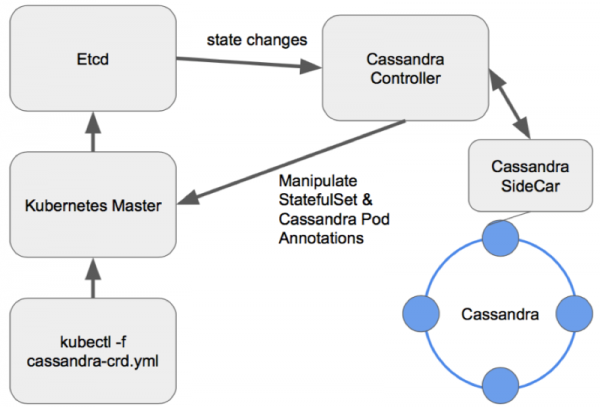
Schéma správy uzlů v dobře navrženém operátoru Cassandra
Podívejme se na stávající operátory.
1. Cassandra-operátor z instaclustru
- Připravenost: Alfa
- Licence: Apache 2.0
- Implementováno v: Java
Jedná se skutečně o velmi slibný a aktivně se rozvíjející projekt od společnosti, která nabízí řízená nasazení Cassandry. Jak je popsáno výše, používá kontejner postranního vozíku, který přijímá příkazy přes HTTP. Napsáno v Javě a někdy postrádá pokročilejší funkce knihovny client-go. Provozovatel také nepodporuje různé Racky pro jedno Datacentrum.
Operátor má ale takové výhody, jako je podpora monitorování, správa clusteru na vysoké úrovni pomocí CRD a dokonce dokumentace pro vytváření záloh.
2. Navigátor z Jetstack
- Připravenost: Alfa
- Licence: Apache 2.0
- Realizováno v: Golang
Prohlášení navržené pro nasazení DB-as-a-Service. V současné době podporuje dvě databáze: Elasticsearch a Cassandra. Má tak zajímavá řešení, jako je řízení přístupu k databázi přes RBAC (k tomu má svůj samostatný navigátor-apiserver). Zajímavý projekt, který by stál za bližší prozkoumání, ale poslední commit vznikl před rokem a půl, což jeho potenciál jednoznačně snižuje.
3. Cassandra-operátor od vgkowski
- Připravenost: Alfa
- Licence: Apache 2.0
- Realizováno v: Golang
Nemysleli to „vážně“, protože poslední závazek k úložišti byl před více než rokem. Vývoj operátora je opuštěn: nejnovější verze Kubernetes, která je hlášena jako podporovaná, je 1.9.
4. Cassandra-operátor od Rooka
- Připravenost: Alfa
- Licence: Apache 2.0
- Realizováno v: Golang
Operátor, jehož vývoj nejde tak rychle, jak bychom si přáli. Má promyšlenou strukturu CRD pro správu clusteru, řeší problém identifikace uzlů pomocí Service s ClusterIP (stejný „hack“)... ale to je zatím vše. V současné době neexistuje žádné monitorování ani zálohování po vybalení (mimochodem, jsme pro monitorování ). Zajímavostí je, že pomocí tohoto operátoru můžete nasadit i ScyllaDB.
Pozn.: Tento operátor jsme s drobnými úpravami použili v jednom z našich projektů. Po celou dobu provozu (~4 měsíce provozu) nebyly v práci operátora zaznamenány žádné problémy.
5. CassKop od Orange
- Připravenost: Alfa
- Licence: Apache 2.0
- Realizováno v: Golang
Nejmladší operátor na seznamu: první potvrzení bylo provedeno 23. května 2019. Již nyní má ve svém arzenálu velké množství funkcí z našeho seznamu, o nichž více podrobností naleznete v úložišti projektu. Operátor je postaven na základě oblíbeného operator-sdk. Podporuje monitorování ihned po vybalení. Hlavním rozdílem od ostatních operátorů je použití , implementovaný v Pythonu a používaný pro komunikaci mezi uzly Cassandra.
Závěry
Množství přístupů a možných možností portování Cassandry na Kubernetes mluví samo za sebe: téma je žádané.
V této fázi můžete na vlastní nebezpečí a riziko vyzkoušet cokoliv z výše uvedeného: žádný z vývojářů nezaručuje 100% provoz svého řešení v produkčním prostředí. Ale již nyní mnoho produktů vypadá slibně, že se je pokusíme použít ve vývojových lavicích.
Myslím, že v budoucnu se tato žena na lodi bude hodit!
PS
Přečtěte si také na našem blogu:
- «";
- «";
- «";
- «".
Zdroj: www.habr.com
