


Před pár lety Kubernetes na oficiálním blogu GitHubu. Od té doby se stala standardní technologií pro nasazování služeb. Kubernetes nyní spravuje významnou část interních a veřejných služeb. Jak naše clustery rostly a požadavky na výkon byly přísnější, začali jsme si všímat, že některé služby na Kubernetes sporadicky zaznamenávají latenci, kterou nelze vysvětlit zátěží samotné aplikace.
Aplikace v podstatě zažívají náhodnou síťovou latenci až 100 ms nebo více, což vede k časovým limitům nebo opakování. Očekávalo se, že služby budou schopny reagovat na požadavky mnohem rychleji než 100 ms. To je ale nemožné, když samotné připojení zabere tolik času. Samostatně jsme pozorovali velmi rychlé dotazy MySQL, které by měly trvat milisekundy, a MySQL se dokončilo v milisekundách, ale z pohledu žádající aplikace trvala odpověď 100 ms nebo více.
Okamžitě bylo jasné, že problém nastal pouze při připojení k uzlu Kubernetes, i když hovor přišel zvenčí. Nejjednodušší způsob, jak problém reprodukovat, je test , který běží z libovolného interního hostitele, testuje službu Kubernetes na konkrétním portu a sporadicky zaznamenává vysokou latenci. V tomto článku se podíváme na to, jak se nám podařilo vypátrat příčinu tohoto problému.
Odstranění zbytečné složitosti v řetězci vedoucí k selhání
Reprodukcí stejného příkladu jsme chtěli zúžit zaměření problému a odstranit zbytečné vrstvy složitosti. Zpočátku bylo mezi Podravkou a Kubernetes lusky příliš mnoho prvků. Chcete-li identifikovat hlubší problém se sítí, musíte některé z nich vyloučit.
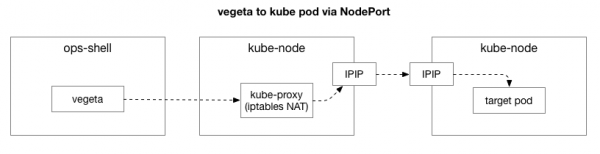
Klient (Vegeta) vytvoří TCP spojení s libovolným uzlem v clusteru. Kubernetes funguje jako překryvná síť (nad stávající sítí datových center), která využívá , to znamená, že zapouzdří IP pakety překryvné sítě uvnitř IP paketů datového centra. Při připojení k prvnímu uzlu se provede překlad síťových adres (NAT) stavový k překladu IP adresy a portu uzlu Kubernetes na IP adresu a port v překryvné síti (konkrétně pod s aplikací). U příchozích paketů se provádí obrácená posloupnost akcí. Jedná se o komplexní systém se spoustou stavu a mnoha prvky, které se neustále aktualizují a mění, jak jsou služby nasazovány a přesouvány.
Užitečnost tcpdump v testu Vegeta je prodleva při TCP handshake (mezi SYN a SYN-ACK). Chcete-li odstranit tuto zbytečnou složitost, můžete použít hping3 pro jednoduché „pingy“ s pakety SYN. Zkontrolujeme, zda nedošlo ke zpoždění v paketu odpovědi, a poté resetujeme připojení. Můžeme filtrovat data tak, aby zahrnovala pouze pakety delší než 100 ms a získat jednodušší způsob, jak reprodukovat problém, než je úplný test síťové vrstvy 7 Vegeta. Zde jsou "pingy" uzlu Kubernetes pomocí TCP SYN/SYN-ACK na službě "port uzlu" (30927) v intervalech 10 ms, filtrované podle nejpomalejších odpovědí:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 ms
Může okamžitě provést první pozorování. Soudě podle pořadových čísel a časování je jasné, že nejde o jednorázové zácpy. Zpoždění se často kumuluje a nakonec se zpracuje.
Dále chceme zjistit, které složky se mohou podílet na vzniku přetížení. Možná jsou to některá ze stovek pravidel iptables v NAT? Nebo jsou nějaké problémy s IPIP tunelováním v síti? Jedním ze způsobů, jak to zkontrolovat, je otestovat každý krok systému jeho odstraněním. Co se stane, když odeberete NAT a logiku brány firewall a ponecháte pouze část IPIP:
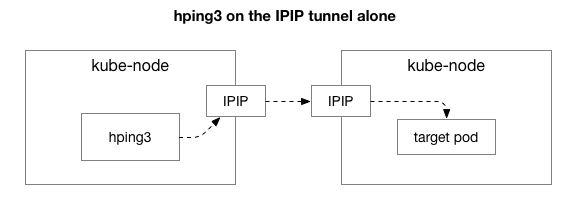
Naštěstí, Linux umožňuje snadný přímý přístup k vrstvě IP overlay, pokud je počítač ve stejné síti:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 ms
Soudě podle výsledků problém stále přetrvává! To nezahrnuje iptables a NAT. Takže problém je TCP? Podívejme se, jak probíhá běžný ICMP ping:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
Výsledky ukazují, že problém nezmizel. Možná je to IPIP tunel? Pojďme si test dále zjednodušit:
Posílají se všechny pakety mezi těmito dvěma hostiteli?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms
Zjednodušili jsme situaci tak, že dva uzly Kubernetes si navzájem posílají jakýkoli paket, dokonce i ICMP ping. Stále vidí latenci, pokud je cílový hostitel "špatný" (někteří horší než ostatní).
Nyní poslední otázka: proč ke zpoždění dochází pouze na serverech kube-node? A stane se to, když je kube-node odesílatel nebo příjemce? Naštěstí je to také docela snadné zjistit odesláním paketu od hostitele mimo Kubernetes, ale se stejným „známým špatným“ příjemcem. Jak vidíte, problém nezmizel:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 ms
Poté spustíme stejné požadavky z předchozího zdrojového uzlu kube na externího hostitele (což vylučuje zdrojového hostitele, protože ping obsahuje komponentu RX i TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
Zkoumáním zachycování paketů s latencí jsme získali další informace. Konkrétně, že odesílatel (dole) vidí tento časový limit, ale příjemce (nahoře) ne - viz sloupec Delta (v sekundách):
Pokud se navíc podíváte na rozdíl v pořadí paketů TCP a ICMP (podle pořadových čísel) na straně příjemce, pakety ICMP vždy dorazí ve stejném pořadí, v jakém byly odeslány, ale s odlišným načasováním. Zároveň se někdy TCP pakety prokládají a některé z nich uvíznou. Zejména pokud prozkoumáte porty paketů SYN, jsou v pořádku na straně odesílatele, ale ne na straně příjemce.
Je jemný rozdíl v tom, jak moderní servery (jako ty v našem datovém centru) zpracovávají pakety obsahující TCP nebo ICMP. Když paket dorazí, síťový adaptér ho „zahašuje na připojení“, to znamená, že se pokusí rozdělit spojení do front a každou frontu odeslat do samostatného jádra procesoru. U TCP tento hash zahrnuje zdrojovou i cílovou IP adresu a port. Jinými slovy, každé spojení je hashováno (potenciálně) jinak. V případě protokolu ICMP se hašují pouze adresy IP, protože neexistují žádné porty.
Další nové pozorování: během tohoto období vidíme zpoždění ICMP u veškeré komunikace mezi dvěma hostiteli, ale TCP nikoli. To nám říká, že příčina pravděpodobně souvisí s hašováním fronty RX: zahlcení je téměř jistě ve zpracování paketů RX, nikoli v odesílání odpovědí.
To eliminuje odesílání paketů ze seznamu možných příčin. Nyní víme, že problém se zpracováním paketů je na straně příjmu na některých serverech kube-node.
Pochopení zpracování paketů v jádře Linux
Abychom pochopili, proč k problému dochází na přijímači na některých serverech s uzly Kube, podívejme se, jak jádro... Linux zpracovává pakety.
Vrátíme-li se k nejjednodušší tradiční implementaci, síťová karta paket přijme a odešle jádro Linuxže existuje paket, který je třeba zpracovat. Jádro zastaví ostatní práci, přepne kontext na obslužnou rutinu přerušení, zpracuje paket a poté se vrátí k aktuálním úlohám.
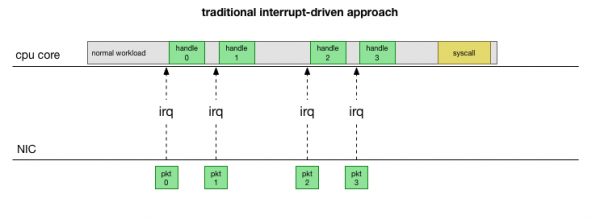
Toto přepínání kontextu je pomalé: latence nemusela být patrná na 10Mbps síťových kartách v 90. letech, ale na moderních 10G kartách s maximální propustností 15 milionů paketů za sekundu může být každé jádro malého osmijádrového serveru přerušeno miliony krát za sekundu.
Aby se předešlo neustálému zpracování přerušení, před mnoha lety v Linux přidal : Síťové API, které všechny moderní ovladače používají ke zlepšení výkonu při vysokých rychlostech. Při nízkých rychlostech jádro stále přijímá přerušení ze síťové karty starým způsobem. Jakmile dorazí dostatek paketů, které překročí práh, jádro zakáže přerušení a místo toho začne dotazovat síťový adaptér a sbírat pakety po částech. Zpracování se provádí v softirq, tedy v po systémových voláních a hardwarových přerušeních, kdy jádro (na rozdíl od uživatelského prostoru) již běží.
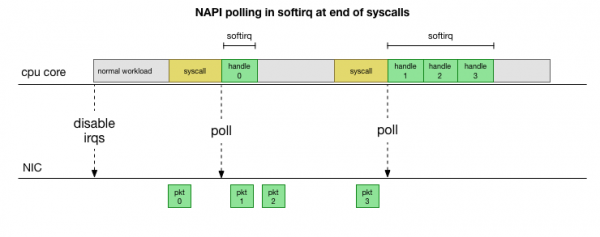
Je to mnohem rychlejší, ale způsobuje to jiný problém. Pokud je paketů příliš mnoho, pak veškerý čas stráví zpracováním paketů ze síťové karty a procesy v uživatelském prostoru nemají čas tyto fronty skutečně vyprázdnit (čtení z TCP spojení atd.). Nakonec se fronty zaplní a začneme zahazovat pakety. Ve snaze najít rovnováhu nastaví jádro rozpočet pro maximální počet paketů zpracovaných v kontextu softirq. Po překročení tohoto rozpočtu se probudí samostatné vlákno ksoftirqd (jednoho z nich uvidíte v ps na jádro), který zpracovává tyto softirq mimo normální cestu systémového volání/přerušení. Toto vlákno je naplánováno pomocí standardního plánovače procesů, který se pokouší spravedlivě alokovat zdroje.
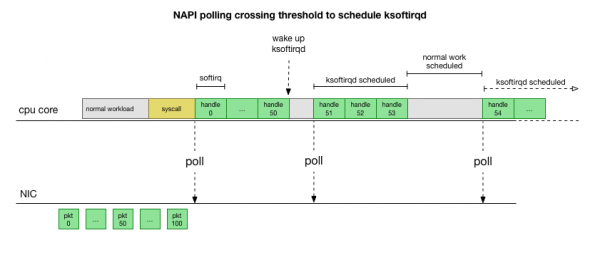
Po prostudování toho, jak jádro zpracovává pakety, můžete vidět, že existuje určitá pravděpodobnost zahlcení. Pokud jsou volání softirq přijímána méně často, pakety budou muset nějakou dobu čekat na zpracování ve frontě RX na síťové kartě. Může to být způsobeno nějakou úlohou, která blokuje jádro procesoru, nebo něco jiného brání jádru v běhu softirq.
Zúžení zpracování až na jádro nebo metodu
Zpoždění Softirq jsou zatím jen odhadem. Ale dává to smysl a víme, že vidíme něco velmi podobného. Dalším krokem je tedy potvrzení této teorie. A pokud se to potvrdí, pak najděte důvod zpoždění.
Vraťme se k našim pomalým paketům:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
Jak již bylo zmíněno, tyto ICMP pakety jsou hašovány do jediné fronty RX síťové karty a zpracovávány jedním jádrem CPU. Chceme-li pochopit fungování... Linux, je užitečné vědět, kde (na kterém jádru CPU) a jak (softirq, ksoftirqd) jsou tyto pakety zpracovávány, aby bylo možné proces sledovat.
Nyní je čas použít nástroje, které umožňují sledovat výkon jádra v reálném čase. LinuxZde jsme použili . Tato sada nástrojů vám umožňuje psát malé programy v C, které zachytí libovolné funkce v jádře a uloží události do pythonského programu v uživatelském prostoru, který je dokáže zpracovat a vrátit vám výsledek. Zapojování libovolných funkcí do jádra je složitá záležitost, ale nástroj je navržen pro maximální zabezpečení a je navržen tak, aby přesně vystopoval ty druhy produkčních problémů, které nelze snadno reprodukovat v testovacím nebo vývojovém prostředí.
Plán je zde jednoduchý: víme, že jádro zpracovává tyto ICMP pingy, takže zavěsíme na funkci jádra , který přijme příchozí paket ICMP echo request a zahájí odeslání ICMP echo odpovědi. Paket můžeme identifikovat zvýšením čísla icmp_seq, které se zobrazí hping3 vyšší.
Kód vypadá to složitě, ale není to tak děsivé, jak se zdá. Funkce icmp_echo převody struct sk_buff *skb: Toto je paket s "echo request". Můžeme to sledovat, vytáhnout sekvenci echo.sequence (což je srovnatelné s icmp_seq od hping3 выше) a odešlete jej do uživatelského prostoru. Je také vhodné zachytit aktuální název/id procesu. Níže jsou uvedeny výsledky, které vidíme přímo, když jádro zpracovává pakety:
TGID PID NÁZEV PROCESU ICMP_SEQ 0 0 swapper/11 770 0 0 swapper/11 771 0 0 swapper/11 772 0 0 swapper/11 773 0 0 swapper/11 774 20041 20086 prowame/775 swapper 0 swapper/0 11 776 0 0 swapper/11 777 0 0 paprsků-report-s 11
Zde je třeba poznamenat, že v kontextu softirq procesy, které provedly systémová volání, se budou jevit jako "procesy", i když je to ve skutečnosti jádro, které bezpečně zpracovává pakety v kontextu jádra.
Pomocí tohoto nástroje můžeme přiřadit konkrétní procesy ke konkrétním balíčkům, které vykazují zpoždění hping3. Pojďme si to zjednodušit grep na tomto zachycení pro určité hodnoty icmp_seq. Pakety odpovídající výše uvedeným hodnotám icmp_seq byly zaznamenány spolu s jejich RTT, které jsme pozorovali výše (v závorkách jsou očekávané hodnoty RTT pro pakety, které jsme odfiltrovali kvůli hodnotám RTT menším než 50 ms):
TGID PID NÁZEV PROCESU ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99 ms ksoft76** 76d11m 1954 ksoftir qd/89 76 ** 76 ms 11 1955 ksoftirqd/ 79 76 ** 76 ms 11 1956 ksoftirqd/69 76 ** 76 ms 11 1957 ksoftirqd/59 76 ** (76 ms) 11 1958 ksoftirqd/49 76 ** (76 ms 11 kB) 1959 ms** (39 ms 76 k76) 11 1960 ksoft irqd/ 29 76 ** (76 ms) 11 1961 ksoftirqd/19 76 ** (76 ms) -- 11 1962 cadvisor 9 10137 10436 cadvisor 2068 10137 10436 ** (2069 ms) -- 76 76 cadvisor 11 2070 75 cadvisor 76 76 dvisor 11 ** 2071 65 ms 76 ksoftirqd/76 11 ** 2072 ms 55 76 ksoftirqd/ 76 11 ** 2073 ms 45 76 ksoftirqd/76 11 ** (2074 ms) 35 76 ksoftirqd/76 11 ** (2075 ms) 25 76 ksoftirqd/76 11/2076** (ksoftirq15) ** ** (76 ms ) 76 11 ksoftirqd/2077 5 ** (XNUMX ms)
Výsledky nám říkají několik věcí. Za prvé, všechny tyto balíčky jsou zpracovávány kontextem ksoftirqd/11. To znamená, že pro tuto konkrétní dvojici počítačů byly pakety ICMP hašovány do jádra 11 na přijímací straně. Také vidíme, že kdykoli dojde k zaseknutí, existují pakety, které jsou zpracovány v kontextu systémového volání cadvisor. Pak ksoftirqd převezme úlohu a zpracuje nashromážděnou frontu: přesně takový počet paketů, který se poté nashromáždil cadvisor.
Skutečnost, že bezprostředně před tím vždy funguje cadvisor, znamená jeho zapojení do problému. Ironicky, účel - "analyzovat využití zdrojů a výkonnostní charakteristiky běžících kontejnerů" spíše než způsobovat tento problém s výkonem.
Stejně jako u jiných aspektů kontejnerů se jedná o vysoce pokročilé nástroje a lze očekávat, že za určitých nepředvídaných okolností budou mít problémy s výkonem.
Co dělá cadvisor, že zpomaluje frontu paketů?
Nyní máme docela dobrou představu o tom, jak k pádu dochází, který proces ho způsobuje a na kterém CPU. Vidíme, že kvůli hardwarovému zámku jádro Linux nemá čas si to naplánovat ksoftirqd. A vidíme, že pakety jsou zpracovávány v kontextu cadvisor. To je logické předpokládat cadvisor spustí pomalé systémové volání, po kterém jsou zpracovány všechny pakety nashromážděné v té době:
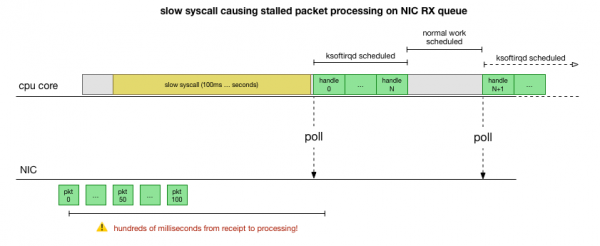
To je teorie, ale jak to otestovat? Co můžeme udělat, je vysledovat jádro CPU během tohoto procesu, najít bod, kde počet paketů překročí rozpočet a volá se ksoftirqd, a pak se podívat o něco dále zpět, abychom viděli, co přesně běželo na jádru CPU těsně před tímto bodem. . Je to jako rentgenování CPU každých pár milisekund. Bude to vypadat nějak takto:
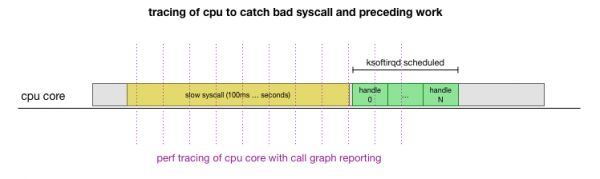
To vše lze pohodlně provést pomocí stávajících nástrojů. Například, kontroluje dané jádro CPU na zadané frekvenci a dokáže vygenerovat graf volání běžícího systému, včetně uživatelského prostoru i jádra. LinuxTento záznam můžete vzít a zpracovat pomocí malého forku programu. od Brendana Gregga, který zachovává pořadí trasování zásobníku. Můžeme ukládat jednořádkové trasování zásobníku každou 1 ms a poté zvýraznit a uložit vzorek 100 milisekund před trasováním ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Zde jsou výsledky:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Je zde spousta věcí, ale hlavní je, že najdeme vzor „cadvisor before ksoftirqd“, který jsme viděli dříve v ICMP traceru. Co to znamená?
Každý řádek je trasováním CPU v určitém okamžiku. Každé volání v zásobníku na řádku je odděleno středníkem. Uprostřed řádků vidíme volání syscall: read(): .... ;do_syscall_64;sys_read; .... Cadvisor tedy tráví spoustu času systémovým voláním read()související s funkcemi mem_cgroup_* (horní část zásobníku/konec řádku).
Je nepohodlné vidět v trasování hovoru, co přesně se čte, takže běžme strace a podívejme se, co dělá cadvisor a najdeme systémová volání delší než 100 ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
Jak můžete očekávat, vidíme zde pomalé hovory read(). Z obsahu operací čtení a kontextu mem_cgroup je jasné, že tyto výzvy read() odkazovat na soubor memory.stat, který ukazuje využití paměti a limity cgroup (technologie izolace zdrojů Docker). Nástroj cadvisor se dotazuje na tento soubor, aby získal informace o využití prostředků pro kontejnery. Pojďme zkontrolovat, zda jádro nebo cadvisor nedělá něco neočekávaného:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
skutečné 0 m 0.153 s
uživatel 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $
Nyní můžeme chybu reprodukovat a pochopit, že jádro Linux setkává se s patologií.
Proč je operace čtení tak pomalá?
V této fázi je mnohem snazší najít zprávy od ostatních uživatelů o podobných problémech. Jak se ukázalo, v cadvisor trackeru byla tato chyba hlášena jako , jen si nikdo nevšiml, že se latence náhodně odráží i v síťovém zásobníku. Skutečně bylo zjištěno, že cadvisor spotřebovává více času CPU, než se očekávalo, ale tomu se nepřikládal velký význam, protože naše servery mají mnoho zdrojů CPU, takže problém nebyl pečlivě studován.
Problém je v tom, že cgroups berou v úvahu využití paměti v rámci jmenného prostoru (kontejneru). Když všechny procesy v této cgroup skončí, Docker uvolní paměťovou cgroup. „Paměť“ však není jen paměť procesů. Přestože se samotná procesní paměť již nepoužívá, zdá se, že jádro stále přiřazuje obsah mezipaměti, jako jsou dentries a inody (metadata adresářů a souborů), které jsou ukládány do mezipaměti v cgroup paměti. Z popisu problému:
zombie cgroups: cgroups, které nemají žádné procesy a byly smazány, ale stále mají přidělenou paměť (v mém případě z mezipaměti dentry, ale lze ji alokovat také z mezipaměti stránek nebo tmpfs).
Kontrola jádra všech stránek v mezipaměti při uvolňování cgroup může být velmi pomalá, takže je zvolen líný proces: počkejte, až budou tyto stránky znovu požadovány, a poté konečně vymažte cgroup, až bude paměť skutečně potřeba. Až do tohoto okamžiku je cgroup stále brána v úvahu při shromažďování statistik.
Z hlediska výkonu obětovali paměť výkonu: urychlili počáteční čištění tím, že ponechali část paměti v mezipaměti. Tohle je fajn. Když jádro používá poslední z mezipaměti, cgroup je nakonec vymazána, takže to nemůže být nazýváno "únik". Bohužel konkrétní implementace vyhledávacího mechanismu memory.stat v této verzi jádra (4.9) v kombinaci s obrovským množstvím paměti na našich serverech znamená, že obnovení nejnovějších dat uložených v mezipaměti a vymazání zombie cgroup trvá mnohem déle.
Ukázalo se, že některé z našich uzlů měly tolik zombíků cgroup, že čtení a latence přesáhly sekundu.
Řešením problému s cadvisorem je okamžité uvolnění mezipaměti dentries/inodes v celém systému, což okamžitě eliminuje latenci čtení a také latenci sítě na hostiteli, protože vymazáním mezipaměti se zapnou stránky zombie cgroup uložené v mezipaměti a také je uvolní. Toto není řešení, ale potvrzuje příčinu problému.
Ukázalo se, že v novějších verzích jádra (4.19+) se výkon volání zlepšil memory.stat, takže přechod na toto jádro problém vyřešil. Zároveň jsme měli nástroje pro detekci problematických uzlů v clusterech Kubernetes, jejich ladné vyprázdnění a restartování. Pročesali jsme všechny clustery, našli uzly s dostatečně vysokou latencí a restartovali je. To nám dalo čas aktualizovat OS na zbývajících serverech.
Sčítání
Protože tato chyba zastavila zpracování fronty RX NIC na stovky milisekund, způsobila současně jak vysokou latenci u krátkých připojení, tak latenci uprostřed připojení, například mezi požadavky MySQL a pakety odpovědí.
Pochopení a udržování výkonu nejzákladnějších systémů, jako je Kubernetes, je zásadní pro spolehlivost a rychlost všech služeb, které jsou na nich založeny. Každý systém, který provozujete, těží z vylepšení výkonu Kubernetes.
Zdroj: www.habr.com
