

Vzhledem k povaze mé práce se musím vypořádat se situacemi, kdy vývojář napíše požadavek a myslí si „…Základna je chytrá, všechno si poradí sama!«
V některých případech (částečně kvůli neznalosti možností databáze, částečně kvůli předčasným optimalizacím) vede tento přístup ke vzniku „Frankensteinů“.
Nejprve uvedu příklad takového požadavku:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Abychom objektivně vyhodnotili kvalitu dotazu, vytvořme náhodnou datovou sadu:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
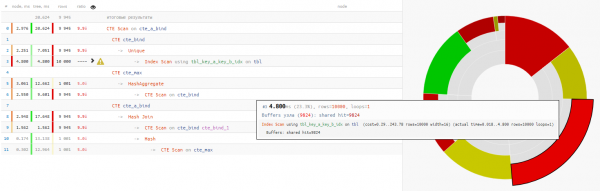
Ukazuje se, že je to čtení dat trvalo méně než čtvrtinu celkového času provedení dotazu:
Rozeberme to kousek po kousku
Pojďme se na žádost podívat blíže a zamyslet se:
- Proč je zde WITH RECURSIVE, když neexistují žádné rekurzivní CTE?
- Proč seskupovat min/max hodnoty do samostatného CTE, pokud jsou pak stále vázány na původní vzorek?
+25% času - Proč na konci používat opětovné čtení z předchozího CTE pomocí bezpodmínečného 'SELECT * FROM'?
+14% času
V tomto případě jsme měli velké štěstí, že pro připojení byl zvolen Hash Join, a nikoli Nested Loop, protože bychom pak neobdrželi ani jeden průchod CTE Scan, ale 10K!
Trochu o CTE skenováníZde si musíme pamatovat, že CTE sken je analogem Seq Scan. - tedy žádné indexování, ale pouze úplný výčet, což by vyžadovalo 10K x 0.3 ms = 3000ms při cyklování přes cte_max nebo 1K x 1.5 ms = 1500ms při smyčce pomocí cte_bind!
Co jste vlastně chtěl ve výsledku dosáhnout? Ano, to je ten typ otázky, která se obvykle objeví někde kolem 5. minuty analýzy dotazů „třípatrových“.
Chtěli jsme pro každý unikátní pár klíčů vygenerovat výstup min/max ze skupiny podle key_a.
Tak to pojďme použít k tomuhle :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 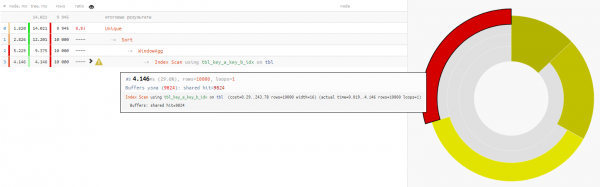
Protože čtení dat v obou možnostech trvá přibližně stejně 4-5 ms, pak celý náš časový zisk -32% - tohle je v nejčistší podobě zátěž odstraněna ze základny CPU, pokud je takový požadavek prováděn dostatečně často.
Obecně není třeba nutit základní oblečení „nosit kulaté věci, rolovat hranaté věci“.
Zdroj: www.habr.com
