

Navrhuji, abyste si přečetli přepis zprávy Vladimira Sitnikova z počátku roku 2016 „PostgreSQL a JDBC vytlačují veškerou šťávu“


Dobré odpoledne Jmenuji se Vladimír Sitnikov. Pro NetCracker pracuji 10 let. A hlavně se zabývám produktivitou. Vše, co souvisí s Javou, vše, co souvisí s SQL, je to, co miluji.
A dnes budu mluvit o tom, s čím jsme se ve firmě setkali, když jsme začali používat PostgreSQL jako databázový server. A většinou pracujeme s Javou. Ale to, co vám dnes povím, není jen o Javě. Jak ukázala praxe, vyskytuje se to i v jiných jazycích.

Promluvíme si:
- o vzorkování dat.
- O ukládání dat.
- A také o výkonu.
- A o podvodních hrábě, které jsou tam zahrabané.

Začněme jednoduchou otázkou. Z tabulky vybereme jeden řádek na základě primárního klíče.

Databáze je umístěna na stejném hostiteli. A celé to farmaření trvá 20 milisekund.

Těchto 20 milisekund je hodně. Pokud máte 100 takových požadavků, trávíte čas každou sekundu procházením těchto požadavků, to znamená, že ztrácíme čas.
Neradi to děláme a podíváme se, co nám k tomu základna nabízí. Databáze nám nabízí dvě možnosti provádění dotazů.

První možností je jednoduchá žádost. co je na tom dobrého? To, že to vezmeme a pošleme, a nic víc.

Databáze má také pokročilý dotaz, který je složitější, ale funkčnější. Samostatně můžete odeslat požadavek na analýzu, provedení, variabilní vazbu atd.
Super rozšířený dotaz je něco, čemu se v aktuální zprávě nebudeme věnovat. My možná něco chceme z databáze a existuje nějaký wishlist, který se v nějaké formě vytvořil, tedy to, co chceme, ale teď a v příštím roce je to nemožné. Takže jsme to jen nahráli a budeme chodit a otřásat hlavními lidmi.

A co můžeme udělat, je jednoduchý dotaz a rozšířený dotaz.
Co je na každém přístupu zvláštní?
Jednoduchý dotaz je dobrý pro jednorázové provedení. Jednou hotovo a zapomenuto. A problém je, že nepodporuje formát binárních dat, tedy není vhodný pro některé výkonné systémy.

Rozšířený dotaz – umožňuje ušetřit čas při analýze. To je to, co jsme udělali a začali používat. Tohle nám opravdu pomohlo. Ušetří se nejen na analýze. Dochází k úsporám za přenos dat. Přenos dat v binárním formátu je mnohem efektivnější.

Pojďme k praxi. Takto vypadá typická aplikace. Může to být Java atd.
Vytvořili jsme prohlášení. Provedl příkaz. Vytvořeno zavřít. Kde je tady chyba? Co je za problém? Žádný problém. Tak se to píše ve všech knihách. Tak by se to mělo psát. Pokud chcete maximální výkon, pište takto.

Praxe ale ukázala, že to nefunguje. Proč? Protože máme metodu "zavřít". A když to uděláme, z pohledu databáze se ukáže, že je to jako když kuřák pracuje s databází. Řekli jsme „PARSE EXECUTE DEALLOCATE“.
Proč všechno to extra vytváření a vykládání výpisů? Nikdo je nepotřebuje. Ale to, co se obvykle děje v PreparedStatements je, že když je zavřeme, zavřou vše v databázi. To není to, co chceme.

Chceme, jako zdraví lidé, pracovat se základnou. Vzali jsme a připravili naše prohlášení jednou, pak jsme ho provedli mnohokrát. Ve skutečnosti byly mnohokrát - to je jednou za celou životnost aplikací - analyzovány. A používáme stejné ID příkazu na různých RESTech. To je náš cíl.

Jak toho můžeme dosáhnout?

Je to velmi jednoduché – není třeba uzavírat prohlášení. Píšeme to takto: „připravit“ „provést“.


Pokud něco takového spustíme, tak je jasné, že někde něco přeteče. Pokud to není jasné, můžete to zkusit. Pojďme napsat benchmark, který používá tuto jednoduchou metodu. Vytvořte prohlášení. Spustíme jej na nějaké verzi ovladače a zjistíme, že se docela rychle zhroutí se ztrátou veškeré paměti, kterou měl.
Je jasné, že takové chyby lze snadno opravit. Nebudu o nich mluvit. Ale řeknu, že nová verze funguje mnohem rychleji. Metoda je to hloupá, ale stejně.

Jak správně pracovat? Co pro to musíme udělat?
Ve skutečnosti aplikace vždy zavírají příkazy. Ve všech knihách se píše, že to zavřete, jinak paměť vyteče.
A PostgreSQL neví, jak ukládat dotazy do mezipaměti. Je nutné, aby si každá relace vytvořila tuto mezipaměť sama pro sebe.
A také nechceme ztrácet čas analýzou.

A jako obvykle máme dvě možnosti.
První možností je, že to vezmeme a řekneme, že vše zabalíme do PgSQL. Je tam cache. Ukládá vše do mezipaměti. Dopadne to skvěle. Tohle jsme viděli. Máme 100500 XNUMX žádostí. Nefunguje. Nesouhlasíme s manuální přeměnou požadavků na procedury. Ne ne.
Máme druhou možnost – vezměte si to a uřízněte si to sami. Otevřeme prameny a začneme řezat. Viděli jsme a viděli. Ukázalo se, že to není tak obtížné.

To se objevilo v srpnu 2015. Nyní existuje modernější verze. A všechno je skvělé. Funguje to tak dobře, že v aplikaci nic neměníme. A dokonce jsme přestali uvažovat směrem k PgSQL, to znamená, že nám to stačilo ke snížení všech režijních nákladů téměř na nulu.
Proto jsou serverem připravené příkazy aktivovány při 5. provedení, aby se zabránilo plýtvání pamětí v databázi při každém jednorázovém požadavku.

Můžete se zeptat – kde jsou čísla? co dostáváš? A zde nebudu uvádět čísla, protože každý požadavek má své vlastní.
Naše dotazy byly takové, že jsme strávili asi 20 milisekund analýzou dotazů OLTP. Na provedení bylo 0,5 milisekundy, na analýzu 20 milisekund. Požadavek – 10 kiB textu, 170 řádků plánu. Toto je požadavek OLTP. Vyžaduje 1, 5, 10 řádků, někdy i více.
Ale vůbec jsme nechtěli ztrácet 20 milisekund. Snížili jsme to na 0. Všechno je skvělé.
Co si odtud můžete odnést? Pokud máte Javu, tak si vezmete moderní verzi ovladače a radujete se.
Pokud mluvíte jiným jazykem, přemýšlejte – možná to také potřebujete? Protože z pohledu finálního jazyka, například pokud máte PL 8 nebo máte LibPQ, tak vám není zřejmé, že trávíte čas ne exekucí, parsováním, a to stojí za kontrolu. Jak? Vše je zdarma.
Až na to, že jsou tam chyby a některé zvláštnosti. A právě o nich budeme mluvit. Většina z toho bude o průmyslové archeologii, o tom, co jsme našli, na co jsme narazili.

Pokud je požadavek generován dynamicky. Stalo se to. Někdo slepí řetězce dohromady a výsledkem je SQL dotaz.
Proč je špatný? Je to špatné, protože pokaždé skončíme s jiným řetězcem.
A hashCode tohoto odlišného řetězce je třeba znovu přečíst. To je opravdu úloha CPU – najít dlouhý text požadavku v dokonce existujícím hashe není tak snadné. Proto je závěr jednoduchý – negenerovat požadavky. Uložte je do jedné proměnné. A radovat se.

Další problém. Datové typy jsou důležité. Existují ORM, které říkají, že nezáleží na tom, jaký druh NULL existuje, ať je nějaký. Pokud Int, pak říkáme setInt. A když NULL, tak ať je to vždy VARCHAR. A jaký je nakonec rozdíl v tom, co je tam NULL? Databáze sama vše pochopí. A tento obrázek nefunguje.
V praxi je to databázi úplně jedno. Pokud jste poprvé řekli, že se jedná o číslo, a podruhé, že se jedná o VARCHAR, pak není možné znovu použít příkazy připravené serverem. A v tomto případě musíme naše prohlášení znovu vytvořit.

Pokud provádíte stejný dotaz, ujistěte se, že datové typy ve vašem sloupci nejsou zmatené. Musíte si dát pozor na NULL. Toto je běžná chyba, kterou jsme měli poté, co jsme začali používat PreparedStatements

Dobře, zapnuto. Možná vzali řidiče. A produktivita klesla. Věci se zhoršily.
Jak se to stane? Je to chyba nebo funkce? Bohužel nebylo možné pochopit, zda se jedná o chybu nebo funkci. Existuje však velmi jednoduchý scénář pro reprodukci tohoto problému. Úplně nečekaně nás přepadla. A spočívá v samplování doslova z jednoho stolu. Takových požadavků jsme měli samozřejmě víc. Zpravidla zahrnovaly dva nebo tři stoly, ale existuje i takový scénář přehrávání. Vezměte libovolnou verzi ze své databáze a zahrajte si ji.

Jde o to, že máme dva sloupce, z nichž každý je indexovaný. V jednom sloupci NULL je milion řádků. A druhý sloupec obsahuje pouze 20 řádků. Když provádíme bez vázaných proměnných, vše funguje dobře.
Pokud začneme provádět s vázanými proměnnými, tj. spustíme "?" nebo „1 dolar“ za naši žádost, co nakonec získáme?
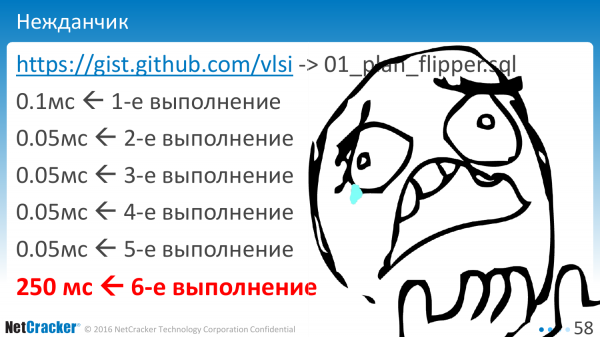
První provedení je podle očekávání. Druhý je o něco rychlejší. Něco bylo uloženo do mezipaměti. Třetí, čtvrtý, pátý. Pak prásk - a něco takového. A nejhorší je, že se to stane při šesté popravě. Kdo věděl, že je nutné provést přesně šest poprav, abychom pochopili, jaký je skutečný plán poprav?

kdo je vinen? Co se stalo? Databáze obsahuje optimalizaci. A zdá se, že je optimalizován pro obecný případ. A proto, počínaje určitým bodem, přechází na obecný plán, který se bohužel může ukázat jako jiný. Může se ukázat, že je to stejné, nebo to může být jiné. A existuje nějaká prahová hodnota, která k tomuto chování vede.
co s tím můžete dělat? Zde je samozřejmě obtížnější cokoliv předpokládat. Existuje jednoduché řešení, které používáme. To je +0, OFFSET 0. Určitě taková řešení znáte. Prostě to vezmeme a k požadavku přidáme „+0“ a vše je v pořádku. Ukážu ti to později.
A je tu ještě jedna možnost – prohlédněte si plány pečlivěji. Vývojář musí nejen napsat požadavek, ale také šestkrát říci „vysvětlit analýzu“. Pokud je to 6, nebude to fungovat.
A je tu třetí možnost – napsat dopis pgsql-hackerům. Psal jsem, nicméně zatím není jasné, zda se jedná o chybu nebo funkci.

Zatímco přemýšlíme, zda se jedná o chybu nebo funkci, pojďme to opravit. Vezměme náš požadavek a přidejte „+0“. Vše je v pořádku. Dva symboly a nemusíte ani přemýšlet o tom, jak to je nebo co to je. Velmi jednoduché. Jednoduše jsme databázi zakázali používat index v tomto sloupci. Nemáme index ve sloupci „+0“ a to je vše, databáze nepoužívá index, vše je v pořádku.

Toto je pravidlo 6 vysvětlit. Nyní v aktuálních verzích to musíte udělat 6krát, pokud máte vázané proměnné. Pokud nemáte vázané proměnné, děláme to my. A právě tato žádost nakonec selže. Není to nic složitého.
Zdálo by se, kolik je možné? Chyba sem, chyba tam. Ve skutečnosti je chyba všude.

Pojďme se na to blíže podívat. Například máme dvě schémata. Schéma A s tabulkou S a schéma B s tabulkou S. Dotaz – výběr dat z tabulky. Co budeme mít v tomto případě? Budeme mít chybu. Budeme mít vše výše uvedené. Platí pravidlo – chyba je všude, budeme mít vše výše uvedené.

Nyní otázka zní: "Proč?" Zdá se, že existuje dokumentace, že pokud máme schéma, pak existuje proměnná „search_path“, která nám říká, kde máme tabulku hledat. Zdálo by se, že existuje proměnná.
Co je za problém? Problém je v tom, že příkazy připravené na serveru nemají podezření, že search_path může někdo změnit. Tato hodnota zůstává pro databázi jakoby konstantní. A některé části nemusí získat nový význam.

To samozřejmě závisí na verzi, kterou testujete. Záleží na tom, jak moc se vaše tabulky liší. A verze 9.1 jednoduše provede staré dotazy. Nové verze mohou chybu zachytit a říct vám, že máte chybu.

Jak to léčit? Existuje jednoduchý recept – nedělejte to. Když je aplikace spuštěna, není třeba měnit cestu hledání. Pokud změníte, je lepší vytvořit nové připojení.
Můžete diskutovat, tedy otevírat, diskutovat, přidávat. Možná se nám podaří přesvědčit vývojáře databáze, že když někdo změní hodnotu, databáze by o tom měla klientovi říct: „Podívejte, vaše hodnota byla aktualizována zde. Možná budete muset resetovat výpisy a znovu je vytvořit? Nyní se databáze chová skrytě a nijak nehlásí, že by se výpisy někde uvnitř změnily.
A znovu zdůrazním – to je něco, co není pro Javu typické. Totéž uvidíme v PL/pgSQL jedna ku jedné. Ale bude se tam reprodukovat.

Zkusme ještě výběr dat. Vybíráme a vybíráme. Máme tabulku s milionem řádků. Každý řádek je kilobajt. Přibližně gigabajt dat. A máme pracovní paměť v Java stroji 128 megabajtů.
Jak je doporučeno ve všech knihách, používáme zpracování datových proudů. To znamená, že otevřeme resultSet a postupně čteme data odtud. Bude to fungovat? Vypadne z paměti? Budete si trochu číst? Důvěřujme databázi, věřme Postgresu. Nevěříme tomu. Vypadneme z paměti? Kdo zažil OutOfMemory? Komu se to potom podařilo opravit? Někdo to dokázal opravit.
Pokud máte milion řádků, nemůžete jen vybírat. Je vyžadován OFFSET/LIMIT. Kdo je pro tuto možnost? A kdo je pro hraní s autoCommit?
Zde se jako obvykle ukazuje jako správná nejneočekávanější možnost. A pokud náhle vypnete autoCommit, pomůže to. proč tomu tak je? Věda o tom neví.

Ve výchozím nastavení však všichni klienti připojující se k databázi Postgres načítají všechna data. PgJDBC v tomto ohledu není výjimkou, vybere všechny řádky.
Existuje variace na téma FetchSize, tj. na úrovni samostatného prohlášení můžete říci, že zde prosím vyberte data o 10, 50. To však nefunguje, dokud nevypnete autoCommit. Vypnutý autoCommit - začne fungovat.
Ale procházet kód a nastavovat setFetchSize všude je nepohodlné. Proto jsme provedli nastavení, které bude říkat výchozí hodnotu pro celé připojení.
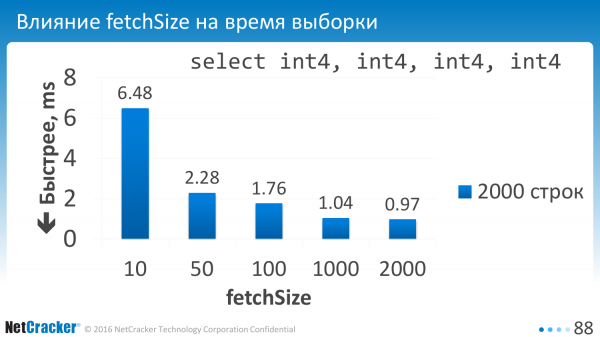
To jsme řekli. Parametr byl nakonfigurován. A co jsme dostali? Pokud vybereme malé částky, pokud například vybereme 10 řádků najednou, pak máme velmi velké režijní náklady. Proto by tato hodnota měla být nastavena na zhruba sto.
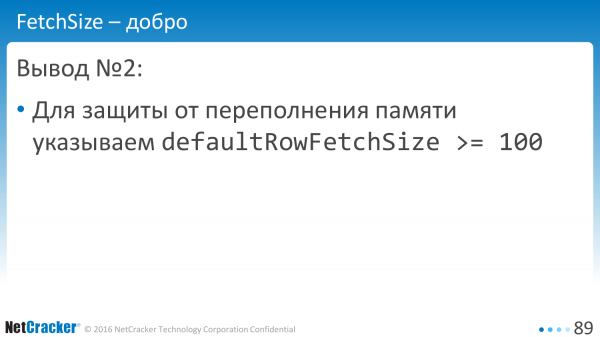
V ideálním případě se samozřejmě musíte ještě naučit, jak to omezit v bajtech, ale recept je tento: nastavte defaultRowFetchSize na více než sto a buďte šťastní.

Pojďme k vkládání dat. Vkládání je jednodušší, jsou různé možnosti. Například INSERT, VALUES. To je dobrá volba. Můžete říci „INSERT SELECT“. V praxi je to totéž. Rozdíl ve výkonu není žádný.
Knihy říkají, že musíte provést příkaz Batch, knihy říkají, že můžete provádět složitější příkazy s několika závorkami. A Postgres má skvělou funkci – můžete dělat COPY, tedy rychleji.

Pokud to změříte, můžete opět učinit zajímavé objevy. Jak chceme, aby to fungovalo? Nechceme analyzovat a neprovádět zbytečné příkazy.
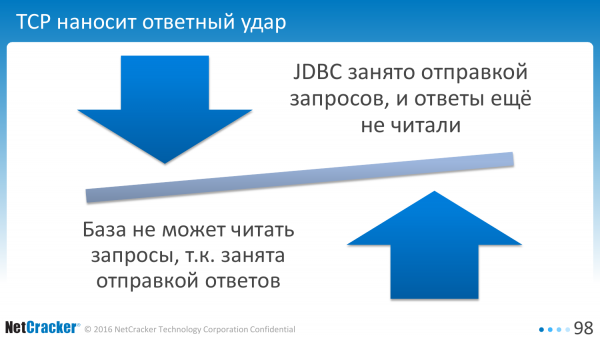
V praxi nám to TCP neumožňuje. Pokud je klient zaneprázdněn odesíláním požadavku, pak databáze nečte požadavky při pokusech o zaslání odpovědi. Konečným výsledkem je, že klient čeká, až databáze přečte požadavek, a databáze čeká, až si klient přečte odpověď.

A proto je klient nucen periodicky posílat synchronizační paket. Další síťové interakce, další ztráta času.
 A čím víc jich přidáváme, tím je to horší. Řidič je dost pesimistický a přidává je poměrně často, cca jednou za 200 řádků, záleží na velikosti řádků atp.
A čím víc jich přidáváme, tím je to horší. Řidič je dost pesimistický a přidává je poměrně často, cca jednou za 200 řádků, záleží na velikosti řádků atp.
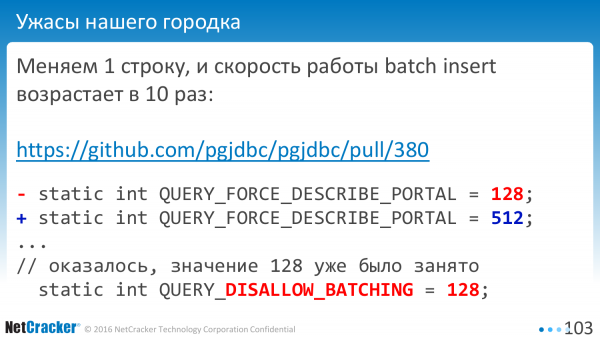
Stává se, že opravíte jen jeden řádek a vše se 10x zrychlí. Stalo se to. Proč? Jak už to tak bývá, konstanta jako tato už byla někde použita. A hodnota „128“ znamenala nepoužívat dávkování.

Je dobře, že to nebylo součástí oficiální verze. Objeveno před začátkem vydání. Všechny významy, které uvádím, vycházejí z moderních verzí.

Pojďme to zkusit. Měříme InsertBatch jednoduše. InsertBatch měříme vícekrát, tedy totéž, ale existuje mnoho hodnot. Ošemetný tah. Ne každý to dokáže, ale je to tak jednoduchý krok, mnohem jednodušší než COPY.

Můžete udělat COPY.

A můžete to udělat na strukturách. Deklarujte výchozí typ uživatele, předejte pole a INSERT přímo do tabulky.
Pokud otevřete odkaz: pgjdbc/ubenchmsrk/InsertBatch.java, pak je tento kód na GitHubu. Můžete konkrétně vidět, jaké požadavky se tam generují. To je jedno.
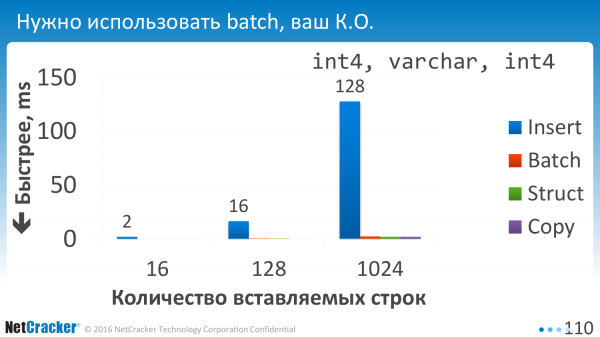
Spustili jsme. A první věc, kterou jsme si uvědomili, bylo, že nepoužívat dávku je prostě nemožné. Všechny možnosti dávkování jsou nulové, tj. doba provádění je prakticky nulová ve srovnání s jednorázovým prováděním.
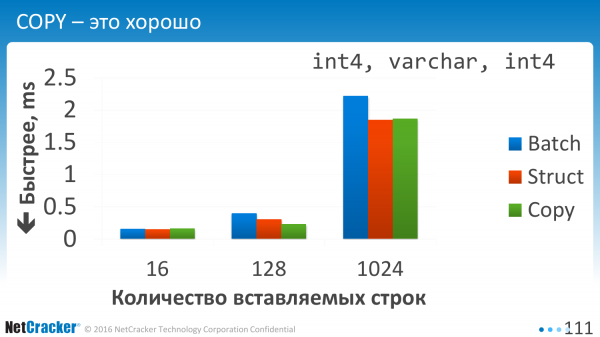
Vkládáme data. Je to velmi jednoduchý stůl. Tři sloupce. A co tady vidíme? Vidíme, že všechny tři tyto možnosti jsou zhruba srovnatelné. A COPY je samozřejmě lepší.
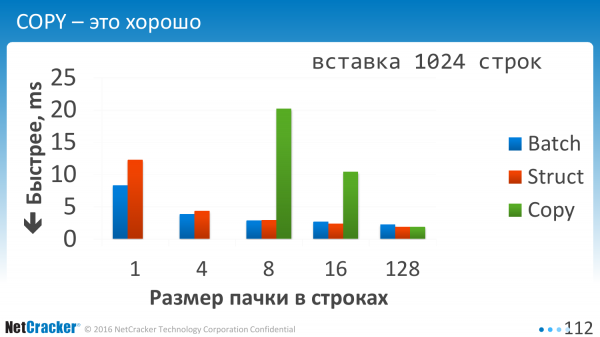
To je, když vkládáme kousky. Když jsme řekli, že jedna hodnota VALUES, dvě hodnoty VALUES, tři hodnoty VALUES, nebo jsme uvedli 10 z nich oddělených čárkou. Tohle je teď jen horizontální. 1, 2, 4, 128. Je vidět, že díky modře nakreslené Batch Insert se cítí mnohem lépe. To znamená, že když vkládáte jeden po druhém nebo dokonce když vkládáte čtyři najednou, bude to dvakrát lepší, jednoduše proto, že jsme do HODNOT nacpali trochu víc. Méně operací EXECUTE.
Použití COPY na malých objemech je extrémně neslibné. Na ty první dva jsem ani nekreslil. Jdou do nebe, tedy tato zelená čísla pro COPY.
COPY byste měli použít, když máte alespoň sto řádků dat. Režie otevření tohoto připojení je velká. A abych byl upřímný, nekopal jsem tímto směrem. Optimalizoval jsem Batch, ale ne COPY.
co budeme dělat dál? Zkusili jsme to. Chápeme, že musíme použít buď struktury, nebo chytrou bacth, která kombinuje několik významů.

Co byste si z dnešní reportáže měli odnést?
- PreparedStatement je pro nás vším. To dává hodně pro produktivitu. V masti to způsobí velký propadák.
- A musíte provést EXPLAIN ANALYZE 6krát.
- A potřebujeme zředit OFFSET 0 a triky jako +0, abychom opravili zbývající procento našich problematických dotazů.
Zdroj: www.habr.com
