

Mnozí, kteří již používají - naše služba vizualizace plánu PostgreSQL si možná neuvědomuje jednu ze svých superschopností - otočit těžko čitelný kus protokolu serveru ...
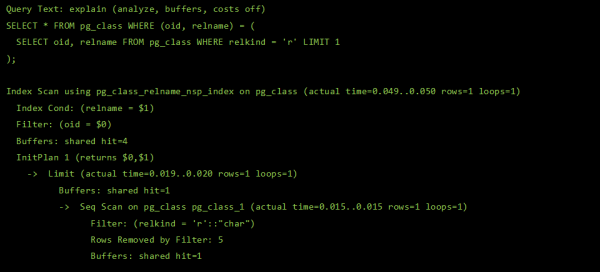
… do krásně navrženého dotazu s kontextovými radami pro relevantní uzly plánu:
V tomto přepisu druhé části jeho Řeknu vám, jak se nám to podařilo.
Přepis první části, věnované typickým problémům s výkonem dotazů a jejich řešení, naleznete v článku .

Nejprve si uděláme kolorování - a plán už nebudeme vybarvovat, ten už máme namalovaný, už je krásný a srozumitelný, ale prosba.
Zdálo se nám, že požadavek vytažený z klády s nenaformátovaným „listem“ vypadá velmi ošklivě a tudíž nepohodlně.

Zvláště když vývojáři „slepí“ tělo požadavku v kódu (toto je samozřejmě anti-vzor, ale stává se to) na jeden řádek. Hrůza!
Pojďme to nakreslit nějak krásněji.
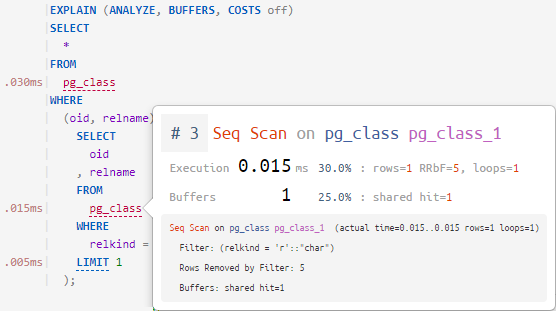
A pokud to umíme krásně nakreslit, tedy rozebrat a sestavit tělo požadavku zpět, pak můžeme ke každému předmětu tohoto požadavku „připojit“ nápovědu – co se stalo v odpovídajícím bodě plánu.
Strom syntaxe dotazu
Chcete-li to provést, musí být dotaz nejprve analyzován.
Protože, máme , pak jsme pro to udělali modul, můžete . Ve skutečnosti se jedná o rozšířené „vazby“ na vnitřnosti samotného analyzátoru PostgreSQL. To znamená, že gramatika je jednoduše binárně zkompilována a vazby k ní jsou vytvořeny NodeJS. Jako základ jsme vzali moduly jiných lidí - zde není žádné velké tajemství.
Do naší funkce přivedeme tělo vstupního požadavku - na výstupu dostaneme syntaktický strom syntaxe ve formě JSON objektu.

Nyní můžeme projít tento strom v opačném směru a sestavit požadavek s požadovanými odsazeními, barvami a formátováním. Ne, toto nelze konfigurovat, ale mysleli jsme si, že by to bylo pohodlné.

Mapovací dotaz a plánovací uzly
Nyní se podívejme, jak můžeme zkombinovat plán, který jsme analyzovali v prvním kroku, a dotaz, který jsme analyzovali ve druhém.
Vezměme si jednoduchý příklad – máme požadavek, který vytvoří CTE a přečte jej dvakrát. Vytvoří takový plán.

CTE
Pokud se na to podíváte pozorně, tak před 12. verzí (nebo od ní počínaje klíčovým slovem MATERIALIZED) formace .

A to znamená, pokud někde v požadavku vidíme generování CTE a někde v plánu uzel CTE, pak tyto uzly jedinečně „bojují“ mezi sebou, můžeme je okamžitě kombinovat.
Úkol "s hvězdičkou"Poznámka: CTE lze vnořit.

Tam jsou velmi špatně vnořené, a dokonce i stejné jméno. Například můžete uvnitř CTE A dělat CTE Xa na stejné úrovni uvnitř CTE B udělat znovu CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...Při srovnávání to musíte pochopit. Je velmi těžké to pochopit „očima“ – dokonce vidět plán, dokonce vidět tělo žádosti. Pokud je vaše generace CTE složitá, vnořená, požadavky jsou velké, pak je zcela nevědomá.
UNION
Pokud máme v požadavku klíčové slovo UNION [ALL] (operátor spojení dvou vzorků), pak odpovídá v plánu buď uzlu Append, nebo nějaké Recursive Union.
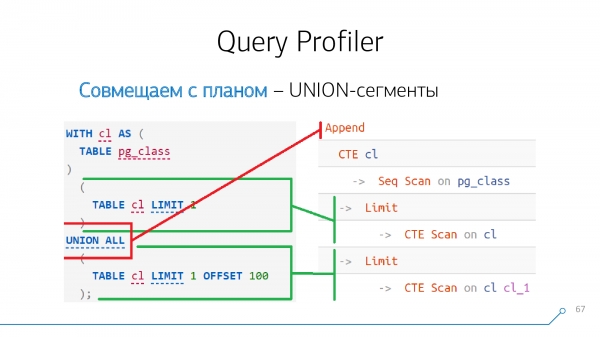
To, co je "nahoře" UNION - to je první dítě našeho uzlu, které je "zdola" - druhé. Pokud přes UNION tak jsme "slepili" několik bloků najednou Append-node bude mít stále jen jedno, ale nebude mít dvě děti, ale mnoho - v pořadí, jak jdou, resp.
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
Úkol "s hvězdičkou": uvnitř generování rekurzivního načtení (WITH RECURSIVE) může být také více než jeden UNION. Ale pouze úplně poslední blok po posledním je vždy rekurzivní UNION. Vše výše uvedené je jedno, ale jiné UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2, тут кончается генерация стартового состояния рекурсии
UNION ALL
(...) -- #3, только этот блок рекурсивный и может содержать обращение к T
)
...
Takové příklady je také potřeba umět „vložit“. V tomto příkladu to vidíme UNION-segmenty v naší žádosti byly 3 kusy. V souladu s tím jeden UNION odpovídá Append-uzel a další - Recursive Union.

Čtení a zápis dat
Vše, rozložené, nyní víme, která část požadavku odpovídá které části plánu. A v těchto dílech snadno a přirozeně najdeme ty předměty, které jsou „čitelné“.
Z hlediska dotazu nevíme, zda se jedná o tabulku nebo CTE, ale jsou označeny stejným uzlem RangeVar. A v „čitelném“ plánu je to také poměrně omezená sada uzlů:
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
Známe strukturu plánu a požadavku, známe korespondenci bloků, známe názvy objektů – jednoznačné srovnání.

Znovu úkol "s hvězdičkou". Vezmeme požadavek, provedeme ho, nemáme žádné aliasy – jen ho čteme dvakrát z jednoho CTE.

Podívejme se na plán - v čem je problém? Proč jsme měli alias? Neobjednali jsme to. Odkud bere takové „číslo“?
PostgreSQL to přidává sám. Jen to musíš pochopit jen takový alias pro nás to pro účely srovnání s plánem nedává žádný smysl, je to zde prostě doplněno. Nevšímejme si ho.
Druhý úkol "s hvězdičkou": pokud čteme z rozdělené tabulky, pak dostaneme uzel Append nebo Merge Append, která se bude skládat z velkého počtu „dětí“, a z nichž každé bude nějaké Scan'om ze sekce tabulky: Seq Scan, Bitmap Heap Scan nebo Index Scan. Ale v každém případě tyto „děti“ nebudou složité dotazy – takto lze tyto uzly odlišit od Append na UNION.

Takovým uzlům také rozumíme, sbíráme je „na jednu hromadu“ a říkáme: „vše, co čtete z megatable, je přímo tady a dole na stromě".
"Jednoduché" uzly pro získávání dat

Values Scan v plánu odpovídá VALUES v žádosti.
Result je žádost bez FROM jako je SELECT 1. Nebo když máte falešný výraz WHERE-block (pak se objeví atribut One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- или 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan "Mapyatsya" na SRF stejného jména.
U vnořených dotazů je ale vše složitější – bohužel ne vždy se promění v InitPlan/SubPlan. Někdy se promění v ... Join nebo ... Anti Join, zvláště když píšete něco jako WHERE NOT EXISTS .... A to není vždy možné kombinovat - v textu plánu nejsou žádné operátory odpovídající uzlům plánu.
Znovu úkol "s hvězdičkou": některé VALUES v žádosti. V tomto případě a v plánu získáte několik uzlů Values Scan.

"Číselné" přípony pomohou je od sebe odlišit - přidávají se přesně v pořadí, ve kterém odpovídající VALUES-blokuje v průběhu požadavku shora dolů.
Zpracování dat
Zdá se, že vše v naší žádosti bylo vyřešeno - pouze Limit.

Ale vše je zde jednoduché - takové uzly jako Limit, Sort, Aggregate, WindowAgg, Unique „Namapují“ jeden k jednomu na odpovídající operátory v požadavku, pokud tam jsou. Neexistují žádné "hvězdy" a žádné potíže.

REGISTRACE
Potíže nastávají, když chceme kombinovat JOIN mezi sebou. To není vždy možné, ale je to možné.

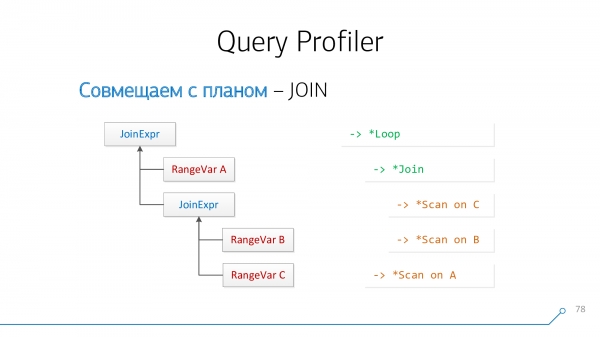
Z pohledu analyzátoru dotazů máme uzel JoinExpr, která má rovnou dvě děti – levé a pravé. To je to, co je „nad“ vaším JOINem a co je napsáno „pod“ v dotazu.
A z hlediska plánu jde o dva potomky některých * Loop/* Join-uzel. Nested Loop, Hash Anti Join... je něco takového.
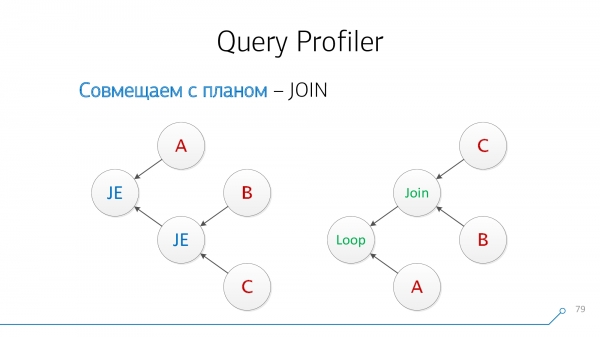
Použijme jednoduchou logiku: pokud máme tabulky A a B, které se v plánu vzájemně „spojují“, pak by se v dotazu mohly nacházet buď A-JOIN-BNebo B-JOIN-A. Zkusme takto kombinovat, zkusme kombinovat opačně a tak dále, dokud takové dvojice nedojdou.
Vezměte si náš strom syntaxe, vezměte náš plán, podívejte se na ně... nevypadá to tak!
Překreslíme to do podoby grafů – ach, něco se už stalo podobnému!
Všimněme si, že máme uzly, které mají současně děti B a C – je nám jedno, v jakém pořadí. Spojme je a otočme obrázek uzlu.
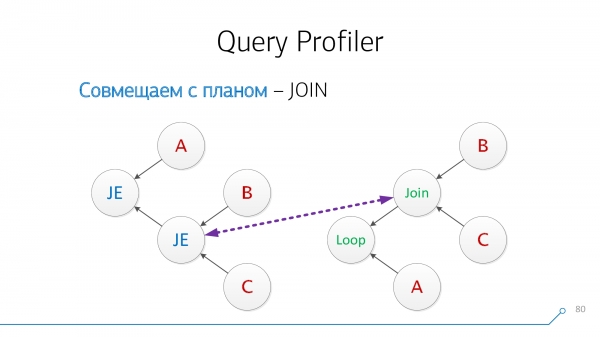
Podívejme se znovu. Nyní máme uzly s dětmi A a páry (B + C) - s nimi kompatibilní.
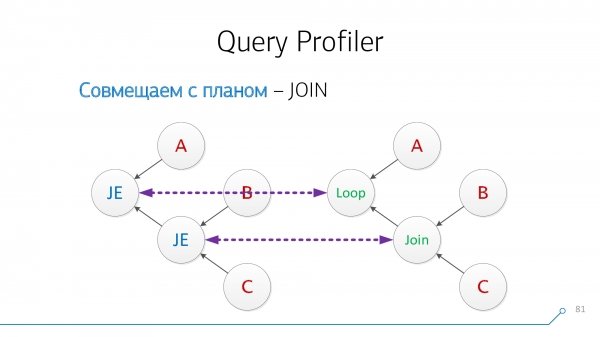
Skvělý! Ukazuje se, že jsme tito dva JOIN z dotazu s uzly plánu byly úspěšně zkombinovány.
Bohužel, tento problém není vždy vyřešen.
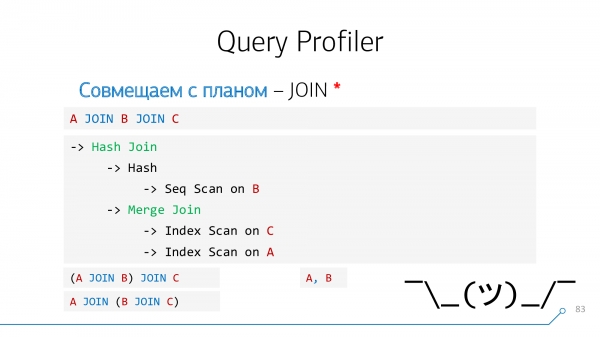
Například pokud žádost A JOIN B JOIN C, a v plánu byly propojeny především „extrémní“ uzly A a C. Ale v dotazu takový operátor není, nemáme co zvýrazňovat, není k čemu připojit nápovědu. To samé s "čárkou", když píšete A, B.
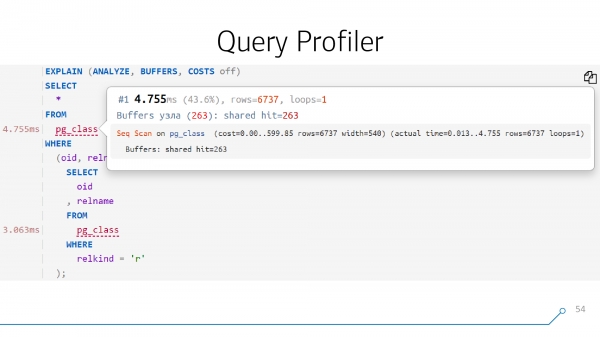
Ale ve většině případů se téměř všem uzlům podaří včas „rozvázat“ a získat takové profilování vlevo – doslova, jako v Google Chrome, když analyzujete kód JavaScript. Můžete vidět, jak dlouho byl každý řádek a každý příkaz "proveden".

A abychom vám toto všechno usnadnili, vytvořili jsme úložiště , kde si můžete uložit a poté najít své plány spolu s přidruženými dotazy nebo sdílet s někým odkaz.
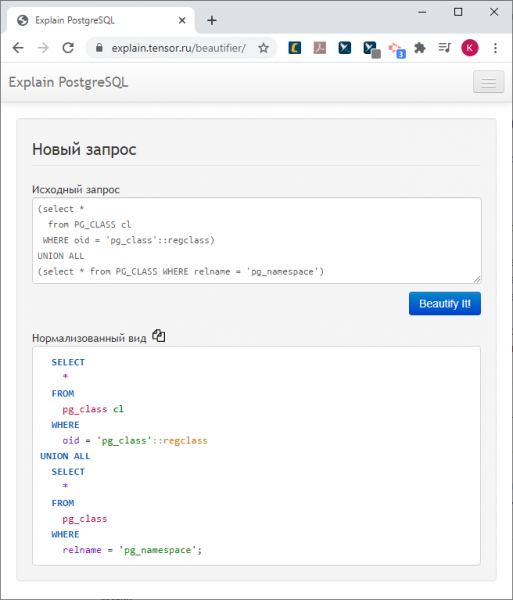
Potřebujete-li jen nečitelný požadavek uvést do adekvátní podoby, použijte .
Zdroj: www.habr.com
