


Abyste plně zvládli Kubernetes, musíte znát různé způsoby škálování clusterových prostředků: Toto je jeden z hlavních cílů Kubernetes. Připravili jsme podrobný přehled mechanismů horizontálního a vertikálního automatického škálování a změny velikosti clusteru spolu s doporučeními, jak je efektivně používat.
Článek přeloženo týmem, který implementoval automatické škálování v .
Proč je důležité zvážit škálování
— nástroj pro správu zdrojů a orchestraci. Samozřejmě je fajn si pohrát s zajímavými funkcemi pro nasazení, monitorování a správu podů (pod je skupina kontejnerů spuštěných v reakci na požadavek).
Měli byste se však zamyslet i nad následujícími otázkami:
- Jak škálovat moduly a aplikace?
- Jak udržovat kontejnery v dobrém provozním stavu a efektivně?
- Jak reagovat na neustálé změny v kódu a uživatelské zátěži?
Konfigurace clusterů Kubernetes pro vyvážení zdrojů a výkonu může být složitá a vyžaduje odbornou znalost vnitřního fungování Kubernetes. Zátěž vaší aplikace nebo služeb může kolísat v průběhu dne nebo dokonce hodiny, takže vyvažování je nejlepší vnímat jako průběžný proces.
Úrovně automatického škálování Kubernetes
Efektivní automatické škálování vyžaduje koordinaci mezi dvěma úrovněmi:
- Vrstva podu zahrnuje horizontální (Horizontal Pod Autoscaler, HPA) a vertikální (Vertical Pod Autoscaler, VPA) automatické škálování. Tím se škálují dostupné zdroje pro vaše kontejnery.
- Úroveň clusteru je spravována automatickým škálováním clusteru (CA), které zvyšuje nebo snižuje počet uzlů v clusteru.
Modul horizontálního automatického škálování výkonu (HPA)
Jak název napovídá, HPA škáluje počet replik podů. Většina DevOps systémů používá jako spouštěče pro změnu počtu replik zatížení CPU a paměti. Systém je však možné škálovat na základě... , jejich nebo .
Diagram fungování HPA na vysoké úrovni:
- HPA průběžně kontroluje hodnoty metrik zadané během instalace ve výchozím intervalu 30 sekund.
- HPA se pokusí zvýšit počet modulů, pokud je dosaženo zadané prahové hodnoty.
- HPA aktualizuje počet replik uvnitř řadiče nasazení/replikace.
- Řadič nasazení/replikace poté nasadí všechny potřebné další moduly.
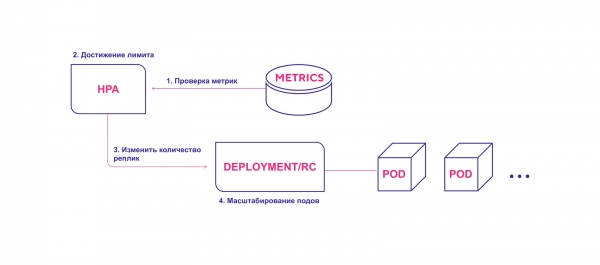
HPA spustí proces nasazení modulů, když je dosaženo prahové hodnoty metriky.
Při použití HPA zvažte následující:
- Výchozí interval kontroly HPA je 30 sekund. Nastavuje se příznakem horizontální-pod-autoscaler-synchronizační-perioda ve správci řadičů.
- Výchozí relativní chyba je 10 %.
- Po posledním zvýšení počtu modulů HPA čeká tři minuty na stabilizaci metrik. Tento interval je nastaven příznakem. horizontální-pod-autoscaler-upscale-delay.
- Po posledním snížení počtu modulů čeká HPA pět minut na stabilizaci. Tento interval je nastaven příznakem horizontální-pod-autoscaler-downscale-delay.
- HPA funguje nejlépe s objekty nasazení, nikoli s řadiči replikace. Horizontální automatické škálování je nekompatibilní s postupnými aktualizacemi, které přímo manipulují s řadiči replikace. Během nasazení závisí počet replik přímo na objektech nasazení.
Automatické škálování vertikálního podu
Vertikální automatické škálování (VPA) alokuje více (nebo méně) CPU nebo paměti stávajícím podům. Funguje jak pro stavové, tak pro bezstavové pody, ale je primárně určeno pro stavové služby. VPA však můžete použít i pro bezstavové pody, pokud potřebujete automaticky upravit počáteční alokaci zdrojů.
VPA také reaguje na události OOM (nedostatek paměti). Změna času CPU a paměti vyžaduje restart podu. Během restartů se VPA drží alokačního rozpočtu () aby byl zajištěn minimální požadovaný počet modulů.
Pro každý pod můžete nastavit minimální a maximální alokaci zdrojů. Například můžete omezit maximální alokaci paměti na 8 GB. To je užitečné, pokud aktuální uzly nejsou schopny alokovat více než 8 GB paměti na kontejner. Podrobné specifikace a operační mechanismus jsou popsány v .
VPA má navíc zajímavou funkci doporučování (VPA Recommender). Monitoruje využití zdrojů a události OOM pro všechny pody a na základě inteligentního algoritmu a historických metrik navrhuje nové alokace paměti a CPU. K dispozici je také API, které přijímá deskriptor podu a vrací navrhované alokace zdrojů.
Za zmínku stojí, že doporučovatel VPA nesleduje limity zdrojů. To může vést k tomu, že modul monopolizuje zdroje v rámci uzlů. Nejlepší je nastavit limit na úrovni jmenného prostoru, abyste se vyhnuli nadměrnému využití paměti nebo CPU.
Diagram fungování VPA na vysoké úrovni:
- VPA průběžně kontroluje hodnoty metrik zadané během instalace ve výchozím intervalu 10 sekund.
- Pokud je dosaženo zadané prahové hodnoty, VPA se pokusí změnit přidělené množství zdrojů.
- VPA aktualizuje počet zdrojů uvnitř řadiče nasazení/replikace.
- Po restartu modulů se všechny nové prostředky použijí na vytvořené instance.
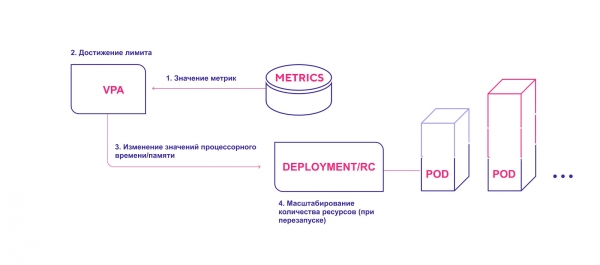
VPA přidává požadované množství zdrojů
Při používání VPA zvažte následující body:
- Škálování vyžaduje povinný restart podu. To je nezbytné, aby se zabránilo nestabilitě po provedení změn. Pro zajištění spolehlivosti se pody restartují a distribuují mezi uzly na základě nově přidělených zdrojů.
- VPA a HPA zatím nejsou vzájemně kompatibilní a nemohou fungovat na stejných podech. Pokud používáte oba mechanismy škálování ve stejném clusteru, ujistěte se, že nastavení brání jejich aktivaci na stejných objektech.
- VPA upravuje požadavky na zdroje kontejneru výhradně na základě historického a aktuálního využití. Nestanovuje žádné limity využití zdrojů. To by mohlo vést k problémům s nesprávným během aplikací a spotřebou stále většího množství zdrojů, což by vedlo k vypnutí podu ze strany Kubernetes.
- VPA je stále v raných fázích vývoje. Upozorňujeme, že systém může v blízké budoucnosti projít určitými změnami. Více si můžete přečíst o и Plány tedy zahrnují implementaci společného provozu VPA a HPA, stejně jako nasazení modulů spolu s vertikální politikou automatického škálování pro ně (například speciální označení „vyžaduje VPA“).
Automatické škálování Kubernetes Cluster
Automatické škálování clusteru (CA) upravuje počet uzlů na základě počtu čekajících podů. Systém pravidelně kontroluje čekající pody a zvětšuje velikost clusteru, pokud je potřeba více zdrojů a cluster zůstává v rámci nakonfigurovaných limitů. CA komunikuje s poskytovatelem cloudu, vyžádá si další uzly nebo uvolní nečinné. První obecně dostupná verze CA byla vydána v Kubernetes 1.8.
Diagram fungování CA na vysoké úrovni:
- CA kontroluje moduly ve stavu čekání ve výchozím intervalu 10 sekund.
- Pokud je jeden nebo více podů ve stavu čekání, protože cluster nemá dostatek dostupných zdrojů k jejich alokaci, pokusí se zřídit jeden nebo více dalších uzlů.
- Jakmile poskytovatel cloudu alokuje požadovaný uzel, připojí se ke clusteru a je připraven obsluhovat pody.
- Plánovač Kubernetes přiřadí čekající pody novému uzlu. Pokud některé pody zůstanou čekat, proces se opakuje a do clusteru se přidají nové uzly.
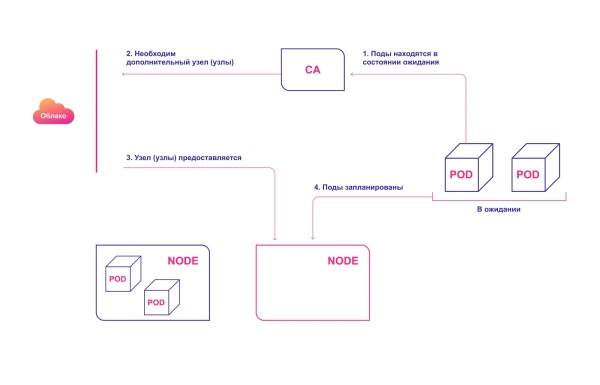
Automatická alokace uzlů clusteru v cloudu
Při používání CA zvažte následující:
- CA zajišťuje, aby všechny moduly v clusteru měly dostatek místa pro spuštění bez ohledu na zatížení CPU. Také se snaží zajistit, aby v clusteru nebyly žádné zbytečné uzly.
- CA zaregistruje potřebu škálování přibližně po 30 sekundách.
- Jakmile se uzel stane nepotřebným, CA standardně čeká 10 minut, než systém škáluje.
- Systém automatického škálování využívá koncept expandérů. Jedná se o různé strategie pro výběr skupiny uzlů, ke kterým budou přidány nové.
- Používejte tuto možnost zodpovědně cluster-autoscaler.kubernetes.io/safe-to-evict (true)Pokud nainstalujete mnoho podů nebo pokud je mnoho z nich rozptýleno po všech uzlech, výrazně ztratíte možnost horizontálního navýšení kapacity clusteru.
- použití aby se zabránilo odebrání podů, což by mohlo způsobit úplné selhání části vaší aplikace.
Jak spolu interagují systémy automatického škálování Kubernetes
Pro dokonalou harmonii by mělo být automatické škálování implementováno jak na úrovni podu (HPA/VPA), tak na úrovni clusteru. Interakce je relativně snadná:
- HPA nebo VPA aktualizuje repliky podů nebo zdroje přidělené existujícím podům.
- Pokud není dostatek uzlů pro provedení plánovaného škálování, CA si všimne, že existují pody v čekacím stavu.
- CA alokuje nové uzly.
- Moduly jsou distribuovány mezi nové uzly.
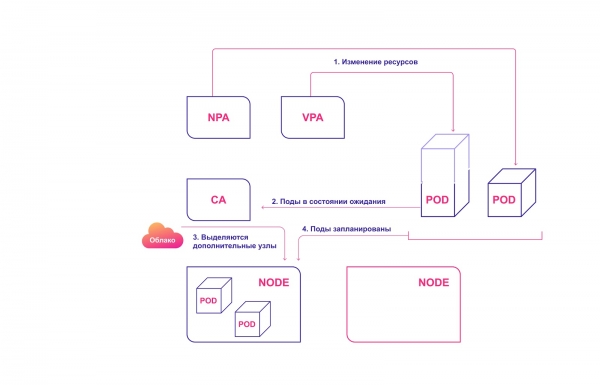
Systém pro kolaborativní škálování Kubernetes
Časté chyby v automatickém škálování Kubernetes
Existuje několik běžných problémů, kterým DevOps týmy čelí při implementaci automatického škálování.
HPA a VPA závisí na metrikách a některých historických datech. Pokud není přiděleno dostatek zdrojů, moduly se vypnou a nebudou moci generovat metriky. V tomto případě k automatickému škálování nikdy nedojde.
Samotná operace škálování je časově citlivá. Chceme, aby se pody a cluster škálovaly rychle – dříve, než si uživatelé všimnou jakýchkoli problémů nebo selhání. Proto je třeba zvážit průměrnou dobu škálování podu a clusteru.
Ideální scénář - 4 minuty:
- 30 sekund. Aktualizace cílových metrik: 30–60 sekund.
- 30 sekund. HPA kontroluje hodnoty metrik: 30 sekund.
- Méně než 2 sekundy. Pody jsou vytvořeny a přecházejí do nečinného stavu: 1 sekunda.
- Méně než 2 sekundy. CA vidí čekající moduly a vydává volání pro přípravu uzlů: 1 sekunda.
- 3 minuty. Poskytovatel cloudu alokuje uzly. K8s čeká, dokud nebudou připraveny: až 10 minut (v závislosti na několika faktorech).
Nejhorší (realističtější) scénář - 12 minut:
- 30 sekund. Aktualizace cílových metrik.
- 30 sekund. HPA kontroluje hodnoty metrik.
- Méně než 2 sekundy. Pody jsou vytvořeny a přecházejí do stavu čekání.
- Méně než 2 sekundy. CA vidí čekající moduly a odesílá volání do přípravných uzlů.
- 10 minut. Poskytovatel cloudu alokuje uzly. K8s čeká, dokud nebudou připraveny. Doba čekání závisí na několika faktorech, jako je latence poskytovatele, latence operačního systému a provoz podpůrných nástrojů.
Nezaměňujte mechanismy škálování poskytovatelů cloudu s naší certifikační autoritou (CA). Ta funguje v rámci clusteru Kubernetes, zatímco mechanismus poskytovatele cloudu funguje na základě alokace uzlů. Neví, co se děje s vašimi pody nebo aplikací. Tyto systémy fungují paralelně.
Jak spravovat škálování v Kubernetes
- Kubernetes je nástroj pro správu a orchestraci zdrojů. Operace správy zdrojů podů a clusterů jsou klíčovým milníkem v ovládnutí Kubernetes.
- Pochopte logiku škálovatelnosti podů na základě HPA a VPA.
- CA byste měli používat pouze tehdy, pokud dobře rozumíte potřebám vašich podů a kontejnerů.
- Pro optimální konfiguraci clusteru je nutné pochopit, jak různé systémy škálování spolupracují.
- Při odhadování doby škálování mějte na paměti nejhorší a nejlepší možný scénář.
Zdroj: www.habr.com
