


VictoriaMetrics je rychlý a škálovatelný DBMS pro ukládání a zpracování dat ve formě časové řady (záznam tvoří čas a množinu hodnot odpovídající této době, např. získané periodickým dotazováním na stav senzorů nebo shromažďování metrik).


Jmenuji se Pavel Kolobajev. DevOps, SRE, LeroyMerlin, všechno je jako kód – je to všechno o nás: o mně ao dalších zaměstnancích LeroyMerlin.
Existuje cloud založený na OpenStacku. Je tam malý odkaz na technický radar.

Je postaven na bázi železa Kubernetes, stejně jako na všech souvisejících službách OpenStack a protokolování.
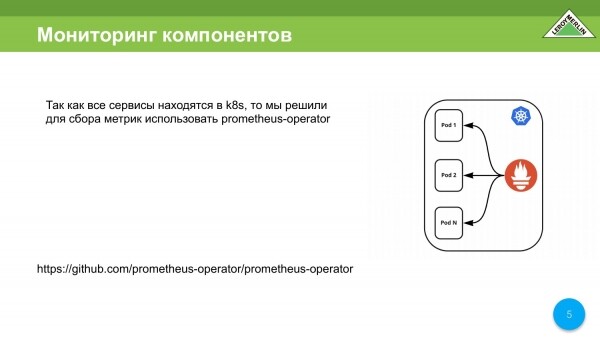
Toto je schéma, které jsme měli ve vývoji. Když jsme to všechno vyvinuli, měli jsme operátora Prometheus, který ukládal data uvnitř samotného clusteru K8s. Automaticky najde, co je potřeba vydrhnout, a dá si to, zhruba řečeno, pod nohy.

Budeme muset přesunout všechna data mimo cluster Kubernetes, protože pokud se něco stane, pak musíme pochopit co a kam.
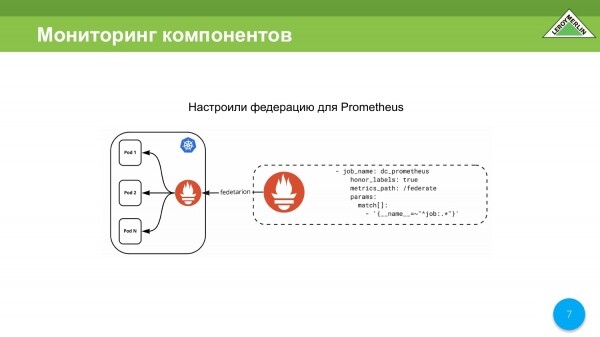
Prvním řešením je použití federace, když máme Prometheus třetí strany, když jdeme do clusteru Kubernetes prostřednictvím mechanismu federace.

Jsou zde ale drobné problémy. V našem případě problémy začaly, když jsme měli 250 000 metrik, a když tam bylo 400 000 metrik, uvědomili jsme si, že takhle nemůžeme fungovat. Zvýšili jsme scrape_timeout na 25 sekund.
Proč jsme to museli udělat? Prometheus začne počítat časový limit od začátku okamžiku vyzvednutí. Nevadí, že se data stále hrnou. Pokud se během této stanovené doby data nesloučí a relace není uzavřena přes http, má se za to, že relace selhala a data se do samotného Promethea nedostanou.
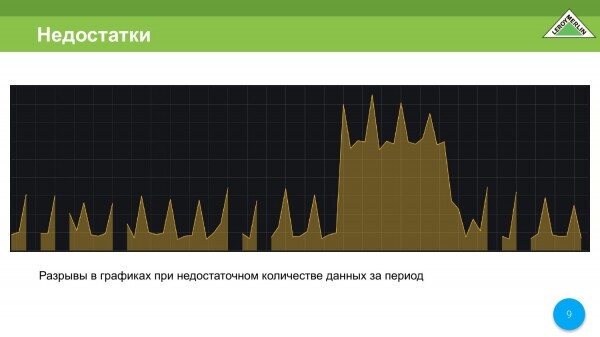
Každý zná grafy, které dostaneme, když část dat chybí. Grafika je potrhaná a nejsme s ní spokojeni.
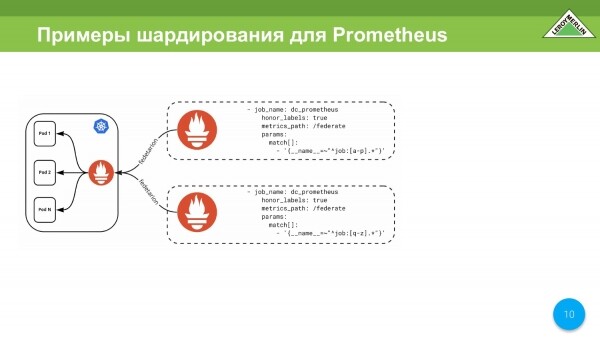
Další možností je sharding na základě dvou různých Prometheus prostřednictvím stejného federačního mechanismu.
Stačí je například vzít a rozstříhat podle jména. I to se dá využít, ale rozhodli jsme se jít dál.
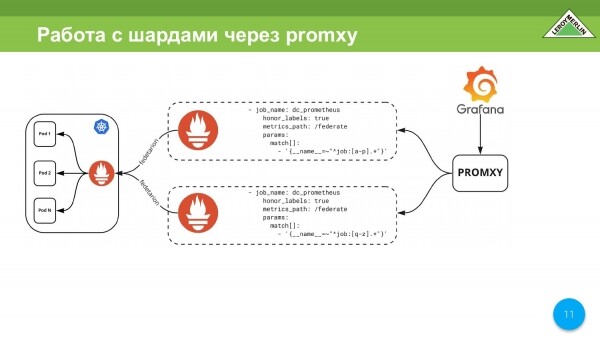
Tyto střípky teď budeme muset nějak zpracovat. Můžete si vzít promxy, který sestoupí do oblasti střepu, znásobí data. Pracuje se dvěma střepy jako jediným vstupním bodem. To lze implementovat přes promxy, ale zatím je to příliš složité.
První možnost – chceme opustit mechanismus federace, protože je velmi pomalý.
Vývojáři Prometheus výslovně říkají: "Kluci, použijte jinou TimescaleDB, protože nebudeme podporovat dlouhodobé ukládání metrik." To není jejich úkol. 
Zapisujeme si na papír, který ještě potřebujeme vyložit ven, abychom vše neukládali na jedno místo.
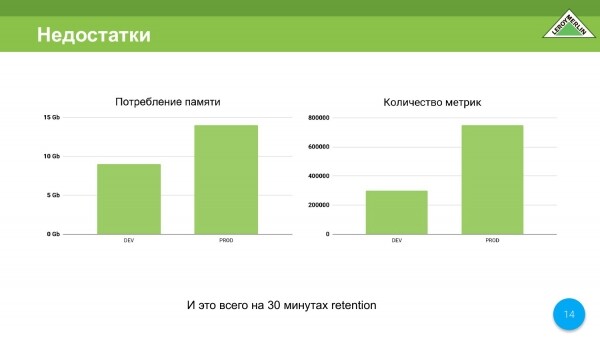
Druhou nevýhodou je spotřeba paměti. Ano, chápu, že mnozí řeknou, že v roce 2020 pár gigabajtů paměti stojí za cent, ale přesto.
Nyní máme vývojářské a prod prostředí. Ve vývoji je to asi 9 gigabajtů na 350 000 metrik. Ve výrobě je to 14 gigabajtů s malými metrikami 780 000. Zároveň máme pouze 30 minut retenčního času. Je to špatné. A teď vysvětlím proč.
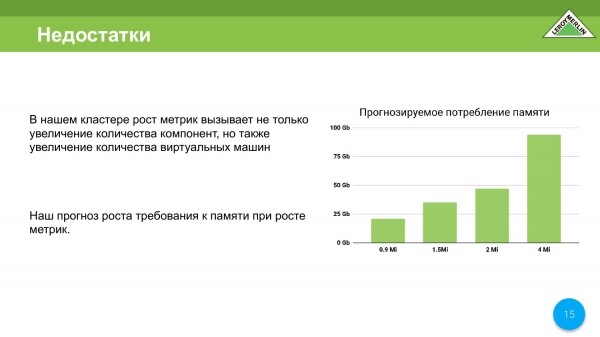
Uděláme výpočet, to znamená s jedním a půl milionem metrik, a už jsme jim blízko, ve fázi návrhu dostaneme 35-37 gigabajtů paměti. Ale již na 4 miliony metrik je již potřeba asi 90 gigabajtů paměti. To znamená, že byl vypočten podle vzorce poskytnutého vývojáři Prometheus. Podívali jsme se na korelaci a zjistili jsme, že nechceme platit pár milionů za server jen za monitoring.
Budeme nejen navyšovat počet strojů, sledujeme i samotné virtuální stroje. Čím více virtuálních strojů, tím více metrik různého druhu atd. Budeme mít zvláštní růst našeho clusteru z hlediska metrik.
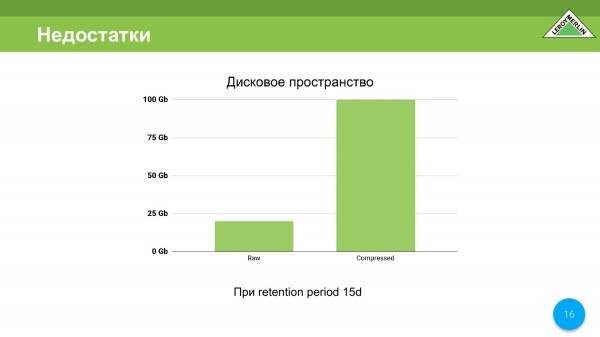
S místem na disku zde není vše tak smutné, ale rád bych to vylepšil. Za 15 dní jsme obdrželi celkem 120 gigabajtů, z toho 100 komprimovaných dat, 20 nekomprimovaných dat, ale vždy chcete méně.

Podle toho si zapíšeme ještě jeden bod – jedná se o velkou spotřebu zdrojů, kterou chceme ještě ušetřit, protože nechceme, aby náš monitorovací cluster žral více zdrojů než náš cluster, který spravuje OpenStack.

Prometheus má ještě jednu nevýhodu, kterou jsme si sami identifikovali, je to alespoň nějaké omezení paměti. S Prometheem je tady všechno mnohem horší, protože takové zvraty vůbec nemá. Použití limitu dockeru také není možné. Pokud náhle vaše RAF klesla a je zde 20-30 gigabajtů, bude trvat velmi dlouho, než se zvýší.

I proto pro nás není Prometheus vhodný, tedy nemůžeme omezit spotřebu paměti.
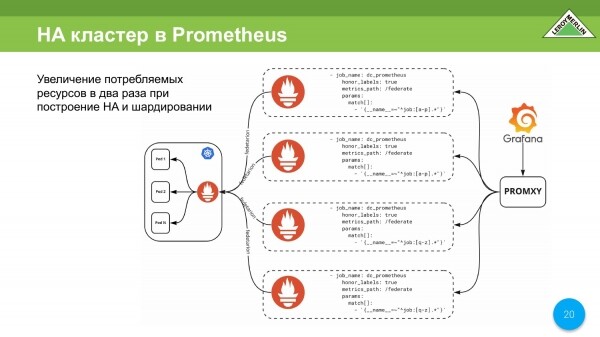
Bylo by možné vymyslet takové schéma. Toto schéma potřebujeme, abychom mohli organizovat HA cluster. Chceme, aby naše metriky byly dostupné kdykoli a kdekoli, i když dojde k selhání serveru, který tyto metriky ukládá. A proto musíme takové schéma vytvořit.
Toto schéma říká, že budeme mít duplikaci střepů, a tedy duplikaci nákladů na spotřebované zdroje. Dá se téměř horizontálně škálovat, ale přesto bude spotřeba zdrojů pekelná.

Nevýhody v pořadí, ve formě, v jaké jsme si je vypsali:
- Vyžaduje nahrání metrik ven.
- Vysoká spotřeba zdrojů.
- Spotřebu paměti nelze omezit.
- Složitá a na zdroje náročná implementace HA.

Za sebe jsme se rozhodli, že se od Promethea jako úložiště vzdalujeme.
Identifikovali jsme pro sebe další požadavky, které potřebujeme. Tento:
- Toto je podpora promql, protože pro Prometheus už toho bylo napsáno hodně: dotazy, upozornění.
- A pak tu máme Grafanu, která je už napsaná stejným způsobem pod Prometheem jako backend. Nechci přepisovat dashboardy.
- Chceme vybudovat normální HA architekturu.
- Chceme snížit spotřebu jakýchkoli zdrojů.
- Je tu ještě jedna malá nuance. Pro sběr metrik nemůžeme používat různé druhy cloudových systémů. Zatím nevíme, co do těchto metrik poletí. A protože tam může létat cokoli, musíme se omezit na místní umístění.

Výběr byl malý. Shromáždili jsme vše, s čím jsme měli zkušenosti. Podívali jsme se na stránku Prometheus v sekci integrace, přečetli hromadu článků, podívali se na to, co je obecně dostupné. A pro sebe jsme zvolili VictoriaMetrics jako náhradu za Prometheus.
Proč? Protože:
- Schopný promql.
- Existuje modulární architektura.
- Nevyžaduje žádné změny v Grafaně.
- A co je nejdůležitější, pravděpodobně budeme poskytovat úložiště metrik v rámci naší společnosti jako službu, takže se předem díváme na různé druhy omezení, aby uživatelé mohli využívat všechny zdroje clusteru nějakým omezeným způsobem, protože existuje šance že bude multinájemní.
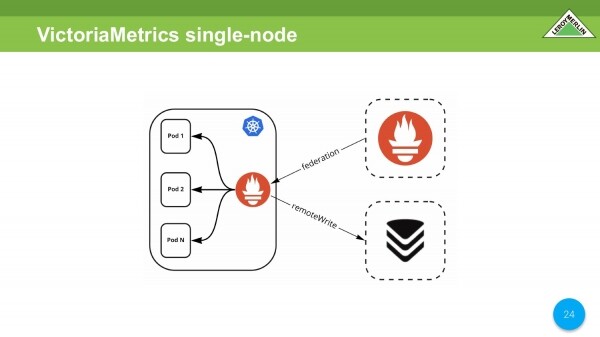
Provádíme první srovnání. Vezmeme stejného Promethea uvnitř shluku, externí Prometheus k němu jde. Přidáme pomocí remoteWrite VictoriaMetrics.
Okamžitě udělám rezervaci, že jsme zde zachytili mírné zvýšení spotřeby CPU od společnosti VictoriaMetrics. Wiki VictoriaMetrics říká, které parametry jsou nejvhodnější. Zkontrolovali jsme je. Velmi dobře snížily spotřebu CPU.
V našem případě se spotřeba paměti Prometheus, který je umístěn v clusteru Kubernetes, výrazně nezvýšila.
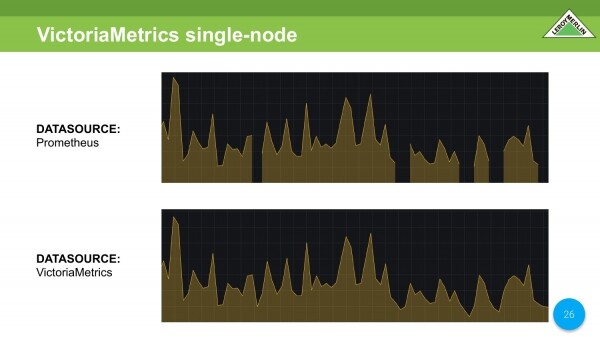
Porovnáváme dva zdroje dat stejných dat. V Prometheovi vidíme všechna stejná chybějící data. Ve VictoriaMetrics je vše dobré.

Výsledky testů s místem na disku. My v Prometheus jsme získali celkem 120 gigabajtů. Ve společnosti VictoriaMetrics již dostáváme 4 gigabajty za den. Je tam trochu jiný mechanismus, než jaký jste zvyklí vídat v Prometheovi. To znamená, že data jsou již docela dobře komprimována na den, na půl hodiny. Jsou již dobře sklizeny za den, za půl hodiny, i když později budou data sloučena. Díky tomu jsme ušetřili místo na disku.
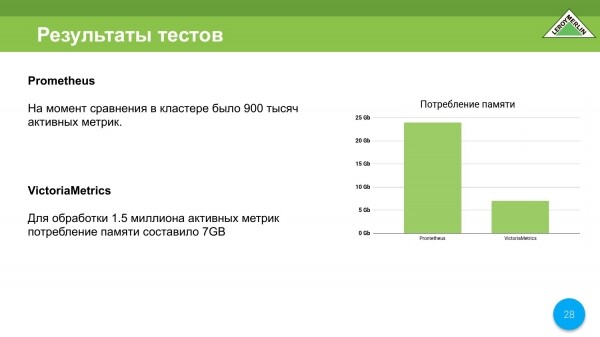
Šetříme také na spotřebě paměťových prostředků. V době testů jsme měli Prometheus nasazený na virtuálním stroji – 8 jader, 24 gigabajtů. Prometheus jí skoro všechno. Padl na OOM Killer. Přitom se do něj nasypalo jen 900 000 aktivních metrik. To je asi 25 000–27 000 metrik za sekundu.
VictoriaMetrics běžela na dvoujádrovém virtuálním počítači s 8 gigabajty paměti RAM. Podařilo se nám přimět VictoriaMetrics, aby dobře fungovala, vyladěním některých věcí na 8GB počítači. Ve výsledku jsme se drželi do 7 gigabajtů. Zároveň jsme dostali rychlost doručování obsahu, tedy metriky, ještě vyšší než u Promethea.
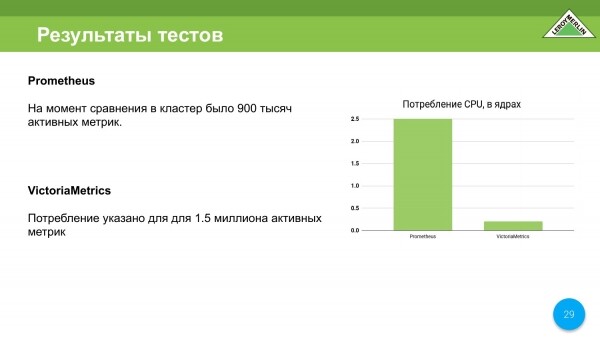
CPU je mnohem lepší než Prometheus. Zde Prometheus spotřebuje 2,5 jádra a VictoriaMetrics pouze 0,25 jádra. Na začátku - 0,5 jádra. Když se spojí, dosáhne jednoho jádra, ale to je extrémně, extrémně vzácné.
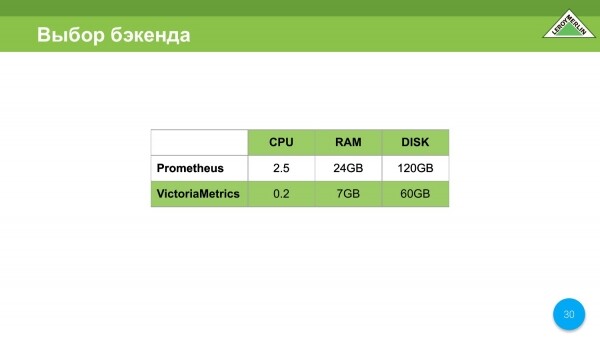
V našem případě padla volba z pochopitelných důvodů na VictoriaMetrics, chtěli jsme ušetřit a ušetřili.

Hned na začátku škrtneme dva body – to je vyložení metrik a velká spotřeba zdrojů. A na nás zbývá rozhodnout dva body, které jsme si ještě nechali pro sebe.

Zde udělám rezervaci hned, VictoriaMetrics považujeme za úložiště metrik. Protože ale s největší pravděpodobností poskytneme VictoriaMetrics jako úložiště pro všechny Leroy, musíme omezit ty, kteří budou tento cluster používat, aby nám ho nedali.
Existuje skvělý parametr, který vám umožňuje omezit časem, množstvím dat a dobou provádění.
A existuje také vynikající možnost, která vám umožní omezit spotřebu paměti, takže můžeme najít samotnou rovnováhu, která nám umožní dosáhnout normální rychlosti a přiměřené spotřeby zdrojů.

Mínus ještě jeden bod, to znamená, že škrtneme bod - nemůžete omezit spotřebu paměti.
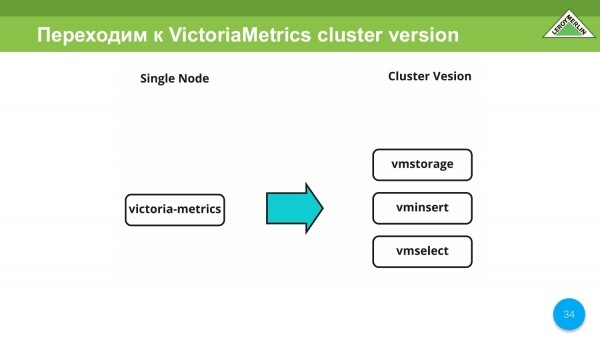
V prvních iteracích jsme testovali VictoriaMetrics Single Node. Dále přejdeme k verzi VictoriaMetrics Cluster.
Zde máme volnou ruku na téma oddělení různých služeb ve VictoriaMetrics v závislosti na tom, na čem se budou točit a jaké zdroje budou spotřebovávat. Jedná se o velmi flexibilní a pohodlné řešení. Sami jsme to použili.
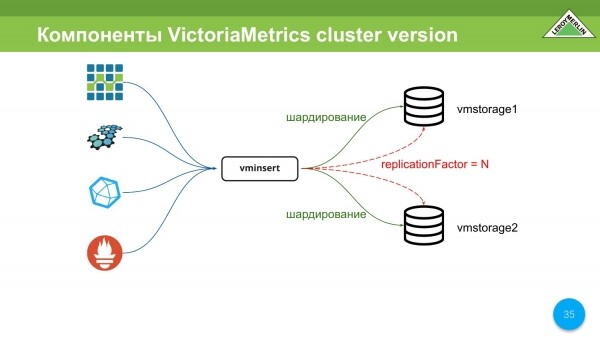
Hlavní součásti VictoriaMetrics Cluster Version jsou vmstsorage. Může tam být N číslo. V našem případě jsou 2 z nich.
A je tam vminsert. Toto je proxy server, který nám umožňuje: zařídit sharding mezi všemi úložišti, o kterých jsme mu řekli, a umožňuje další repliku, tj. budete mít jak sharding, tak repliku.
Vminsert podporuje protokoly OpenTSDB, Graphite, InfluxDB a remoteWrite od společnosti Prometheus.
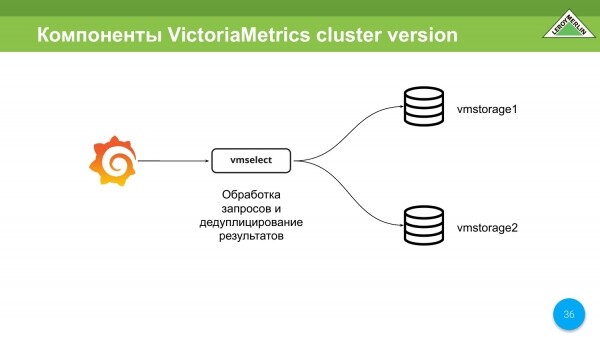
Existuje také vmselect. Jeho hlavním úkolem je přejít do vmstorage, získat z nich data, tato data odstranit a dát je klientovi.
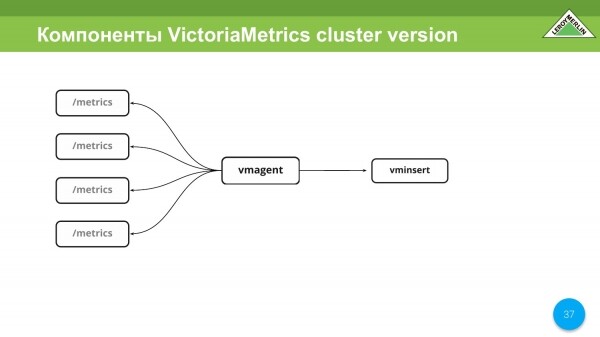
Existuje úžasná věc jako vmagent. Máme ji moc rádi. Umožňuje vám konfigurovat stejně jako Prometheus a přesto dělat vše jako Prometheus. To znamená, že shromažďuje metriky od různých subjektů a služeb a odesílá je do vminsert. Pak vše záleží na vás.
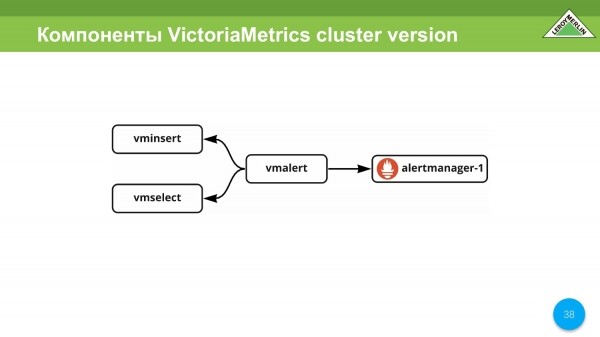
Další skvělou službou je vmalert, který umožňuje používat VictoriaMetrics jako backend, přijímat zpracovaná data z vminsert a odesílat zpracovaná data do vmselect. Zpracovává samotná upozornění a také pravidla. V případě výstrah dostáváme výstrahu prostřednictvím správce výstrah.
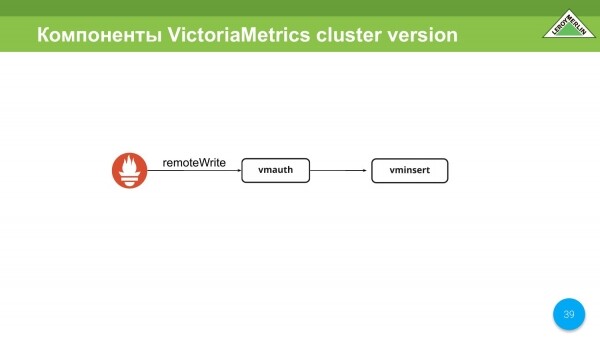
Existuje komponenta wmauth. Pravděpodobně jej využijeme a možná ne (ještě jsme se k tomu nerozhodli) jako autorizační systém pro multitenancy verze clusterů. Podporuje remoteWrite pro Prometheus a umí autorizovat na základě adresy URL, respektive její druhé části, kam můžete nebo nemůžete psát.
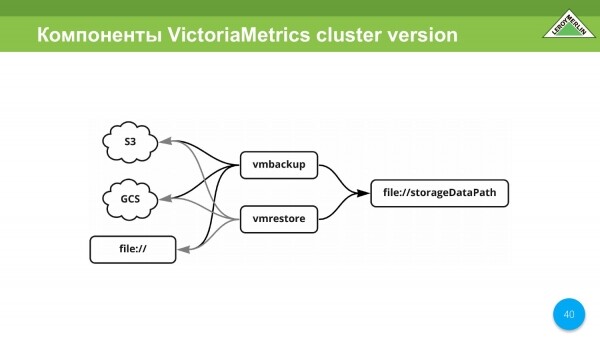
Existuje také vmbackup, vmrestore. Jedná se ve skutečnosti o obnovu a zálohování všech dat. Schopný S3, GCS, soubor.
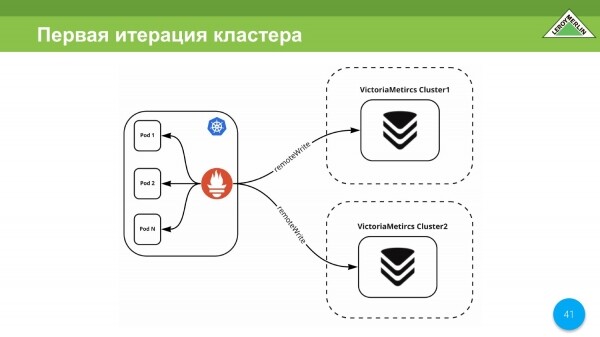
První iterace našeho clusteru byla provedena během karantény. V té době neexistovala žádná replika, takže naše iterace sestávala ze dvou různých a nezávislých clusterů, do kterých jsme přijímali data přes remoteWrite.
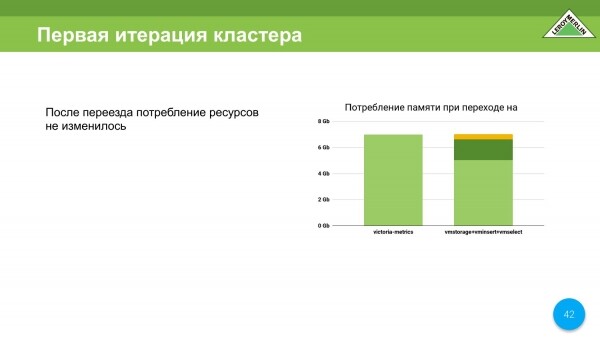
Zde udělám výhradu, že když jsme přešli z VictoriaMetrics Single Node na VictoriaMetrics Cluster Version, zůstali jsme stále ve stejných spotřebovaných zdrojích, tedy hlavním je paměť. Přibližně tímto způsobem byla distribuována naše data, tedy spotřeba zdrojů.
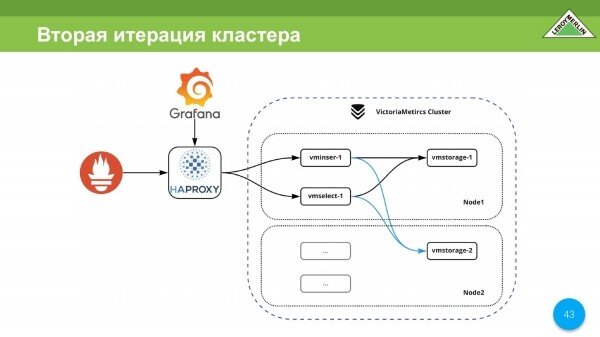
Zde již byla přidána replika. To vše jsme spojili do jednoho poměrně velkého shluku. Všechna data jsou jak sdílená, tak replikovaná.
Celý cluster má N vstupních bodů, tj. Prometheus může přidávat data přes HAPROXY. Zde je náš vstupní bod. A přes tento vstupní bod se můžete přihlásit pomocí Grafany.
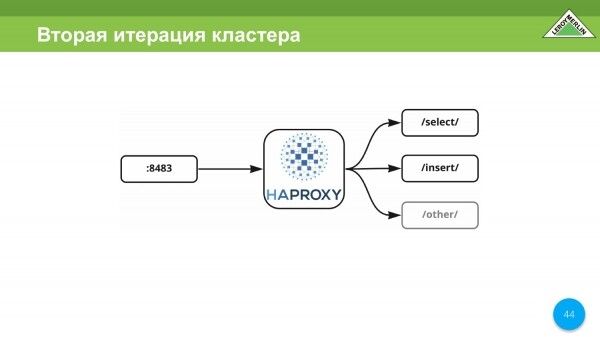
V našem případě je HAPROXY jediný port, který proxy vybírají, vkládají a další služby do tohoto clusteru. V našem případě nebylo možné vytvořit jednu adresu, museli jsme udělat několik vstupních bodů, protože samotné virtuální stroje, na kterých běží cluster VictoriaMetrics, se nacházejí v různých zónách stejného poskytovatele cloudu, tedy ne uvnitř našeho cloudu. , ale venku.
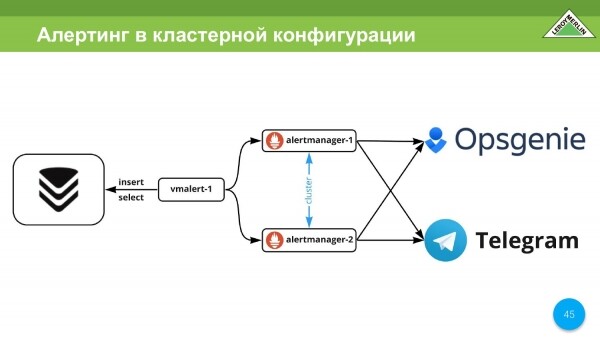
Máme výstrahu. Používáme to. Používáme alertmanager od Prometheus. Jako kanál pro doručování výstrah používáme Opsgenie a Telegram. V Telegramu sypou z dev, možná něco z prod, ale spíš jako něco statistického, co potřebují inženýři. A Opsgenie je kritický. Jsou to hovory, správa incidentů.
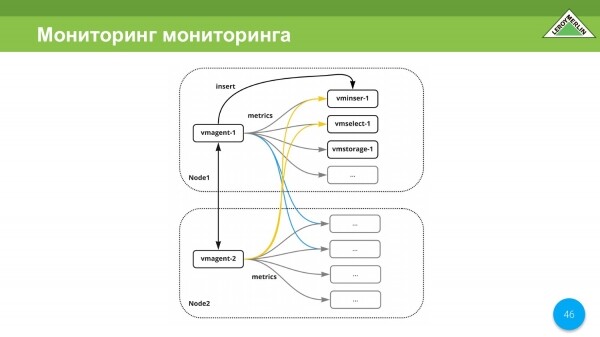
Odvěká otázka: „Kdo monitoruje?“. Monitoring v našem případě sleduje samotné monitorování, protože na každém uzlu používáme vmagent. A protože naše uzly jsou umístěny v různých datových centrech stejného poskytovatele, každé datové centrum má svůj vlastní kanál, jsou nezávislé, a i když dojde k rozdělení mozku, stále budeme dostávat upozornění. Ano, bude jich více, ale je lepší dostávat více upozornění než žádné.

Náš výčet končíme implementací HA.

A dále bych rád zaznamenal zkušenost s komunikací s komunitou VictoriaMetrics. Ukázalo se to velmi pozitivně. Kluci reagují. Snaží se proniknout do každého případu, který se nabízí.
Udělal jsem problémy na GitHubu. Byly vyřešeny velmi rychle. Existuje několik dalších problémů, které nejsou zcela uzavřeny, ale již z kódu vidím, že v tomto směru probíhá práce.
Hlavní bolestí během iterací pro mě bylo to, že když jsem uzel uřízl, pak vminsert prvních 30 sekund nemohl pochopit, že neexistuje žádný backend. Nyní je již rozhodnuto. A doslova za sekundu nebo dvě jsou data převzata ze všech zbývajících uzlů a požadavek přestane čekat na chybějící uzel.

V určitém okamžiku jsme od společnosti VictoriaMetrics chtěli být operátorem společnosti VictoriaMetrics. Čekali jsme na něj. Nyní aktivně budujeme vazbu na operátora VictoriaMetrics, aby přijal všechna pravidla pro předvýpočet atd. Prometheus, protože poměrně aktivně používáme pravidla, která přicházejí s operátorem Prometheus.
Existují návrhy na zlepšení implementace clusteru. Nastínil jsem je výše.
A také opravdu chci downsampling. V našem případě je downsampling potřeba výhradně pro prohlížení trendů. Zhruba řečeno, jedna metrika mi během dne stačí. Tyto trendy jsou potřeba na rok, tři, pět, deset let. A stačí jedna metrická hodnota.
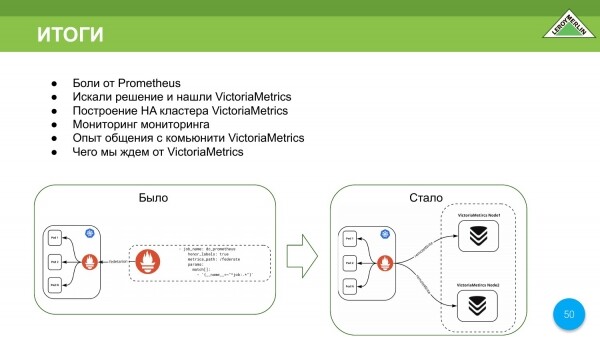
- Při používání Promethea jsme poznali bolest, stejně jako někteří naši kolegové.
- Vybrali jsme si pro sebe VictoriaMetrics.
- Škáluje docela dobře jak vertikálně, tak horizontálně.
- Můžeme distribuovat různé komponenty do různého počtu uzlů v clusteru, omezit je z hlediska paměti, přidat paměť atd.
Doma budeme používat VictoriaMetrics, protože se nám moc líbil. Zde je to, co se stalo a co se stalo.

Pár qr kódů pro chat VictoriaMetrics, moje kontakty, technický radar LeroyMerlin.
Zdroj: www.habr.com
