


Rydym yn dod ar draws cronfa ddata Apache Cassandra yn rheolaidd a'r angen i'w gweithredu o fewn seilwaith sy'n seiliedig ar Kubernetes. Yn y deunydd hwn, byddwn yn rhannu ein gweledigaeth o'r camau angenrheidiol, y meini prawf a'r atebion presennol (gan gynnwys trosolwg o weithredwyr) ar gyfer mudo Cassandra i K8s.
“Gall pwy bynnag all reoli menyw reoli’r wladwriaeth hefyd”
Pwy yw Cassandra? Mae'n system storio ddosbarthedig sydd wedi'i chynllunio i reoli symiau mawr o ddata tra'n sicrhau argaeledd uchel heb un pwynt methiant. Go brin bod angen cyflwyniad hir ar y prosiect, felly dim ond prif nodweddion Cassandra fydd yn berthnasol yng nghyd-destun erthygl benodol y byddaf yn eu rhoi:
- Mae Cassandra wedi'i ysgrifennu yn Java.
- Mae topoleg Cassandra yn cynnwys sawl lefel:
- Node - un enghraifft o Cassandra;
- Mae Rack yn grŵp o achosion Cassandra, wedi'u huno gan rai nodweddion, sydd wedi'u lleoli yn yr un ganolfan ddata;
- Datacenter - casgliad o bob grŵp o achosion Cassandra wedi'u lleoli mewn un ganolfan ddata;
- Mae clwstwr yn gasgliad o'r holl ganolfannau data.
- Mae Cassandra yn defnyddio cyfeiriad IP i adnabod nod.
- Er mwyn cyflymu gweithrediadau ysgrifennu a darllen, mae Cassandra yn storio peth o'r data yn RAM.
Nawr - i'r potensial gwirioneddol symud i Kubernetes.
Rhestr wirio ar gyfer trosglwyddo
Wrth siarad am ymfudiad Cassandra i Kubernetes, rydym yn gobeithio gyda'r symud y bydd yn dod yn fwy cyfleus i'w reoli. Beth fydd ei angen ar gyfer hyn, beth fydd yn helpu gyda hyn?
1. storio data
Fel yr eglurwyd eisoes, mae Cassanda yn storio rhan o'r data yn RAM - yn Memtable. Ond mae rhan arall o'r data sy'n cael ei gadw ar ddisg - yn y ffurflen SSTable. Mae endid yn cael ei ychwanegu at y data hwn Log Ymrwymo — cofnodion o'r holl drafodion, sydd hefyd yn cael eu cadw ar ddisg.
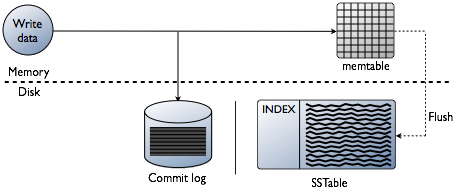
Ysgrifennwch ddiagram trafodiad yn Cassandra
Yn Kubernetes, gallwn ddefnyddio PersistentVolume i storio data. Diolch i fecanweithiau profedig, mae gweithio gyda data yn Kubernetes yn dod yn haws bob blwyddyn.
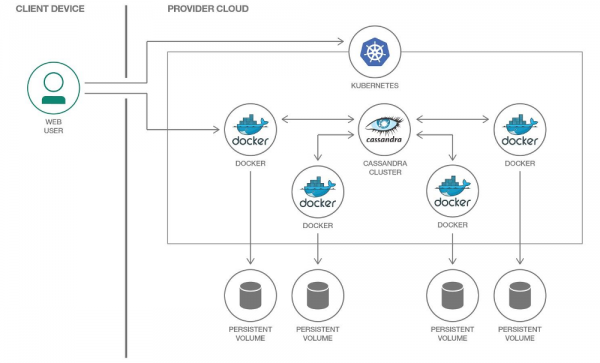
Byddwn yn dyrannu ein Cyfrol Barhaol ein hunain i bob pod Cassandra
Mae'n bwysig nodi bod Cassandra ei hun yn awgrymu atgynhyrchu data, gan gynnig mecanweithiau adeiledig ar gyfer hyn. Felly, os ydych chi'n adeiladu clwstwr Cassandra o nifer fawr o nodau, yna nid oes angen defnyddio systemau dosbarthedig fel Ceph neu GlusterFS ar gyfer storio data. Yn yr achos hwn, byddai'n rhesymegol storio data ar y ddisg gwesteiwr gan ddefnyddio neu mowntio hostPath.
Cwestiwn arall yw a ydych chi am greu amgylchedd ar wahân i ddatblygwyr ar gyfer pob cangen nodwedd. Yn yr achos hwn, y dull cywir fyddai codi un nod Cassandra a storio’r data mewn storfa ddosbarthedig, h.y. y Ceph a GlusterFS a grybwyllir fydd eich opsiynau. Yna bydd y datblygwr yn sicr na fydd yn colli data prawf hyd yn oed os collir un o nodau clwstwr Kuberntes.
2. Monitro
Y dewis sydd bron yn ddiwrthwynebiad ar gyfer gweithredu monitro yn Kubernetes yw Prometheus (siaradasom am hyn yn fanwl yn ). Sut mae Cassandra yn ei wneud ag allforwyr metrigau ar gyfer Prometheus? A beth sydd hyd yn oed yn bwysicach, gyda dangosfyrddau cyfatebol ar gyfer Grafana?
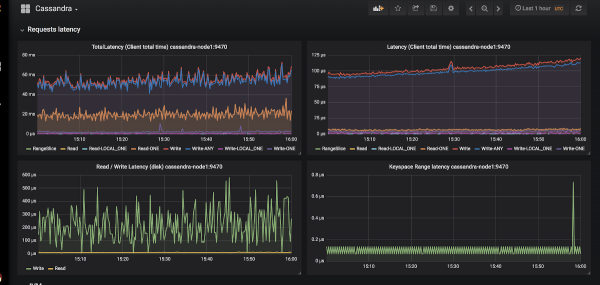
Enghraifft o ymddangosiad graffiau yn Grafana ar gyfer Cassandra
Dim ond dau allforiwr sydd: и .
Fe wnaethon ni ddewis yr un cyntaf i ni ein hunain oherwydd:
- Mae JMX Exporter yn tyfu ac yn datblygu, tra nad yw Cassandra Exporter wedi gallu cael digon o gefnogaeth gymunedol. Nid yw Cassandra Exporter yn cefnogi'r rhan fwyaf o fersiynau o Cassandra o hyd.
- Gallwch ei redeg fel javaagent trwy ychwanegu baner
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - Mae un iddo , sy'n anghydnaws ag Allforiwr Cassandra.
3. Dewis cyntefig Kubernetes
Yn ôl strwythur uchod clwstwr Cassandra, gadewch i ni geisio trosi popeth a ddisgrifir yno i derminoleg Kubernetes:
- Nôd Cassandra → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → cronfa o StatefulSets
- Clwstwr Cassandra → ???
Mae'n ymddangos bod rhywfaint o endid ychwanegol ar goll i reoli clwstwr cyfan Cassandra ar unwaith. Ond os nad oes rhywbeth yn bodoli, gallwn ei greu! Mae gan Kubernetes fecanwaith ar gyfer diffinio ei adnoddau ei hun at y diben hwn - .
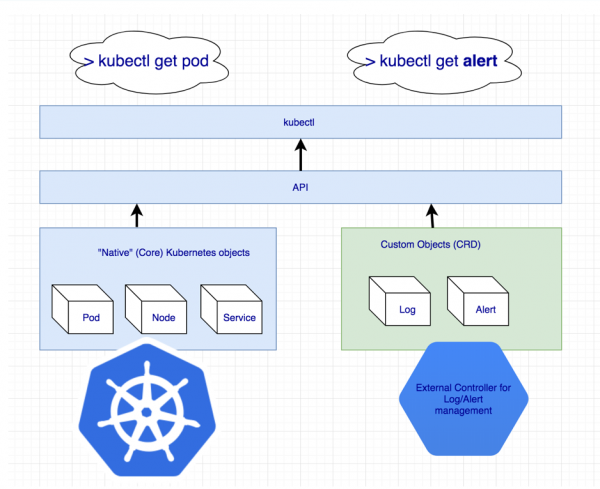
Datgan adnoddau ychwanegol ar gyfer logiau a rhybuddion
Ond nid yw Custom Resource ei hun yn golygu dim: wedi'r cyfan, mae'n gofyn y rheolydd. Efallai y bydd angen i chi ofyn am help ...
4. Adnabod codennau
Yn y paragraff uchod, fe wnaethom gytuno y bydd un nod Cassandra yn hafal i un pod yn Kubernetes. Ond bydd cyfeiriadau IP y codennau yn wahanol bob tro. Ac mae adnabod nod yn Cassandra yn seiliedig ar y cyfeiriad IP... Mae'n ymddangos y bydd clwstwr Cassandra yn ychwanegu nod newydd ar ôl tynnu pod bob tro.
Mae yna ffordd allan, ac nid un yn unig:
- Gallwn gadw cofnodion gan ddynodwyr gwesteiwr (UUIDs sy'n nodi achosion Cassandra yn unigryw) neu yn ôl cyfeiriadau IP a storio'r cyfan mewn rhai strwythurau / tablau. Mae gan y dull ddau brif anfantais:
- Y risg y bydd cyflwr hil yn digwydd os bydd dau nod yn disgyn ar unwaith. Ar ôl y cynnydd, bydd nodau Cassandra ar yr un pryd yn gofyn am gyfeiriad IP o'r bwrdd ac yn cystadlu am yr un adnodd.
- Os yw nod Cassandra wedi colli ei ddata, ni fyddwn yn gallu ei adnabod mwyach.
- Mae'r ail ateb yn ymddangos fel darn bach, ond serch hynny: gallwn greu Gwasanaeth gyda ClusterIP ar gyfer pob nod Cassandra. Problemau gyda'r gweithrediad hwn:
- Os oes llawer o nodau mewn clwstwr Cassandra, bydd yn rhaid i ni greu llawer o Wasanaethau.
- Mae'r nodwedd ClusterIP yn cael ei gweithredu trwy iptables. Gall hyn ddod yn broblem os oes gan glwstwr Cassandra lawer o nodau (1000... neu hyd yn oed 100?). Er yn gallu datrys y broblem hon.
- Y trydydd ateb yw defnyddio rhwydwaith o nodau ar gyfer nodau Cassandra yn lle rhwydwaith penodol o godennau trwy alluogi'r gosodiad
hostNetwork: true. Mae'r dull hwn yn gosod rhai cyfyngiadau:- Amnewid unedau. Mae'n angenrheidiol bod gan y nod newydd yr un cyfeiriad IP â'r un blaenorol (mewn cymylau fel AWS, GCP mae hyn bron yn amhosibl ei wneud);
- Gan ddefnyddio rhwydwaith o nodau clwstwr, rydym yn dechrau cystadlu am adnoddau rhwydwaith. Felly, bydd gosod mwy nag un pod gyda Cassandra ar un nod clwstwr yn broblemus.
5. Copïau wrth gefn
Rydym am gadw fersiwn lawn o ddata un nod Cassandra ar amserlen. Mae Kubernetes yn darparu nodwedd gyfleus gan ddefnyddio , ond dyma Cassandra ei hun yn rhoi araith yn ein holwynion.
Gadewch imi eich atgoffa bod Cassandra yn storio peth o'r data yn y cof. I wneud copi wrth gefn llawn, mae angen data o'r cof (Memtables) symud i ddisg (SSTables). Ar y pwynt hwn, mae nod Cassandra yn rhoi'r gorau i dderbyn cysylltiadau, gan gau'n llwyr o'r clwstwr.
Ar ôl hyn, caiff y copi wrth gefn ei dynnu (ciplun) a bod y cynllun yn cael ei gadw (gofod allweddol). Ac yna mae'n ymddangos nad yw copi wrth gefn yn unig yn rhoi unrhyw beth i ni: mae angen i ni arbed y dynodwyr data yr oedd nod Cassandra yn gyfrifol amdanynt - mae'r rhain yn docynnau arbennig.
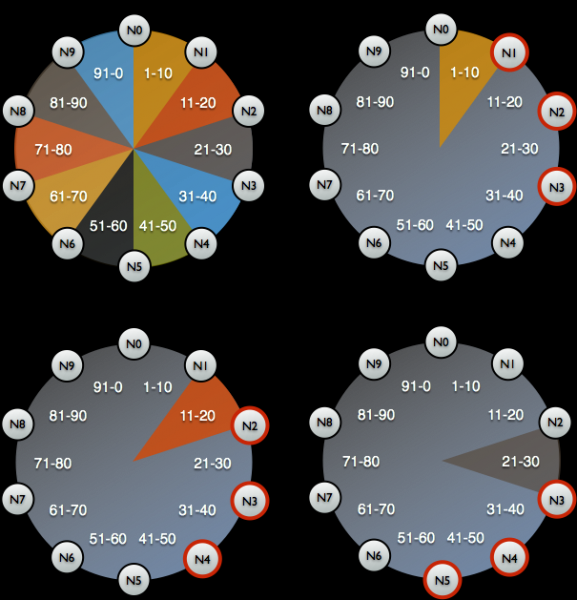
Dosbarthu tocynnau i nodi pa ddata y mae nodau Cassandra yn gyfrifol amdano
Gellir dod o hyd i sgript enghreifftiol ar gyfer cymryd copi wrth gefn Cassandra gan Google yn Kubernetes yn . Yr unig bwynt nad yw'r sgript yn ei gymryd i ystyriaeth yw ailosod data i'r nod cyn cymryd y ciplun. Hynny yw, mae'r copi wrth gefn yn cael ei berfformio nid ar gyfer y cyflwr presennol, ond ar gyfer cyflwr ychydig yn gynharach. Ond mae hyn yn helpu i beidio â thynnu'r nod allan o weithrediad, sy'n ymddangos yn rhesymegol iawn.
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Enghraifft o sgript bash ar gyfer cymryd copi wrth gefn o un nod Cassandra
Datrysiadau parod ar gyfer Cassandra yn Kubernetes
Beth sy'n cael ei ddefnyddio ar hyn o bryd i leoli Cassandra yn Kubernetes a pha un o'r rhain sy'n gweddu orau i'r gofynion penodol?
1. Atebion yn seiliedig ar siartiau StatefulSet neu Helm
Mae defnyddio swyddogaethau sylfaenol StatefulSets i redeg clwstwr Cassandra yn opsiwn da. Gan ddefnyddio'r siart Helm a thempledi Go, gallwch roi rhyngwyneb hyblyg i'r defnyddiwr ar gyfer defnyddio Cassandra.
Mae hyn fel arfer yn gweithio'n iawn... nes bod rhywbeth annisgwyl yn digwydd, fel methiant nod. Yn syml, ni all offer Kubernetes safonol ystyried yr holl nodweddion a ddisgrifir uchod. Yn ogystal, mae'r dull hwn yn gyfyngedig iawn o ran faint y gellir ei ymestyn ar gyfer defnyddiau mwy cymhleth: ailosod nodau, gwneud copi wrth gefn, adfer, monitro, ac ati.
Cynrychiolwyr:
- ;
- .
Mae'r ddau siart yr un mor dda, ond maent yn amodol ar y problemau a ddisgrifir uchod.
2. Atebion yn seiliedig ar Weithredydd Kubernetes
Mae opsiynau o'r fath yn fwy diddorol oherwydd eu bod yn darparu digon o gyfleoedd i reoli'r clwstwr. Ar gyfer dylunio gweithredwr Cassandra, fel unrhyw gronfa ddata arall, mae patrwm da yn edrych fel Sidecar <-> Rheolydd <-> CRD:
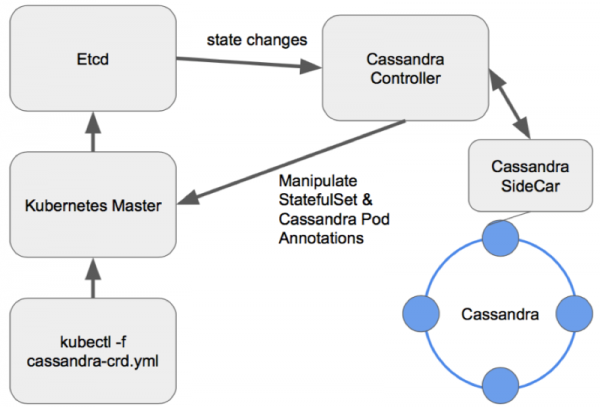
Cynllun rheoli nodau mewn gweithredwr Cassandra wedi'i ddylunio'n dda
Edrychwn ar y gweithredwyr presennol.
1. Cassandra-gweithredwr o instaclustr
- Parodrwydd: Alffa
- Trwydded: Apache 2.0
- Wedi'i weithredu yn: Java
Mae hwn yn wir yn brosiect addawol iawn sy'n datblygu'n weithredol gan gwmni sy'n cynnig gosodiadau a reolir gan Cassandra. Mae, fel y disgrifir uchod, yn defnyddio cynhwysydd car ochr sy'n derbyn gorchmynion trwy HTTP. Wedi'i ysgrifennu yn Java, weithiau nid oes ganddo ymarferoldeb mwy datblygedig y llyfrgell cleient-mynd. Hefyd, nid yw'r gweithredwr yn cefnogi gwahanol Racks ar gyfer un Datacenter.
Ond mae gan y gweithredwr fanteision fel cefnogaeth ar gyfer monitro, rheolaeth clwstwr lefel uchel gan ddefnyddio CRD, a hyd yn oed dogfennaeth ar gyfer gwneud copïau wrth gefn.
2. Llywiwr o Jetstack
- Parodrwydd: Alffa
- Trwydded: Apache 2.0
- Gweithredwyd yn: Golang
Datganiad wedi'i gynllunio i ddefnyddio DB-fel-Gwasanaeth. Ar hyn o bryd yn cefnogi dwy gronfa ddata: Elasticsearch a Cassandra. Mae ganddo atebion mor ddiddorol â rheoli mynediad cronfa ddata trwy RBAC (ar gyfer hyn mae ganddo ei lywiwr-apiserver ei hun). Prosiect diddorol a fyddai’n werth edrych arno’n fanylach, ond gwnaed yr ymrwymiad diwethaf flwyddyn a hanner yn ôl, sy’n amlwg yn lleihau ei botensial.
3. Cassandra-gweithredwr gan vgkowski
- Parodrwydd: Alffa
- Trwydded: Apache 2.0
- Gweithredwyd yn: Golang
Nid oeddent yn ei ystyried yn “ddifrifol”, gan fod yr ymrwymiad diwethaf i'r ystorfa fwy na blwyddyn yn ôl. Rhoddir y gorau i ddatblygiad gweithredwyr: y fersiwn ddiweddaraf o Kubernetes yr adroddwyd ei fod wedi'i gefnogi yw 1.9.
4. Cassandra-gweithredwr gan Rook
- Parodrwydd: Alffa
- Trwydded: Apache 2.0
- Gweithredwyd yn: Golang
Gweithredwr nad yw ei ddatblygiad yn mynd rhagddo mor gyflym ag yr hoffem. Mae ganddo strwythur CRD wedi'i feddwl yn ofalus ar gyfer rheoli clystyrau, mae'n datrys y broblem o nodi nodau gan ddefnyddio Gwasanaeth gyda ClusterIP (yr un “hac”) ... ond dyna'r cyfan am y tro. Ar hyn o bryd nid oes unrhyw fonitro na chopïau wrth gefn allan o'r bocs (gyda llaw, rydym ar gyfer monitro ). Pwynt diddorol yw y gallwch chi hefyd ddefnyddio ScyllaDB gan ddefnyddio'r gweithredwr hwn.
DS: Defnyddiwyd y gweithredwr hwn gyda mân addasiadau yn un o'n prosiectau. Ni sylwyd ar unrhyw broblemau yng ngwaith y gweithredwr yn ystod y cyfnod gweithredu cyfan (~4 mis o weithredu).
5. CassKop o Orange
- Parodrwydd: Alffa
- Trwydded: Apache 2.0
- Gweithredwyd yn: Golang
Y gweithredwr ieuengaf ar y rhestr: gwnaed yr ymrwymiad cyntaf ar Fai 23, 2019. Eisoes erbyn hyn mae ganddo yn ei arsenal nifer fawr o nodweddion o'n rhestr, y gellir dod o hyd i fwy o fanylion amdanynt yn ystorfa'r prosiect. Mae'r gweithredwr wedi'i adeiladu ar sail y gweithredwr-sdk poblogaidd. Yn cefnogi monitro allan o'r bocs. Y prif wahaniaeth gan weithredwyr eraill yw'r defnydd , wedi'i weithredu yn Python a'i ddefnyddio ar gyfer cyfathrebu rhwng nodau Cassandra.
Canfyddiadau
Mae nifer y dulliau gweithredu a'r opsiynau posibl ar gyfer cludo Cassandra i Kubernetes yn siarad drosto'i hun: mae galw am y pwnc.
Ar y cam hwn, gallwch chi roi cynnig ar unrhyw un o'r uchod ar eich perygl a'ch risg eich hun: nid oes yr un o'r datblygwyr yn gwarantu gweithrediad 100% o'u datrysiad mewn amgylchedd cynhyrchu. Ond eisoes, mae llawer o gynhyrchion yn edrych yn addawol i geisio eu defnyddio mewn meinciau datblygu.
Rwy'n meddwl yn y dyfodol y bydd y fenyw hon ar y llong yn dod yn ddefnyddiol!
PS
Darllenwch hefyd ar ein blog:
- «";
- «";
- «";
- «'.
Ffynhonnell: hab.com
