

Helo pawb! Fy enw i yw Golov Nikolay. Yn flaenorol, bûm yn gweithio yn Avito ac yn rheoli'r Platfform Data am chwe blynedd, hynny yw, bûm yn gweithio ar bob cronfa ddata: dadansoddol (Vertica, ClickHouse), ffrydio ac OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). Yn ystod y cyfnod hwn, deliais â nifer fawr o gronfeydd data - gwahanol iawn ac anarferol, a chydag achosion ansafonol o'u defnydd.
Rwy'n gweithio yn ManyChat ar hyn o bryd. Yn ei hanfod, busnes cychwynnol yw hwn - newydd, uchelgeisiol sy'n tyfu'n gyflym. A phan ymunais â'r cwmni am y tro cyntaf, cododd cwestiwn clasurol: “Beth ddylai busnes newydd ei gymryd nawr o'r farchnad DBMS a chronfa ddata?”
Yn yr erthygl hon, yn seiliedig ar fy adroddiad yn , atebaf y cwestiwn hwn. Mae fersiwn fideo o'r adroddiad ar gael yn .
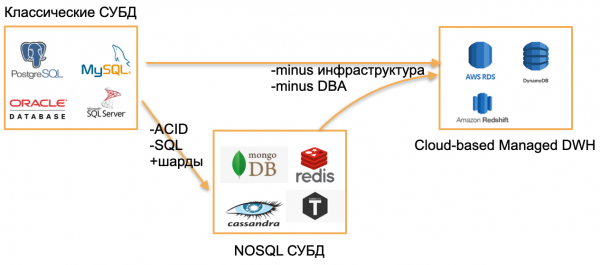
Cronfeydd data adnabyddus 2020
Mae'n 2020, edrychais o gwmpas a gweld tri math o gronfeydd data.
Math cyntaf - cronfeydd data OLTP clasurol: PostgreSQL, SQL Server, Oracle, MySQL. Fe'u hysgrifennwyd amser maith yn ôl, ond maent yn dal yn berthnasol oherwydd eu bod mor gyfarwydd i'r gymuned ddatblygwyr.
Ail fath - seiliau o "sero". Fe wnaethant geisio symud i ffwrdd o batrymau clasurol trwy gefnu ar SQL, strwythurau traddodiadol ac ACID, trwy ychwanegu darnio adeiledig a nodweddion deniadol eraill. Er enghraifft, dyma Cassandra, MongoDB, Redis neu Tarantool. Roedd yr holl atebion hyn eisiau cynnig rhywbeth sylfaenol newydd i'r farchnad ac yn meddiannu eu cilfach oherwydd eu bod yn troi allan i fod yn hynod gyfleus ar gyfer rhai tasgau. Byddaf yn dynodi'r cronfeydd data hyn gyda'r term ymbarél NOSQL.
Mae'r “seros” drosodd, daethom i arfer â chronfeydd data NOSQL, a chymerodd y byd, o'm safbwynt i, y cam nesaf - i cronfeydd data a reolir. Mae gan y cronfeydd data hyn yr un craidd â chronfeydd data OLTP clasurol neu rai newydd NoSQL. Ond nid oes angen DBA a DevOps arnynt ac maent yn rhedeg ar galedwedd wedi'i reoli yn y cymylau. I ddatblygwr, “dim ond sylfaen” yw hon sy'n gweithio yn rhywle, ond nid oes neb yn poeni sut mae'n cael ei osod ar y gweinydd, pwy ffurfweddu'r gweinydd a phwy sy'n ei ddiweddaru.
Enghreifftiau o gronfeydd data o'r fath:
- Mae AWS RDS yn ddeunydd lapio a reolir ar gyfer PostgreSQL/MySQL.
- Mae DynamoDB yn analog AWS o gronfa ddata seiliedig ar ddogfennau, yn debyg i Redis a MongoDB.
- Mae Amazon Redshift yn gronfa ddata ddadansoddol a reolir.
Yn y bôn, hen gronfeydd data yw'r rhain, ond fe'u codir mewn amgylchedd a reolir, heb fod angen gweithio gyda chaledwedd.
Nodyn. Cymerir yr enghreifftiau ar gyfer amgylchedd AWS, ond mae eu analogau hefyd yn bodoli yn Microsoft Azure, Google Cloud, neu Yandex.Cloud.
Beth sy'n newydd am hyn? Yn 2020, dim o hyn.
Cysyniad di-weinydd
Yr hyn sy'n wirioneddol newydd ar y farchnad yn 2020 yw atebion heb weinydd neu heb weinydd.
Byddaf yn ceisio esbonio beth mae hyn yn ei olygu gan ddefnyddio'r enghraifft o wasanaeth rheolaidd neu gymhwysiad ôl-wyneb.
Er mwyn defnyddio ôl-gymhwysiad rheolaidd, rydym yn prynu neu'n rhentu gweinydd, yn copïo'r cod arno, yn cyhoeddi'r pwynt terfyn y tu allan ac yn talu am rent, trydan a gwasanaethau canolfan ddata yn rheolaidd. Dyma'r cynllun safonol.
A oes unrhyw ffordd arall? Gyda gwasanaethau di-weinydd gallwch chi.
Beth yw ffocws y dull hwn: nid oes gweinydd, nid oes hyd yn oed rhentu enghraifft rithwir yn y cwmwl. I ddefnyddio'r gwasanaeth, copïwch y cod (swyddogaethau) i'r gadwrfa a'i gyhoeddi i'r diweddbwynt. Yna rydym yn syml yn talu am bob galwad i'r swyddogaeth hon, gan anwybyddu'n llwyr y caledwedd lle mae'n cael ei weithredu.
Byddaf yn ceisio darlunio'r dull hwn gyda lluniau.
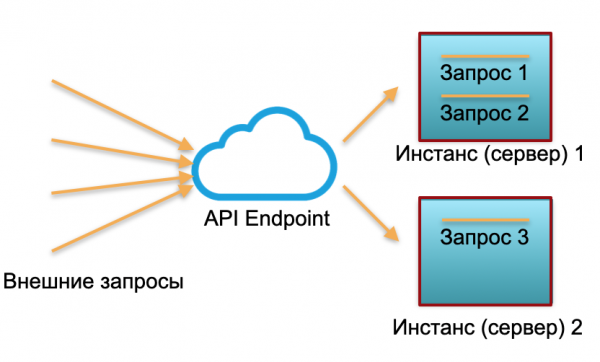
Defnydd clasurol. Mae gennym wasanaeth gyda llwyth penodol. Rydym yn codi dau achos: gweinyddwyr ffisegol neu enghreifftiau yn AWS. Anfonir ceisiadau allanol i'r achosion hyn a'u prosesu yno.
Fel y gwelwch yn y llun, nid yw'r gweinyddwyr yn cael eu gwaredu'n gyfartal. Mae un yn cael ei ddefnyddio 100%, mae dau gais, a dim ond 50% yw un - yn rhannol segur. Os na fydd tri chais yn cyrraedd, ond 30, yna ni fydd y system gyfan yn gallu ymdopi â'r llwyth a bydd yn dechrau arafu.
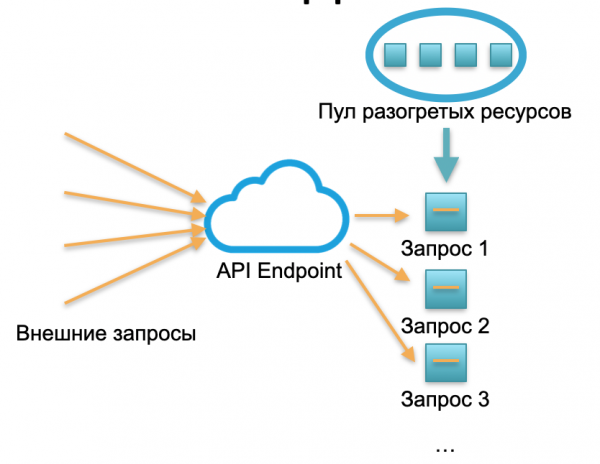
Defnydd di-weinydd. Mewn amgylchedd heb weinydd, nid oes gan wasanaeth o'r fath achosion na gweinyddwyr. Mae yna gronfa benodol o adnoddau wedi'u gwresogi - cynwysyddion Docker parod bach gyda chod swyddogaeth wedi'i ddefnyddio. Mae'r system yn derbyn ceisiadau allanol ac ar gyfer pob un ohonynt mae'r fframwaith di-weinydd yn codi cynhwysydd bach gyda chod: mae'n prosesu'r cais penodol hwn ac yn lladd y cynhwysydd.
Un cais - codwyd un cynhwysydd, 1000 o geisiadau - 1000 o gynwysyddion. Ac mae lleoli ar weinyddion caledwedd eisoes yn waith darparwr y cwmwl. Mae wedi'i guddio'n llwyr gan y fframwaith di-weinydd. Yn y cysyniad hwn rydym yn talu am bob galwad. Er enghraifft, daeth un alwad y dydd - talon ni am un alwad, daeth miliwn y funud - talon ni am filiwn. Neu mewn eiliad, mae hyn hefyd yn digwydd.
Mae'r cysyniad o gyhoeddi swyddogaeth heb weinydd yn addas ar gyfer gwasanaeth heb wladwriaeth. Ac os oes angen gwasanaeth gwladwriaethol (cyflwr) arnoch chi, yna rydyn ni'n ychwanegu cronfa ddata at y gwasanaeth. Yn yr achos hwn, o ran gweithio gyda'r wladwriaeth, mae pob swyddogaeth wladwriaethol yn ysgrifennu ac yn darllen o'r gronfa ddata. Ar ben hynny, o gronfa ddata o unrhyw un o'r tri math a ddisgrifir ar ddechrau'r erthygl.
Beth yw cyfyngiad cyffredin yr holl gronfeydd data hyn? Dyma gostau gweinydd cwmwl neu galedwedd a ddefnyddir yn gyson (neu sawl gweinydd). Nid oes ots a ydym yn defnyddio cronfa ddata glasurol neu a reolir, p'un a oes gennym Devops a gweinyddwr ai peidio, rydym yn dal i dalu am galedwedd, trydan a rhentu canolfan ddata 24/7. Os oes gennym ni sylfaen glasurol, rydyn ni'n talu am feistr a chaethwas. Os yw'n gronfa ddata wedi'i thorri'n fawr, rydyn ni'n talu am 10, 20 neu 30 o weinyddion, ac rydyn ni'n talu'n gyson.
Yn flaenorol, roedd presenoldeb gweinyddwyr a gadwyd yn barhaol yn y strwythur costau yn cael ei ystyried yn ddrwg angenrheidiol. Mae gan gronfeydd data confensiynol anawsterau eraill hefyd, megis cyfyngiadau ar nifer y cysylltiadau, cyfyngiadau graddio, consensws geo-ddosbarthedig - gellir eu datrys rywsut mewn rhai cronfeydd data, ond nid i gyd ar unwaith ac nid yn ddelfrydol.
Cronfa ddata di-weinydd - theori
Cwestiwn 2020: a yw'n bosibl gwneud cronfa ddata heb weinydd hefyd? Mae pawb wedi clywed am y backend di-weinydd ... gadewch i ni geisio gwneud y gronfa ddata yn ddi-weinydd?
Mae hyn yn swnio'n rhyfedd, oherwydd bod y gronfa ddata yn wasanaeth llawn cyflwr, nad yw'n addas iawn ar gyfer seilwaith heb weinydd. Ar yr un pryd, mae cyflwr y gronfa ddata yn fawr iawn: gigabeit, terabytes, ac mewn cronfeydd data dadansoddol hyd yn oed petabytes. Nid yw mor hawdd ei godi mewn cynwysyddion Docker ysgafn.
Ar y llaw arall, mae bron pob cronfa ddata modern yn cynnwys llawer iawn o resymeg a chydrannau: trafodion, cydlyniad uniondeb, gweithdrefnau, dibyniaethau perthynol a llawer o resymeg. Ar gyfer cryn dipyn o resymeg cronfa ddata, mae cyflwr bach yn ddigon. Dim ond cyfran fach o resymeg y gronfa ddata sy'n ymwneud â gweithredu ymholiadau'n uniongyrchol sy'n defnyddio Gigabytes a Terabytes yn uniongyrchol.
Yn unol â hynny, y syniad yw: os yw rhan o'r rhesymeg yn caniatáu gweithredu heb wladwriaeth, beth am rannu'r sylfaen yn rhannau Gwladol a Di-wladwriaeth.
Heb weinydd ar gyfer datrysiadau OLAP
Gawn ni weld sut olwg fyddai ar dorri cronfa ddata yn rhannau Gwladol a Di-wladwriaeth drwy ddefnyddio enghreifftiau ymarferol.
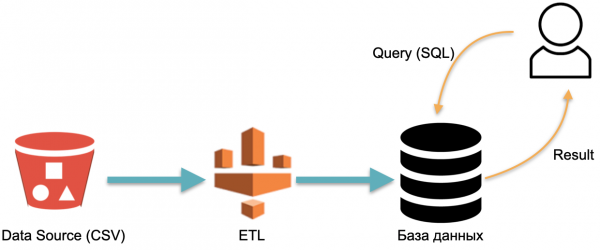
Er enghraifft, mae gennym gronfa ddata ddadansoddol: data allanol (silindr coch ar y chwith), proses ETL sy'n llwytho data i'r gronfa ddata, a dadansoddwr sy'n anfon ymholiadau SQL i'r gronfa ddata. Mae hwn yn gynllun gweithredu warws data clasurol.
Yn y cynllun hwn, mae ETL yn cael ei berfformio'n amodol unwaith. Yna mae angen i chi dalu'n gyson am y gweinyddwyr y mae'r gronfa ddata yn rhedeg arnynt gyda data wedi'i lenwi ag ETL, fel bod rhywbeth i anfon ymholiadau ato.
Gadewch i ni edrych ar ddull amgen a roddwyd ar waith yn AWS Athena Serverless. Nid oes unrhyw galedwedd pwrpasol parhaol ar gyfer storio data wedi'i lawrlwytho. Yn lle hyn:
- Mae'r defnyddiwr yn cyflwyno ymholiad SQL i Athena. Mae'r optimizer Athena yn dadansoddi'r ymholiad SQL ac yn chwilio'r storfa metadata (Metadata) am y data penodol sydd ei angen i weithredu'r ymholiad.
- Mae'r optimizer, yn seiliedig ar y data a gasglwyd, yn lawrlwytho'r data angenrheidiol o ffynonellau allanol i storfa dros dro (cronfa ddata dros dro).
- Gweithredir ymholiad SQL gan y defnyddiwr mewn storfa dros dro a dychwelir y canlyniad i'r defnyddiwr.
- Mae storfa dros dro yn cael ei chlirio a chaiff adnoddau eu rhyddhau.
Yn y bensaernïaeth hon, dim ond am y broses o weithredu'r cais yr ydym yn talu. Dim ceisiadau - dim costau.
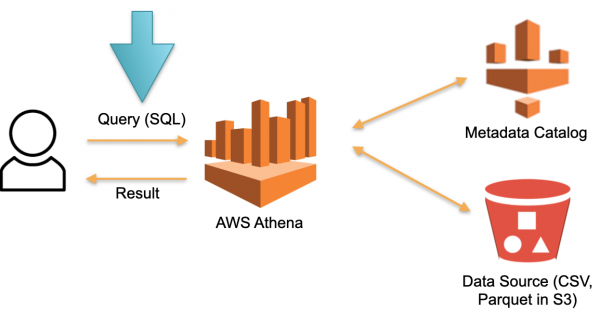
Mae hwn yn ddull gweithio ac fe'i gweithredir nid yn unig yn Athena Serverless, ond hefyd yn Redshift Spectrum (yn AWS).
Mae enghraifft Athena yn dangos bod cronfa ddata Serverless yn gweithio ar ymholiadau go iawn gyda degau a channoedd o Terabytes o ddata. Bydd angen cannoedd o weinyddion ar gannoedd o Terabytes, ond nid oes rhaid i ni dalu amdanynt - rydym yn talu am y ceisiadau. Mae cyflymder pob cais yn isel (iawn) o'i gymharu â chronfeydd data dadansoddol arbenigol fel Vertica, ond nid ydym yn talu am gyfnodau segur.
Mae cronfa ddata o'r fath yn berthnasol ar gyfer ymholiadau dadansoddol ad hoc prin. Er enghraifft, pan fyddwn yn penderfynu'n ddigymell i brofi rhagdybiaeth ar rywfaint o ddata enfawr. Mae Athena yn berffaith ar gyfer yr achosion hyn. Ar gyfer ceisiadau rheolaidd, mae system o'r fath yn ddrud. Yn yr achos hwn, cachewch y data mewn datrysiad arbenigol.
Heb weinydd ar gyfer datrysiadau OLTP
Edrychodd yr enghraifft flaenorol ar dasgau OLAP (dadansoddol). Nawr, gadewch i ni edrych ar dasgau OLTP.
Gadewch i ni ddychmygu PostgreSQL neu MySQL graddadwy. Gadewch i ni godi enghraifft reolaidd a reolir PostgreSQL neu MySQL gydag ychydig iawn o adnoddau. Pan fydd yr enghraifft yn derbyn mwy o lwyth, byddwn yn cysylltu copïau ychwanegol y byddwn yn dosbarthu rhan o'r llwyth darllen iddynt. Os nad oes unrhyw geisiadau na llwyth, byddwn yn diffodd y copïau. Y meistr yw'r lle cyntaf, ac mae'r gweddill yn gopïau.
Gweithredir y syniad hwn mewn cronfa ddata o'r enw Aurora Serverless AWS. Mae'r egwyddor yn syml: mae'r fflyd ddirprwy yn derbyn ceisiadau gan geisiadau allanol. Wrth weld y cynnydd yn y llwyth, mae'n dyrannu adnoddau cyfrifiadurol o achosion cynhesach lleiaf posibl - gwneir y cysylltiad cyn gynted â phosibl. Mae achosion o anabledd yn digwydd yn yr un modd.
O fewn Aurora mae cysyniad Uned Capasiti Aurora, ACU. Mae hwn (yn amodol) yn enghraifft (gweinydd). Gall pob ACU penodol fod yn feistr neu'n gaethwas. Mae gan bob Uned Cynhwysedd ei RAM, prosesydd a disg leiaf ei hun. Yn unol â hynny, mae un yn feistr, mae'r gweddill yn gopïau darllen yn unig.
Mae nifer yr Unedau Cynhwysedd Aurora hyn sy'n rhedeg yn baramedr y gellir ei ffurfweddu. Gall y swm lleiaf fod yn un neu sero (yn yr achos hwn, nid yw'r gronfa ddata yn gweithio os nad oes unrhyw geisiadau).
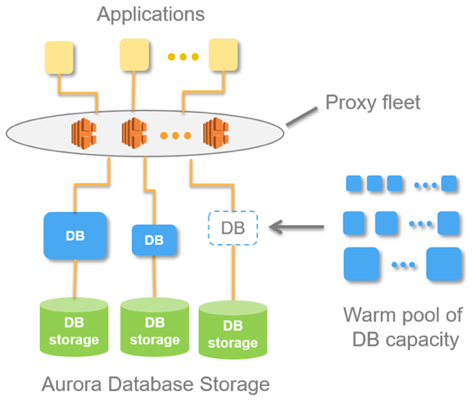
Pan fydd y sylfaen yn derbyn ceisiadau, mae'r fflyd dirprwy yn codi Aurora CapacityUnits, gan gynyddu adnoddau perfformiad y system. Mae'r gallu i gynyddu a lleihau adnoddau yn caniatáu i'r system “jyglo” adnoddau: arddangos ACUs unigol yn awtomatig (gan eu disodli â rhai newydd) a chyflwyno'r holl ddiweddariadau cyfredol i'r adnoddau a dynnwyd yn ôl.
Gall sylfaen Aurora Serverless raddfa'r llwyth darllen. Ond nid yw'r ddogfennaeth yn dweud hyn yn uniongyrchol. Efallai y bydd yn teimlo y gallant godi aml-feistr. Nid oes unrhyw hud.
Mae'r gronfa ddata hon yn addas iawn i osgoi gwario symiau enfawr o arian ar systemau â mynediad anrhagweladwy. Er enghraifft, wrth greu safleoedd cardiau busnes MVP neu farchnata, nid ydym fel arfer yn disgwyl llwyth sefydlog. Yn unol â hynny, os nad oes mynediad, nid ydym yn talu am achosion. Pan fydd llwyth annisgwyl yn digwydd, er enghraifft ar ôl cynhadledd neu ymgyrch hysbysebu, mae torfeydd o bobl yn ymweld â'r wefan ac mae'r llwyth yn cynyddu'n ddramatig, mae Aurora Serverless yn cymryd y llwyth hwn yn awtomatig ac yn cysylltu'r adnoddau coll (ACU) yn gyflym. Yna mae'r gynhadledd yn mynd heibio, mae pawb yn anghofio am y prototeip, mae'r gweinyddwyr (ACU) yn mynd yn dywyll, ac mae costau'n gostwng i sero - cyfleus.
Nid yw'r datrysiad hwn yn addas ar gyfer llwyth uchel sefydlog oherwydd nid yw'n graddio'r llwyth ysgrifennu. Mae'r holl gysylltiadau a datgysylltu adnoddau hyn yn digwydd ar yr hyn a elwir yn “bwynt graddfa” - pwynt mewn amser pan nad yw'r gronfa ddata yn cael ei chefnogi gan drafodiad neu dablau dros dro. Er enghraifft, o fewn wythnos efallai na fydd y pwynt graddfa yn digwydd, ac mae'r sylfaen yn gweithio ar yr un adnoddau ac ni all ehangu na chontractio.
Nid oes hud - mae'n PostgreSQL rheolaidd. Ond mae'r broses o ychwanegu peiriannau a'u datgysylltu yn rhannol awtomataidd.
Heb weinydd trwy ddyluniad
Mae Aurora Serverless yn hen gronfa ddata wedi'i hailysgrifennu ar gyfer y cwmwl i fanteisio ar rai o fanteision Serverless. Ac yn awr byddaf yn dweud wrthych am y sylfaen, a ysgrifennwyd yn wreiddiol ar gyfer y cwmwl, ar gyfer y dull di-weinydd - Serverless-by-design. Fe'i datblygwyd ar unwaith heb y rhagdybiaeth y byddai'n rhedeg ar weinyddion ffisegol.
Gelwir y sylfaen hon yn Snowflake. Mae ganddo dri bloc allweddol.
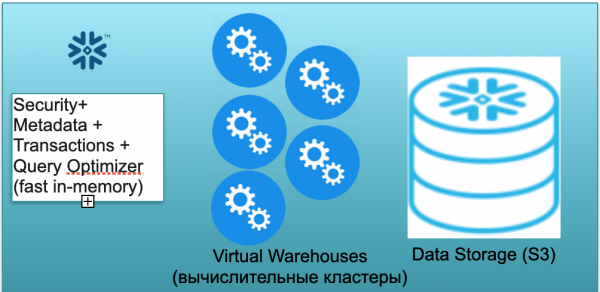
Y cyntaf yw bloc metadata. Mae hwn yn wasanaeth cof cyflym sy'n datrys problemau gyda diogelwch, metadata, trafodion, ac optimeiddio ymholiadau (a ddangosir yn y llun ar y chwith).
Mae'r ail floc yn set o glystyrau cyfrifiadurol rhithwir ar gyfer cyfrifiadau (yn y llun mae set o gylchoedd glas).
Mae'r trydydd bloc yn system storio data yn seiliedig ar S3. Mae S3 yn storfa gwrthrychau di-dimensiwn yn AWS, fel Dropbox di-dimensiwn ar gyfer busnes.
Gawn ni weld sut mae Snowflake yn gweithio, gan dybio dechrau oer. Hynny yw, mae cronfa ddata, mae'r data'n cael ei lwytho i mewn iddo, nid oes unrhyw ymholiadau rhedeg. Yn unol â hynny, os nad oes unrhyw geisiadau i'r gronfa ddata, yna rydym wedi codi'r gwasanaeth Metadata cof cyflym (bloc cyntaf). Ac mae gennym storfa S3 lle mae data bwrdd yn cael ei storio, wedi'i rannu'n ficroraniadau fel y'u gelwir. Er mwyn symlrwydd: os yw'r tabl yn cynnwys trafodion, yna microraniadau yw dyddiau trafodion. Mae pob dydd yn ficroraniad ar wahân, yn ffeil ar wahân. A phan fydd y gronfa ddata yn gweithredu yn y modd hwn, dim ond am y gofod a feddiannir gan y data y byddwch yn talu. Ar ben hynny, mae'r gyfradd fesul sedd yn isel iawn (yn enwedig gan ystyried y cywasgu sylweddol). Mae'r gwasanaeth metadata hefyd yn gweithio'n gyson, ond nid oes angen llawer o adnoddau arnoch i wneud y gorau o ymholiadau, a gellir ystyried y gwasanaeth yn shareware.
Nawr, gadewch i ni ddychmygu bod defnyddiwr wedi dod i'n cronfa ddata ac wedi anfon ymholiad SQL. Anfonir yr ymholiad SQL ar unwaith i'r gwasanaeth Metadata i'w brosesu. Yn unol â hynny, ar ôl derbyn cais, mae'r gwasanaeth hwn yn dadansoddi'r cais, y data sydd ar gael, caniatâd defnyddwyr ac, os yw popeth yn iawn, yn llunio cynllun ar gyfer prosesu'r cais.
Nesaf, mae'r gwasanaeth yn cychwyn lansiad y clwstwr cyfrifiadura. Mae clwstwr cyfrifiadurol yn glwstwr o weinyddion sy'n gwneud cyfrifiadau. Hynny yw, mae hwn yn glwstwr a all gynnwys 1 gweinydd, 2 weinydd, 4, 8, 16, 32 - cymaint ag y dymunwch. Rydych chi'n taflu cais ac mae lansiad y clwstwr hwn yn dechrau ar unwaith. Mae wir yn cymryd eiliadau.
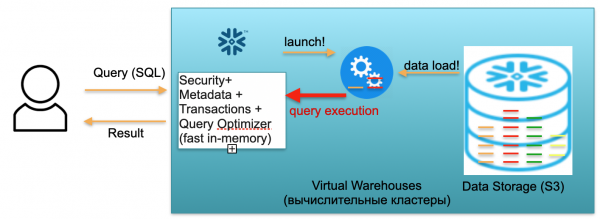
Nesaf, ar ôl i'r clwstwr ddechrau, mae'r microraniadau sydd eu hangen i brosesu'ch cais yn dechrau cael eu copïo i'r clwstwr o S3. Hynny yw, gadewch i ni ddychmygu bod angen dau raniad o un bwrdd ac un o'r ail i gyflawni ymholiad SQL. Yn yr achos hwn, dim ond y tri rhaniad angenrheidiol fydd yn cael eu copïo i'r clwstwr, ac nid pob tabl yn gyfan gwbl. Dyna pam, ac yn union oherwydd bod popeth wedi'i leoli o fewn un ganolfan ddata ac wedi'i gysylltu â sianeli cyflym iawn, mae'r broses drosglwyddo gyfan yn digwydd yn gyflym iawn: mewn eiliadau, anaml iawn mewn munudau, oni bai ein bod yn sôn am rai ceisiadau gwrthun. Yn unol â hynny, caiff microraniadau eu copïo i'r clwstwr cyfrifiadura, ac, ar ôl ei gwblhau, gweithredir yr ymholiad SQL ar y clwstwr cyfrifiadurol hwn. Gall canlyniad y cais hwn fod yn un llinell, sawl llinell neu dabl - cânt eu hanfon yn allanol at y defnyddiwr fel y gall ei lawrlwytho, ei arddangos yn ei declyn BI, neu ei ddefnyddio mewn rhyw ffordd arall.
Gall pob ymholiad SQL nid yn unig ddarllen agregau o ddata a lwythwyd yn flaenorol, ond hefyd llwytho/cynhyrchu data newydd yn y gronfa ddata. Hynny yw, gall fod yn ymholiad sydd, er enghraifft, yn mewnosod cofnodion newydd i dabl arall, sy'n arwain at ymddangosiad rhaniad newydd ar y clwstwr cyfrifiadurol, sydd, yn ei dro, yn cael ei gadw'n awtomatig mewn un storfa S3.
Mae'r senario a ddisgrifir uchod, o ddyfodiad y defnyddiwr i godi'r clwstwr, llwytho data, gweithredu ymholiadau, cael canlyniadau, yn cael ei dalu ar y gyfradd am funudau o ddefnyddio'r clwstwr cyfrifiadura rhithwir uchel, warws rhithwir. Mae'r gyfradd yn amrywio yn dibynnu ar barth AWS a maint y clwstwr, ond ar gyfartaledd mae'n ychydig ddoleri yr awr. Mae clwstwr o bedwar peiriant ddwywaith yn ddrytach na chlwstwr o ddau beiriant, ac mae clwstwr o wyth peiriant yn dal i fod ddwywaith yn ddrutach. Mae opsiynau o 16, 32 o beiriannau ar gael, yn dibynnu ar gymhlethdod y ceisiadau. Ond dim ond am y munudau hynny pan fydd y clwstwr yn rhedeg y byddwch chi'n talu, oherwydd pan nad oes unrhyw geisiadau, rydych chi'n fath o dynnu'ch dwylo, ac ar ôl 5-10 munud o aros (paramedr ffurfweddadwy) bydd yn mynd i ffwrdd ar ei ben ei hun, rhyddhau adnoddau a dod yn rhydd.
Senario cwbl realistig yw pan fyddwch chi'n anfon cais, mae'r clwstwr yn ymddangos, yn gymharol siarad, mewn munud, mae'n cyfrif munud arall, yna pum munud i gau, ac rydych chi'n talu am saith munud o weithredu'r clwstwr hwn yn y pen draw, a nid am fisoedd a blynyddoedd.
Disgrifiodd y senario gyntaf ddefnyddio Snowflake mewn lleoliad un defnyddiwr. Nawr, gadewch i ni ddychmygu bod yna lawer o ddefnyddwyr, sy'n agosach at y senario go iawn.
Gadewch i ni ddweud bod gennym lawer o ddadansoddwyr ac adroddiadau Tableau sy'n peledu ein cronfa ddata yn gyson â nifer fawr o ymholiadau SQL dadansoddol syml.
Yn ogystal, gadewch i ni ddweud bod gennym Wyddonwyr Data dyfeisgar sy'n ceisio gwneud pethau gwrthun gyda data, yn gweithredu gyda degau o Terabytes, yn dadansoddi biliynau a thriliynau o resi o ddata.
Ar gyfer y ddau fath o lwyth gwaith a ddisgrifir uchod, mae Snowflake yn caniatáu ichi godi sawl clwstwr cyfrifiadura annibynnol o wahanol alluoedd. At hynny, mae'r clystyrau cyfrifiadurol hyn yn gweithio'n annibynnol, ond gyda data cyson cyffredin.
Ar gyfer nifer fawr o ymholiadau ysgafn, gallwch godi 2-3 clwstwr bach, tua 2 beiriant yr un. Gellir gweithredu'r ymddygiad hwn, ymhlith pethau eraill, gan ddefnyddio gosodiadau awtomatig. Felly rydych chi'n dweud, “Pluen eira, codwch glwstwr bach. Os yw'r llwyth arno'n cynyddu uwchlaw paramedr penodol, codwch ail, trydydd tebyg. Pan fydd y llwyth yn dechrau ymsuddo, diffoddwch y gormodedd.” Fel bod gan bawb ddigon o adnoddau, ni waeth faint o ddadansoddwyr sy'n dechrau edrych ar adroddiadau.
Ar yr un pryd, os yw dadansoddwyr yn cysgu ac nad oes neb yn edrych ar yr adroddiadau, efallai y bydd y clystyrau'n mynd yn dywyll yn llwyr, ac rydych chi'n rhoi'r gorau i dalu amdanynt.
Ar yr un pryd, ar gyfer ymholiadau trwm (gan Wyddonwyr Data), gallwch godi un clwstwr mawr iawn ar gyfer 32 o beiriannau. Bydd y clwstwr hwn hefyd yn cael ei dalu am y munudau a'r oriau hynny pan fydd eich cais anferth yn rhedeg yno.
Mae'r cyfle a ddisgrifir uchod yn caniatáu ichi rannu nid yn unig 2, ond hefyd mwy o fathau o lwyth gwaith yn glystyrau (ETL, monitro, gwireddu adroddiadau, ...).
Gadewch i ni grynhoi Pluenen Eira. Mae'r sylfaen yn cyfuno syniad hardd a gweithrediad ymarferol. Yn ManyChat, rydym yn defnyddio Snowflake i ddadansoddi'r holl ddata sydd gennym. Nid oes gennym dri chlwstwr, fel yn yr enghraifft, ond o 5 i 9, o wahanol feintiau. Mae gennym 16-peiriant confensiynol, 2-peiriant, a hefyd rhai 1-peiriant bach iawn ar gyfer rhai tasgau. Maent yn dosbarthu'r llwyth yn llwyddiannus ac yn ein galluogi i arbed llawer.
Mae'r gronfa ddata yn graddio'r llwyth darllen ac ysgrifennu yn llwyddiannus. Mae hwn yn wahaniaeth enfawr ac yn ddatblygiad enfawr o'i gymharu â'r un “Aurora”, a oedd yn cario'r llwyth darllen yn unig. Mae pluen eira yn caniatáu ichi raddio'ch llwyth gwaith ysgrifennu gyda'r clystyrau cyfrifiadurol hyn. Hynny yw, fel y soniais, rydym yn defnyddio sawl clwstwr yn ManyChat, mae clystyrau bach ac uwch-fach yn cael eu defnyddio'n bennaf ar gyfer ETL, ar gyfer llwytho data. Ac mae dadansoddwyr eisoes yn byw ar glystyrau canolig, nad yw'r llwyth ETL yn effeithio arnynt o gwbl, felly maent yn gweithio'n gyflym iawn.
Yn unol â hynny, mae'r gronfa ddata yn addas iawn ar gyfer tasgau OLAP. Fodd bynnag, yn anffodus, nid yw'n berthnasol eto ar gyfer llwythi gwaith OLTP. Yn gyntaf, mae'r gronfa ddata hon yn golofnog, gyda'r holl ganlyniadau dilynol. Yn ail, nid yw'r dull ei hun, pan fyddwch chi'n codi clwstwr cyfrifiadura ac yn gorlifo â data ar gyfer pob cais, yn anffodus, yn ddigon cyflym eto ar gyfer llwythi OLTP. Mae aros eiliadau ar gyfer tasgau OLAP yn normal, ond ar gyfer tasgau OLTP mae'n annerbyniol; byddai 100 ms yn well, neu byddai 10 ms hyd yn oed yn well.
Cyfanswm
Mae cronfa ddata heb weinydd yn bosibl trwy rannu'r gronfa ddata yn rhannau Di-wladwriaeth a Gwladol. Efallai eich bod wedi sylwi, yn yr holl enghreifftiau uchod, mai'r rhan Stateful, yn gymharol siarad, yw storio micro-barwydydd yn S3, a Stateless yw'r optimizer, gan weithio gyda metadata, gan drin materion diogelwch y gellir eu codi fel gwasanaethau di-wladwriaeth ysgafn annibynnol.
Gall gweithredu ymholiadau SQL hefyd gael ei ystyried yn wasanaethau cyflwr ysgafn a all ymddangos yn y modd di-weinydd, fel clystyrau cyfrifiadurol Snowflake, lawrlwytho'r data angenrheidiol yn unig, gweithredu'r ymholiad a "mynd allan."
Mae cronfeydd data lefel cynhyrchu di-weinydd eisoes ar gael i'w defnyddio, maen nhw'n gweithio. Mae'r cronfeydd data di-weinydd hyn eisoes yn barod i drin tasgau OLAP. Yn anffodus, ar gyfer tasgau OLTP maent yn cael eu defnyddio ... gyda naws, gan fod cyfyngiadau. Ar y naill law, minws yw hwn. Ond, ar y llaw arall, dyma gyfle. Efallai y bydd un o'r darllenwyr yn dod o hyd i ffordd i wneud cronfa ddata OLTP yn gwbl ddi-weinydd, heb gyfyngiadau Aurora.
Rwy'n gobeithio eich bod wedi ei chael yn ddiddorol. Heb weinydd yw'r dyfodol :)
Ffynhonnell: hab.com
