


Hej Habr! I denne artikel vil jeg tale om et fantastisk værktøj til at udvikle batch-databehandlingsprocesser, for eksempel i infrastrukturen af en virksomheds DWH eller din DataLake. Vi vil tale om Apache Airflow (i det følgende benævnt Airflow). Han er uretfærdigt frataget opmærksomheden på Habré, og i hovedsagen vil jeg forsøge at overbevise dig om, at Airflow i det mindste er værd at se på, når du vælger en skemalægger til dine ETL/ELT-processer.
Tidligere skrev jeg en række artikler om emnet DWH, da jeg arbejdede i Tinkoff Bank. Nu er jeg blevet en del af Mail.Ru Group-teamet og er ved at udvikle en platform til dataanalyse på spilområdet. Faktisk, efterhånden som nyheder og interessante løsninger dukker op, vil teamet og jeg her tale om vores platform for dataanalyse.
prolog
Så lad os begynde. Hvad er luftstrøm? Dette er et bibliotek (eller ) til at udvikle, planlægge og overvåge arbejdsgange. Hovedtræk ved Airflow er, at Python-kode bruges til at beskrive (udvikle) processer. Dette har en masse fordele for at organisere dit projekt og udvikling: Faktisk er dit (for eksempel) ETL-projekt bare et Python-projekt, og du kan organisere det, som du vil, under hensyntagen til infrastrukturfunktioner, teamstørrelse og andre krav . Instrumentelt er alt simpelt. Brug for eksempel PyCharm + Git. Det er fantastisk og meget praktisk!
Lad os nu se på hovedenhederne i Airflow. Når du har forstået deres essens og formål, vil du optimalt organisere procesarkitekturen. Måske er hovedenheden den rettede acykliske graf (herefter DAG).
DAG
DAG er en semantisk association af dine opgaver, som du ønsker at fuldføre i en strengt defineret rækkefølge på en bestemt tidsplan. Airflow præsenterer en praktisk webgrænseflade til at arbejde med DAG'er og andre enheder:
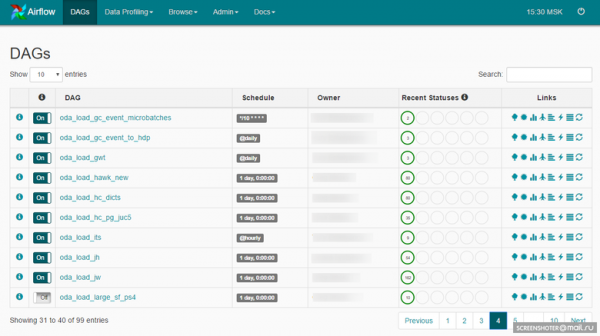
DAG kan se sådan ud:
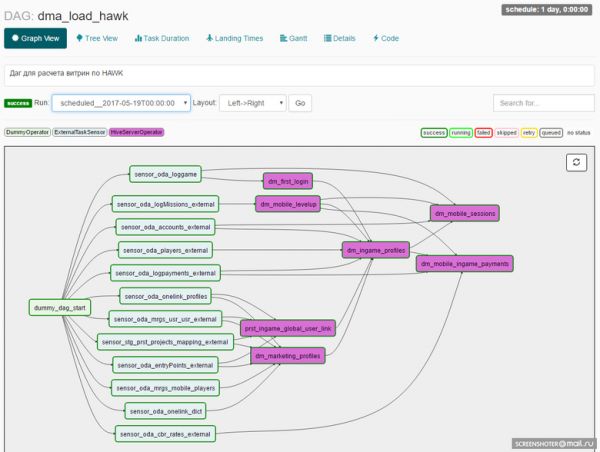
Ved design af en DAG fastlægger en udvikler et sæt operatører, som opgaver inden for DAG skal bygges på. Her kommer vi til en anden vigtig enhed: Airflow Operator.
operatører
En operatør er en enhed, ud fra hvilke jobinstanser der oprettes, som beskriver, hvad der vil ske under udførelsen af en jobinstans. indeholder allerede et sæt udsagn, der er klar til at blive brugt. Eksempler:
- BashOperator er en operatør til at udføre en bash-kommando.
- PythonOperator er en operatør til at kalde Python-kode.
- EmailOperator - operatør til afsendelse af e-mail.
- HTTPOperator - en operatør til at arbejde med http-anmodninger.
- SqlOperator er en operatør til at udføre SQL-kode.
- Sensor er en operatør til at vente på en begivenhed (ankomsten af det ønskede tidspunkt, udseendet af den påkrævede fil, en række i databasen, et svar fra API'en osv. osv.).
Der er mere specifikke operatører: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator.
Du kan også udvikle operatører, der passer til dine behov og bruge dem i dit projekt. For eksempel har vi skabt MongoDBToHiveViaHdfsTransfer, en operatør til eksport af dokumenter fra MongoDB til Hive, og flere operatører til at arbejde med : CHLoadFromHiveOperator og CHTableLoaderOperator. Faktisk, så snart et projekt ofte har brugt kode bygget på grundlæggende sætninger, kan du overveje at kompilere den til en ny erklæring. Dette vil forenkle den videre udvikling, og du vil tilføje dit bibliotek af operatører i projektet.
Yderligere skal alle disse forekomster af opgaver udføres, og nu vil vi tale om planlæggeren.
Planlægger
Opgaveplanlæggeren i Airflow er bygget på . Selleri er et Python-bibliotek, der giver dig mulighed for at organisere en kø plus asynkron og distribueret udførelse af opgaver. Fra Airflow-siden er alle opgaver opdelt i puljer. Puljer oprettes manuelt. Som regel er deres formål at begrænse belastningen af at arbejde med kilden eller at skrive opgaver inde i DWH. Puljer kan administreres via webgrænsefladen:
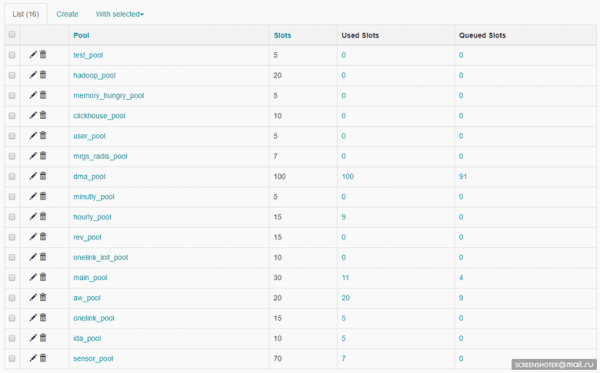
Hver pulje har en grænse for antallet af slots. Når du opretter en DAG, får den en pulje:
ALERT_MAILS = Variable.get("gv_mail_admin_dwh")
DAG_NAME = 'dma_load'
OWNER = 'Vasya Pupkin'
DEPENDS_ON_PAST = True
EMAIL_ON_FAILURE = True
EMAIL_ON_RETRY = True
RETRIES = int(Variable.get('gv_dag_retries'))
POOL = 'dma_pool'
PRIORITY_WEIGHT = 10
start_dt = datetime.today() - timedelta(1)
start_dt = datetime(start_dt.year, start_dt.month, start_dt.day)
default_args = {
'owner': OWNER,
'depends_on_past': DEPENDS_ON_PAST,
'start_date': start_dt,
'email': ALERT_MAILS,
'email_on_failure': EMAIL_ON_FAILURE,
'email_on_retry': EMAIL_ON_RETRY,
'retries': RETRIES,
'pool': POOL,
'priority_weight': PRIORITY_WEIGHT
}
dag = DAG(DAG_NAME, default_args=default_args)
dag.doc_md = __doc__Puljen indstillet på DAG-niveau kan tilsidesættes på opgaveniveau.
En separat proces, Scheduler, er ansvarlig for at planlægge alle opgaver i Airflow. Faktisk beskæftiger planlæggeren sig med al mekanikken til at indstille opgaver til udførelse. En opgave gennemgår flere faser, før den udføres:
- Tidligere opgaver er udført i DAG, en ny kan stå i kø.
- Køen sorteres alt efter opgaveprioritet (prioriteringer kan også styres), og hvis der er en ledig plads i puljen, kan opgaven tages på arbejde.
- Hvis der er en gratis arbejderselleri, sendes opgaven til den; det arbejde, du har programmeret i opgaven, begynder ved hjælp af en eller anden operatør.
Simpelt nok.
Scheduleren kører på et sæt af alle DAG'er og alle opgaver inden for DAG'er.
For at planlæggeren kan begynde at arbejde med DAG'en, skal DAG'en sætte en tidsplan:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly')Der er et sæt færdige forudindstillinger: @once, @hourly, @daily, @weekly, @monthly, @yearly.
Du kan også bruge cron-udtryk:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *')Udførelsesdato
For at forstå, hvordan Airflow fungerer, er det vigtigt at forstå, hvad en udførelsesdato er for en DAG. Airflow DAG'en har dimensionen Udførelsesdato, dvs. afhængigt af DAG'ens arbejdsplan, oprettes opgaveforekomster for hver Udførelsesdato. Og for hver Udførelsesdato kan opgaver genudføres - eller for eksempel kan en DAG arbejde samtidigt i flere Udførelsesdatoer. Dette er tydeligt vist her:
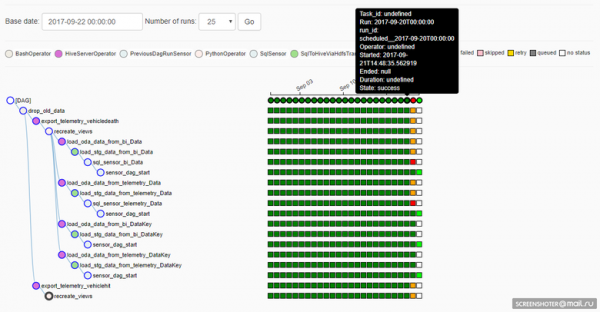
Desværre (eller måske heldigvis: det afhænger af situationen), hvis implementeringen af opgaven i DAG er korrekt, så vil udførelsen i den tidligere Udførelsesdato følge med justeringerne. Dette er godt, hvis du skal genberegne data i tidligere perioder ved hjælp af en ny algoritme, men det er dårligt, fordi reproducerbarheden af resultatet går tabt (selvfølgelig er der ingen, der gider returnere den nødvendige version af kildekoden fra Git og beregne, hvad du brug én gang efter behov).
Opgavegenerering
DAG-implementeringen er Python-kode, så vi har en meget praktisk måde at reducere mængden af kode på, når vi for eksempel arbejder med shardede kilder. Antag, at du har tre MySQL-shards som kilde, skal du klatre ind i hver og hente nogle data. Og uafhængigt og parallelt. Python-koden i DAG kan se sådan ud:
connection_list = lv.get('connection_list')
export_profiles_sql = '''
SELECT
id,
user_id,
nickname,
gender,
{{params.shard_id}} as shard_id
FROM profiles
'''
for conn_id in connection_list:
export_profiles = SqlToHiveViaHdfsTransfer(
task_id='export_profiles_from_' + conn_id,
sql=export_profiles_sql,
hive_table='stg.profiles',
overwrite=False,
tmpdir='/data/tmp',
conn_id=conn_id,
params={'shard_id': conn_id[-1:], },
compress=None,
dag=dag
)
export_profiles.set_upstream(exec_truncate_stg)
export_profiles.set_downstream(load_profiles)DAG ser således ud:
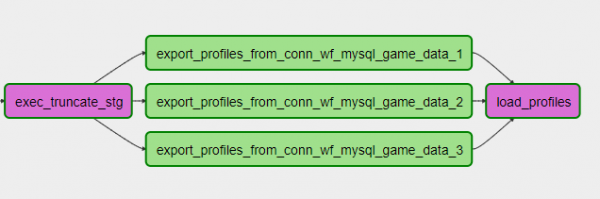
Samtidig kan du tilføje eller fjerne et skår ved blot at justere indstillingen og opdatere DAG. Komfortabel!
Du kan også bruge mere kompleks kodegenerering, for eksempel arbejde med kilder i form af en database eller beskrive en tabelstruktur, en algoritme til at arbejde med en tabel og, under hensyntagen til funktionerne i DWH-infrastrukturen, generere processen indlæsning af N tabeller i dit lager. Eller hvis du for eksempel arbejder med en API, der ikke understøtter at arbejde med en parameter i form af en liste, kan du generere N opgaver i en DAG ved hjælp af denne liste, begrænse paralleliteten af anmodninger i API'en til en pulje og udtrække de nødvendige data fra API'et. Fleksibel!
depot
Airflow har sit eget backend-lager, en database (måske MySQL eller Postgres, vi har Postgres), som gemmer status for opgaver, DAG'er, forbindelsesindstillinger, globale variabler osv. osv. Her vil jeg gerne sige, at depotet i Airflow er meget enkel (ca. 20 tabeller) og praktisk, hvis du vil bygge nogen af dine processer på den. Jeg husker 100500 tabeller i Informatica-depotet, som skulle ryges i lang tid, før man kunne forstå, hvordan man opbyggede en forespørgsel.
overvågning
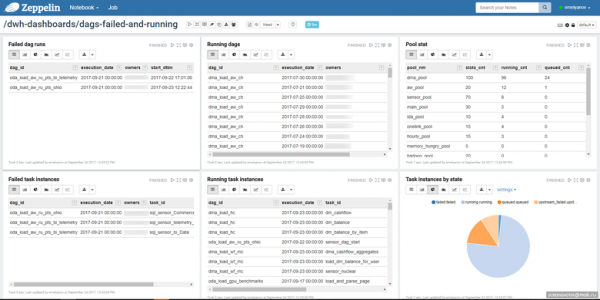
I betragtning af lagerets enkelhed kan du bygge en proces til overvågning af opgaver, som er praktisk for dig. Vi bruger en notesblok i Zeppelin, hvor vi ser på status for opgaver:
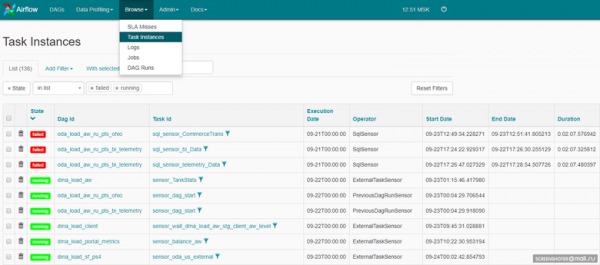
Det kan også være selve Airflows webgrænseflade:
Airflow-koden er åben, så vi tilføjede en advarsel i Telegram. Hver kørende opgaveforekomst, hvis der opstår en fejl, spammer til Telegram-gruppen, hvor hele udviklings- og supportteamet består.
Vi får et hurtigt svar gennem Telegram (hvis nødvendigt), gennem Zeppelin - et samlet billede af opgaverne i Airflow.
I alt
Airflow er først og fremmest open source, og forvent ikke mirakler fra det. Vær forberedt på at bruge tid og kræfter på at bygge en fungerende løsning. Et mål fra kategorien opnåelige, tro mig, det er det værd. Udviklingshastighed, fleksibilitet, let at tilføje nye processer - du vil elske det. Selvfølgelig skal du være meget opmærksom på tilrettelæggelsen af projektet, stabiliteten af arbejdet med Airflow selv: der er ingen mirakler.
Nu har vi Airflow, der arbejder dagligt omkring 6,5 tusinde opgaver. De er ret forskellige i naturen. Der er opgaver til at indlæse data i hoved-DWH fra mange forskellige og meget specifikke kilder, der er opgaver til at beregne butiksfacader inde i hoved-DWH, der er opgaver til at publicere data til en hurtig DWH, der er mange, mange forskellige opgaver - og Airflow tygger dem hele dag efter dag. Taler i tal, det er 2,3 tusind ELT opgaver af varierende kompleksitet indenfor DWH (Hadoop), ca 2,5 hundrede databaser kilder, dette er en kommando fra 4 ETL udviklere, som er opdelt i ETL databehandling i DWH og ELT databehandling indenfor DWH og selvfølgelig flere én admin, som omhandler tjenestens infrastruktur.
Planer for fremtiden
Antallet af processer vokser uundgåeligt, og det vigtigste, vi vil gøre med hensyn til Airflow-infrastrukturen, er skalering. Vi vil bygge en Airflow-klynge, tildele et par ben til Selleri-arbejdere og lave et duplikathoved med jobplanlægningsprocesser og et lager.
Epilog
Dette er selvfølgelig langt fra alt, hvad jeg gerne vil tale om Airflow, men jeg forsøgte at fremhæve hovedpunkterne. Appetit følger med at spise, prøv det, og du vil kunne lide det 🙂
Kilde: www.habr.com
