

Hvordan du kan omsætte forretningskrav til specifikke datastrukturer ved at bruge eksemplet med at designe en messenger-database fra bunden.
- Del 1: design af basisrammen

Vores base vil ikke være så stor og distribueret, eller , men “så det var”, men det var godt – funktionelt, hurtigt og passer på én server PostgreSQL - så du kan implementere en separat instans af tjenesten et sted på siden, for eksempel.
Derfor vil vi ikke berøre spørgsmålene om sharding, replikering og geo-distribuerede systemer, men vil fokusere på kredsløbsløsninger inde i databasen.
Trin 1: Nogle forretningsspecifikationer
Vi vil ikke designe vores budskaber abstrakt, men vil integrere det i miljøet . Det vil sige, at vores folk ikke "bare korresponderer", men kommunikerer med hinanden i forbindelse med løsning af visse forretningsproblemer.
Og hvad er en virksomheds opgaver?.. Lad os se på eksemplet med Vasily, lederen af udviklingsafdelingen.
- "Nikolai, til denne opgave har vi brug for et plaster i dag!"
Det betyder, at korrespondance kan føres i forbindelse med nogle dokumentet. - "Kolya, skal du til Dota i aften?"
Det vil sige, at selv et par samtalepartnere kan kommunikere samtidigt om forskellige emner. - "Peter, Nikolay, se i den vedhæftede fil for prislisten for den nye server."
Så én besked kan have flere modtagere. I dette tilfælde kan meddelelsen indeholde Vedhæftede filer. - "Semyon, se også."
Og der skulle være mulighed for at indgå i eksisterende korrespondance invitere et nyt medlem.
Lad os dvæle ved denne liste over "åbenlyse" behov for nu.
Uden at forstå de anvendte specifikationer af problemet og de begrænsninger, der er givet til det, design effektiv databaseskema til at løse det er næsten umuligt.
Trin 2: Minimal Logic Circuit
Indtil videre fungerer alt meget lig e-mail-korrespondance - et traditionelt forretningsværktøj. Ja, "algoritmisk" ligner mange forretningsproblemer hinanden, derfor vil værktøjerne til at løse dem være strukturelt ens.
Lad os rette det allerede opnåede logiske diagram over entitetsforhold. For at gøre vores model lettere at forstå, vil vi bruge den mest primitive visningsmulighed uden komplikationerne ved UML- eller IDEF-notationer:
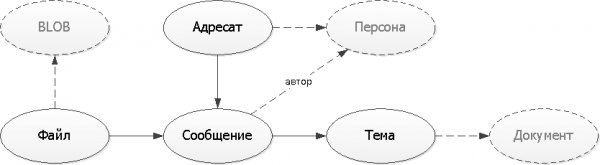
I vores eksempel er personen, dokumentet og den binære "body" af filen "eksterne" enheder, der eksisterer uafhængigt uden vores service. Derfor vil vi blot opfatte dem i fremtiden som nogle links "et eller andet sted" af UUID.
Tegne diagrammer så enkle som muligt - de fleste af de mennesker, du vil vise dem til, er ikke eksperter i at læse UML/IDEF. Men sørg for at tegne.
Trin 3: Skitsering af tabelstrukturen
Om tabel- og feltnavneDe "russiske" navne på felter og tabeller kan behandles forskelligt, men det er en smagssag. Fordi der er ingen udenlandske udviklere, og PostgreSQL giver os mulighed for at give navne selv i hieroglyffer, hvis de omgivet af anførselstegn, så foretrækker vi at navngive objekter entydigt og tydeligt, så der ikke er uoverensstemmelser.
Da mange mennesker skriver beskeder til os på én gang, kan nogle af dem endda gøre dette offline, så er den enkleste mulighed bruge UUID'er som identifikatorer ikke kun for eksterne enheder, men også for alle objekter i vores service. Desuden kan de genereres selv på klientsiden - dette vil hjælpe os med at understøtte afsendelse af beskeder, når databasen er midlertidigt utilgængelig, og sandsynligheden for en kollision er ekstremt lav.
Udkastet til tabelstrukturen i vores database vil se sådan ud:
Tabeller: RU
CREATE TABLE "Тема"(
"Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "Сообщение"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "Автор"
uuid
, "ДатаВремя"
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат"(
"Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл"(
"Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);Tabeller: EN
CREATE TABLE theme(
theme
uuid
PRIMARY KEY
, document
uuid
, title
text
);
CREATE TABLE message(
message
uuid
PRIMARY KEY
, theme
uuid
, author
uuid
, dt
timestamp
, body
text
);
CREATE TABLE message_addressee(
message
uuid
, person
uuid
, PRIMARY KEY(message, person)
);
CREATE TABLE message_file(
file
uuid
PRIMARY KEY
, message
uuid
, content
uuid
, filename
text
);Den enkleste ting, når du skal beskrive et format, er at begynde at "afvikle" forbindelsesgrafen fra tabeller, der ikke er refereret til sig selv til ingen.
Trin 4: Find ud af ikke-oplagte behov
Det er det, vi har designet en database, hvor du kan skrive perfekt og på en eller anden måde at læse.
Lad os sætte os i brugerens sted - hvad vil vi med det?
- Sidste beskeder
Det kronologisk sorteret et register over "mine" beskeder baseret på forskellige kriterier. Hvor jeg er en af modtagerne, hvor jeg er forfatteren, hvor de skrev til mig, og jeg svarede ikke, hvor de ikke svarede mig, ... - Deltagere i korrespondancen
Hvem deltager overhovedet i denne lange, lange chat?
Vores struktur giver os mulighed for at løse begge disse problemer "generelt", men ikke hurtigt. Problemet er, at for sortering inden for den første opgave ude af stand til at oprette indeks, egnet til hver af deltagerne (og du bliver nødt til at udtrække alle posterne), og for at løse den anden, du har brug for udtrække alle beskeder om dette emne.
Utilsigtede brugeropgaver kan være fed kryds på produktivitet.
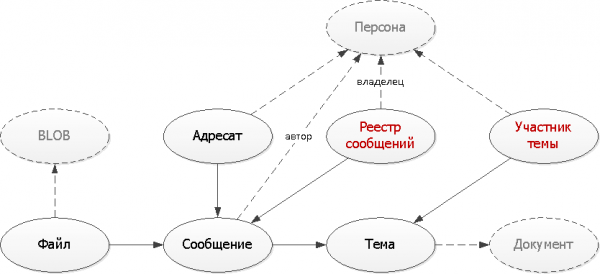
Trin 5: Smart denormalisering
Begge vores problemer vil blive løst af yderligere tabeller, hvor vi vil dubleret del af dataene, nødvendige for at danne indekser, der er egnede til vores opgaver.
Tabeller: RU
CREATE TABLE "РеестрСообщений"(
"Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
CREATE TABLE "УчастникТемы"(
"Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);Tabeller: EN
CREATE TABLE message_registry(
owner
uuid
, registry
smallint
, dt
timestamp
, message
uuid
, PRIMARY KEY(owner, registry, message)
);
CREATE INDEX ON message_registry(owner, registry, dt DESC);
CREATE TABLE theme_participant(
theme
uuid
, person
uuid
, PRIMARY KEY(theme, person)
);Her har vi anvendt to typiske tilgange, der bruges ved oprettelse af hjælpetabeller:
- Multiplikation af poster
Ved hjælp af én indledende beskedpost opretter vi flere opfølgningsposter i forskellige typer registre for forskellige ejere - både for afsender og for modtager. Men hvert af registrene falder nu på indekset - trods alt vil vi i et typisk tilfælde kun ønske at se den første side. - Unikke optegnelser
Hver gang du sender en besked inden for et bestemt emne, er det nok at tjekke, om en sådan post allerede eksisterer. Hvis ikke, så føj det til vores "ordbog".
I den næste del af artiklen vil vi tale om ind i strukturen af vores database.
Kilde: www.habr.com
